TruLens通過引入反饋函數(Feedback Function),以編程方式評估LLM應用的輸入、輸出和中間結果的質量。反饋函數就像是一個個的打分器,幫助我們判斷應用在哪些方面表現良好,哪些方面需要改進。以Groundedness評估為例,它通過對比Response和Context,判斷答案是否基于知識庫生成,實現更為準確的評價。
在RAG知識問答項目中,TruLens提供了四種主要的評估方式:
Groundedness評估主要用于檢測LLM的“幻覺”現象,即生成的回答是否真的基于知識庫中的信息。通過分析Response中的句子在Context中的存在證據,TruLens可以判斷回答的可靠性。
Answer Relevance評估側重于判斷Response與Query的相關性。即便答案較長或較短,評估標準都應保持一致,確保答案的相關性和準確性。與問題相關的回答可獲得更高的得分。
Context Relevance評估用于判斷召回的知識是否與Query相關。通過對比召回內容與問題的匹配程度,TruLens能有效識別知識庫中的冗余信息,提升召回效率。
Groundtruth評估通過將Response與標準答案進行對比,評估答案的準確性。評分標準為1到10之間的整數,越接近正確答案得分越高。
使用TruLens進行評估測試非常簡單,只需按照以下步驟進行操作:
通過定義RAG_from_scratch類,連接RAG應用,并為函數添加裝飾器@instrument,以便記錄輸入輸出。使用Claude作為評估模型,定義反饋函數進行評估。
class RAG_from_scratch:
@instrument
def retrieve(self, query: str) -> list:
results = self.call_remote_service(query, retrieve_only=True)
return [result['doc'] for result in results]運行測試后,通過run_dashboard()生成鏈接,查看測試結果和詳細分數。
在實際應用中,我們可以使用TruLens對不同版本的提示詞模板進行效果測試。例如,在對比Template v1和Template v2時,通過TruLens的得分明細,我們可以清晰地看到哪個版本的模板效果更佳。
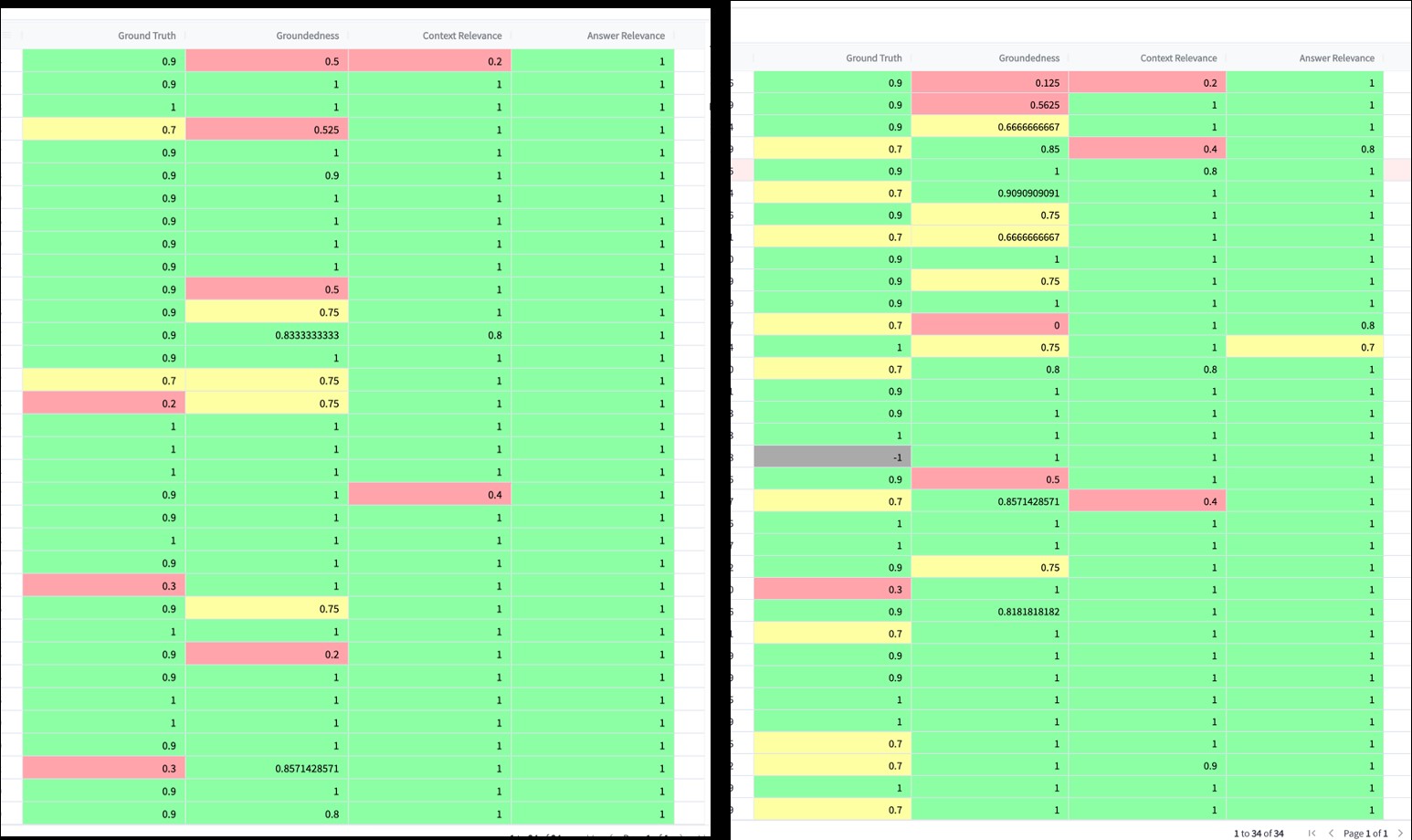
TruLens為LLM應用提供了一種系統化的評估方法,能夠有效衡量應用的性能和質量,并跟蹤每次迭代后的改善情況。盡管在實驗中發現Claude v2模型在評估模型中的表現更加穩定,但TruLens仍需依賴LLM進行結果評估,因此可能存在個別評估結果偏差的情況。
未來,隨著TruLens的不斷發展和完善,我們將能夠更好地為LLM應用提供高效的評估和優化方案,推動人工智能技術的進一步落地。
問:TruLens主要適用于哪些場景?
問:如何提升RAG項目的評估效果?
問:TruLens是否支持本地化部署?
問:Claude v2和v2.1在評估中的差異在哪里?
問:如何確保評估結果的準確性?