
使用PRAW庫與RedditAPI進行數據交互
Claude 3 Opus是目前最智能的模型,在多個評測基準上超越同行,包括本科和研究生水平的知識測評。它在復雜任務中表現出接近人類的理解和流暢性。
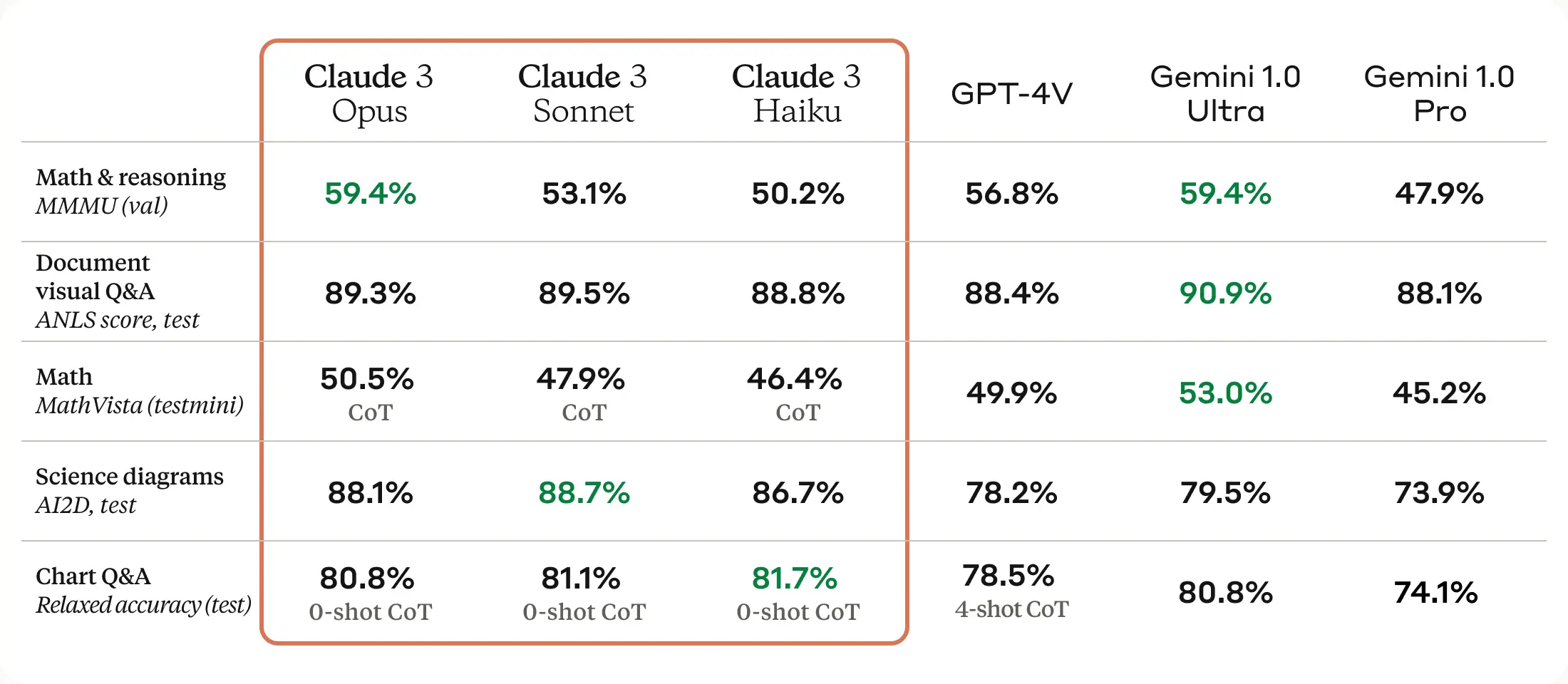
Claude 3模型擁有先進的視覺處理能力,可處理照片、圖表、圖形和技術圖表。這對于企業用戶來說尤其重要,因為很多知識庫以PDF、流程圖和幻燈片格式存在。
Claude 3支持上傳base64編碼的圖片,推薦使用WebP格式以減少存儲空間。對于大尺寸圖片,先將其resize到1568像素以下,可以減少API調用時的流量。
以下是一個在Amazon Bedrock上調用Claude 3模型的完整代碼示例,包含圖片類型檢查、轉換及編碼。
import io
import base64
import json
import httpx
from PIL import Image
import boto3
AVAILABLE_FORMAT = {"jpeg", "png", "gif", "webp"}
MAX_SIZE = 1568
def preprocessing_image(image_url, target_format=None, re_encoding=False):
image_data = httpx.get(image_url).content
image_pil = Image.open(io.BytesIO(image_data))
image_format = image_pil.format.lower()
target_format = target_format if target_format else image_format
if target_format not in AVAILABLE_FORMAT:
target_format = "webp"
re_encoding = re_encoding or (target_format != image_format)
width, height = image_pil.size
max_size = max(width, height)
if max_size > MAX_SIZE:
width = round(width * MAX_SIZE / max_size )
height = round(height * MAX_SIZE / max_size )
image_pil = image_pil.resize((width, height))
re_encoding = True
if re_encoding:
buffer = io.BytesIO()
image_pil.save(buffer, format=target_format, quality=75)
image_data = buffer.getvalue()
image_base64 = base64.b64encode(image_data).decode("utf-8")
return image_base64, target_format在API請求中,圖像最好放在文本之前,這樣Claude 3在處理時效果最佳。以下是API請求的示例:
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": image_media_type,
"data": image_data,
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
]Claude 3一次最多處理20張圖,可以利用編號進行區分。多張圖的API請求示例如下:
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Image 1:"
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": image1_media_type,
"data": image1_data,
},
},
{
"type": "text",
"text": "Image 2:"
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": image2_media_type,
"data": image2_data,
},
},
{
"type": "text",
"text": "How are these images different?"
}
],
}
]Claude 3模型可以用于商品標簽生成,為特定任務生成標注標簽。通過詳細描述圖片內容,Claude 3能夠生成更精確的標簽。

Claude 3能夠分析視頻,通過拆幀將視頻內容轉化為圖片進行處理。
def parsing_video(video_path):
container = av.open(video_path)
stream = container.streams.video[0]
stream.codec_context.skip_frame = "NONKEY"
images = []
for index, frame in enumerate(container.decode(stream)):
if index > 20:
break
images.append(frame.to_image())
return imagesClaude 3模型在智能能力、響應速度和跨模態處理能力上都取得了顯著突破,為用戶提供了一系列優質的AI助手選擇。無論是圖像處理、視頻分析還是復雜文本處理,Claude 3都展示了其強大的潛力。




