
DeepSeek Janus-Pro 應用代碼與圖片鏈接實踐
AltDiffusion通過其獨特的多語言處理能力,能夠同時支持多達九種語言的輸入和輸出。這一特性得益于其在WuDao 和 LAION 數據集上的訓練,使得模型在中文和其他語言的語義理解上表現優異。AltDiffusion的多語言能力不僅體現在文本生成上,還在圖像生成和圖像-文本對齊任務中展現出強大優勢。
在AltDiffusion中,鍵模型遷移是實現多語言處理的重要技術。通過將源模型的知識遷移到目標模型上,AltDiffusion能夠在不增加計算復雜度的情況下顯著提升目標模型的性能。這種遷移通常是通過將一個模型的權重參數作為初始化參數傳遞給另一個模型來實現的。
鍵模型遷移技術的核心在于有效利用源模型的權重參數。在AltDiffusion的訓練過程中,源模型被稱為“鍵”模型,而目標模型則是“遷移”模型。通過這種方式,模型能夠在不同語言之間實現快速的語義遷移和知識共享。
import torch
source_model_weights = torch.load('source_model.pth')
target_model = MyModel()
target_model.load_state_dict(source_model_weights)多語言AltDiffusion在推理過程中,通過在模型內部表示中引入梯度噪聲,顯著提高了推理速度。這種方法不僅提升了模型的生成能力,還保證了輸出的多樣性和創造性。在多語言環境下,AltDiffusion能夠處理不同語言之間復雜的語義差異。
AltDiffusion的推理過程通過引入隨機擾動,生成更加多樣化的輸出。這一過程通過在模型的內部表示中施加梯度噪聲,實現了對多語言輸入的有效處理。推理速度的提高也使得AltDiffusion在實際應用中更具優勢。
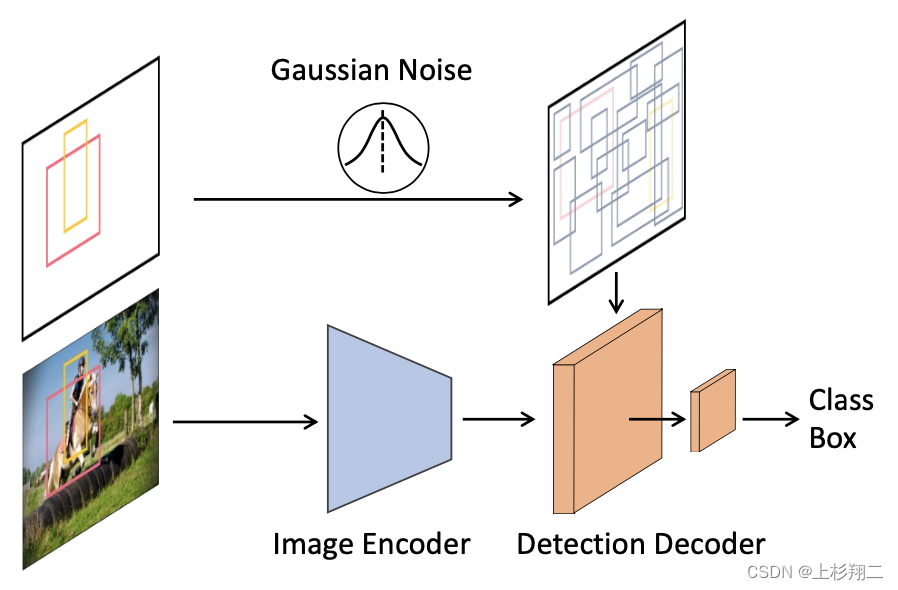
隨著AltDiffusion技術的不斷發展,它逐漸被應用于目標檢測任務中。通過將目標檢測視為一個去噪擴散過程,AltDiffusion能夠以更加靈活的方式處理檢測任務。其動態框設計使得模型能夠在不同的檢測場景中靈活調整精度和速度。
在目標檢測任務中,AltDiffusion通過將噪聲框逐步去噪為真實目標框,實現了對目標的精準識別。這一過程不僅提高了目標檢測的準確性,還顯著減少了模型的訓練時間。
def train_loss(images, gt_boxes):
"""
images: [B, H, W, 3]
gt_boxes: [B, *, 4]
"""
feats = image_encoder(images)
pb = pad_boxes(gt_boxes)
pb = (pb * 2 - 1) * scale
t = randint(0, T)
eps = normal(mean=0, std=1)
pb_crpt = sqrt(alpha_cumprod(t)) * pb + sqrt(1 - alpha_cumprod(t)) * eps
pb_pred = detection_decoder(pb_crpt, feats, t)
loss = set_prediction_loss(pb_pred, gt_boxes)
return lossAltDiffusion的應用不僅限于圖像生成和目標檢測,它在視頻生成領域同樣展現出強大的潛力。通過自回歸潛在擴散模型,AltDiffusion能夠生成連續幀的圖像,保證視頻內容的連貫性和高質量。
自回歸潛在擴散模型利用歷史幀的信息指導當前幀的生成,確保生成視頻的連續性和一致性。這一方法通過對每一幀進行獨立生成,大幅提升了視頻生成的靈活性。

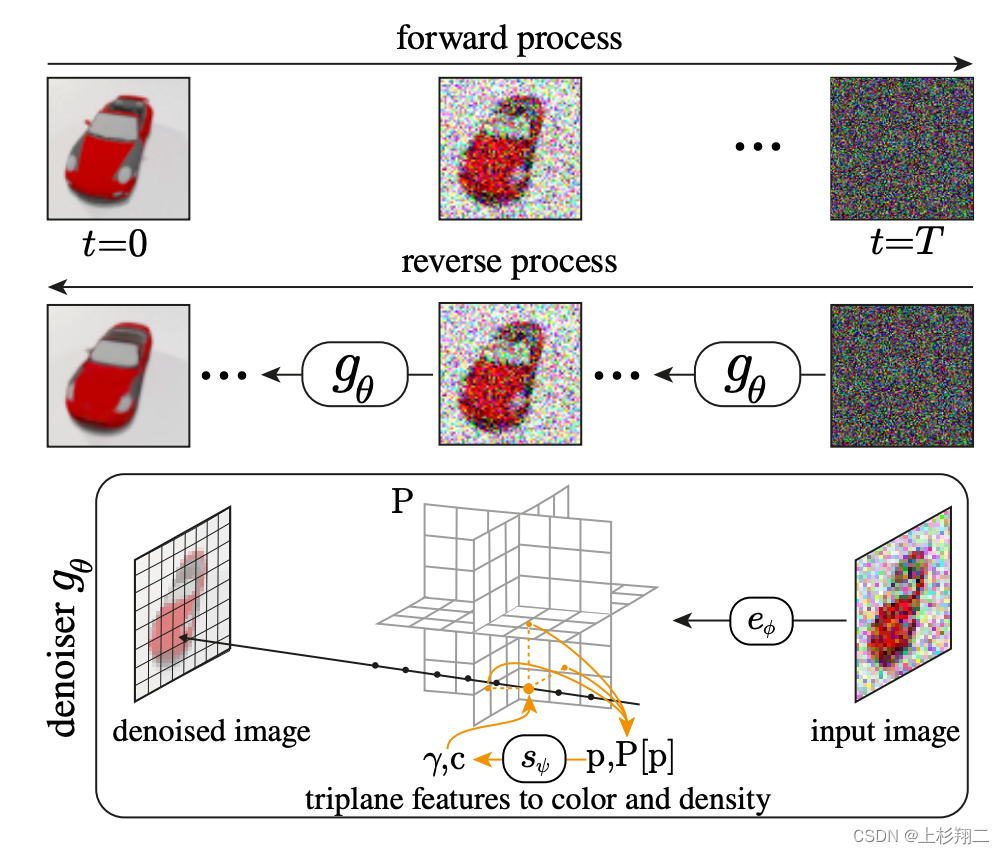
在3D場景生成領域,AltDiffusion通過將3D結構引入到傳統的2D擴散中,實現了3D場景的高效生成和推理。通過體積渲染,AltDiffusion能夠在每個去噪步驟中生成并渲染場景的中間三維表示。
AltDiffusion在3D場景生成中,通過在圖像去噪架構中引入3D表示,實現了對3D場景的高精度生成。體積渲染過程不僅提高了生成的真實感,還增強了模型的泛化能力。
隨著AltDiffusion技術的不斷完善,其應用領域將不斷擴展。未來,AltDiffusion將在更多的計算機視覺任務中展現出強大的潛力,為多語言環境下的應用提供更為高效的解決方案。
AltDiffusion的多語言處理能力和高效的推理速度,使其在多模態生成、圖像編輯等任務中具備廣闊的應用前景。隨著技術的不斷進步,AltDiffusion有望成為多語言環境下的標準推理方法。
問:AltDiffusion如何提升多語言處理能力?
問:AltDiffusion在目標檢測中有哪些優勢?
問:AltDiffusion是否可用于視頻生成?
問:如何在3D場景生成中應用AltDiffusion?
問:未來AltDiffusion的發展方向是什么?







