
快速高效的語音轉(zhuǎn)文字工具:讓語音轉(zhuǎn)文字更簡(jiǎn)單
市場(chǎng)上有多種NER工具可供使用,以下是一些常用工具的簡(jiǎn)介:
HanLP是由大快搜索主導(dǎo)的開源NLP工具包,支持命名實(shí)體識(shí)別,并提供了豐富的API接口。
pip install pyhanlp
HanLP提供了高效的中文分詞功能,支持對(duì)文本進(jìn)行分詞處理。

可以通過API調(diào)用HanLP的各種功能,如關(guān)鍵詞提取、自動(dòng)摘要、依存句法分析等。
from pyhanlp import *
print(HanLP.segment('你好,歡迎在Python中調(diào)用HanLP的API'))
for term in HanLP.segment('下雨天地面積水'):
print('{}t{}'.format(term.word, term.nature))
近年來,隨著硬件計(jì)算能力的發(fā)展以及詞的分布式表示(word embedding)的提出,神經(jīng)網(wǎng)絡(luò)可以有效處理許多NLP任務(wù)。BiLSTM-CRF模型是目前基于深度學(xué)習(xí)的NER方法中的最主流模型。
BiLSTM-CRF模型主要由Embedding層、雙向LSTM層以及CRF層構(gòu)成,實(shí)現(xiàn)了端到端的NER任務(wù)處理。
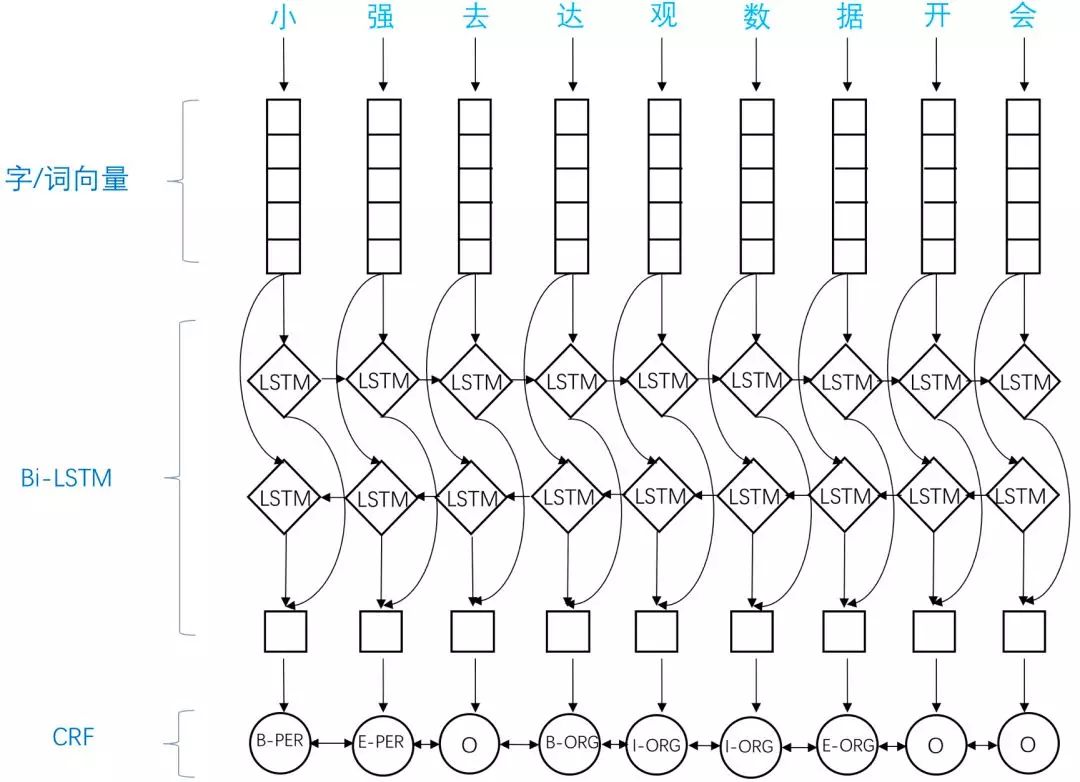
以下是一個(gè)簡(jiǎn)單的命名實(shí)體識(shí)別模型示例:
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
model = Sequential()
model.add(Embedding(16000, 256, input_length=80))
model.add(Bidirectional(LSTM(128, return_sequences=True), merge_mode="concat"))
model.add(Dense(128, activation='relu'))
model.add(Dense(9, activation='softmax'))NER技術(shù)在不斷發(fā)展,但仍面臨一些挑戰(zhàn):
命名實(shí)體識(shí)別(NER)是一種自然語言處理技術(shù),旨在從文本中識(shí)別和標(biāo)注具有特定意義的實(shí)體,如人名、地名、機(jī)構(gòu)名等。
NER常用的標(biāo)注方式包括BIOES和IOB等。這些標(biāo)注方式用于標(biāo)識(shí)實(shí)體的開始、中間、結(jié)束等位置。
NER廣泛應(yīng)用于信息提取、問答系統(tǒng)、機(jī)器翻譯和搜索引擎等領(lǐng)域,是NLP的重要基礎(chǔ)技術(shù)。
NER面臨的主要挑戰(zhàn)包括實(shí)體數(shù)量的不斷增加、構(gòu)詞的靈活性以及類別的模糊性等。
常用的NER工具包括HanLP、Stanford NER、NLTK等,這些工具提供了豐富的API和功能支持。
對(duì)比大模型API的內(nèi)容創(chuàng)意新穎性、情感共鳴力、商業(yè)轉(zhuǎn)化潛力
一鍵對(duì)比試用API 限時(shí)免費(fèi)





