
數據庫表關聯:構建高效數據結構的關鍵
線性數據和非線性數據的區別在于它們的模型擬合方式。線性數據可以使用簡單的直線方程進行擬合,而非線性數據則需要更復雜的方程或模型。為了準確捕捉非線性數據的模式,需要考慮使用多項式回歸或其他非線性回歸方法。
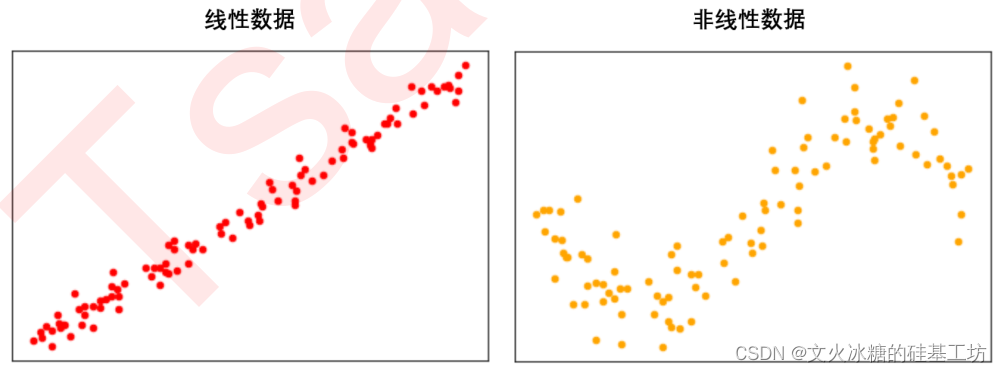
處理非線性數據時,通常有兩種主要方法:
特征轉換:例如,通過將特征平方增大其復雜性,使得數據在新的特征空間中呈現線性。
import numpy as np
X = np.array([-1+(1-(-1))*(i/10) for i in range(10)]).reshape(-1,1)
X2 = X**2使用非線性模型:例如,決策樹模型通過節點劃分數據空間,適合處理非線性數據。
非線性數據在機器學習中應用廣泛,特別是在分類和回歸問題中。許多實際問題都涉及復雜的非線性模式,例如圖像識別、語音識別和金融預測。
解決非線性問題的關鍵在于選擇合適的模型和特征轉換方法。通過對數據的深入分析和理解,可以選擇適當的模型和技術來處理非線性數據。
處理非線性數據是現代數據科學和機器學習中的重要課題。通過適當的特征轉換和模型選擇,可以實現對非線性數據的有效分析和預測。在實際應用中,需要根據具體問題靈活應用各種技術和工具,以獲得最佳結果。
問:什么是非線性數據?
問:如何判斷數據是否為非線性?
問:處理非線性數據的方法有哪些?




