
ChatGPT API 申請與使用全攻略
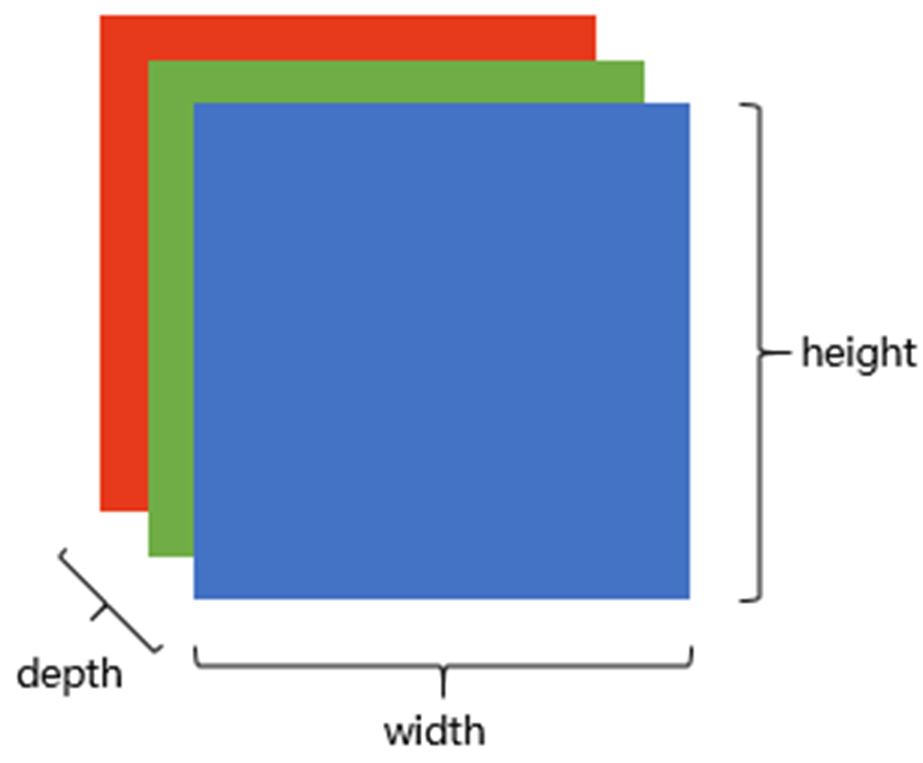
RGB顏色模型的每個通道都代表不同顏色的光強度。圖像在計算機中的存儲和處理依賴于這些通道信息。
傳統神經網絡在處理圖像時存在位置不變性的不足。如下圖所示,傳統網絡難以識別同一物體在不同位置的圖像。

卷積神經網絡通過卷積操作捕捉圖像的局部特征,實現了在位置變化下的識別不變性。

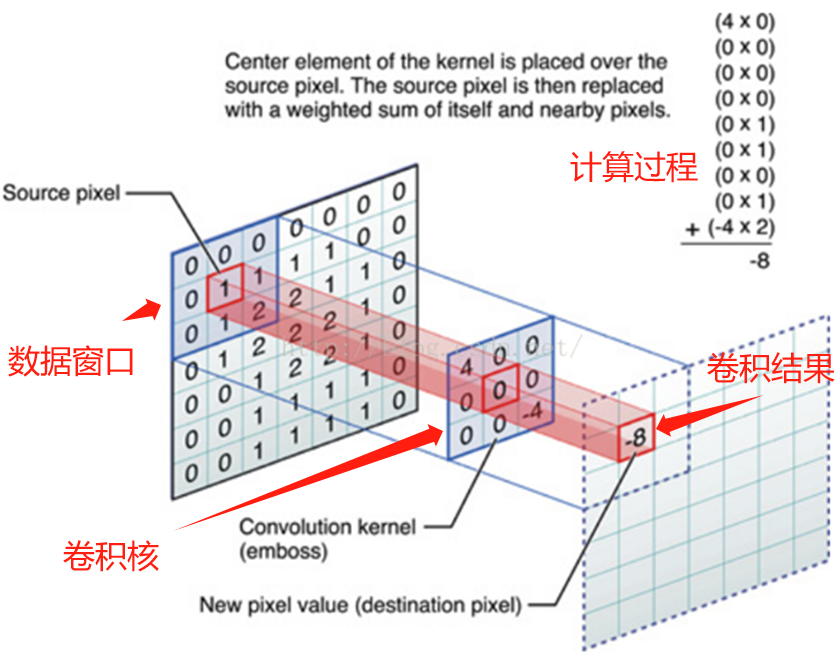
卷積操作是CNN的核心。它通過一個可移動的小窗口(稱為數據窗口),逐元素地與圖像進行相乘和相加操作。這個窗口也叫卷積核或濾波器,通過滑動窗口提取圖像特征。

數據填充確保卷積核覆蓋整個輸入圖像邊緣,同時保持輸出特征圖大小不變。例如,對于一個4×4的輸入圖像,使用3×3卷積核時,如果不進行填充,輸出特征圖會縮小。
input_image = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
]
padded_image = [
[0, 0, 0, 0, 0, 0],
[0, 1, 2, 3, 4, 0],
[0, 5, 6, 7, 8, 0],
[0, 9, 10, 11, 12, 0],
[0, 13, 14, 15, 16, 0],
[0, 0, 0, 0, 0, 0]
]
輸入層接收原始圖像數據,通常由三個顏色通道組成,形成一個二維矩陣,表示像素的強度值。
卷積層通過卷積核進行特征提取,然后應用激活函數(如ReLU)引入非線性,使網絡能夠學習復雜的特征。
池化層通過減小特征圖的大小來減少計算復雜性,通常通過選擇池化窗口內的最大值或平均值來實現。
CNN通常由多個卷積和池化層的堆疊組成,以提取更高級別的特征。
全連接層將提取的特征映射為最終輸出,如分類標簽或回歸值。
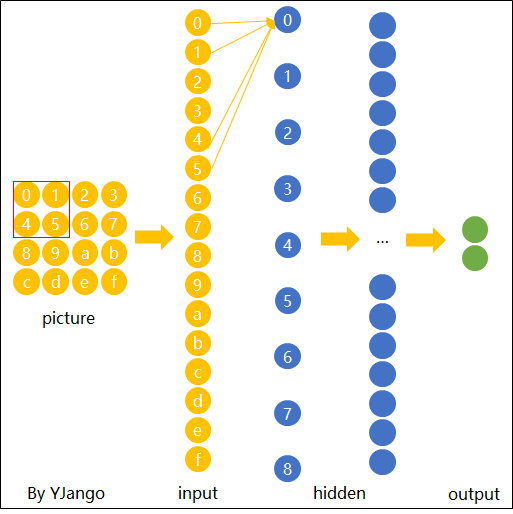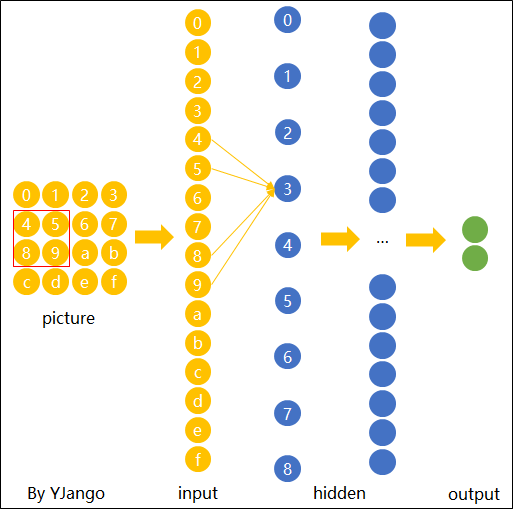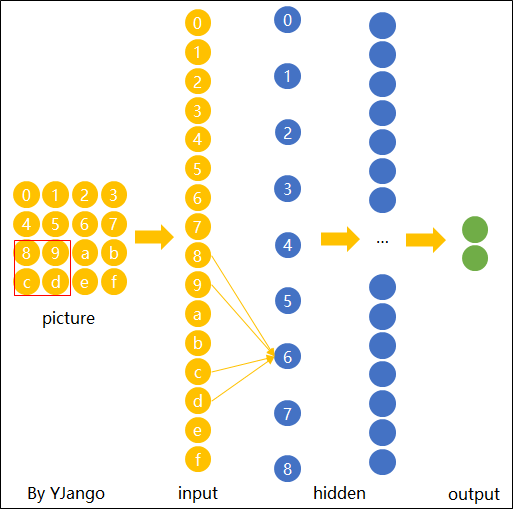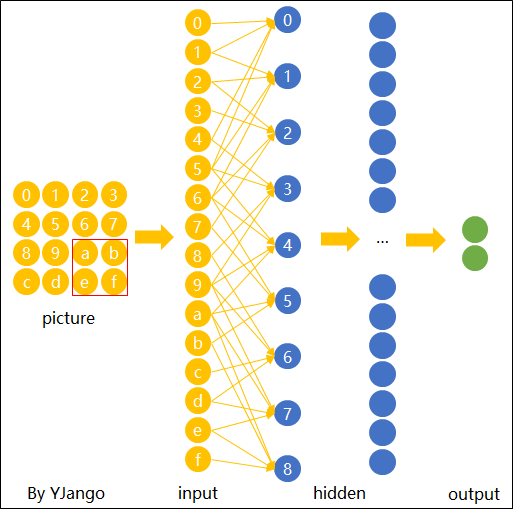
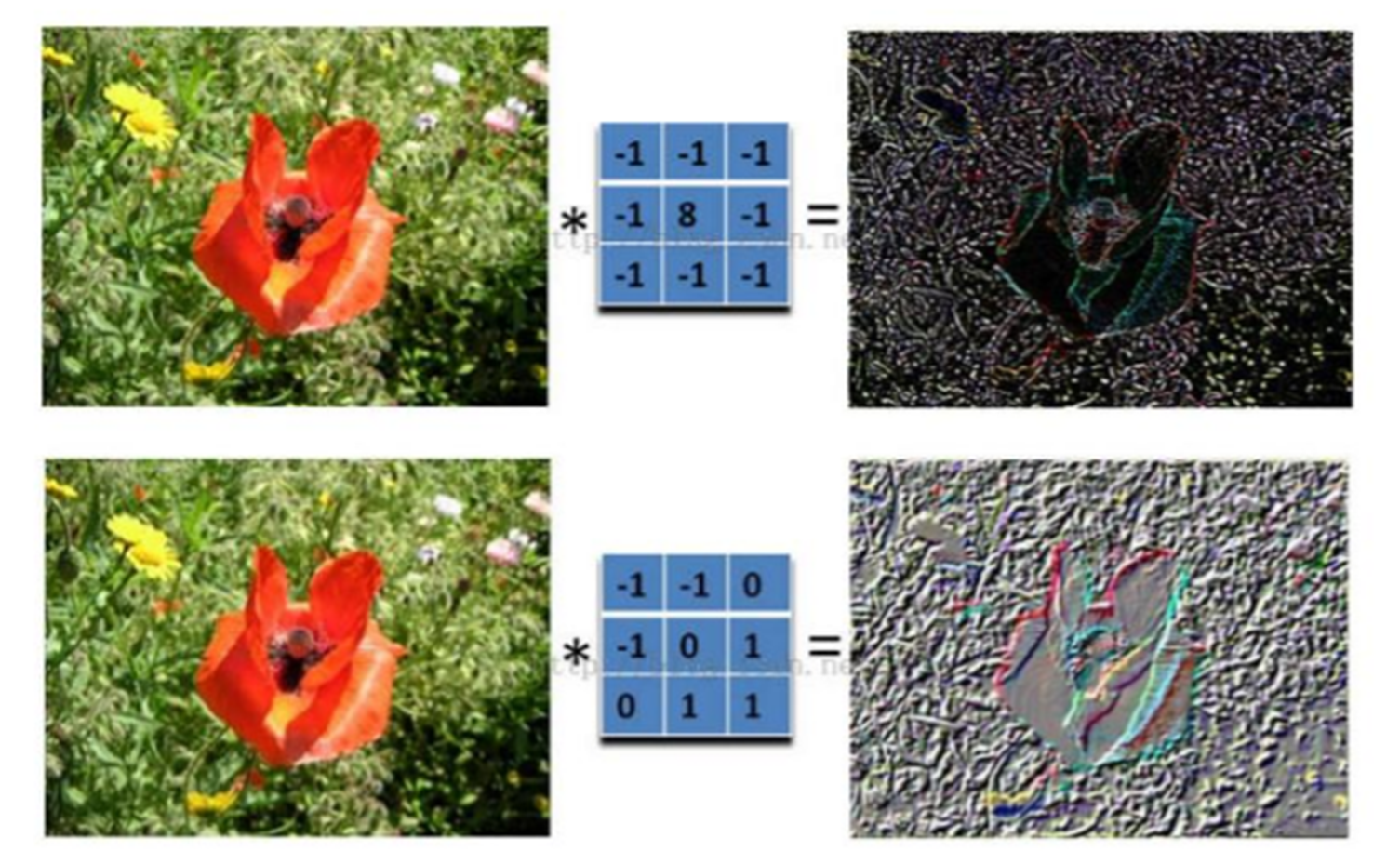
卷積神經網絡處理圖像后,可以提取出物體的輪廓特征,類似于人類視覺系統識別物體的方式。
問:什么是卷積神經網絡?
問:CNN的優勢是什么?
問:如何選擇卷積核的大小?
問:卷積神經網絡可以應用于哪些領域?
問:如何提高CNN的性能?




