
大模型RAG技術:從入門到實踐
大模型微調(Fine-tuning)是針對預訓練模型進行針對性優化的過程,旨在提升其在特定任務上的性能。通過微調,模型可以適應特定領域的需求,表現出更高的準確性和效率。微調的核心在于利用特定領域的數據集,對已預訓練的模型進行進一步訓練,使其在特定任務上表現更佳。
微調不僅是提升模型性能的關鍵手段,也是實現模型定制化的重要步驟。大模型,如GPT-3、BERT等,雖然在通用任務上表現出色,但在特定領域的應用中往往需要進一步優化。這一過程能夠讓模型更好地理解領域特定的語言模式和知識,從而提升任務表現。
微調的核心在于通過特定領域的數據對預訓練模型進行優化。這個過程涉及對模型參數的調整,尤其是超參數的設置,如學習率、批次大小和訓練輪次等。超參數的合理設置對于微調的成功至關重要。
在微調過程中,模型通過不斷調整參數,逐步適應新的數據分布,從而在特定任務上取得更好的性能。合理的超參數設置可以加速訓練過程,提高模型的收斂速度和最終性能。
選擇合適的平臺進行微調是成功的關鍵。Hugging Face 是一家專注于自然語言處理(NLP)模型訓練和部署的平臺公司,提供了豐富的預訓練模型和工具,助力快速開發與部署。
Hugging Face 平臺的優勢在于其跨平臺兼容性,與 TensorFlow、PyTorch 和 Keras 等主流深度學習框架兼容。其微調工具可以節省從頭開始訓練模型的時間和精力,而龐大的用戶社區也為用戶提供了豐富的支持和幫助。
在開始微調之前,首先需要選擇與任務相關的數據集,并對其進行預處理。這包括數據的清洗、分詞和編碼等步驟。數據的質量直接影響到微調的效果,因此需要確保數據集的準確性和多樣性。
選擇一個適合的預訓練模型是微調成功的基礎。常用的預訓練模型包括 BERT、GPT-3 等。根據任務需求設置微調參數,包括學習率、訓練輪次和批處理大小等。
在微調過程中,加載預訓練的模型和權重,并根據任務需求對模型進行必要的修改。選擇合適的損失函數和優化器,使用選定的數據集進行微調訓練。
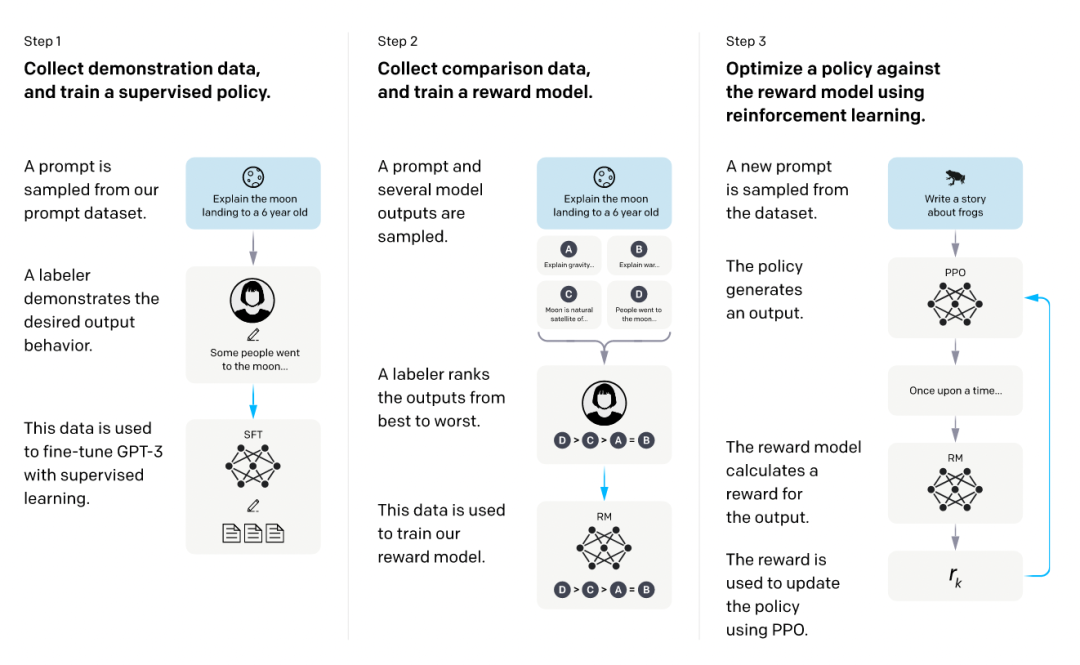
強化學習結合人類反饋(RLHF)是一種利用人類反饋作為獎勵信號來訓練強化學習模型的方法。通過這種方法,模型能夠更符合人類的偏好,提高文本生成的質量。
在這個過程中,首先使用監督數據微調語言模型,然后訓練獎勵模型評估文本質量。最終,通過強化學習訓練,模型在生成文本時能夠更好地符合人類的期望。
微調技術在多個領域得到了廣泛的應用。通過全量微調和參數高效微調(PEFT),模型可以適應不同的任務需求,達到更高的性能表現。全量微調適用于需要充分利用預訓練模型通用特征的場景,而PEFT則適用于資源有限的情況。
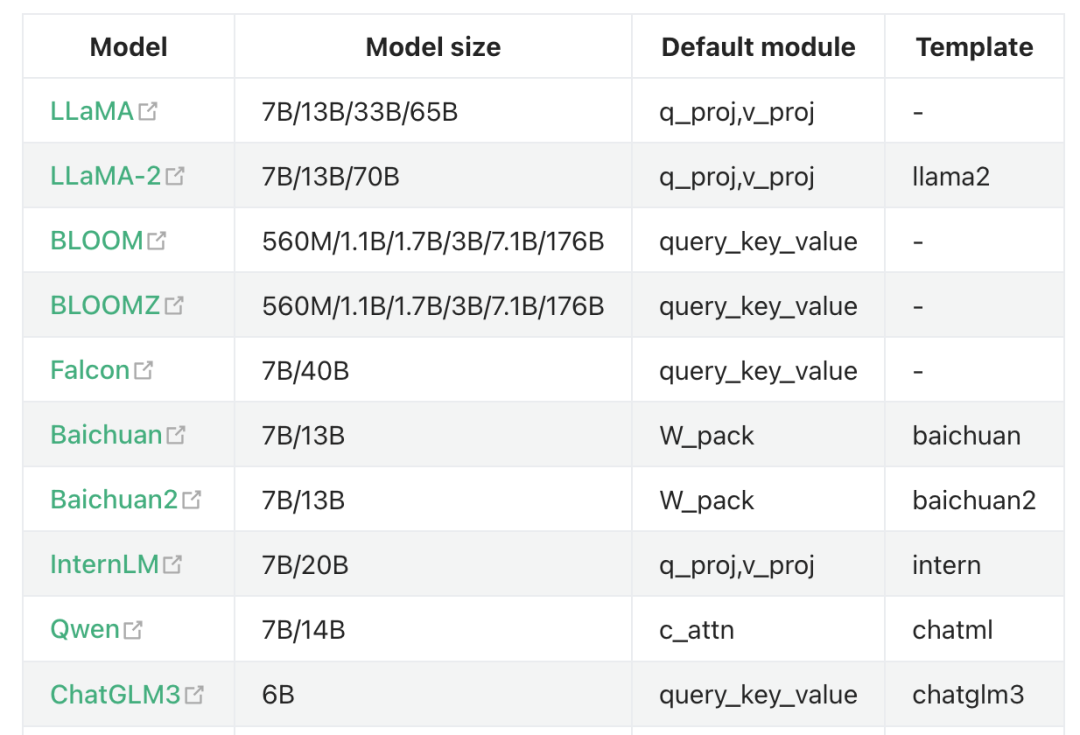
支持微調的模型眾多,包括BERT、GPT-3等。而數據集則是微調成功的關鍵,常用的數據集包括中文問答、情感分析、文本相似度和摘要生成等。
LLaMA-Factory 是一個全棧微調工具,支持海量模型和多種主流微調方法。通過這個工具,用戶可以進行快速實驗和模型驗證,顯著提高微調效率。
大模型微調是一個復雜但必要的過程,通過選擇合適的微調方法和工具,結合合理的數據集和超參數設置,可以顯著提升模型在特定任務上的表現。未來,隨著微調技術的不斷發展,其應用范圍和效果將更加廣泛和深入。
問:什么是大模型微調?
問:微調過程中需要注意哪些超參數?
問:有哪些常用的微調平臺?







