
JSON 文件在線打開指南
Transformer的架構由編碼器和解碼器兩個部分組成。編碼器將輸入序列轉換為中間表示,解碼器則從中間表示生成輸出序列。每個編碼器和解碼器都由多個層組成,每一層包括多頭自注意力機制和前饋神經網絡。
編碼器的每一層由兩個子層組成:多頭自注意力機制和前饋神經網絡。解碼器在編碼器的基礎上增加了一個用于獲取編碼器輸出的注意力層。每個子層后都附有殘差連接和歸一化操作,確保信息流在網絡中順暢傳遞。

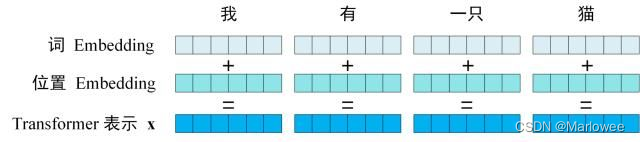
Transformer的輸入由單詞嵌入和位置嵌入相加而成。單詞嵌入可以通過預訓練獲得,位置嵌入則用于保留序列的位置信息。位置編碼的設計讓模型可以處理任意長度的序列,并保持對相對位置的敏感性。
Transformer的核心是注意力機制,尤其是自注意力。注意力機制可以看作是從輸入到輸出的全局依賴建模,允許模型在不使用循環結構的情況下捕獲序列間的依賴關系。
自注意力機制通過對輸入序列的每個位置計算查詢、鍵和值,然后通過點積計算注意力權重,最后加權求和得到輸出。這個過程不僅提高了并行計算能力,還使得模型能夠捕獲長程依賴關系。
import torch
import torch.nn.functional as F
class SelfAttention(torch.nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = torch.nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.nn.functional.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out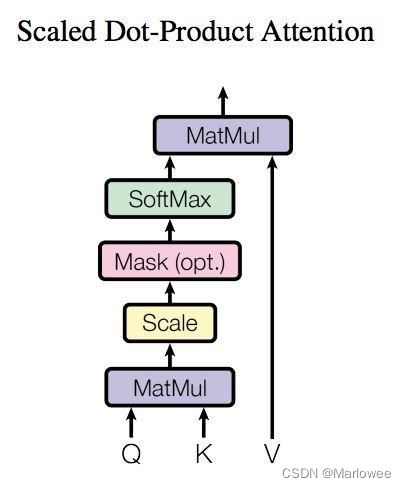
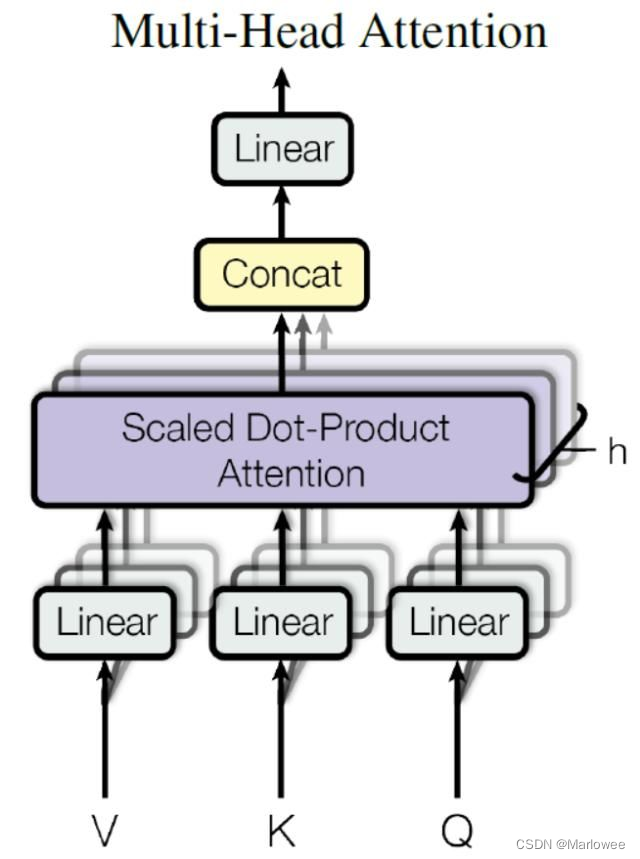
多頭注意力機制是自注意力的擴展。通過并行計算多個注意力頭,模型可以關注到不同的特征子空間,從而增強信息提取能力。每個頭的輸出經過拼接和線性變換,最終得到多頭注意力的結果。
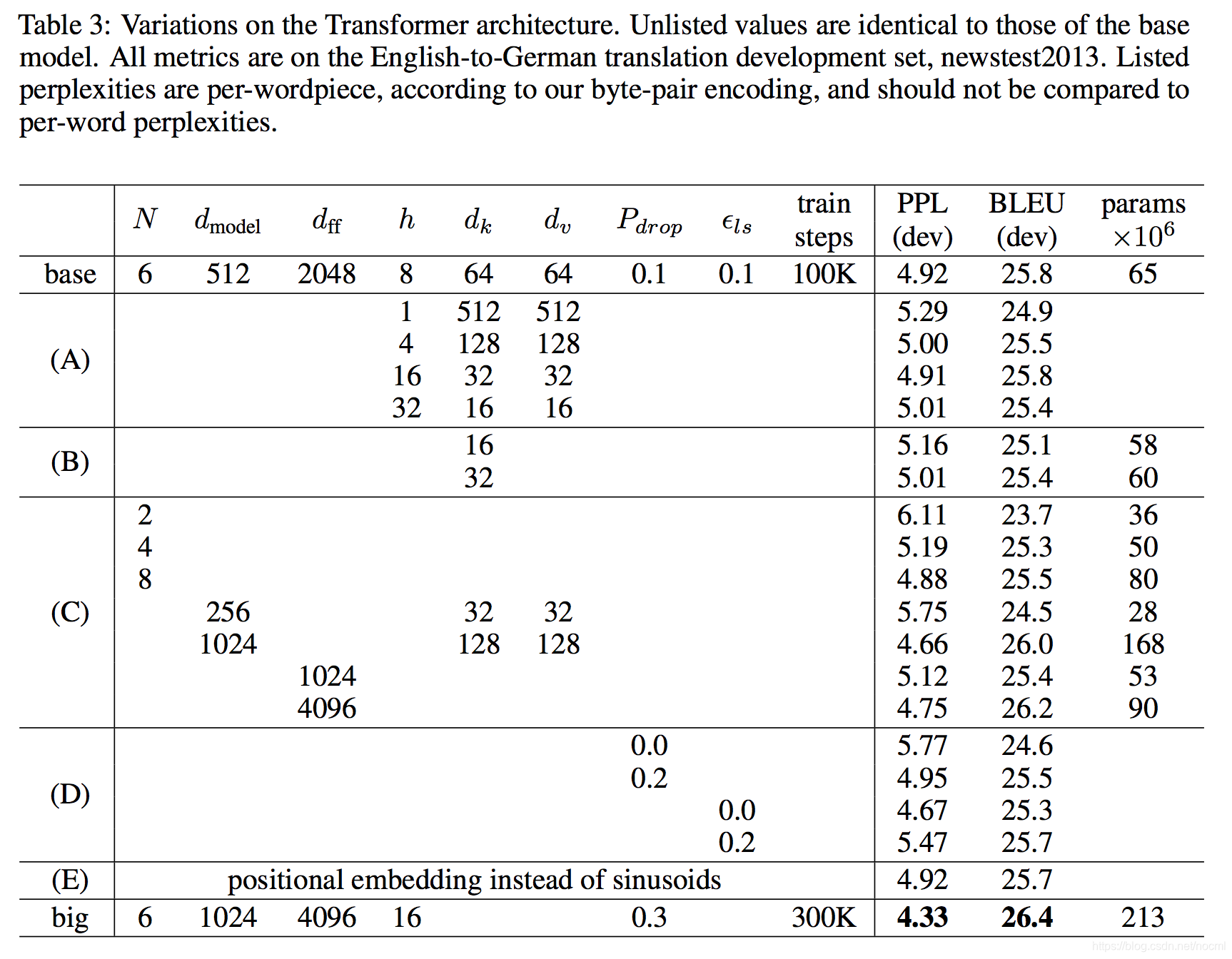
Transformer在機器翻譯任務中取得了顯著的成功,其優越的并行性和高效的訓練使得它在大規模數據集上表現出色。尤其是在WMT2014英語到德語和英語到法語的翻譯任務中,Transformer模型創造了新的基準。
在WMT2014英語-德語翻譯任務中,Transformer的BLEU評分達到28.4,超過了之前所有的模型。在WMT2014英語-法語任務中,Transformer的BLEU得分為41.0,同樣領先于其他模型。
Transformer不僅在NLP領域表現出色,其模型架構的靈活性使得它在其他任務中也有廣泛應用的潛力。未來,Transformer有望在圖像、音頻和視頻處理等領域中發揮更大的作用。
問:Transformer模型與傳統RNN相比有何優勢?
問:什么是多頭注意力機制?
問:Transformer能應用于哪些領域?
問:為什么Transformer在機器翻譯中表現優異?
問:如何提升Transformer的訓練效率?






