YOLOv6的架構采用了CSPDarknet53作為骨干網絡,結合了空間金字塔池化(SPP)和路徑聚合網絡(PAN),增強了模型對不同尺度對象的檢測能力。此外,YOLOv6在訓練過程中引入了多尺度預測和IOU損失,進一步提升了小目標檢測的效果。
數據集準備與預處理
在進行YOLOv6訓練之前,準備一個高質量的數據集是至關重要的。我們的數據集專門為教室人員檢測設計,包含8557張圖像,分為訓練集、驗證集和測試集。通過自動定向處理,我們確保了所有圖像的方向一致。

數據集的預處理包括自動調整圖像分辨率至416×416像素。這一標準化處理雖然可能導致形狀畸變,但在實時檢測中,提高了處理效率。特別是在教室這種場景,模型需要適應多變環境,預處理步驟的標準化是保證檢測穩定性的關鍵。
系統界面與用戶體驗
我們的系統界面采用PySide6庫進行開發,提供了一個直觀的用戶操作環境。界面設計以用戶友好為目標,包括注冊登錄功能、圖片和視頻輸入支持,以及實時檢測結果顯示。
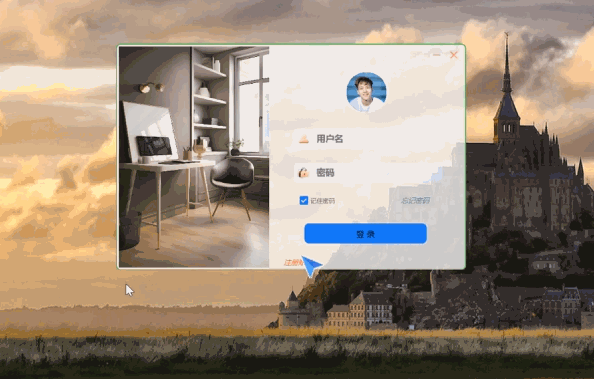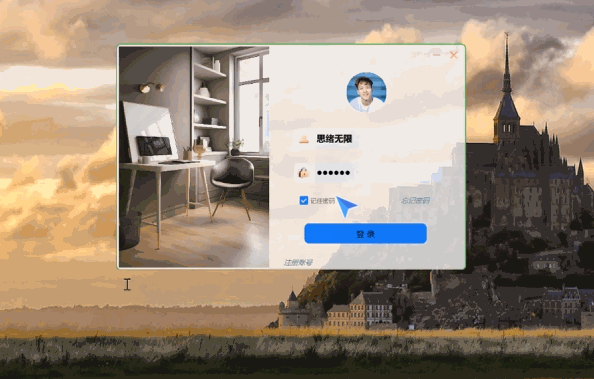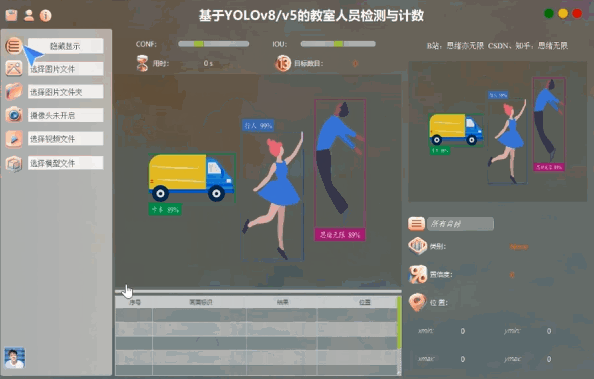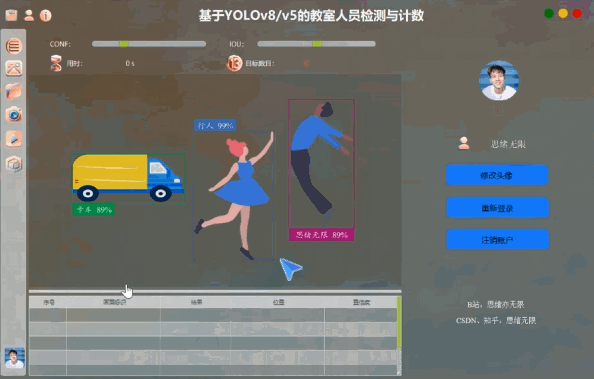
用戶可以通過圖形界面選擇不同的輸入源,如圖片、視頻或實時攝像頭,系統會自動處理輸入并顯示檢測結果。此外,用戶界面還支持一鍵切換YOLOv8/v5模型,滿足不同檢測需求。
YOLOv6訓練過程與準確率查看
在YOLOv6的訓練過程中,我們使用PyTorch框架,并通過配置YOLOv6模型的超參數來優化訓練效果。以下是YOLOv6訓練中重要的超參數及其設置:
- 學習率(lr0):0.01
- 學習率衰減(lrf):0.01
- 動量(momentum):0.937
- 權重衰減(weight_decay):0.0005
- 熱身訓練周期(warmup_epochs):3.0
- 批量大小(batch):16
- 輸入圖像大小(imgsz):640
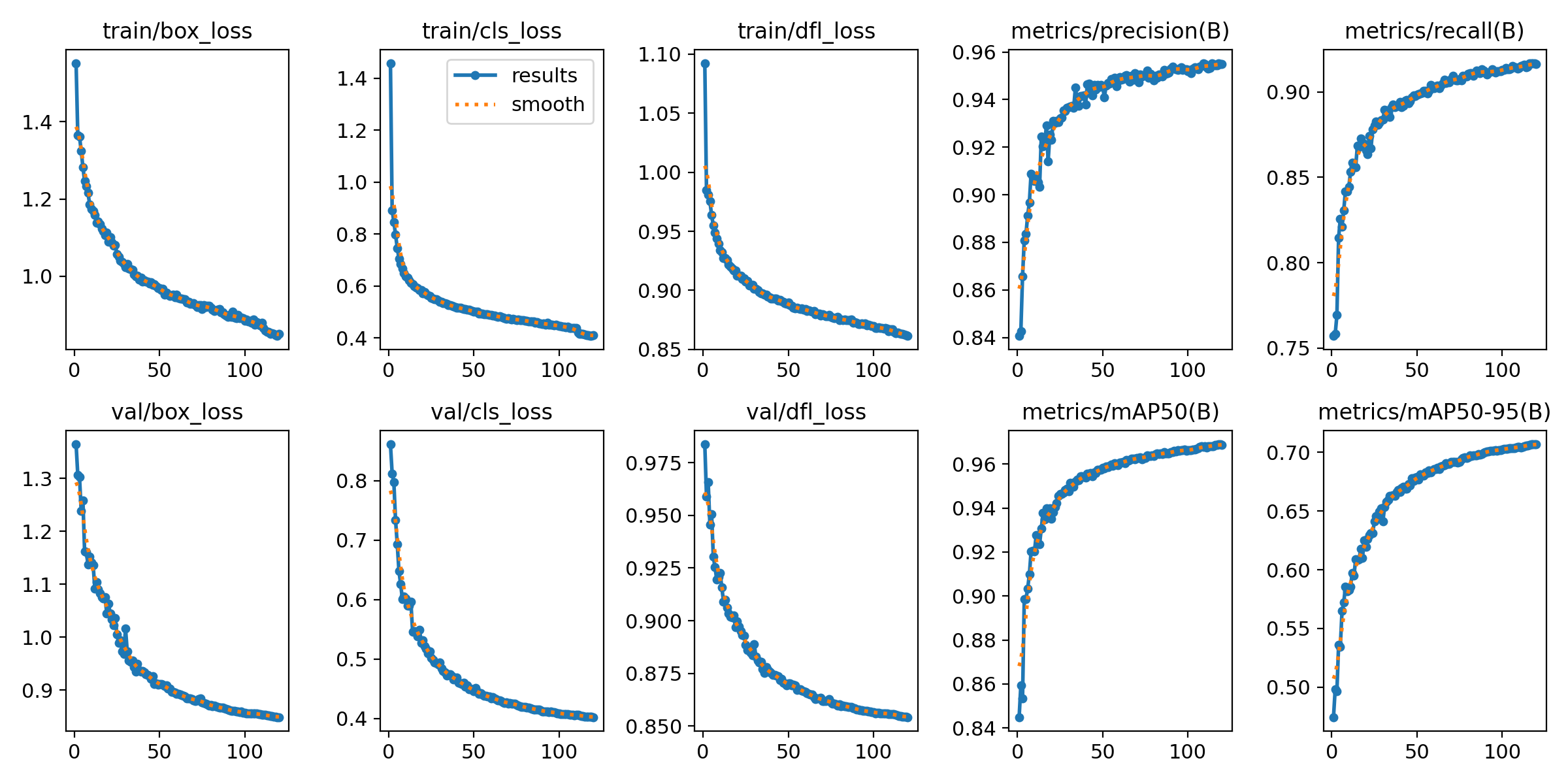
在訓練過程中,損失函數的變化是判斷模型學習效果的重要依據。通過分析“train/box_loss”、“train/cls_loss”和“train/obj_loss”,可以看到模型在訓練過程中逐漸學習并改善其對數據的理解。
YOLOv5、YOLOv6、YOLOv7和YOLOv8對比分析
在這部分,我們對比了YOLO系列模型在相同數據集上的性能。通過mAP和F1-Score兩個指標,分析了各版本的優缺點。YOLOv6在小目標檢測上的優勢使其在復雜場景中表現尤為出色。
| 模型 |
mAP |
F1-Score |
| YOLOv5nu |
0.966 |
0.93 |
| YOLOv6n |
0.933 |
0.89 |
| YOLOv7-tiny |
0.969 |
0.94 |
| YOLOv8n |
0.969 |
0.94 |
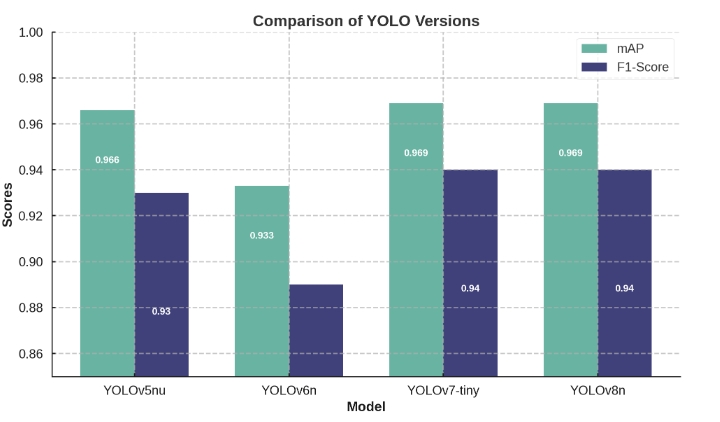
YOLOv7-tiny和YOLOv8n在性能上接近,顯示了YOLO系列的持續進步。隨著版本升級,模型的檢測能力不斷提升,特別是在精確率和召回率上的優化。
實現教室人員檢測與計數
在實現教室人員檢測時,我們采用了模塊化的系統設計思路,使得系統在界面層、處理層和控制層之間的協作更加緊密。處理層使用YOLOv8Detector類進行目標檢測,界面層提供用戶友好的操作界面,控制層負責協調用戶界面和處理器的交互。
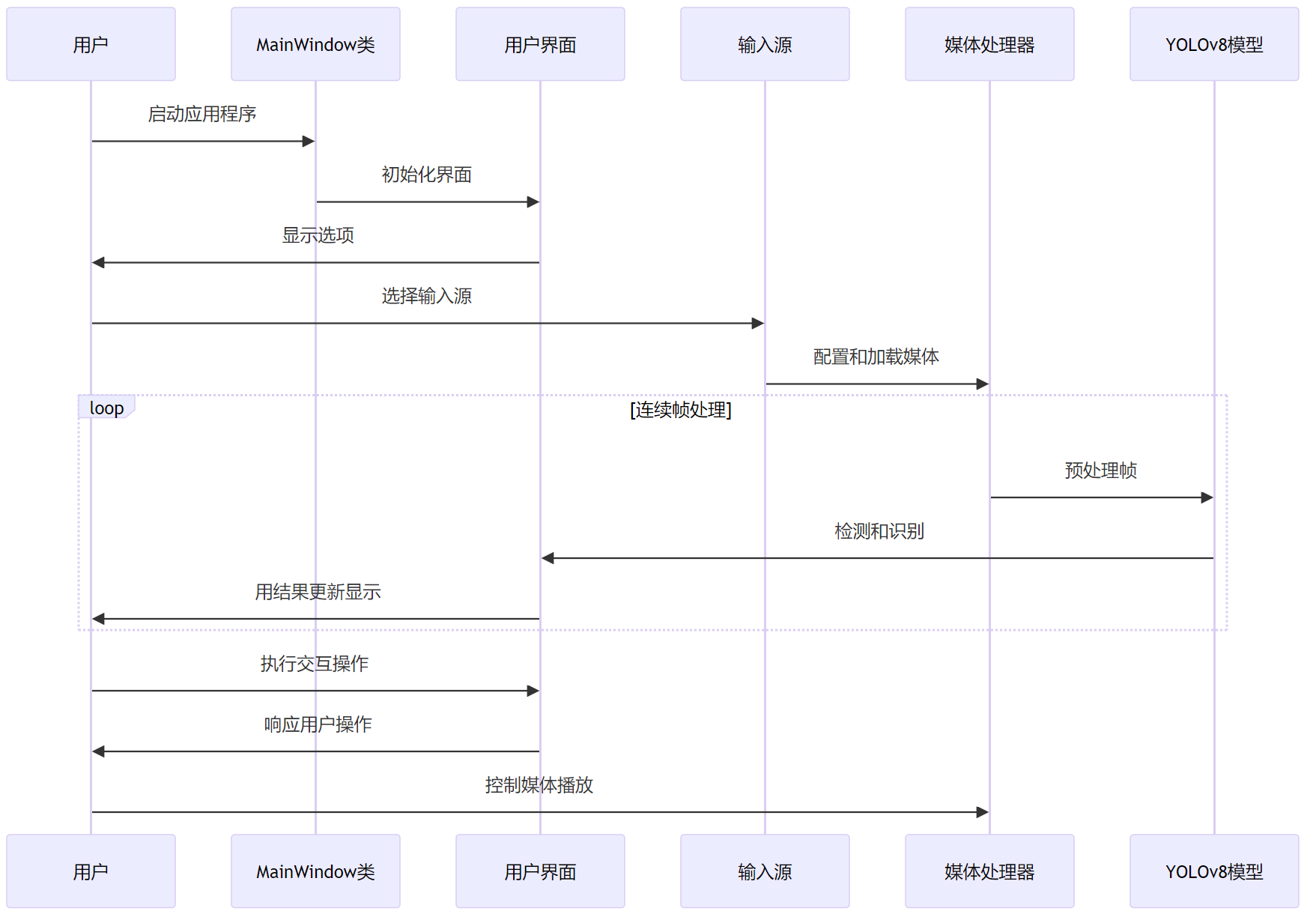
系統通過一系列槽函數和信號機制實現不同組件間的數據傳遞和事件觸發,確保用戶操作的實時響應。用戶可以通過界面觀看實時視頻流和檢測結果,并進行參數調整以優化檢測性能。
登錄與賬戶管理
系統的用戶管理功能基于SQLite數據庫和PySide6界面構建,確保用戶數據的安全存儲和便捷管理。用戶可以通過注冊界面創建賬戶,設置密碼并上傳頭像。賬戶管理功能包括密碼修改、頭像調整和賬戶注銷,提升了系統的安全性和用戶體驗。

下載鏈接與資源獲取
完整的代碼和資源包已上傳至博主的面包多平臺,讀者可通過以下鏈接獲取:
總結與展望
本文詳細介紹了基于YOLOv6的教室人員檢測與計數系統。通過合理的架構設計和用戶友好的界面,系統實現了高效的人員檢測。未來,我們計劃增加更多預訓練模型,優化界面設計,增強系統的個性化功能,以更好地滿足用戶需求。
FAQ
-
問:YOLOv6的主要優勢是什么?
- 答:YOLOv6在速度和準確性之間達到了良好的平衡,特別是在小目標檢測和遮擋場景下表現出色。
-
問:如何選擇合適的YOLO版本?
- 答:選擇YOLO版本應根據具體的任務需求和計算資源限制。如果資源有限,YOLOv7-tiny是個不錯的選擇;如果追求高性能,YOLOv8n是更佳選擇。
-
問:如何提高YOLOv6的檢測準確率?
- 答:可以通過調整超參數、增加訓練數據集、使用更高質量的標注數據來提高YOLOv6的檢測準確率。
-
問:系統支持哪些輸入源?
- 答:系統支持圖片、視頻、實時攝像頭和批量文件等多種輸入源,適應不同場景的檢測需求。
-
問:如何獲取完整的代碼資源?
- 答:完整的代碼和資源包可通過博主提供的下載鏈接獲取,具體鏈接見文中下載鏈接部分。
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
3000+提示詞助力AI大模型
和專業工程師共享工作效率翻倍的秘密
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
久久精品人人做人人综合|
久久久精品免费观看|
色狠狠桃花综合|
亚洲色图清纯唯美|
91啦中文在线观看|
亚洲制服丝袜一区|
欧美日本一道本|
视频一区二区三区入口|
日韩一本二本av|
国产精品18久久久久久久久|
国产日韩欧美不卡|
91丝袜美女网|
无码av免费一区二区三区试看
|
日韩精品免费视频人成|
欧美人与性动xxxx|
久88久久88久久久|
1024成人网色www|
69精品人人人人|
成人一区二区三区在线观看|
国产精品无人区|
欧美日本一区二区|
成人av片在线观看|
久久激情综合网|
一区二区三区蜜桃|
国产精品美女久久久久久久网站|
奇米色777欧美一区二区|
国产日本欧洲亚洲|
欧美一区二区三区成人|
成人av电影免费在线播放|
日本欧美一区二区三区|
亚洲人精品午夜|
久久久亚洲综合|
91精品国产综合久久久蜜臀图片|
国产美女精品人人做人人爽|
亚洲图片一区二区|
欧美激情一区在线观看|
欧美v国产在线一区二区三区|
色av成人天堂桃色av|
国产成人精品影院|
国产一区不卡视频|
久久99热狠狠色一区二区|
性做久久久久久免费观看欧美|
中文字幕精品在线不卡|
久久久国产综合精品女国产盗摄|
欧美精品一级二级|
欧美老人xxxx18|
欧美情侣在线播放|
欧美日韩国产另类不卡|
欧美色精品在线视频|
91热门视频在线观看|
99v久久综合狠狠综合久久|
国产91丝袜在线18|
成人动漫一区二区三区|
国产a久久麻豆|
成人av中文字幕|
在线一区二区三区|
制服丝袜一区二区三区|
欧美一级夜夜爽|
久久免费精品国产久精品久久久久|
精品国产污网站|
国产三级一区二区三区|
久久久久久久久久久99999|
精品国产91洋老外米糕|
91香蕉视频在线|
911国产精品|
精品99一区二区三区|
国产欧美日韩不卡|
亚洲一区日韩精品中文字幕|
亚洲午夜电影在线|
激情综合色综合久久|
一区二区三区中文在线观看|
亚洲国产一二三|
紧缚奴在线一区二区三区|
成人污视频在线观看|
一本色道亚洲精品aⅴ|
制服丝袜成人动漫|
久久久国产精品麻豆|
亚洲老妇xxxxxx|
老司机精品视频线观看86|
成人黄色免费短视频|
久久精品国产网站|
色一情一乱一乱一91av|
精品乱码亚洲一区二区不卡|
亚洲视频在线观看一区|
蜜桃在线一区二区三区|
91视频一区二区三区|
日韩精品一区二区三区在线观看|
亚洲视频中文字幕|
看电视剧不卡顿的网站|
欧美日韩激情一区二区|
成人免费视频在线观看|
国产一区二区调教|
欧美一区二区三区视频在线观看|
一色桃子久久精品亚洲|
精品在线视频一区|
777久久久精品|
午夜精品久久久久久久久久
|
亚洲图片另类小说|
国产精品一区不卡|
精品国偷自产国产一区|
午夜精品久久一牛影视|
色婷婷久久一区二区三区麻豆|
久久久综合九色合综国产精品|
日韩高清欧美激情|
欧美日韩在线观看一区二区
|
精品国产免费人成电影在线观看四季|
亚洲人精品一区|
成人在线视频一区|
国产精品蜜臀在线观看|
国产精品一区二区久激情瑜伽|
3d动漫精品啪啪一区二区竹菊|
一区二区成人在线观看|
欧美伊人久久久久久久久影院|
亚洲综合色视频|
欧美精品免费视频|
奇米影视一区二区三区小说|
日韩一区二区免费高清|
久久精品国产99久久6|
日韩午夜av电影|
国产不卡免费视频|
亚洲精品老司机|
亚洲人成精品久久久久|
美国av一区二区|
久久久久成人黄色影片|
成人污视频在线观看|
综合av第一页|
91麻豆精品国产自产在线观看一区|
亚洲在线观看免费|
91精品一区二区三区在线观看|
日韩精品1区2区3区|
精品粉嫩aⅴ一区二区三区四区|
国产一区二区三区四|
国产精品三级久久久久三级|
色噜噜狠狠一区二区三区果冻|
日韩精品一二区|
国产精品色哟哟网站|
欧美日韩日日夜夜|
国产精品亚洲成人|
午夜精品久久久久久久久|
国产三级欧美三级日产三级99|
色88888久久久久久影院按摩|
天堂精品中文字幕在线|
久久综合国产精品|
欧美在线小视频|
国产乱色国产精品免费视频|
亚洲欧美日韩国产另类专区|
日韩一区二区在线播放|
91视频一区二区|
国产精品18久久久久久vr|
亚洲制服丝袜av|
国产欧美久久久精品影院|
欧美丰满美乳xxx高潮www|
99视频超级精品|
国产专区欧美精品|
毛片av一区二区|
日韩精品高清不卡|
亚洲精品视频在线看|
国产清纯在线一区二区www|
日韩欧美中文一区|
欧美一区二区三区爱爱|
日本高清视频一区二区|
99精品视频中文字幕|
丁香啪啪综合成人亚洲小说|
久久99久久久欧美国产|
日本成人中文字幕在线视频|
亚洲线精品一区二区三区|
亚洲精品伦理在线|
亚洲日本在线a|
亚洲精选一二三|
亚洲欧美乱综合|
亚洲三级电影网站|
亚洲一区二区三区自拍|
一区二区三区国产豹纹内裤在线|
中文字幕一区二区三区四区|
亚洲欧美在线高清|
亚洲男人电影天堂|
一区二区三区在线观看动漫|
亚洲色图视频网|
午夜在线电影亚洲一区|
亚洲成人综合视频|
欧美日韩国产综合一区二区|
91日韩在线专区|
在线观看视频一区二区欧美日韩|
色网站国产精品|
在线播放欧美女士性生活|
欧美大肚乱孕交hd孕妇|
国产亚洲欧洲997久久综合|
中文字幕精品在线不卡|
亚洲精品免费在线|
蜜臀av性久久久久蜜臀aⅴ流畅
|
一本大道综合伊人精品热热
|
日韩精品一区二区三区在线|
欧美高清www午色夜在线视频|
麻豆91精品91久久久的内涵|
欧美变态tickle挠乳网站|
欧美一级在线观看|
不卡影院免费观看|
国产精品色在线|
欧美精品粉嫩高潮一区二区|
亚洲成人av福利|