在DQN中,深度神經網絡用于學習狀態特征,進而預測每個可能動作的Q值。這使得DQN能夠在復雜的高維狀態空間中高效運作,特別是在游戲和機器人控制等領域表現出色。
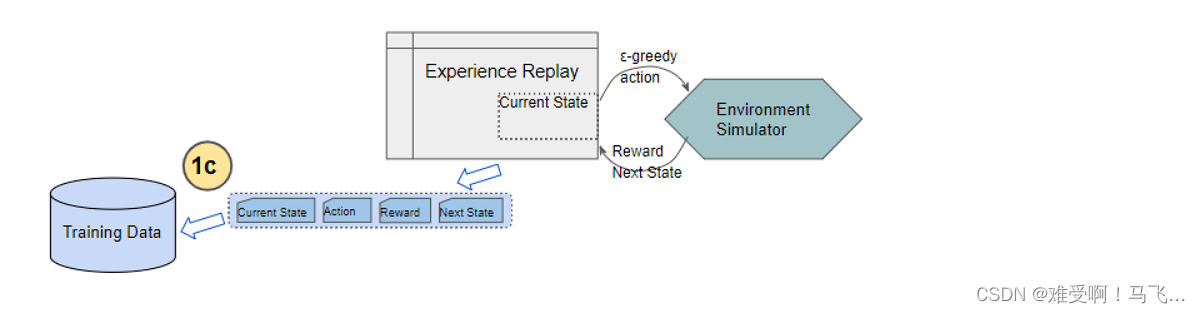
DQN中的經驗回放機制通過存儲智能體與環境的交互過程,打破了樣本之間的時間相關性。經驗回放庫中存儲了大量的歷史經驗,訓練時從中隨機抽取樣本,這樣的隨機化處理打破了樣本之間的相關性,有助于提高訓練的穩定性和效率。
經驗回放的另一個好處是能夠重復利用經驗,充分挖掘已有數據的價值。這種機制在資源有限的情況下尤為重要。
DQN使用兩個神經網絡:在線網絡和目標網絡。在線網絡用于選擇動作,而目標網絡用于計算目標Q值。目標網絡的參數并不會立即更新,而是在一定步數后與在線網絡同步。這種設計減少了目標Q值的波動,增強了訓練的穩定性。
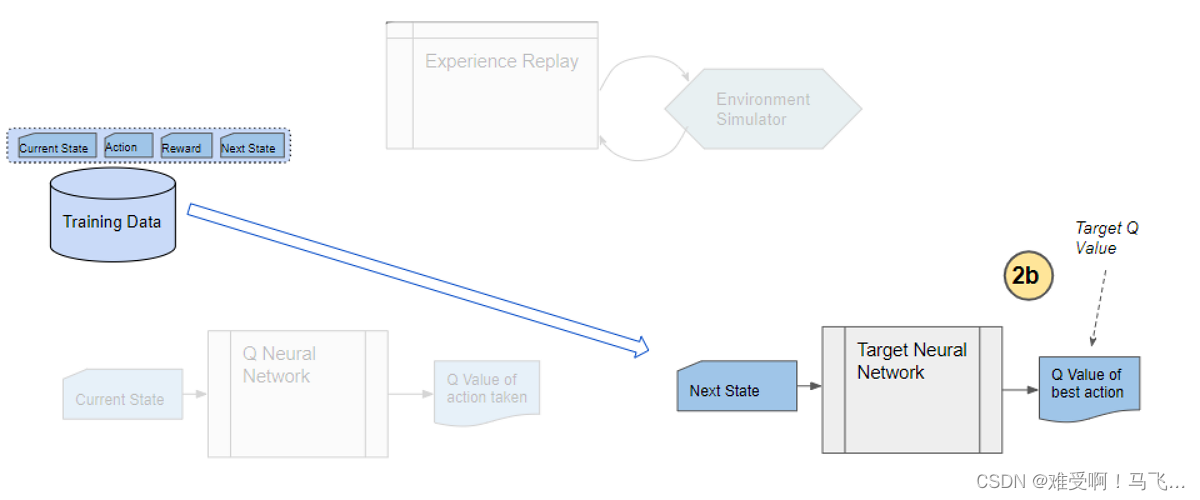
目標網絡的穩定性使得DQN在訓練過程中能夠逐漸逼近最優策略,而不是在不穩定的目標值上反復震蕩。
DQN的訓練過程包括以下幾個步驟:
初始化:初始化在線網絡和目標網絡,并創建經驗回放緩沖區。
選擇動作:使用ε-greedy策略選擇動作,確保在探索和利用之間保持平衡。
存儲經驗:將當前狀態、動作、獎勵和下一個狀態存儲到經驗回放緩沖區中。
更新網絡:從經驗回放緩沖區中隨機抽取樣本,計算目標Q值和預測Q值之間的誤差,并通過反向傳播更新在線網絡的參數。
同步網絡:每隔一定步數,將在線網絡的參數復制到目標網絡。
這種訓練過程的設計使得DQN能夠充分利用歷史經驗,穩定地逼近最優策略。
DQN在Atari 2600游戲中的表現令人矚目。通過學習像素級別的游戲畫面,DQN能夠在多個游戲中達到甚至超越人類玩家的水平。DQN的成功展示了深度強化學習在處理復雜視覺輸入和策略規劃中的潛力。

這種能力的實現得益于神經網絡對復雜特征的提取和強化學習策略的優化,DQN能夠在多樣化的游戲場景中表現出色。
以下是一個簡單的DQN代碼實現示例,使用Python和TensorFlow構建。
import numpy as np
import tensorflow as tf
class DeepQNetwork:
def __init__(self, n_actions, n_features, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9, replace_target_iter=300, memory_size=500, batch_size=32, e_greedy_increment=None, output_graph=True):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.learn_step_counter = 0
self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
tf.summary.FileWriter('logs/', self.sess.graph)
self.sess.run(tf.global_variables_initializer())
self.cost_his = []
def _build_net(self):
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s')
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target')
with tf.variable_scope('eval_net'):
c_names, n_l1, w_initializer, b_initializer = ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1)
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_eval = tf.matmul(l1, w2) + b2
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_')
with tf.variable_scope('target_net'):
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_next = tf.matmul(l1, w2) + b2以上代碼展示了如何構建一個簡單的DQN網絡,包括目標網絡和在線網絡的定義。神經網絡的結構可以根據具體任務進行調整。
盡管DQN在許多任務中表現出色,但仍然面臨一些挑戰,如樣本效率低、長時間依賴性等。為此,研究人員提出了多種改進方法,如雙DQN、優先經驗回放、A3C等,以進一步提高DQN的性能和穩定性。
這些改進方法在不同的應用場景中展現出良好的效果,使得DQN及其變種在研究和工業界廣泛應用。
問:DQN與傳統Q-learning的主要區別是什么?
問:DQN如何保證訓練的穩定性?
問:DQN能否應用于非視覺輸入的任務?
問:如何選擇DQN中的超參數?
問:DQN在實際應用中有哪些限制?
通過本文對DQN網絡的深入探討,希望能夠幫助讀者更好地理解其原理和實現,并在實際應用中有效利用這一強大的算法。