
DeepSeek Janus-Pro 應(yīng)用代碼與圖片鏈接實(shí)踐
這種獨(dú)特的步驟使eDiff-I對(duì)其生成的內(nèi)容有更強(qiáng)的控制。除了將文本生成圖像外,eDiff-I模型還有兩個(gè)功能——風(fēng)格轉(zhuǎn)移,允許使用參考圖像的風(fēng)格來控制生成的圖案的風(fēng)格,以及“用文字繪畫”,用戶可以通過在虛擬畫布上繪制分割圖來創(chuàng)建圖像,這個(gè)功能對(duì)于用戶創(chuàng)建特定場(chǎng)景的圖像非常方便。
擴(kuò)散模型的合成通常是通過一系列迭代去噪過程進(jìn)行的,這些流程通過隨機(jī)噪音逐漸生成圖像,在整個(gè)去噪過程中使用同一個(gè)去噪器神經(jīng)網(wǎng)絡(luò)。eDiff-I模型采用了另一種獨(dú)特的去噪方法,該模型在生成過程的不同時(shí)期內(nèi)訓(xùn)練專門用于去噪的去噪器集合。Nvidia將這種新的去噪網(wǎng)絡(luò)稱為“專家級(jí)去噪器”,并稱這一過程極大地提高了圖像生成的質(zhì)量。
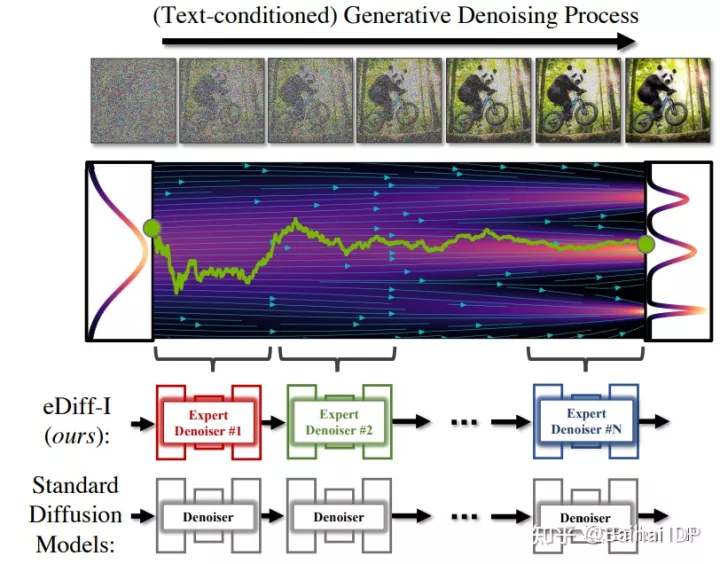
Deepgram的首席執(zhí)行官Scott Stephenson表示,eDiff-I提出的新方法可以被運(yùn)用到DALL-E或Stable Diffusion的新版本中,使合成圖像在質(zhì)量和控制能力方面取得重大進(jìn)步。Stephenson指出,這肯定會(huì)增加訓(xùn)練模型的復(fù)雜性,但在生產(chǎn)使用過程中并沒有明顯增加計(jì)算的復(fù)雜性。能夠分割和定義所產(chǎn)生的圖像的每個(gè)組成部分的樣子,可以加速圖像創(chuàng)作過程。這種方法能讓人和機(jī)器更加緊密地合作。
與其他同時(shí)期的產(chǎn)品如DALL-E 2和Imagen只使用單一的編碼器(如CLIP或T5)不同,eDiff-I的架構(gòu)在同一模型中使用兩個(gè)編碼器。這樣的架構(gòu)使eDiff-I能夠從相同的文本輸入中產(chǎn)生大量不同的視覺效果。
CLIP為創(chuàng)建的圖像提供了風(fēng)格化的效果,然而,輸出的圖像經(jīng)常遺漏文本信息。而使用T5文本嵌入創(chuàng)建的圖像可以根據(jù)文本信息產(chǎn)生更好的內(nèi)容。通過結(jié)合它們,eDiff-I產(chǎn)生了集成這兩種優(yōu)點(diǎn)的圖像。

開發(fā)團(tuán)隊(duì)還發(fā)現(xiàn),文本信息的描述性越強(qiáng),T5的表現(xiàn)就越比CLIP好,而且將兩者結(jié)合起來會(huì)產(chǎn)生更好的合成輸出。該模型還在標(biāo)準(zhǔn)數(shù)據(jù)集(如MS-COCO)上進(jìn)行了模型評(píng)估,表明CLIP+T5的trade-off曲線明顯優(yōu)于單獨(dú)的任何一種。根據(jù)Frechet Inception Distance(FID)——這是一種評(píng)估人工智能生成的圖像質(zhì)量的指標(biāo),eDiff-I的表現(xiàn)優(yōu)于DALL-E 2、Make-a-Scene、GLIDE和Stable Diffusion等競(jìng)爭(zhēng)對(duì)手。

Nvidia的研究稱,在對(duì)簡(jiǎn)單和詳細(xì)的文字說明生成的圖像進(jìn)行比較時(shí),DALL-E 2和Stable Diffusion都未能根據(jù)文字說明準(zhǔn)確合成圖像。此外,該研究發(fā)現(xiàn),其他生成模型要么會(huì)產(chǎn)生錯(cuò)誤的信息,要么忽略了一些屬性。同時(shí),eDiff-I可以在大量樣本基礎(chǔ)上正確地從英文文本中建立特征模型。
當(dāng)下文轉(zhuǎn)圖的擴(kuò)散模型可能使藝術(shù)表達(dá)大眾化,為用戶提供了產(chǎn)生細(xì)致和高質(zhì)量圖像的能力,而不需要專門技能。然而,它們也可以被用于進(jìn)行照片處理,以達(dá)到惡意目的或創(chuàng)造欺騙性或有害的內(nèi)容。
生成模型和AI圖像編輯的最新研究進(jìn)展對(duì)圖像的真實(shí)度和其他方面有著較大的影響。Nvidia表示,可通過自動(dòng)驗(yàn)證圖像真實(shí)性和檢測(cè)偽造的內(nèi)容來應(yīng)對(duì)此類挑戰(zhàn)。
目前大規(guī)模文轉(zhuǎn)圖生成模型的訓(xùn)練數(shù)據(jù)集大多未經(jīng)過濾,可能包含由模型捕獲并反映在生成數(shù)據(jù)中的偏差。因此,需要意識(shí)到基礎(chǔ)數(shù)據(jù)中的這種偏差,并通過積極收集更具代表性的數(shù)據(jù)或使用偏差校正方法來抵消偏差。
Stephenson指出,生成式人工智能圖像模型面臨著與其他人工智能領(lǐng)域相同的倫理挑戰(zhàn):訓(xùn)練數(shù)據(jù)的出處和理解它如何被用于模型中,大的圖像標(biāo)注數(shù)據(jù)集可能包含受版權(quán)保護(hù)的材料,而且往往無法解釋受版權(quán)保護(hù)的材料是如何(或是否)被應(yīng)用在最終生成出來的圖像的。
reVolt公司的創(chuàng)始人兼首席執(zhí)行官Kyran McDonnell表示,盡管現(xiàn)在的文轉(zhuǎn)圖模型已經(jīng)做得特別好,但還是缺乏必要的架構(gòu)來構(gòu)建正確理解現(xiàn)實(shí)所需的先驗(yàn)條件。他說:“有了足夠的訓(xùn)練數(shù)據(jù)和更好的模型,生成的圖像將能夠近似于現(xiàn)實(shí),但模型還是不會(huì)真正理解生成的圖像。在這個(gè)根本問題得到解決之前,我們?nèi)匀粫?huì)看到這些模型犯一些常識(shí)性錯(cuò)誤。”
McDonnell認(rèn)為,下一代文轉(zhuǎn)圖的架構(gòu),如eDiff-I,將解決目前的許多問題。他還說:“仍然會(huì)出現(xiàn)構(gòu)圖錯(cuò)誤,但質(zhì)量將類似于現(xiàn)在生成人臉的GANs,我們會(huì)在幾個(gè)應(yīng)用領(lǐng)域看到生成式AI的更多應(yīng)用。根據(jù)一個(gè)品牌的風(fēng)格和‘氛圍’訓(xùn)練出來的生成模型可以產(chǎn)生無限的創(chuàng)意,企業(yè)應(yīng)用的空間很大,而生成性式AI還沒有迎來它的‘輝煌時(shí)刻’。”

問:eDiff-I與其他文轉(zhuǎn)圖模型有何不同?
問:eDiff-I在圖像生成質(zhì)量上有什么優(yōu)勢(shì)?
問:生成式AI在應(yīng)用中面臨哪些挑戰(zhàn)?
問:未來的生成式AI發(fā)展方向是什么?
問:如何提高生成模型的訓(xùn)練數(shù)據(jù)質(zhì)量?
DeepSeek Janus-Pro 應(yīng)用代碼與圖片鏈接實(shí)踐

即夢(mèng)AI智能對(duì)話機(jī)器人:探索技術(shù)與應(yīng)用

Imagen 3 API 購(gòu)買與圖像生成技術(shù)的前景
AltDiffusion 應(yīng)用代碼的探索與實(shí)現(xiàn)

阿里通義 ModelScope API 申請(qǐng)指南

基于百度文心 ERNIE-ViLG 的 RAG 系統(tǒng)

阿里通義 ModelScope Agent 開發(fā)全解析

基于 DeepSeek Janus-Pro 的 RAG 系統(tǒng)

即夢(mèng)AI私人AI助手:創(chuàng)新賦能創(chuàng)意創(chuàng)作
對(duì)比大模型API的內(nèi)容創(chuàng)意新穎性、情感共鳴力、商業(yè)轉(zhuǎn)化潛力
一鍵對(duì)比試用API 限時(shí)免費(fèi)