
AI聊天無敏感詞:技術原理與應用實踐
在Node.js中,Stream是一種處理流式數據的接口,可以將數據視為一系列的小塊(chunk),而不是一次性加載整個數據集到內存中。這對于處理大量數據,尤其是文件導出等操作非常有用。
在許多應用中,我們可能需要將數據庫中的數據導出到CSV、Excel或者其他格式的文件中。這通常涉及到大量的數據處理和流式寫入。
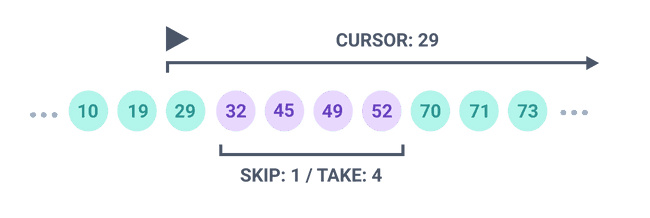
使用Prisma時,我們可以通過cursor-based pagination來有效地處理大量數據。這種方式不需要像offset-based pagination那樣加載大量數據到內存中。
const fetcher = (cursor) => prisma.model.findMany({
take: 1000,
skip: cursor ? 1 : 0,
cursor: cursor ? { id: cursor } : undefined,
});通過將數據源轉換為Readable stream,我們可以逐塊讀取數據,而不是一次性將所有數據加載到內存中。
const streamQuery = (fetcher) => {
let cursor;
return new Readable({
objectMode: true,
async read() {
const items = await fetcher(cursor);
if (items.length === 0) {
this.push(null);
} else {
for (const item of items) {
this.push(item);
}
cursor = items[items.length - 1].id;
}
},
});
};將數據流轉換為Excel格式,我們可以使用Transform stream。
const formatter = new Transform({
objectMode: true,
transform(chunk, _, callback) {
callback(null, [chunk.a, chunk.b, chunk.c]);
},
});
queryStream.pipe(formatter);最后,我們使用Writable stream將格式化后的數據寫入Excel文件。
import Excel from 'exceljs';
const exportToXlsxStream = (header) => {
const reader = new PassThrough();
const workbook = new Excel.stream.xlsx.WorkbookWriter({
stream: reader,
});
const worksheet = workbook.addWorksheet('exported');
const columns = header.map(h => ({ header: h, key: h }));
worksheet.columns = columns;
const writer = new Writable({
objectMode: true,
write(chunk, _, callback) {
worksheet.addRow(chunk).commit();
callback();
},
});
writer.on('finish', async () => {
worksheet.commit();
await workbook.commit();
});
return { reader, writer };
};通過使用Prisma和Stream,我們可以有效地處理和導出大量數據,這對于需要處理大數據量的應用尤為重要。Prisma的聲明式數據庫操作和Stream的流式數據處理能力,使得數據導出變得更加高效和可靠。

使用Prisma和Stream導出大量數據
Derek
2024-05-09






