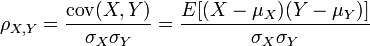
公式中,cov(X, Y)是X和Y的協方差,σX是X的標準差,μX是X的期望。
代碼示例:
a <- c(1, 2, 3)
b <- c(11, 12, 14)
cor.test(a, b, method="pearson")
圖示:為了形象化地理解皮爾遜相關系數,我們通常會使用散點圖來展示數據點的分布。
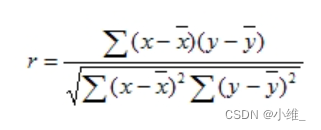
3:斯皮爾曼相關系數(Spearman Rank Correlation Coefficient)
斯皮爾曼相關系數是一種非參數的相關性分析方法,適用于對數據的等級順序進行分析。與皮爾遜相關系數不同,斯皮爾曼相關系數不需要數據呈正態分布,因而更適合于處理偏態數據或有序數據。
-
公式說明:斯皮爾曼相關系數的計算方式類似于皮爾遜相關系數,只需要將原始數據替換為排名數據。
-
代碼示例:
a <- c(1, 10, 100, 101)
b <- c(21, 10, 15, 13)
cor.test(a, b, method="spearman")
-
應用場景:斯皮爾曼相關系數廣泛應用于非線性關系的檢測,如在教育領域分析學生成績排名之間的相關性。
4:肯德爾相關系數(Kendall’s Tau Correlation Coefficient)
肯德爾相關系數用于衡量兩個變量之間的排序一致性。它通過計算和諧對與不和諧對的數量差,來判斷變量之間的相關性。
-
公式說明:
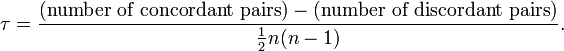
-
代碼示例:
a <- c(1, 2, 3)
b <- c(1, 3, 2)
cor.test(a, b, method="kendall")
-
應用場景:適用于小樣本數據和存在重復值的情況,常用于社會科學研究中。
5:多變量相關性分析
多變量相關性分析用于研究多個變量之間的關系。主成分分析(PCA)和因子分析是其中的常見方法,主要用于降維和識別主要相關性模式。
- PCA示例:通過PCA可以將高維數據降維,保留主要信息,有助于數據可視化和模型構建。
6:相關性分析在數據科學中的應用
在數據科學中,相關性分析是數據清洗和特征選擇的重要工具。它幫助數據科學家識別重要變量、消除多重共線性,提高模型的預測能力。
7:結論與未來展望
相關性分析為我們提供了一個強大的工具,可以幫助理解復雜數據集中的變量關系。隨著數據量和復雜性的增加,相關性分析將在大數據分析、機器學習和人工智能領域發揮更重要的作用。通過不斷發展和深化這些分析方法,我們將能夠從數據中獲取更豐富的洞察。
FAQ
-
問:相關系數的取值范圍是什么?
- 答:相關系數的取值范圍是-1到1。其中,1表示完全正相關,-1表示完全負相關,0表示無相關性。
-
問:如何選擇合適的相關系數分析方法?
- 答:選擇相關系數分析方法主要取決于數據的類型和分布。皮爾遜相關系數適用于正態分布的連續數據,斯皮爾曼和肯德爾相關系數適用于非正態分布或有序數據。
-
問:相關性分析與因果關系有何不同?
- 答:相關性分析僅揭示變量之間的關系強度和方向,并不表示因果關系。因果關系需要通過實驗設計和因果推斷來驗證。
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
3000+提示詞助力AI大模型
和專業工程師共享工作效率翻倍的秘密
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
久久久精品影视|
精品入口麻豆88视频|
风流少妇一区二区|
精品免费日韩av|
国内久久婷婷综合|
亚洲国产精华液网站w|
成人白浆超碰人人人人|
亚洲欧美怡红院|
91久久久免费一区二区|
丝袜美腿亚洲综合|
2014亚洲片线观看视频免费|
国产91精品露脸国语对白|
中文字幕在线观看不卡视频|
jlzzjlzz亚洲日本少妇|
亚洲乱码国产乱码精品精的特点
|
日韩欧美一区在线|
国产福利精品一区二区|
亚洲午夜视频在线|
久久久久久电影|
欧美怡红院视频|
日本成人在线看|
最近日韩中文字幕|
日韩欧美精品三级|
一本色道a无线码一区v|
久久综合综合久久综合|
一区二区三区精品在线观看|
久久综合资源网|
欧美无人高清视频在线观看|
国产真实精品久久二三区|
一区二区不卡在线播放|
国产女主播一区|
欧美电影精品一区二区|
欧美日韩精品一二三区|
91丝袜美腿高跟国产极品老师|
免费美女久久99|
亚洲黄一区二区三区|
久久综合久久综合久久综合|
欧美久久一二区|
色婷婷综合久久久|
99re热这里只有精品免费视频|
国产乱理伦片在线观看夜一区|
国产欧美一区二区精品秋霞影院|
国产乱码一区二区三区|
亚洲一区二区四区蜜桃|
亚洲免费资源在线播放|
久久精子c满五个校花|
精品剧情在线观看|
日韩欧美一区二区三区在线|
精品视频在线免费观看|
色婷婷综合视频在线观看|
av一区二区三区四区|
av亚洲精华国产精华精|
99久久精品免费看国产免费软件|
丰满亚洲少妇av|
eeuss鲁片一区二区三区在线观看|
国内久久精品视频|
国产成人亚洲精品青草天美|
国产一区二区精品久久|
国产九色sp调教91|
91在线免费看|
欧美亚洲国产一区在线观看网站
|
欧美精品久久一区二区三区|
欧美三级视频在线观看|
欧美电影一区二区三区|
欧美成人a视频|
日本一区二区视频在线|
一区二区三区四区乱视频|
日韩在线卡一卡二|
国产麻豆日韩欧美久久|
91丨porny丨蝌蚪视频|
欧美精选一区二区|
久久久不卡影院|
国产精品毛片a∨一区二区三区
|
国产精品网曝门|
亚洲狠狠丁香婷婷综合久久久|
亚洲福利一区二区三区|
国产一区激情在线|
欧美中文字幕一区|
久久综合久色欧美综合狠狠|
亚洲免费观看高清完整版在线观看熊|
午夜精品123|
国产99久久久国产精品免费看|
欧美综合天天夜夜久久|
久久看人人爽人人|
日产国产欧美视频一区精品|
97se亚洲国产综合自在线不卡|
日韩三级中文字幕|
一区二区三区欧美|
九九精品视频在线看|
欧美三级韩国三级日本一级|
久久久久久久久久久久电影|
亚洲成人激情社区|
av日韩在线网站|
久久综合九色综合久久久精品综合
|
色综合 综合色|
国产三区在线成人av|
日本三级亚洲精品|
欧美男人的天堂一二区|
亚洲欧洲一区二区三区|
成人h精品动漫一区二区三区|
精品国产乱码91久久久久久网站|
无码av中文一区二区三区桃花岛|
色综合亚洲欧洲|
中文字幕永久在线不卡|
国产做a爰片久久毛片|
日韩视频免费观看高清完整版
|
69成人精品免费视频|
又紧又大又爽精品一区二区|
av午夜一区麻豆|
17c精品麻豆一区二区免费|
国产高清久久久久|
中文字幕av一区二区三区免费看|
国产在线精品一区二区不卡了
|
欧美一二区视频|
日本不卡一区二区三区高清视频|
欧美在线色视频|
午夜激情久久久|
欧美一区二区性放荡片|
日韩高清不卡一区二区三区|
8x福利精品第一导航|
日韩精品电影在线观看|
欧美成人激情免费网|
韩国av一区二区三区|
国产日韩一级二级三级|
91在线精品秘密一区二区|
一区二区三国产精华液|
欧美日韩国产影片|
国产一区二区日韩精品|
中文字幕一区二区三区四区|
欧美日韩小视频|
国产成人精品亚洲午夜麻豆|
亚洲精选视频免费看|
欧美一区二区三区思思人|
久久99国内精品|
国产精品高潮呻吟久久|
欧美乱妇23p|
成人av在线一区二区三区|
亚洲一区二区三区精品在线|
日韩一区二区三区四区|
色婷婷精品久久二区二区蜜臂av
|
欧美变态tickling挠脚心|
不卡一二三区首页|
奇米777欧美一区二区|
18成人在线观看|
2欧美一区二区三区在线观看视频|
proumb性欧美在线观看|
激情综合色丁香一区二区|
日韩一区在线看|
国产视频一区不卡|
亚洲精品在线观|
欧美精品一级二级|
色偷偷一区二区三区|
成人av电影在线观看|
激情文学综合网|
免费观看91视频大全|
一区二区欧美在线观看|
自拍av一区二区三区|
亚洲国产精品二十页|
久久亚洲精华国产精华液|
91精品中文字幕一区二区三区|
色偷偷久久人人79超碰人人澡|
成人教育av在线|
国产成人av资源|
国产精品 日产精品 欧美精品|
亚洲一区二区三区美女|
亚洲精品久久7777|
亚洲欧美日韩国产成人精品影院
|
黄网站免费久久|
国产精品一区二区三区99|
久久精品国产免费|
蜜桃av噜噜一区|
激情国产一区二区|
国产一区二区三区黄视频|
久久福利资源站|
国产一区亚洲一区|
成人中文字幕在线|
97se亚洲国产综合自在线观|
94-欧美-setu|
欧美色窝79yyyycom|
欧美男女性生活在线直播观看|
欧美一区永久视频免费观看|
精品日韩一区二区|
国产午夜精品一区二区三区嫩草
|
成人综合婷婷国产精品久久免费|
欧美伦理影视网|
www.亚洲免费av|
色综合久久久网|
欧美性videosxxxxx|
精品视频1区2区|
欧美一级黄色大片|
久久久久久久久久久久电影
|
国产精品区一区二区三|
国产精品久久福利|
一区二区三区精品|
日产精品久久久久久久性色|
国产精品1区2区|
欧美四级电影在线观看|
久久久亚洲高清|
婷婷丁香久久五月婷婷|
成人深夜在线观看|