
獲取汽車品牌的API接口及圖片鏈接
GRPO(Gradient-based Reward Policy Optimization)是一種專門為強化學習設計的在線學習算法,旨在提高模型在復雜推理任務中的表現。它通過分階段的反饋機制,不斷優化模型的策略。
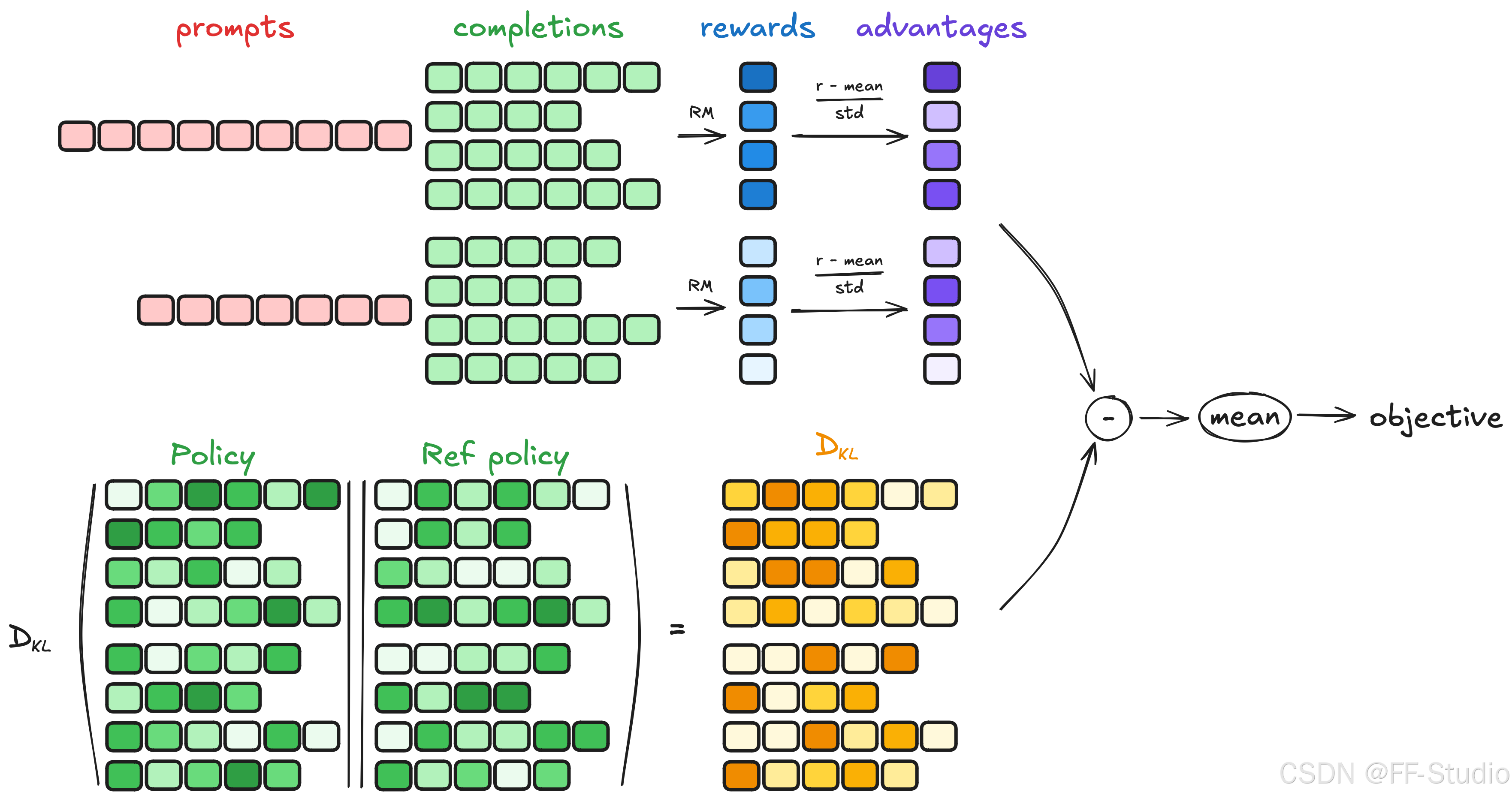
Hugging Face宣布的Open R1項目旨在填補DeepSeek未開源組件的空白。通過開源數據集和代碼,Open R1為全球開發者提供了復制和構建DeepSeek模型的機會。

在Open R1中,GRPO算法的實現是通過配置文件和腳本的結合來完成的。
配置文件confg_full.yaml中定義了模型參數和訓練設置,包括模型路徑、數據集名稱和訓練器參數等。
model_name_or_path: deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
model_revision: main
torch_dtype: bfloat16
dataset_name: AI-MO/NuminaMath-TIR
num_processes: 7使用accelerate工具執行GRPO訓練腳本,通過配置文件指定相關參數,實現模型的訓練和評估。
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/zero3.yaml --num_processes=7 src/open_r1/grpo.py --config recipes/qwen/Qwen2.5-1.5B-Instruct/grpo/confg_full.yamlDeepSeek不僅限于AI模型訓練,其靈活性和高效性使得它在數據庫擴展中也獲得了應用。
Duckdb-Extension是一個為DuckDB數據庫系統開發的擴展模塊,利用DeepSeek的推理能力來處理復雜的查詢操作。
頭文件quack_extension.hpp定義了擴展類,繼承自DuckDB的核心類。
class QuackExtension : public Extension {
public:
void Load(DuckDB &db) override;
std::string Name() override;
std::string Version() const override;
};源文件中實現了具體的擴展功能,如字符串處理函數和函數注冊。
inline void QuackScalarFun(DataChunk &args, ExpressionState &state, Vector &result) {
UnaryExecutor::Execute(
name_vector, result, args.size(), [&](string_t name) {
return StringVector::AddString(result, "Quack " + name.GetString() + " ??");
}
);
}隨著開源社區的推動,DeepSeek有望在更多領域發揮其潛力。從數據處理到AI推理,DeepSeek正在成為一種通用的解決方案。
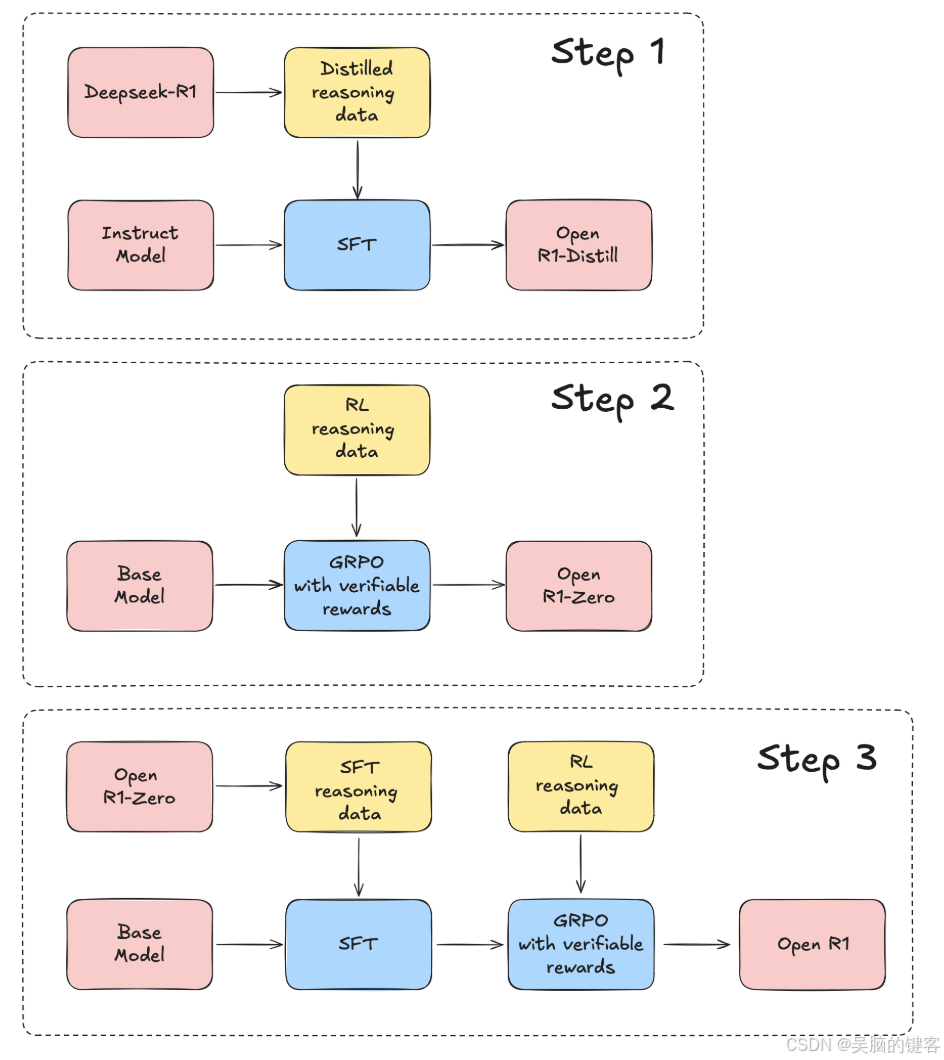
DeepSeek作為一種新興的AI推理模型,正在通過開源和社區合作不斷發展。其核心算法GRPO的應用不僅限于學術研究,還在實際工程中展現出巨大的價值。未來,隨著更多數據和技術的融入,DeepSeek將繼續引領AI領域的創新。
問:DeepSeek的核心算法是什么?
問:Open R1項目的目標是什么?
問:如何在Duckdb中應用DeepSeek技術?
問:DeepSeek未來的發展方向是什么?
問:如何獲取DeepSeek的源碼和文檔?







