
2024年您產品必備的10大AI API推薦
如何實現constrained decoding?
一個直覺是:定義好schema之后,我們就知道了各個字段的輸出范圍。
例如,有個字段是int類型,那么模型在生成該字段的內容時,只應該輸出0-9的數字,其他的token不能被輸出。
因此,只要先提前做些處理:計算并存儲模型在每一步時可以輸出的tokens;然后在每次生成時,mask掉不該輸出的tokens(將其生成概率賦為0),那么最終結果一定符合預先定義的schema。
這是constrained decoding的第一個基本思想。
第二個基本思想:schema中有些部分不需模型生成,因為已經提前定義好了。
例如,我們想要輸出如下json類型的內容(一個典型的Chain Of Thought):
{
"reasoning_step": "模型的推理過程",
"result": "最終結果"
}很明顯,括號、雙引號、字段名稱,都是無需生成的,直接“放”在模型的輸出中即可,模型只需關注字段內容的生成。
從這2個基本思想,可以得到constrained decoding的基本特性:
Berkeley Function Calling Leaderboard的簡單任務上,Phi-3-medium-4k-instruct+ structured generation 可以超越GPT-4;對于json schema,outlines首先將其轉為正則表達式,然后再轉為token-level的Finite State Machine(FSM)。
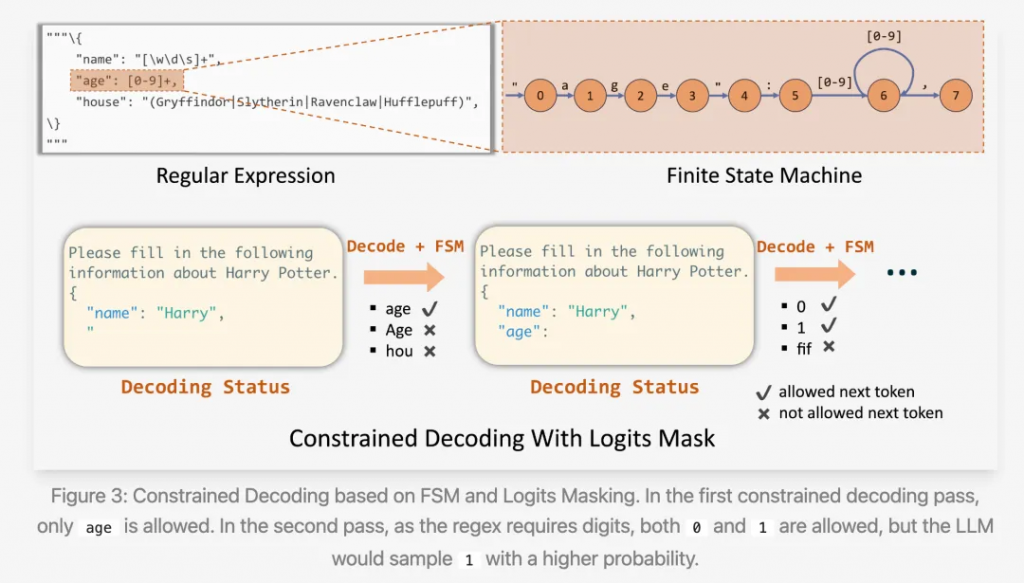
隨后,模型的生成過程就變成在state之間的跳轉:首先從初始state出發,隨后在有限的輸出路徑中選一條,到達下一個state,直到到達最后一個state,完成生成。
其中”有限的輸出路徑“就是前文所提到的tokens輸出范圍。
對技術細節感興趣的讀者,可以參閱outlines的論文[9];FSM的缺點是無法準確表示復雜的schema,細節請看下文。
outlines充分利用了原理1,但沒有利用原理2,即沒有避免生成不必要的token,所以還不夠快。
SGLang對其進行了優化。核心思路如下圖所示。
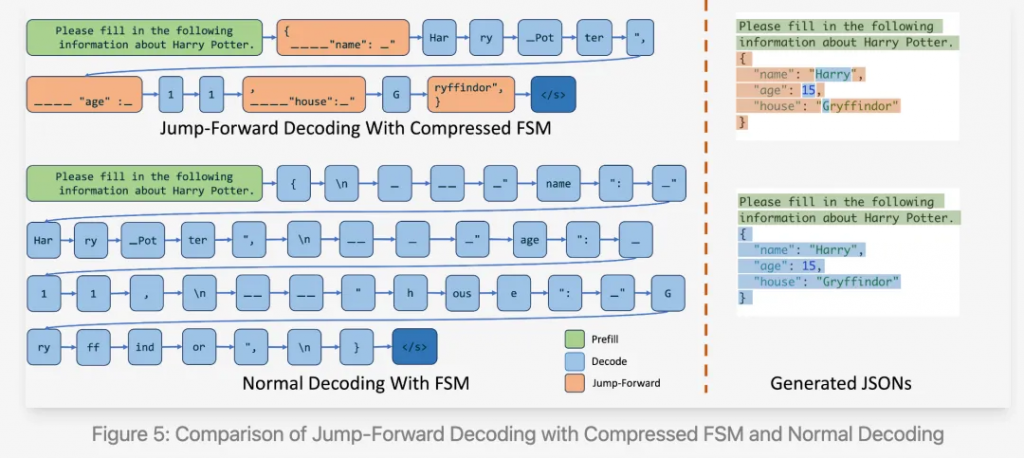
上圖便是SGLang提出的Compressed FSM方法,與原始的FSM相比,該方法壓縮了state,合并了一些無需生成的state。
因此,SGLang能有更快的生成速度。與guidance + llama.cpp、outlines + vLLM相比,SGLang可以降低2倍的latency,并提高2.5倍的吞吐量,具體可參見他們的blog[10]。
這里有個細節,同一段文字在token-level也可能有多種組合方式,如果按規則選擇其中一種,那么有可能影響后續的生成效果;SGLang用2個方法緩解了這個問題,具體可參見blog。
對outlines和SGLang來說,其思路仍是圍繞FSM。但FSM,或者說正則表達式,在表達能力上是有缺陷的,它們無法準確處理復雜的schema,例如嵌套型和遞歸型的數據結構。
下面是openai給出的一個無法用FSM來表示的schema。
{
"name": "ui",
"description": "Dynamically generated UI",
"strict": true,
"schema": {
"type": "object",
"properties": {
"type": {
"type": "string",
"description": "The type of the UI component",
"enum": ["div", "button", "header", "section", "field", "form"]
},
"label": {
"type": "string",
"description": "The label of the UI component, used for buttons or form fields"
},
"children": {
"type": "array",
"description": "Nested UI components",
"items": {
"$ref": "#"
}
},
"attributes": {
"type": "array",
"description": "Arbitrary attributes for the UI component, suitable for any element",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The name of the attribute, for example onClick or className"
},
"value": {
"type": "string",
"description": "The value of the attribute"
}
}
}
}
},
"required": ["type", "label", "children", "attributes"],
"additionalProperties": false
}
}這個例子中,children下面可以嵌套相同的schema,并且可以有任意個;這種情況確實難以用正則來準確表示。
因此,openai不使用FSM,而是使用表達能力更強的Context-Free Grammars(CFGs)。至于什么是CFGs,這里有一個簡短的介紹[11]。
openai并未提供具體的技術細節,但提到其生成過程與FSM比較相似,都是限定了模型在每步生成時的范圍。
outlines和guidance都支持基于CFGs的
structured generation;對細節感興趣的朋友可以看它們的github。
Json Mode是structured generation的小弟,它只限定模型輸出json,而不限定具體的schema。
它的實現方式也是基于CFGs的。
具體而言,可以預先定義Json的CFGs,然后在生成時限制模型在CFGs內生成。
下圖是llama-cpp-python所使用的Json CFGs。
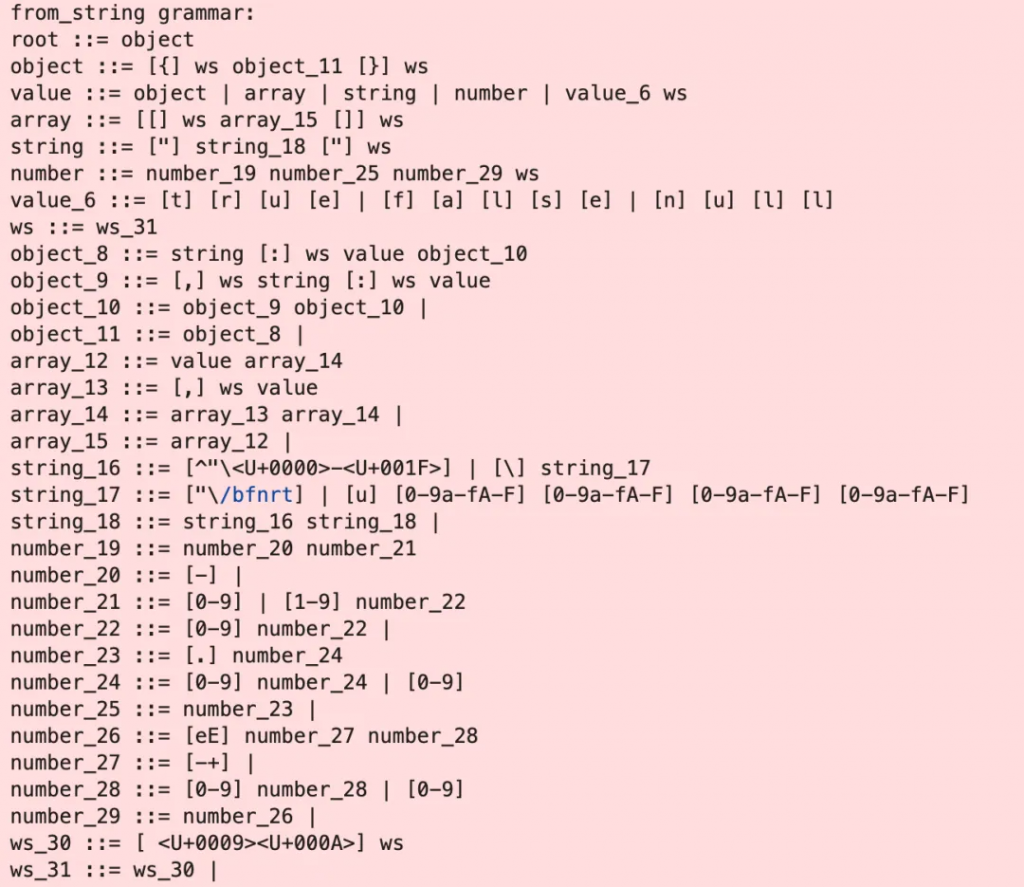
同理,特定的編程語言(SQL、C語言等)也可以預先構建CFGs,以限定模型只能生成符合規范的結果。
本文介紹了constrained decoding技術的基本原理和常見的實現思路,對于復雜的prompt技術和workflow而言,structured generation?會成為開發者的標配,Agent的開發也因此變得更加工程化。
文章轉自微信公眾號@漫談NLP







