
GLM-4 智能對話機器人本地部署指南
提示:妥善管理你的API Key,避免泄露或濫用。

Image Source: unsplash
在使用谷歌云自然語言API進行實體提取時,構(gòu)造一個有效的API請求是關(guān)鍵。你需要準備一個包含文本內(nèi)容的JSON文檔,并指定語言和內(nèi)容類型。以下是一個基本的請求結(jié)構(gòu)示例:
{
"document": {
"type": "PLAIN_TEXT",
"language": "zh",
"content": "谷歌云自然語言API是一款強大的工具。"
},
"encodingType": "UTF8"
}在構(gòu)造請求時,你可以調(diào)整參數(shù)以優(yōu)化結(jié)果。例如,設(shè)置不同的結(jié)構(gòu)化關(guān)鍵詞權(quán)重或狄利克雷平滑因子會影響實體提取的效果。以下是常用參數(shù)及其取值范圍:
| 參數(shù)類型 | 取值范圍 |
|---|---|
| 結(jié)構(gòu)化關(guān)鍵詞權(quán)重 | {1, 5, 10, 15, 20, 15, 30} |
| η | {1, 2, 3, 5, 7} |
| 狄利克雷平滑因子 | {100, 500, 1000, 1500, 2000, 2500, 3000} |
通過合理設(shè)置這些參數(shù),你可以更精確地提取文本中的實體信息。
構(gòu)造好請求后,你可以調(diào)用analyzeEntities方法來提取文本中的實體信息。以下是一個Python代碼示例,展示了如何調(diào)用該方法:
from google.cloud import language_v1
client = language_v1.LanguageServiceClient()
document = {
"content": "谷歌云自然語言API是一款強大的工具。",
"type_": language_v1.Document.Type.PLAIN_TEXT,
"language": "zh"
}
response = client.analyze_entities(request={"document": document, "encoding_type": "UTF8"})
for entity in response.entities:
print(f"Entity: {entity.name}, Type: {entity.type_}, Salience: {entity.salience}")調(diào)用成功后,響應(yīng)中會包含每個實體的名稱、類型和重要性等信息。以下是一些解析響應(yīng)的技巧:
確保正確處理編碼類型,避免亂碼。
檢查每個實體的salience值,優(yōu)先關(guān)注重要性較高的實體。
使用日志記錄工具監(jiān)控API調(diào)用的成功率和響應(yīng)時間。
此外,官方文檔提供了詳細的解析步驟和示例數(shù)據(jù),包括如何提取名片信息和解析文本數(shù)據(jù)。你可以參考這些資源以提高開發(fā)效率。
提示:在實際應(yīng)用中,結(jié)合上下文信息可以進一步提升實體提取的準確性。

Image Source: unsplash
情感分析是谷歌云自然語言API的一項核心功能。通過分析文本中的情感傾向,你可以快速了解用戶的滿意度和情緒狀態(tài)。這在客戶反饋分析、輿情監(jiān)控等場景中尤為重要。
要進行情感分析,首先需要構(gòu)造一個有效的API請求。以下是一個JSON格式的請求示例:
{
"document": {
"type": "PLAIN_TEXT",
"language": "zh",
"content": "這款產(chǎn)品真的非常棒!"
},
"encodingType": "UTF8"
}在構(gòu)造請求時,請確保文本內(nèi)容清晰且語言設(shè)置正確。文本類型通常為PLAIN_TEXT,但如果處理HTML內(nèi)容,可以選擇HTML類型。為了提高分析的準確性,建議對輸入文本進行預(yù)處理,例如去除無關(guān)字符或標點符號。
構(gòu)造好請求后,你可以調(diào)用analyzeSentiment方法來獲取情感分析結(jié)果。以下是一個Python代碼示例:
from google.cloud import language_v1
client = language_v1.LanguageServiceClient()
document = {
"content": "這款產(chǎn)品真的非常棒!",
"type_": language_v1.Document.Type.PLAIN_TEXT,
"language": "zh"
}
response = client.analyze_sentiment(request={"document": document})
print(f"Document Sentiment Score: {response.document_sentiment.score}")
print(f"Document Sentiment Magnitude: {response.document_sentiment.magnitude}")響應(yīng)結(jié)果中包含情感分數(shù)(score)和強度(magnitude)。情感分數(shù)范圍為-1到1,表示從負面到正面的情感傾向;強度則反映了情感的強烈程度。
此外,某在線零售商通過整合網(wǎng)站、社交媒體和客戶服務(wù)的反饋數(shù)據(jù),顯著提升了客戶滿意度。這種整合式分析消除了信息孤島,幫助企業(yè)獲取全面的客戶視圖。
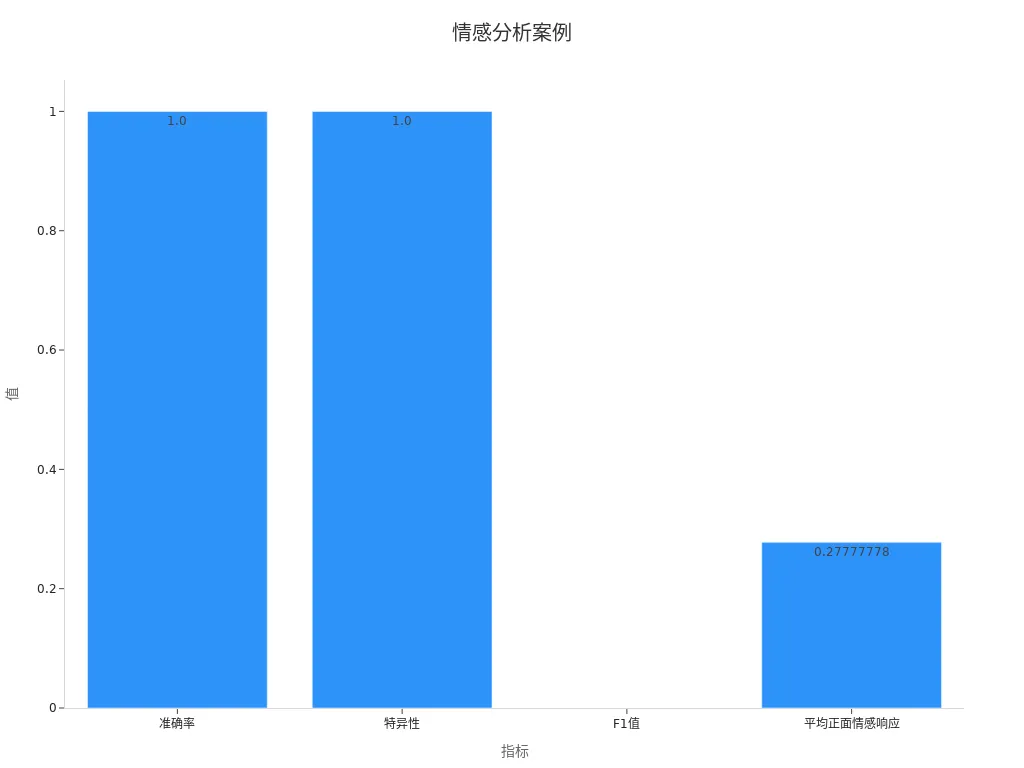
通過結(jié)合上下文信息和歷史數(shù)據(jù),你可以進一步優(yōu)化情感分析的準確性。
語法分析是谷歌云自然語言API的一項重要功能。通過分析文本的句法結(jié)構(gòu),你可以提取句子中的詞性、依存關(guān)系和短語結(jié)構(gòu)。這對于開發(fā)語言處理應(yīng)用程序,如自動摘要生成或語法糾錯工具,具有重要意義。
在進行語法分析之前,你需要構(gòu)造一個有效的API請求。以下是一個JSON格式的請求示例:
{
"document": {
"type": "PLAIN_TEXT",
"language": "zh",
"content": "谷歌云自然語言API是一款強大的工具。"
},
"features": {
"extract_syntax": true
},
"encodingType": "UTF8"
}在這個請求中,extract_syntax參數(shù)被設(shè)置為true,表示啟用語法分析功能。你需要確保文本內(nèi)容清晰,并正確指定語言和編碼類型。為了提高分析的準確性,建議對輸入文本進行預(yù)處理,例如去除多余的空格或特殊字符。
構(gòu)造好請求后,你可以調(diào)用annotateText方法來獲取語法分析結(jié)果。以下是一個Python代碼示例:
from google.cloud import language_v1
client = language_v1.LanguageServiceClient()
document = {
"content": "谷歌云自然語言API是一款強大的工具。",
"type_": language_v1.Document.Type.PLAIN_TEXT,
"language": "zh"
}
features = {"extract_syntax": True}
response = client.annotate_text(request={"document": document, "features": features, "encoding_type": "UTF8"})
for token in response.tokens:
print(f"Word: {token.text.content}, Part of Speech: {token.part_of_speech.tag}, Dependency: {token.dependency_edge.label}")調(diào)用成功后,響應(yīng)中包含每個詞的詞性、依存關(guān)系和其他語法信息。
為了更高效地使用谷歌云自然語言API,你需要深入理解API響應(yīng)中的關(guān)鍵字段。這些字段直接影響數(shù)據(jù)解析的準確性和應(yīng)用效果。以下是一些實際案例,幫助你更好地掌握這一點:
示例A:垃圾分類的過程展示了如何根據(jù)不同參數(shù)解析數(shù)據(jù)結(jié)構(gòu)。
示例B:考試結(jié)果的同步與異步返回展示了不同處理模式對結(jié)果確認的影響。
通過分析這些案例,你可以發(fā)現(xiàn)關(guān)鍵字段的作用。例如,在情感分析中,score字段表示情感傾向,而magnitude字段反映情感強度。理解這些字段的含義和相互關(guān)系,可以幫助你更精準地解讀分析結(jié)果。
優(yōu)化API請求是提升性能的關(guān)鍵。你可以從以下幾個方面入手:
使用緩存機制減少重復(fù)請求。
優(yōu)化數(shù)據(jù)庫查詢以加快數(shù)據(jù)處理速度。
采用異步處理和并發(fā)控制提高響應(yīng)效率。
利用壓縮技術(shù)減少數(shù)據(jù)傳輸量。
實現(xiàn)負載均衡與分布式部署,提升系統(tǒng)穩(wěn)定性。
優(yōu)化資源管理,避免資源浪費。
持續(xù)監(jiān)控和調(diào)優(yōu),及時發(fā)現(xiàn)并解決性能瓶頸。
在一次實際優(yōu)化中,開發(fā)團隊通過合并多個循環(huán)為一個,顯著提升了接口性能。測試結(jié)果顯示,優(yōu)化后的系統(tǒng)完全滿足性能要求。這些方法不僅能提高效率,還能降低資源消耗,為你的應(yīng)用帶來更好的用戶體驗。
谷歌云自然語言API可以與其他Google Cloud服務(wù)結(jié)合,構(gòu)建更復(fù)雜的應(yīng)用。例如,你可以將API與BigQuery集成,用于大規(guī)模數(shù)據(jù)分析;或者結(jié)合Cloud Storage,實現(xiàn)海量文本的批量處理。此外,利用Cloud Functions,你可以創(chuàng)建自動化的觸發(fā)器,在特定事件發(fā)生時調(diào)用API。
通過這些組合,你可以開發(fā)出功能更強大的解決方案。例如,某企業(yè)通過將自然語言API與機器學(xué)習(xí)服務(wù)結(jié)合,成功實現(xiàn)了客戶評論的自動分類和情感分析。這種整合式應(yīng)用不僅提升了效率,還為企業(yè)決策提供了更全面的數(shù)據(jù)支持。
提示:在設(shè)計復(fù)雜應(yīng)用時,確保各服務(wù)之間的接口清晰,避免因依賴關(guān)系導(dǎo)致的性能問題。
谷歌云自然語言API為文本數(shù)據(jù)處理提供了強大的支持。通過實體提取,你可以快速識別文本中的關(guān)鍵信息;情感分析幫助你了解用戶的情緒傾向;語法分析則讓你深入解析句子結(jié)構(gòu)。這些功能在客戶反饋分析、輿情監(jiān)控等場景中展現(xiàn)了巨大的應(yīng)用價值。



微信截圖_17436594531397.png)
