
數(shù)據(jù)庫(kù)表關(guān)聯(lián):構(gòu)建高效數(shù)據(jù)結(jié)構(gòu)的關(guān)鍵
Attention機(jī)制有多種變體,每種變體在不同的情境下展示出特有的優(yōu)勢(shì)。
硬性注意力只關(guān)注特定位置的信息,其選擇機(jī)制具有隨機(jī)性,難以通過反向傳播訓(xùn)練,需要強(qiáng)化學(xué)習(xí)方法。
這種變體中,Key和Value不再相同,通過這種方式可以更精確地控制信息流動(dòng)。
多頭注意力通過多個(gè)并行的注意力機(jī)制捕捉不同方面的信息,增強(qiáng)了模型的表達(dá)能力。
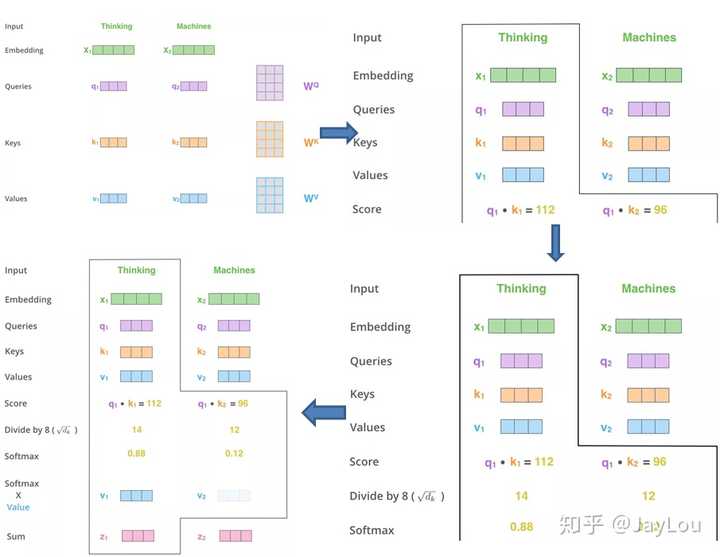
自注意力模型在處理長(zhǎng)距離序列時(shí)尤為強(qiáng)大,能夠動(dòng)態(tài)生成不同連接的權(quán)重,適應(yīng)變長(zhǎng)序列。
傳統(tǒng)的卷積和循環(huán)網(wǎng)絡(luò)在處理長(zhǎng)距離依賴時(shí)存在局部編碼問題,難以有效捕捉全局信息。
自注意力模型通過動(dòng)態(tài)生成權(quán)重,實(shí)現(xiàn)了對(duì)變長(zhǎng)序列的處理。這種模型利用Attention機(jī)制的動(dòng)態(tài)特性,彌補(bǔ)了傳統(tǒng)網(wǎng)絡(luò)的不足。
Transformer模型在NLP領(lǐng)域引發(fā)了革命,徹底改變了自然語(yǔ)言處理的方式。
Transformer由編碼器和解碼器組成,每個(gè)部分包含多個(gè)自注意力層和前饋神經(jīng)網(wǎng)絡(luò)。
編碼器負(fù)責(zé)將輸入序列轉(zhuǎn)換為特征表示,解碼器則根據(jù)編碼器的輸出生成目標(biāo)序列。
Transformer在GPT和BERT等預(yù)訓(xùn)練模型中得到了廣泛應(yīng)用,通過改進(jìn)提升了詞向量的表達(dá)能力。
在Transformer中,Encoder-Decoder注意力和自注意力機(jī)制各自發(fā)揮著重要作用,前者側(cè)重于源和目標(biāo)序列的交互,后者則在捕捉序列的內(nèi)部結(jié)構(gòu)上表現(xiàn)優(yōu)異。
注意力機(jī)制的引入極大地提升了神經(jīng)網(wǎng)絡(luò)處理信息的能力,尤其是在長(zhǎng)距離依賴和復(fù)雜任務(wù)中。通過理解和應(yīng)用不同類型的注意力機(jī)制,研究人員可以設(shè)計(jì)出更高效、更精確的深度學(xué)習(xí)模型。
問:注意力機(jī)制如何提升神經(jīng)網(wǎng)絡(luò)的效率?
問:什么是多頭注意力?
問:自注意力模型為何適合處理長(zhǎng)距離序列?
數(shù)據(jù)庫(kù)表關(guān)聯(lián):構(gòu)建高效數(shù)據(jù)結(jié)構(gòu)的關(guān)鍵

企業(yè)知識(shí)庫(kù)開源:探索開源知識(shí)庫(kù)系統(tǒng)的最佳選擇

探索拉格朗日乘數(shù)法:從基礎(chǔ)到應(yīng)用
伊利諾伊州天氣:極寒天氣的影響與應(yīng)對(duì)措施

冪:從古代數(shù)學(xué)到現(xiàn)代科學(xué)的演變

經(jīng)緯度怎么看:詳細(xì)操作教程
當(dāng)前天氣:技術(shù)實(shí)現(xiàn)與應(yīng)用指南
魯棒性與過擬合的關(guān)系:從理論到實(shí)踐
鍵.png)
如何高效爬取全球新聞網(wǎng)站 – 整合Scrapy、Selenium與Mediastack API實(shí)現(xiàn)自動(dòng)化新聞采集
對(duì)比大模型API的內(nèi)容創(chuàng)意新穎性、情感共鳴力、商業(yè)轉(zhuǎn)化潛力
一鍵對(duì)比試用API 限時(shí)免費(fèi)