
文心一言寫代碼:代碼生成力的探索
RAG 系統(tǒng)的核心在于如何高效地檢索相關(guān)文檔并生成高質(zhì)量的文本。為了實(shí)現(xiàn)這一點(diǎn),RAG 系統(tǒng)通常包括以下兩個(gè)階段:
在檢索階段,系統(tǒng)根據(jù)輸入的問題從知識(shí)庫中尋找相關(guān)信息。知識(shí)庫可以是一個(gè)結(jié)構(gòu)化的數(shù)據(jù)集,也可以是大量文檔的集合。通過關(guān)鍵詞匹配或向量相似度計(jì)算,RAG 系統(tǒng)能夠快速找到與問題相關(guān)的文檔。這一過程的準(zhǔn)確性直接影響到生成階段的效果。
在獲取到相關(guān)文檔后,RAG 系統(tǒng)將這些信息輸入到大語言模型中,生成最終的回答。大語言模型通過結(jié)合用戶問題和檢索到的文檔,生成符合邏輯且詳細(xì)的回答。這一過程需要模型具備強(qiáng)大的理解和生成能力。
火山引擎提供的豆包(Doubao)模型是一種強(qiáng)大的大語言模型,適用于 RAG 系統(tǒng)的構(gòu)建。通過火山引擎的云搜索服務(wù)與豆包模型的結(jié)合,可以搭建出高效的智能問答平臺(tái)。
在火山引擎的平臺(tái)上,首先需要配置云搜索服務(wù)。這一步驟包括創(chuàng)建 OpenSearch 實(shí)例,配置 CPU/內(nèi)存比例,并啟用語義嵌入模型。通過這些配置,可以確保系統(tǒng)具備高效的信息檢索能力。
在完成云搜索服務(wù)的配置后,接下來是豆包模型的部署。在火山引擎方舟控制臺(tái)中,可以創(chuàng)建模型推理接入點(diǎn),選擇適合的豆包模型版本,并獲取 API Key。這些配置將用于后續(xù)的推理服務(wù)調(diào)用。
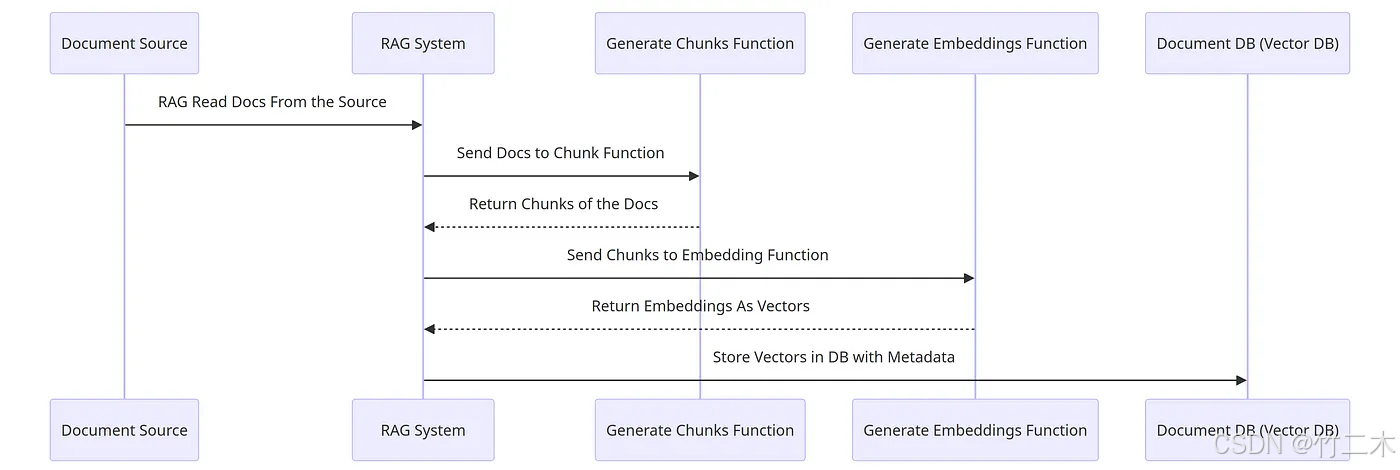
為了提高檢索效率,RAG 系統(tǒng)通常會(huì)將文檔轉(zhuǎn)化為向量存儲(chǔ)在知識(shí)庫中。向量化的過程包括將文檔分塊、轉(zhuǎn)換為向量,并存儲(chǔ)到數(shù)據(jù)庫中。
文檔的分塊可以根據(jù)段落、句子等粒度進(jìn)行,分塊后的文檔塊通過 Embedding 模型轉(zhuǎn)化為向量。將這些向量存儲(chǔ)在 Elasticsearch 等數(shù)據(jù)庫中,可以大大提高檢索效率和準(zhǔn)確性。
from langchain_elasticsearch import ElasticsearchStore
elastic_vector_search = ElasticsearchStore(
embedding=embeddings,
index_name="langchain_index",
es_url=ES_URL,
es_api_key=ES_API_KEY,
)一旦用戶提交問題,RAG 系統(tǒng)將問題轉(zhuǎn)化為向量,并在知識(shí)庫中進(jìn)行相似度檢索。檢索到的文檔將與用戶問題組合生成新的 prompt,輸入到豆包模型中生成回答。
retriever = elastic_vector_search.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.6, "k": 3}
)
retrieved_documents = retriever.invoke("新興項(xiàng)目與突破")為了實(shí)現(xiàn)私有網(wǎng)絡(luò)中的實(shí)例與公網(wǎng)的連接,需要配置 NAT 網(wǎng)關(guān)。通過 NAT 網(wǎng)關(guān),系統(tǒng)可以安全地訪問豆包模型的推理服務(wù)。
通過選擇適合的模板代碼,可以將語料導(dǎo)入至云搜索服務(wù)中。語料的管理和處理是智能問答系統(tǒng)構(gòu)建的重要環(huán)節(jié)。
在完成配置后,可以啟動(dòng) RAG 推理服務(wù)。在 VPC 環(huán)境的 ECS 中,通過調(diào)用 RAG 模型的信息驗(yàn)證推理任務(wù),確保系統(tǒng)正常運(yùn)行。
通過 API 網(wǎng)關(guān),為 RAG 推理服務(wù)配置固定的公網(wǎng)域名,用戶可以通過瀏覽器直接訪問推理服務(wù)并進(jìn)行問答咨詢。這種配置提高了系統(tǒng)的可用性和用戶體驗(yàn)。
答:可以通過優(yōu)化知識(shí)庫的結(jié)構(gòu),使用更高效的向量檢索算法,以及不斷更新知識(shí)庫中的信息來提升檢索效率。
答:豆包模型作為大語言模型,在 RAG 系統(tǒng)中負(fù)責(zé)生成階段,通過結(jié)合檢索到的文檔和用戶問題生成高質(zhì)量的回答。
答:可以通過配置 NAT 網(wǎng)關(guān)、使用安全的 API Key 管理,以及監(jiān)控系統(tǒng)訪問日志來確保系統(tǒng)的安全性。
答:RAG 系統(tǒng)適用于需要高準(zhǔn)確性和實(shí)時(shí)性的信息檢索和回答生成的場景,如智能客服、在線教育、知識(shí)管理等。
答:通過使用高質(zhì)量的知識(shí)庫、提高檢索算法的準(zhǔn)確性,以及優(yōu)化生成模型的訓(xùn)練數(shù)據(jù),可以有效減少“幻覺”問題的發(fā)生。
對(duì)比大模型API的內(nèi)容創(chuàng)意新穎性、情感共鳴力、商業(yè)轉(zhuǎn)化潛力
一鍵對(duì)比試用API 限時(shí)免費(fèi)





