 開(kāi)發(fā)者們正在智能體譜系的中間找到一個(gè)恰到好處的“剛剛好”的平衡點(diǎn),他們將很多控制流程交給了大型語(yǔ)言模型(LLMs),但仍然保持了一套軌道和“狀態(tài)”感。
開(kāi)發(fā)者們正在智能體譜系的中間找到一個(gè)恰到好處的“剛剛好”的平衡點(diǎn),他們將很多控制流程交給了大型語(yǔ)言模型(LLMs),但仍然保持了一套軌道和“狀態(tài)”感。1、AI Agent的譜系:簡(jiǎn)單和自主模式以及"幸福的中間地帶”
讓我們將智能體定義為任何允許大型語(yǔ)言模型(LLM)控制應(yīng)用程序流程的應(yīng)用程序。
事后看來(lái),很明顯AutoGPT太過(guò)通用且沒(méi)有約束,無(wú)法滿(mǎn)足我們的期望。雖然它激發(fā)了人們的想象力,作為大型語(yǔ)言模型如何發(fā)展成通用智能體的概念驗(yàn)證,但缺乏約束使得它無(wú)法可靠地執(zhí)行有用的任務(wù)。
新一代智能體背后的秘訣是它們使用定制的認(rèn)知架構(gòu)來(lái)提供指導(dǎo)和控制狀態(tài)的框架,以保持智能體的專(zhuān)注,不偏離軌道,同時(shí)充分利用LLM的全面能力和特性。
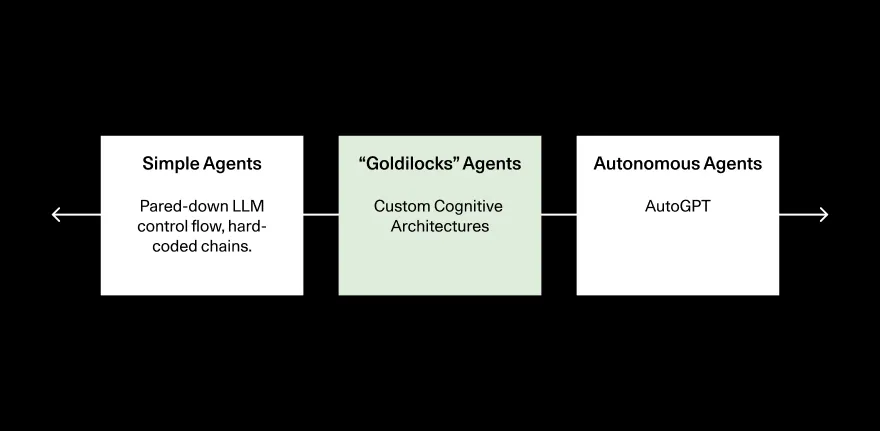
將我們?cè)谝巴饪吹降闹悄荏w類(lèi)型框架化的一個(gè)有用方法是在簡(jiǎn)單、硬編碼的智能體和完全自主的智能體之間進(jìn)行譜系劃分。這種框架揭示了“幸福的中間地帶”,在這里我們最有可能在近期到中期看到有用的智能體出現(xiàn)。
在譜系的最簡(jiǎn)單端,LLMs充當(dāng)“路由器”,決定走哪條路徑,也許有一個(gè)分類(lèi)步驟。在這種情況下,LLM調(diào)用控制應(yīng)用程序的流程,但大部分邏輯仍然是硬編碼的。在另一個(gè)極端,你擁有完全自主的智能體,如AutoGPT。
基于簡(jiǎn)單鏈的智能體不夠靈活或強(qiáng)大,無(wú)法真正利用LLM范式,而完全自主的智能體失敗太頻繁,無(wú)法發(fā)揮作用。
開(kāi)發(fā)者們正在智能體譜系的中間找到一個(gè)恰到好處的“剛剛好”的平衡點(diǎn),他們將很多控制流程交給了大型語(yǔ)言模型(LLMs),但仍然保持了一套軌道和“狀態(tài)”感。
這個(gè)“剛剛好”的中間地帶提供了最佳的權(quán)力、靈活性和控制的平衡,但它也是開(kāi)發(fā)者最難構(gòu)建的智能體類(lèi)型——它需要一個(gè)結(jié)構(gòu)化但也是不確定的認(rèn)知架構(gòu)。一個(gè)完全自主的智能體可以用很少的代碼實(shí)現(xiàn);在極端情況下,你只需要在for循環(huán)中讓智能體每步選擇一個(gè)行動(dòng)。簡(jiǎn)單的智能體也很容易編碼,因?yàn)樾枰刂频碾S機(jī)變量很少。在中間地帶開(kāi)發(fā)需要你將大量的控制權(quán)(以及因此產(chǎn)生的隨機(jī)變量)交給LLMs,同時(shí)也要控制高層次的應(yīng)用程序流程和狀態(tài)管理。
Harrison在我們的播客上分享了Jeff Bezos的一個(gè)精彩引述:“專(zhuān)注于讓你的啤酒味道更好”,他將20世紀(jì)初釀酒廠(chǎng)自己發(fā)電和科技公司在AWS之前運(yùn)行自己的基礎(chǔ)設(shè)施進(jìn)行了類(lèi)比。在一個(gè)智能體經(jīng)常摔倒的世界中,一個(gè)在SWE-bench上12-13%的表現(xiàn)被認(rèn)為是最先進(jìn)的水平,實(shí)現(xiàn)一個(gè)定制的認(rèn)知架構(gòu)絕對(duì)可以讓你的啤酒味道更好。
2、定制的認(rèn)知架構(gòu)是否只是權(quán)宜之計(jì)?
但能持續(xù)多久呢?Harrison在我們的AI Ascent會(huì)議上的演講中也提出了這個(gè)問(wèn)題,他詢(xún)問(wèn)基礎(chǔ)的大型語(yǔ)言模型(LLMs)的改進(jìn)是否會(huì)逐漸取代開(kāi)發(fā)者在“幸福的中間地帶”構(gòu)建的越來(lái)越多的推理和規(guī)劃。
換句話(huà)說(shuō),定制的認(rèn)知架構(gòu)是否只是權(quán)宜之計(jì)?
這是一個(gè)合理的問(wèn)題:許多最早的基于提示工程的智能體架構(gòu)(比如思維鏈)默認(rèn)地融入了LLMs的未來(lái)迭代中,消除了圍繞LLM構(gòu)建它們的必要性。我們相信許多大型研究實(shí)驗(yàn)室的研究人員正專(zhuān)注于推理、規(guī)劃和搜索問(wèn)題。
Harrison的看法是,越來(lái)越多的通用推理將默認(rèn)地融入LLMs,但仍需要應(yīng)用或領(lǐng)域特定的推理。
作為軟件工程師,你規(guī)劃和執(zhí)行行動(dòng)以達(dá)成目標(biāo)的方式與作為科學(xué)家的工作方式大相徑庭,而且作為不同公司的科學(xué)家,情況也有所不同。
領(lǐng)域和應(yīng)用特定的推理空間如此之大,以至于不能有效地編碼在通用模型中。
 3、軟件2.0的開(kāi)發(fā)范式
3、軟件2.0的開(kāi)發(fā)范式
使用大型語(yǔ)言模型(LLMs)開(kāi)發(fā)應(yīng)用程序與軟件1.0開(kāi)發(fā)是不同的范式,需要新的方法來(lái)實(shí)現(xiàn)可觀(guān)測(cè)性和評(píng)估。
Harrison認(rèn)為,許多傳統(tǒng)的軟件開(kāi)發(fā)工具不足以應(yīng)對(duì)LLM應(yīng)用程序的不確定性本質(zhì)。隨著智能體和控制應(yīng)用程序邏輯的新方法的出現(xiàn),使用可觀(guān)測(cè)性和測(cè)試來(lái)監(jiān)控應(yīng)用程序的行為變得至關(guān)重要。
如果你正在構(gòu)建一個(gè)定制的認(rèn)知架構(gòu),以下是一些需要考慮的事情:
“剛剛好”智能體的崛起令人興奮之處在于,它有巨大的潛力來(lái)創(chuàng)造為我們工作且在我們控制之下的軟件。實(shí)現(xiàn)這一潛力不僅取決于模型變得更好(它們肯定會(huì)),而且還依賴(lài)于這一全新的工具生態(tài)系統(tǒng)來(lái)管理這種根本上全新的應(yīng)用程序開(kāi)發(fā)。
哈里森·蔡斯:現(xiàn)在一切都還非常早期,有很多東西需要建造。GPT-5將會(huì)問(wèn)世,它可能會(huì)讓你做的一些事情變得無(wú)關(guān)緊要,但在這個(gè)過(guò)程中你會(huì)學(xué)到很多東西。我堅(jiān)信,這就像是變革性的技術(shù),所以你對(duì)它了解得越多越好。
索妮婭·黃:您好,歡迎來(lái)到《訓(xùn)練數(shù)據(jù)》。我們今天有哈里森·蔡斯,LangChain的創(chuàng)始人兼首席執(zhí)行官。哈里森是智能體生態(tài)系統(tǒng)中的傳奇人物,作為首位將LLMs與工具和行動(dòng)聯(lián)系起來(lái)的產(chǎn)品遠(yuǎn)見(jiàn)者。LangChain是AI領(lǐng)域最受歡迎的智能體構(gòu)建框架。今天,我們很高興向哈里森詢(xún)問(wèn)智能體的現(xiàn)狀、未來(lái)潛力和前進(jìn)的道路。哈里森,非常感謝你加入我們。歡迎來(lái)到我們的節(jié)目。
哈里森·蔡斯:當(dāng)然,感謝你們邀請(qǐng)我。
1、什么是智能體?以L(fǎng)LM為中心的應(yīng)用控制流程
索妮婭·黃:也許只是為了設(shè)定舞臺(tái),智能體是每個(gè)人都想更多了解的話(huà)題。你幾乎從LLM浪潮開(kāi)始以來(lái)就一直處于智能體構(gòu)建的中心。所以也許首先設(shè)定一下舞臺(tái)。
智能體究竟是什么?
哈里森·蔡斯:我認(rèn)為定義智能體實(shí)際上是有點(diǎn)棘手的。
人們可能對(duì)它們有不同的定義,我認(rèn)為這是相當(dāng)公平的,因?yàn)長(zhǎng)LMs和與智能體相關(guān)的一切仍然處于生命周期的早期階段。
我對(duì)智能體的思考方式是,當(dāng)一個(gè)LLM在某種程度上決定應(yīng)用程序的控制流程時(shí)。我的意思是,如果你有一個(gè)更傳統(tǒng)的RAG鏈,或者檢索增強(qiáng)生成鏈,步驟通常事先已知,首先,你可能要生成一個(gè)搜索查詢(xún),然后檢索一些文檔,然后生成一個(gè)答案。然后你會(huì)將其返回給用戶(hù)。這是一個(gè)非常固定的事件序列。
當(dāng)我想到開(kāi)始變得具有智能體特性的東西時(shí),是你將一個(gè)LLM置于中心并讓它決定它究竟要做什么。
所以有時(shí)候它可能會(huì)查找搜索查詢(xún)。其他時(shí)候,它可能不會(huì),它可能只是直接響應(yīng)用戶(hù)。也許它會(huì)查找搜索查詢(xún),得到結(jié)果,再查找另一個(gè)搜索查詢(xún),再查找兩個(gè)搜索查詢(xún),然后做出響應(yīng)。所以你讓 LLM 來(lái)決定控制流。
我認(rèn)為還有一些其他可能更時(shí)髦的東西適合這個(gè)范疇。
工具使用通常與智能體聯(lián)系在一起。我認(rèn)為這是有意義的。因?yàn)楫?dāng)你有一個(gè)LLM決定要做什么時(shí),它決定要做什么的主要方式是通過(guò)工具使用。所以我認(rèn)為這些事情是相輔相成的。
內(nèi)存的某些方面通常與智能體聯(lián)系在一起。我認(rèn)為這也是有道理的,因?yàn)楫?dāng)你有一個(gè)LLM決定要做什么時(shí),它需要記住它之前做了什么。所以像工具使用和記憶是松散關(guān)聯(lián)的。
但對(duì)我來(lái)說(shuō),當(dāng)我想到一個(gè)智能體時(shí),它真的是有一個(gè)LLM決定你的應(yīng)用程序的控制流程。
帕特·格雷迪:哈里森,我剛才從你那里聽(tīng)到的很多內(nèi)容都是關(guān)于決策的。我一直把智能體看作是一種行動(dòng)的采取。
這兩件事是相輔相成的嗎?智能體行為更多是關(guān)于一個(gè)而不是另一個(gè)?你怎么看待這個(gè)?
哈里森·蔡斯:我認(rèn)為它們是相輔相成的。
我認(rèn)為我們所看到的智能體所做的很多事情是決定采取什么行動(dòng),從所有意圖和目的來(lái)看。
我認(rèn)為采取行動(dòng)的大難題是決定采取正確的行動(dòng)。所以我確實(shí)認(rèn)為解決一個(gè)問(wèn)題自然會(huì)導(dǎo)致另一個(gè)問(wèn)題。在你決定行動(dòng)之后,通常有一個(gè)系統(tǒng)圍繞著LLM,然后去執(zhí)行那個(gè)行動(dòng)并將其反饋到智能體中。所以我認(rèn)為,是的,我確實(shí)認(rèn)為它們是相輔相成的。
2、智能體有簡(jiǎn)單模式和完全自主模式
索妮婭·黃:那么哈里森,看起來(lái)主要的區(qū)別就是,智能體和像鏈這樣的事物之間的區(qū)別在于,LLM本身正在決定下一步要采取什么步驟,下一步要采取什么行動(dòng),而不是這些被硬編碼。這是一種公平區(qū)分智能體是什么的方法嗎?
哈里森·蔡斯:是的,我認(rèn)為這是正確的。而且也有不同的層次。
舉個(gè)極端的例子,你可以有一個(gè)路由器來(lái)決定走哪條路。因此,在您的鏈條中可能只有一個(gè)分類(lèi)步驟。所以L(fǎng)LM仍然在決定,比如要做什么,但它是一個(gè)非常簡(jiǎn)單的決定方式。
你知道,在另一個(gè)極端,你有這些完全自主的智能體類(lèi)型的東西。然后在這兩者之間有一個(gè)完整的譜系。所以我認(rèn)為這基本上是正確的,盡管我只是想指出,就像LLM領(lǐng)域最近大多數(shù)事情一樣,有很多細(xì)微差別和灰色地帶。
3、LangChain在智能體生態(tài)系統(tǒng)扮演的角色: “幸福的中間地帶”,構(gòu)建“剛剛好”的智能體
索妮婭·黃:明白了。所以從控制到完全自主的決策和邏輯,這些是智能體的譜系。
你認(rèn)為L(zhǎng)angChain在智能體生態(tài)系統(tǒng)中扮演什么角色?
哈里森·蔡斯:我認(rèn)為現(xiàn)在我們真的專(zhuān)注于讓人們更容易在譜系的中間創(chuàng)建一些東西。出于一系列原因,我們已經(jīng)看到這是目前建立代理的最佳地點(diǎn)。
所以我們看到了一些更完全自主的東西引起了很多興趣,原型也很快出臺(tái)。完全自主的東西實(shí)際上非常簡(jiǎn)單,但我們看到它們經(jīng)常偏離軌道。__我們看到人們想要更有限制的東西,但比鏈更靈活和強(qiáng)大一些。__
所以我們最近專(zhuān)注的很多事情,是作為一個(gè)編排層,使創(chuàng)建這些智能體成為可能,特別是這些介于鏈和完全自主智能體之間的中間東西。我可以更深入地介紹我們?cè)谀抢锞烤乖谧鍪裁础5诟邔哟紊希蔷褪俏覀兿胂笾械木幣趴蚣埽褪荓angChain所在的位置。
索妮婭·黃:明白了。所以有鏈,有完全自主的智能體,有一個(gè)中間的譜系,你的甜蜜點(diǎn)在中間,使人們能夠構(gòu)建智能體。
哈里森·蔡斯:是的,顯然,隨著時(shí)間的推移,這一點(diǎn)也發(fā)生了變化。所以反思LangChain的演變是很有趣的。
你知道,我認(rèn)為當(dāng)LangChain剛開(kāi)始時(shí),它實(shí)際上是鏈的組合。然后我們有一個(gè)類(lèi),這個(gè)智能體執(zhí)行器類(lèi),基本上是這個(gè)完全自主的智能體。我們開(kāi)始向這個(gè)類(lèi)添加更多的控制。
最終,我們意識(shí)到人們想要的靈活性和控制比我們用那個(gè)類(lèi)給他們的要多得多。所以,最近,我們一直在大力投資LangGraph,這是LangChain的一個(gè)擴(kuò)展,真正針對(duì)定制智能體,它們位于中間某個(gè)地方。
我們的重點(diǎn),隨著時(shí)間的推移,隨著領(lǐng)域的發(fā)展而發(fā)展。
4、智能體是下一個(gè)大事件嗎?
索妮婭·黃:太有趣了。也許還有一個(gè)最后的設(shè)定舞臺(tái)問(wèn)題。我們的核心信念之一是智能體是AI的下一個(gè)大浪潮,我們正作為一個(gè)行業(yè)從副駕駛轉(zhuǎn)向智能體。
我很好奇你是否同意這種看法,以及為什么或?yàn)槭裁床唬?/p>
哈里森·蔡斯:是的,我大體上同意這種觀(guān)點(diǎn),我認(rèn)為這對(duì)我來(lái)說(shuō)如此令人興奮的原因是,副駕駛?cè)匀灰蕾?lài)于有這個(gè)人類(lèi)在循環(huán)中。所以從某種意義上說(shuō),有一個(gè)上限,你可以讓另一個(gè)系統(tǒng)完成的工作量。所以在這方面有點(diǎn)限制。
我確實(shí)認(rèn)為圍繞正確的UX和人類(lèi)智能體交互模式有一些非常有趣的思考要做。但我確實(shí)認(rèn)為它們會(huì)更接近于智能體做了一些事情,可能與你一起核對(duì),而不是一個(gè)不斷在循環(huán)中的副駕駛,我只是認(rèn)為它更強(qiáng)大,給你更多的杠桿,如果它們做的越多,這也是非常矛盾的,因?yàn)殡S著你讓它自己做事情,它出錯(cuò)或偏離軌道的風(fēng)險(xiǎn)就越大。所以我認(rèn)為找到正確的平衡將非常非常有趣。
5、為什么第一批自主智能體沒(méi)有成功?
索妮婭·黃:我記得回到2023年3月左右。有一些這樣的自主智能體真的吸引了大家的想象力,比如BabyAGI AutoGPT,一些這樣的。
我記得,Twitter對(duì)對(duì)此非常非常興奮。看起來(lái),第一代智能體架構(gòu)并沒(méi)有完全滿(mǎn)足人們的期望。我想你為什么會(huì)這樣認(rèn)為?你認(rèn)為我們現(xiàn)在在智能體炒作周期的哪個(gè)階段?
哈里森·蔡斯:是的,我想首先考慮智能體炒作周期。
我認(rèn)為AutoGPT絕對(duì)是開(kāi)始。然后,它是GitHub上有史以來(lái)最受歡迎的項(xiàng)目之一。所以炒作周期,我會(huì)說(shuō)從2023年春天到2023年夏天左右開(kāi)始。然后我個(gè)人感覺(jué)從夏末到2024年新年開(kāi)始,有一點(diǎn)低谷/下降趨勢(shì),我認(rèn)為從2024年開(kāi)始,我們開(kāi)始看到一些更現(xiàn)實(shí)的東西上線(xiàn)。
我會(huì)指出我們?cè)贚angChain與Elastic合作的一些工作,例如,他們?cè)谏a(chǎn)有點(diǎn)像Elastic Assistant和Elastic Agent。所以我們看到了Klarna客戶(hù)支持機(jī)器人上線(xiàn),引起了很多炒作。我們看到Devin,我們看到Sierra。這些其他公司開(kāi)始在智能體領(lǐng)域出現(xiàn)。所以考慮到炒作周期,談?wù)摓槭裁碅utoGPT風(fēng)格的架構(gòu)并沒(méi)有真正奏效,它非常籠統(tǒng),非常不受限制。我認(rèn)為這讓它的興奮和激發(fā)了人們的想象力。但我認(rèn)為實(shí)際上對(duì)于人們想要自動(dòng)化的事情,提供即時(shí)的商業(yè)價(jià)值,實(shí)際上有很多事情,這是一個(gè)更具體的事情,他們希望這些智能體去做。而且真的有很多規(guī)則,他們希望智能體遵循,或者他們希望它們以特定的方式做事情。
所以我認(rèn)為在實(shí)踐中,我們看到的這些智能體,它們更像是我們所說(shuō)的定制認(rèn)知架構(gòu),你通常希望智能體以某種方式做事情。當(dāng)然,其中有一定的靈活性。否則,你知道,你只會(huì)編碼它。但這是一種非常有針對(duì)性的思考方式。這就是我們今天看到的大多數(shù)智能體和助手。這只是更多的工程工作。這只是更多的嘗試和看看什么有效,什么無(wú)效,這更難做。所以它只是需要更長(zhǎng)的時(shí)間來(lái)構(gòu)建。我認(rèn)為這就是為什么,你知道,這就是為什么一年前不存在,或者類(lèi)似的事情。
1、什么是認(rèn)知架構(gòu)?
索妮婭·黃:既然你提到了認(rèn)知架構(gòu),我喜歡你對(duì)它們的思考方式,或許你可以解釋一下,比如,什么是認(rèn)知架構(gòu)?我們應(yīng)該如何思考它們,有什么好的思維框架嗎?
哈里森·蔡斯:是的,我對(duì)認(rèn)知架構(gòu)的思考方式基本上是你的大型語(yǔ)言模型(LLM)應(yīng)用程序的系統(tǒng)架構(gòu)是什么?
我的意思是,如果你正在構(gòu)建一個(gè)應(yīng)用程序,其中有一些步驟使用算法。你用這些算法做什么?你是用它們僅僅生成最終答案嗎?你是用它們?cè)趦蓚€(gè)不同的事情之間進(jìn)行路由嗎?你有一個(gè)有很多不同分支的復(fù)雜架構(gòu)嗎?也許有一些循環(huán)在重復(fù)?或者你有一個(gè)循環(huán),基本上你會(huì)在這個(gè)循環(huán)中運(yùn)行這個(gè)LLM,這些都是認(rèn)知架構(gòu)的不同變體,而認(rèn)知架構(gòu)只是花哨的說(shuō)法,從用戶(hù)輸入到用戶(hù)輸出,數(shù)據(jù)流、信息流、LLM調(diào)用在這個(gè)過(guò)程中發(fā)生了什么。
我們?cè)絹?lái)越多地看到的,尤其是當(dāng)人們?cè)噲D將智能體真正投入生產(chǎn)時(shí),是這個(gè)流程特定于他們?cè)谄漕I(lǐng)域中的應(yīng)用程序。所以也許他們想要立即進(jìn)行一些特定的檢查,之后可能會(huì)采取三個(gè)具體步驟。然后每個(gè)選項(xiàng)都可以選擇回循環(huán),或者有兩個(gè)單獨(dú)的子步驟。
因此,如果你仔細(xì)想想,我們看到這些更像是你正在繪制的圖,我們看到越來(lái)越多的基本上是定制和專(zhuān)門(mén)的圖形,因?yàn)槿藗冊(cè)噲D沿著他們的應(yīng)用程序限制和引導(dǎo)智能體。
我之所以稱(chēng)之為認(rèn)知架構(gòu),是因?yàn)槟阒溃艺J(rèn)為L(zhǎng)LMs的很多力量在于推理和思考該做什么。所以,你知道,我可能會(huì)有一個(gè)認(rèn)知心理模型來(lái)執(zhí)行一個(gè)任務(wù)。我基本上只是將這個(gè)心理模型編碼成某種軟件系統(tǒng),某種架構(gòu)。
2、LLM做非常通用的智能體推理,非通用控制循環(huán)不會(huì)在LLM中
帕特·格雷迪:你認(rèn)為這是世界發(fā)展的方向嗎?因?yàn)槲以谀抢锫?tīng)到了兩件事。
一是,它非常定制化。第二是,它相當(dāng)粗暴,就像在很多方面相當(dāng)硬編碼。
你認(rèn)為這是我們的發(fā)展方向嗎?或者你認(rèn)為這是一個(gè)權(quán)宜之計(jì),而在某個(gè)時(shí)候,會(huì)出現(xiàn)更優(yōu)雅的架構(gòu),或者一系列默認(rèn)的參考架構(gòu)?
哈里森·蔡斯:這是一個(gè)非常非常好的問(wèn)題。我花了很多時(shí)間思考這個(gè)問(wèn)題。
我認(rèn)為,極端情況下,你可以認(rèn)為如果模型在規(guī)劃方面真的非常非常好,非常可靠,那么你可能有的最好的東西就是這個(gè)循環(huán)的for循環(huán),調(diào)用LLM,決定做什么,采取行動(dòng)然后再循環(huán)。就像所有這些關(guān)于我期望模型如何表現(xiàn)的限制,我只是把它放在我的提示中,模型就會(huì)明確地遵循。
我確實(shí)認(rèn)為模型在規(guī)劃和推理方面會(huì)變得更好,當(dāng)然。我不太認(rèn)為它們會(huì)達(dá)到那種水平,因?yàn)楦鞣N原因。
我認(rèn)為,第一,效率。如果你知道在步驟B之后總是要做步驟A。你可以直接按順序放。第二,可靠性也是如此。這些都是我們談?wù)摰牟淮_定性事物,特別是在企業(yè)環(huán)境中,你可能會(huì)想要更多的安慰,如果它總是應(yīng)該在步驟B之后做步驟A,它實(shí)際上總是會(huì)做步驟A而不是步驟B或者在步驟B之后。我認(rèn)為創(chuàng)建這些東西會(huì)變得更容易,我認(rèn)為它們可能會(huì)開(kāi)始變得不那么復(fù)雜。
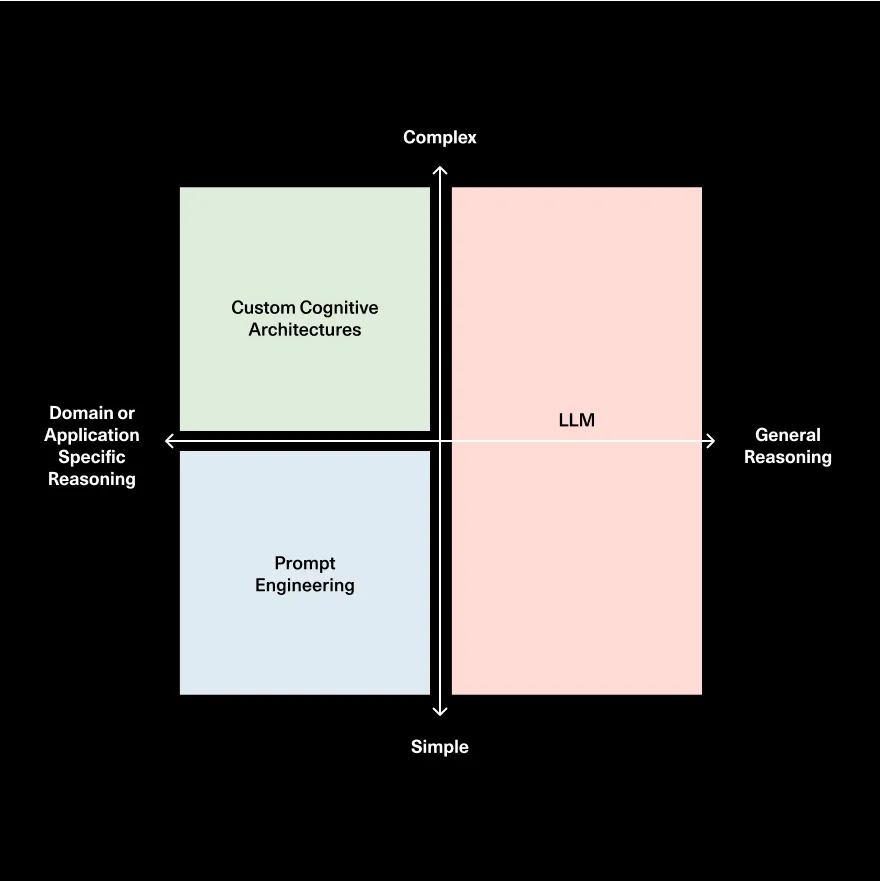
但實(shí)際上,這可能是一個(gè)熱門(mén)觀(guān)點(diǎn),或者我的觀(guān)點(diǎn)很有趣,你可以說(shuō),只是在循環(huán)中運(yùn)行它的架構(gòu),你可以認(rèn)為這是一個(gè)非常簡(jiǎn)單但通用的認(rèn)知架構(gòu)。然后我們?cè)谏a(chǎn)中看到的是定制和復(fù)雜的,有點(diǎn)像認(rèn)知架構(gòu)。我認(rèn)為有一個(gè)單獨(dú)的軸,那就是復(fù)雜但通用的定制或復(fù)雜但通用的認(rèn)知架構(gòu)。所以這將是一個(gè)真正復(fù)雜的計(jì)劃步驟和反思循環(huán)或者像思維樹(shù)之類(lèi)的東西。
我實(shí)際上認(rèn)為隨著時(shí)間的推移,這個(gè)象限可能會(huì)消失,因?yàn)槲艺J(rèn)為很多這種通用規(guī)劃和通用反思將被訓(xùn)練到模型本身中。但仍然會(huì)有很多非通用訓(xùn)練或非通用規(guī)劃,非通用反思,非通用控制循環(huán),基本上永遠(yuǎn)不會(huì)在模型中。
所以我認(rèn)為這是譜系的兩端,我非常看好。
索妮婭·黃:我猜你幾乎可以認(rèn)為LLM做非常通用的智能體推理,然后你需要領(lǐng)域特定的推理,而這些東西是你無(wú)法真正構(gòu)建到一個(gè)通用模型中的東西。
哈里森·蔡斯:100%,我認(rèn)為,我認(rèn)為定制認(rèn)知架構(gòu)的方式,就是你基本上把規(guī)劃責(zé)任從LLM拿走,放到人類(lèi)身上。
一些規(guī)劃,你會(huì)越來(lái)越傾向于模型,越來(lái)越傾向于提示,但我認(rèn)為他們總是會(huì)這樣,我認(rèn)為很多任務(wù)在他們的一些計(jì)劃中實(shí)際上非常復(fù)雜。
因此,我認(rèn)為我們還需要一段時(shí)間才能獲得能夠做到這一點(diǎn)的東西,超級(jí)可靠。
3、智能體的進(jìn)展和空間
索妮婭·黃:看起來(lái)我們?cè)谶^(guò)去的六個(gè)月左右在智能體方面取得了很多進(jìn)展,就像我讀到的一篇論文,普林斯頓SWE論文,他們的編碼智能體現(xiàn)在可以解決12.5%的GitHub問(wèn)題,而之前只是RAG的時(shí)候是3.8%。
所以感覺(jué)我們?cè)谶^(guò)去的六個(gè)月里取得了很多進(jìn)展,但12.5%還不夠好,你知道,甚至不能取代一個(gè)實(shí)習(xí)生,對(duì)吧?所以感覺(jué)我們?nèi)匀挥泻艽蟮目臻g。
我很好奇,你認(rèn)為我們?cè)谀睦铮瑢?duì)于一般的智能體以及你的客戶(hù)正在構(gòu)建智能體?比如,他們是不是達(dá)到了,我假設(shè)不是五星級(jí)的可靠性,但他們是不是達(dá)到了某種門(mén)檻,他們需要部署這些智能體到實(shí)際面向客戶(hù)的部署?
哈里森·蔡斯:是的,所以我想說(shuō),SWE代理是一個(gè)相對(duì)通用的智能體,因?yàn)樗鼞?yīng)該能夠在很多不同的GitHub代碼庫(kù)中工作。
我認(rèn)為如果你看看Vercel的v0,它可能比12.5%更可靠,對(duì)吧?所以我認(rèn)為這說(shuō)明,是的,肯定有定制智能體不是五星級(jí)的可靠性,但是已經(jīng)在生產(chǎn)中使用了。所以Elastic,我認(rèn)為我們已經(jīng)公開(kāi)談?wù)撨^(guò)他們已經(jīng)做了多個(gè)智能體。我認(rèn)為這周是RSA,我認(rèn)為他們?cè)赗SA上宣布了新的東西,那是一個(gè)智能體。
是的,我沒(méi)有確切的可靠性數(shù)字,但是它們足夠可靠,可以投入生產(chǎn)。一般智能體仍然很困難。是的,這就是長(zhǎng)期上下文窗口、更好的規(guī)劃、更好的推理將幫助這些通用智能體的地方。
4、區(qū)分通用和定制,“專(zhuān)注于讓你的啤酒味道更好”
索妮婭·黃:你和我分享了杰夫·貝佐斯(Jeff Bezos)的一句名言,就像,“專(zhuān)注于讓你的啤酒更好。”
我認(rèn)為它指的是在20世紀(jì)初,釀酒廠(chǎng)正在嘗試制造自己的電力,自己發(fā)電。我認(rèn)為今天很多公司都在思考類(lèi)似的問(wèn)題,比如,你認(rèn)為擁有你的認(rèn)知架構(gòu)的控制真的會(huì)讓你的啤酒味道更好嗎?打個(gè)比方?或者,你放棄了模型的控制,只構(gòu)建UI和產(chǎn)品?
哈里森·蔡斯:我認(rèn)為這可能取決于你正在構(gòu)建的認(rèn)知架構(gòu)的類(lèi)型?
回到我們之前的一些討論,如果你正在構(gòu)建一個(gè)通用的認(rèn)知架構(gòu),我不認(rèn)為這會(huì)讓你的啤酒味道更好。
我認(rèn)為模型提供者將致力于這種通用規(guī)劃,我認(rèn)為像很好地致力于這些通用認(rèn)知架構(gòu),你可以立即嘗試。另一方面,如果你的認(rèn)知架構(gòu)基本上是你,對(duì)你支持團(tuán)隊(duì)思考某件事情的方式進(jìn)行編碼,或者內(nèi)部業(yè)務(wù)流程,或者你知道的最佳方式,比如開(kāi)發(fā)代碼,或者開(kāi)發(fā)這種特定類(lèi)型的代碼,或者這種特定類(lèi)型的應(yīng)用程序,是的,我認(rèn)為這絕對(duì)會(huì)讓你的啤酒味道更好,特別是如果我們正在走向一個(gè)這些應(yīng)用程序正在工作的地方。
那么像邏輯,定制的商業(yè)邏輯或心理模型,我現(xiàn)在對(duì)這些LLMs進(jìn)行了很多擬人化,但是像這些東西的最佳工作模型,100%。就像我認(rèn)為這是你銷(xiāo)售的關(guān)鍵,而且在某種程度上,我認(rèn)為UX、UI和分銷(xiāo)絕對(duì)仍然發(fā)揮作用。是的,我區(qū)分了通用和定制。
5、自主智能體完美地工作,意味著人類(lèi)將專(zhuān)注于更高級(jí)的事物
帕特·格雷迪:哈里森,在我們深入了解人們?nèi)绾螛?gòu)建這些東西的一些細(xì)節(jié)之前,我們可以快速提高一個(gè)層次嗎?所以我們的創(chuàng)始人唐·瓦倫丁以問(wèn)“那又怎樣?”這個(gè)問(wèn)題而聞名。
所以我的問(wèn)題是,那又怎樣?讓我們想象一下,自主智能體完美地工作。對(duì)世界意味著什么?生活會(huì)有什么不同?
哈里森·蔡斯:我認(rèn)為在高層次上,這意味著,作為人類(lèi),我們將專(zhuān)注于不同的事物。
所以我認(rèn)為,目前很多行業(yè)中正在進(jìn)行的很多工作都是重復(fù)性勞動(dòng)。因此,智能體的理念是,這些工作將會(huì)被自動(dòng)化,讓我們思考更高層次的問(wèn)題,比如這些智能體應(yīng)該做什么,也許利用它們的輸出進(jìn)行更創(chuàng)造性的工作或在這些輸出的基礎(chǔ)上進(jìn)行更高層次的工作。
所以我認(rèn)為,你可以想象引導(dǎo)一個(gè)公司的整個(gè)發(fā)展,你正在外包你通常必須雇傭的很多職能。所以你可以在有一個(gè)營(yíng)銷(xiāo)智能體、一個(gè)銷(xiāo)售智能體的情況下扮演CEO的角色,基本上讓你將這些工作外包給智能體,讓你做很多有趣的戰(zhàn)略思考、產(chǎn)品思考,也許這取決于你的興趣。
但我認(rèn)為在高層次上,它會(huì)讓我們自由地做我們想做的事情和我們擅長(zhǎng)的事情,自動(dòng)化很多我們可能不一定想做的事情。
1、哪些智能體的落地應(yīng)用已經(jīng)成熟?
帕特·格雷迪:你今天看到了這方面的一些有趣例子嗎,比如已經(jīng)實(shí)時(shí)投入生產(chǎn)的?
哈里森·蔡斯:我的意思是,我認(rèn)為最大的,有兩種類(lèi)別或領(lǐng)域的智能體開(kāi)始獲得更多關(guān)注,一是客戶(hù)支持,一是編碼。
所以我認(rèn)為客戶(hù)支持是一個(gè)很好的例子,比如,你知道,人們經(jīng)常需要客戶(hù)支持,我們?cè)贚angChain也需要客戶(hù)支持。所以如果我們能雇傭智能體來(lái)做這件事,那將是非常強(qiáng)大的。
編碼很有趣,因?yàn)槲艺J(rèn)為編碼的有些方面,我的意思是,這可能是一個(gè)更哲學(xué)上的討論。但是我認(rèn)為編碼的有些方面確實(shí)是非常創(chuàng)造性的,確實(shí)需要,我的意思是,真的很多產(chǎn)品思考,很多定位等等。
編碼的有些方面也可能阻礙人們的創(chuàng)造力。所以如果我媽媽有一個(gè)網(wǎng)站的主意,她不知道如何將它編碼實(shí)現(xiàn),對(duì)吧?但是如果有一個(gè)智能體能夠做到這一點(diǎn),她就可以專(zhuān)注于網(wǎng)站的想法,基本上就是網(wǎng)站的范圍,但是自動(dòng)化這個(gè)過(guò)程。
所以我會(huì)說(shuō)要絕對(duì)地說(shuō)客戶(hù)支持,今天確實(shí)已經(jīng)產(chǎn)生了影響。編碼方面,那里有很多興趣。我不認(rèn)為我們已經(jīng)到達(dá)了,我不認(rèn)為它像客戶(hù)支持那樣成熟。但是就有很多有趣的領(lǐng)域而言,這將是第二個(gè)值得一提的領(lǐng)域。
帕特·格雷迪:你對(duì)編碼的評(píng)論很有趣,因?yàn)槲艺J(rèn)為這是讓我們對(duì)AI非常樂(lè)觀(guān)的事情之一。
這就是縮小從想法到執(zhí)行的差距,或者縮小從夢(mèng)想到現(xiàn)實(shí)的差距,你可以想出一個(gè)非常有創(chuàng)意、引人注目的想法。但你可能有沒(méi)有辦法將其變?yōu)楝F(xiàn)實(shí),而AI似乎非常適合這一點(diǎn)。
我認(rèn)為Figma的Dylan也經(jīng)常談?wù)撨@個(gè)問(wèn)題。
哈里森·蔡斯:是的,我認(rèn)為這回到了這個(gè)想法,自動(dòng)化那些阻礙創(chuàng)造的東西——我喜歡“從想法到現(xiàn)實(shí)”的措辭——它自動(dòng)化了你可能不知道如何做或不想考慮的事情,但這些都是創(chuàng)造你想要的東西所必需的。
我認(rèn)為這也是我花了很多時(shí)間思考的事情之一,就像在生成式AI和智能體的時(shí)代,作為一個(gè)建設(shè)者意味著什么?所以今天作為一個(gè)軟件建設(shè)者意味著你要么是工程師,要么雇傭工程師之類(lèi)的,對(duì)吧?
但我認(rèn)為在智能體和生成式AI的時(shí)代,作為一個(gè)建設(shè)者意味著人們可以構(gòu)建比今天更多的東西。因?yàn)樗麄兪诸^上有所有這些知識(shí),所有這些,有點(diǎn)像,所有這些其他的建設(shè)者,他們可以雇傭并非常便宜地使用。
我的意思是,我認(rèn)為像智能或類(lèi)似東西的通貨化的一些說(shuō)法,因?yàn)檫@些大型語(yǔ)言模型免費(fèi)提供智能。我認(rèn)為這確實(shí)說(shuō)明了使這些新的建設(shè)者出現(xiàn)。
2、最有前途的認(rèn)知架構(gòu)是什么?
規(guī)劃、推理是通用認(rèn)知架構(gòu),此外有定制架構(gòu)
索妮婭·黃:你提到了反思和思維鏈和其他技術(shù),或許你可以說(shuō)一下,我們現(xiàn)在對(duì)這些,我想認(rèn)知架構(gòu)能夠做什么,對(duì)于智能體性能有何了解?也許只是,我很好奇你認(rèn)為最有前途的認(rèn)知架構(gòu)是什么?
哈里森·蔡斯:是的,我認(rèn)為,也許值得談?wù)撘幌聻槭裁碅utoGPT之類(lèi)的東西沒(méi)有奏效。
因?yàn)槲艺J(rèn)為很多認(rèn)知架構(gòu)都差不多,就是為了抵消其中的一些。我想,很久以前,基本上的問(wèn)題是大型語(yǔ)言模型甚至不能很好地推理出第一步該做什么以及他們應(yīng)該采取的第一步是什么。
所以我認(rèn)為像思維鏈這樣的提示技術(shù)在那里非常有幫助,它們基本上給了大型語(yǔ)言模型更多的空間去思考,一步一步地思考,對(duì)于特定步驟他們應(yīng)該做什么。然后實(shí)際上開(kāi)始越來(lái)越多地被訓(xùn)練到模型中。他們通過(guò)默認(rèn)的方式做到了這一點(diǎn)。基本上每個(gè)人都希望模型這樣做,所以是的,你應(yīng)該將這一點(diǎn)訓(xùn)練到模型中。
我記得那時(shí),Shunyu Yao發(fā)表了一篇很棒的論文,叫做ReAct,它基本上是第一個(gè)智能體的認(rèn)知架構(gòu)或類(lèi)似的東西。它所做的一件事,一是讓大型語(yǔ)言模型預(yù)測(cè)要做什么,那就是行動(dòng),但它增加了這個(gè)推理組件,所以它有點(diǎn)像思維鏈,它基本上增加了這個(gè)推理組件,他將其放入循環(huán)中,在每一步之前都要求它進(jìn)行這種推理,你在那里運(yùn)行它。
所以這種顯式的推理步驟實(shí)際上已經(jīng)變得不那么必要了,因?yàn)槟P鸵呀?jīng)被訓(xùn)練了,就像他們已經(jīng)訓(xùn)練了思維鏈一樣,這種顯式的推理步驟變得不那么必要了。
所以如果你看到人們今天在做ReAct風(fēng)格的智能體,他們通常只是使用函數(shù)調(diào)用,而沒(méi)有原始ReAct論文中實(shí)際的思維過(guò)程。但它仍然是這種循環(huán),已經(jīng)成為ReAct論文的同義詞。所以這是智能體最初的很多困難。我不會(huì)完全將這些描述為架構(gòu)。我將它們描述為提示技術(shù)。
但是現(xiàn)在我們已經(jīng)讓它工作了。現(xiàn)在,一些問(wèn)題是什么??jī)蓚€(gè)主要問(wèn)題基本上是規(guī)劃和然后意識(shí)到你已經(jīng)完成了。
所以我所說(shuō)的規(guī)劃,就像我考慮如何做事情時(shí),下意識(shí)或有意識(shí)地,我制定了一個(gè)計(jì)劃,我將要做的步驟的順序。然后我去做每一步。基本上模型在這方面有困難,他們難以進(jìn)行長(zhǎng)期規(guī)劃,難以提出一個(gè)好的長(zhǎng)期計(jì)劃。然后如果你在這個(gè)循環(huán)中運(yùn)行它,在每一步,你都在做計(jì)劃的一部分,也許它完成了,或者也許沒(méi)有完成。所以如果你只是在這個(gè)循環(huán)中運(yùn)行它,你隱含地要求模型首先提出一個(gè)計(jì)劃,然后跟蹤計(jì)劃的進(jìn)度并繼續(xù)前進(jìn)。
所以我認(rèn)為我們看到的一些規(guī)劃認(rèn)知架構(gòu)是,好的,首先讓我們?cè)黾右粋€(gè)明確的步驟,我們要求大型語(yǔ)言模型生成一個(gè)計(jì)劃,然后,我們按照那個(gè)計(jì)劃一步一步進(jìn)行。我們將確保我們做每一步,這只是一種方式,就像,強(qiáng)制模型生成一個(gè)長(zhǎng)期計(jì)劃,并確實(shí)在繼續(xù)之前做每一步,而不是像你知道,生成一個(gè)五步計(jì)劃,做完第一步然后說(shuō),好的,我完成了或者類(lèi)似的事情。
然后,我認(rèn)為,一個(gè)獨(dú)立但相關(guān)的東西是反思的想法,這基本上像是,模型實(shí)際上是否很好地完成了它的工作,對(duì)吧?所以,我可以生成一個(gè)計(jì)劃,我將要去得到這個(gè)答案。我可以從互聯(lián)網(wǎng)上得到一個(gè)答案。也許這完全是錯(cuò)誤的答案,或者我得到了糟糕的搜索結(jié)果或者類(lèi)似的事情。我不應(yīng)該只是返回那個(gè)答案,對(duì)吧?我應(yīng)該想想我是否得到了正確的答案。或者我是否需要再做一次,如果你只是在這個(gè)循環(huán)中運(yùn)行它,你實(shí)際上是在隱含地要求模型這樣做。
所以有一些認(rèn)知架構(gòu)出現(xiàn)了,以克服這一點(diǎn),基本上增加了這一點(diǎn)作為一個(gè)明確的步驟,他們采取了一個(gè)行動(dòng)或一系列行動(dòng),然后要求模型明確思考它是否正確完成了。
所以規(guī)劃和推理可能是兩個(gè)更受歡迎的通用,有點(diǎn)像,認(rèn)知架構(gòu)。有很多,像定制的認(rèn)知架構(gòu),但那都超級(jí)綁定到商業(yè)邏輯等等。但規(guī)劃和推理是通用的,我預(yù)計(jì)這些將越來(lái)越多地被默認(rèn)訓(xùn)練到模型中。
盡管我認(rèn)為他們會(huì)變得多好,這是一個(gè)非常有趣的問(wèn)題,但這可能是一個(gè)單獨(dú)的長(zhǎng)期對(duì)話(huà)。
3、UX可以影響架構(gòu)的有效性
帕特·格雷迪:哈里森,你在AI Ascent上談到的一件事是用戶(hù)體驗(yàn)(UX),我們通常認(rèn)為它與架構(gòu)處于譜系的相反端,你知道,架構(gòu)是在幕后,UX是前臺(tái)的東西。
但我們似乎處于一個(gè)有趣的世界,UX實(shí)際上可以通過(guò)允許你,例如,使用Devin回溯到計(jì)劃過(guò)程中開(kāi)始偏離軌道的點(diǎn),來(lái)影響架構(gòu)的有效性。
你能就UX及其在智能體或LLM中的重要性,以及你可能在那里看到的一些有趣的事情,發(fā)表一些看法嗎?
哈里森·蔡斯:是的,我對(duì)UX非常著迷。我認(rèn)為這里有非常多有趣的工作要做。
我認(rèn)為它之所以如此重要,是因?yàn)檫@些LLM仍然不完美,仍然不太可靠,有出錯(cuò)的傾向。
這就是為什么聊天對(duì)于一些最初的交互和應(yīng)用程序來(lái)說(shuō)是如此強(qiáng)大的UX。你可以很容易地看到它在做什么,它將響應(yīng)流回來(lái),你可以很容易地通過(guò)回應(yīng)它來(lái)糾正它,你可以很容易地提出后續(xù)問(wèn)題。所以我認(rèn)為聊天顯然已經(jīng)成為目前主導(dǎo)的UX。
我確實(shí)認(rèn)為聊天有缺點(diǎn)。你知道,它通常是一條AI信息,一條人類(lèi)信息。人類(lèi)非常處于循環(huán)中,這非常像副駕駛類(lèi)型的東西。
我認(rèn)為,你越是能夠?qū)⑷祟?lèi)從循環(huán)中移出,它就能為你做更多的事情,它可以為你工作。我只是認(rèn)為這是難以置信的強(qiáng)大和賦能。
然而,LLM并不完美,它們會(huì)出錯(cuò)。那么你如何平衡這兩件事呢?我認(rèn)為我們看到的一些有趣的想法,談?wù)揇evin時(shí),是基本上有一個(gè)像透明列表的東西,列出了代理所做的一切,對(duì)吧?你應(yīng)該能夠知道代理做了什么。這似乎是第一步。
第二步可能是能夠修改它正在做的事情或已經(jīng)做過(guò)的事情。所以如果你看到第三步出了問(wèn)題,你可以在那里倒帶,給它一些新的指示,甚至只是手動(dòng)編輯決定,從那里開(kāi)始。
我認(rèn)為除了這種倒帶和編輯之外,還有其他有趣的UX模式。
一種是像收件箱這樣的想法,代理可以在需要時(shí)聯(lián)系人類(lèi)。所以你可能有10個(gè)代理在后臺(tái)并行運(yùn)行,每隔一段時(shí)間,它可能需要向人類(lèi)尋求澄清。所以你有一個(gè)電子郵件收件箱,代理向你發(fā)送像“幫幫我,我在這里,我需要幫助”之類(lèi)的信息,然后你在那個(gè)點(diǎn)幫助它。
另一個(gè)類(lèi)似的是審查它的工作,對(duì)吧?所以我認(rèn)為這非常強(qiáng)大。我們已經(jīng)看到很多代理在寫(xiě)不同類(lèi)型的東西,進(jìn)行研究,像研究風(fēng)格的代理,有一個(gè)很棒的項(xiàng)目,GPT Researcher,它有一些非常有趣的架構(gòu),圍繞代理。我認(rèn)為這是這種審查類(lèi)型的好地方。好吧,你可以讓代理寫(xiě)第一稿,然后我可以審查它。我可以基本上留下評(píng)論。
而且,有幾種不同的方式可以實(shí)際發(fā)生。所以你知道你,最不涉及的方式是,我一次留下一堆評(píng)論,將它們發(fā)送給代理,然后它去修復(fù)所有的問(wèn)題。另一個(gè)非常有趣的UX是這種,像,同時(shí)協(xié)作的。就像Google文檔,但人類(lèi)和代理同時(shí)工作,我留下評(píng)論,代理修復(fù)那個(gè),當(dāng)我在做另一個(gè)評(píng)論或類(lèi)似的事情。我認(rèn)為我認(rèn)為這是另一種UX。這是相當(dāng)復(fù)雜的設(shè)置和工作。
還有一種其他的UX事情,我認(rèn)為很有趣,就是這些代理如何從這些交互中學(xué)習(xí),對(duì)吧?我們談?wù)摰氖且粋€(gè)人在某種程度上,糾正代理或給予反饋。
如果我必須給出相同的反饋100次,那將是非常令人沮喪的,那會(huì)很糟糕。所以,是什么系統(tǒng)架構(gòu)使它能夠開(kāi)始從中學(xué)習(xí),我認(rèn)為這非常有趣。
而且,所有這些都有待解決,我們?cè)谂宄@些事情的游戲中還非常早期。但我們確實(shí)花了很多時(shí)間思考這些問(wèn)題。
4、LangChain不介入模型層和數(shù)據(jù)庫(kù)層
帕特·格雷迪:事實(shí)上,這提醒了我,我不知道你是否知道這一點(diǎn),但你因?yàn)樵陂_(kāi)發(fā)者社區(qū)中的活躍程度以及非常關(guān)注開(kāi)發(fā)者社區(qū)中正在發(fā)生的事情,以及開(kāi)發(fā)者社區(qū)中人們遇到的問(wèn)題而聞名。
所以L(fǎng)angChain直接解決的問(wèn)題,你正在建立一個(gè)企業(yè)來(lái)解決。然后我想你遇到了很多其他問(wèn)題,只是范圍之外的。所以我很好奇,在開(kāi)發(fā)者嘗試使用LLM構(gòu)建或嘗試構(gòu)建AI的今天遇到的問(wèn)題中,有哪些有趣的問(wèn)題你們沒(méi)有直接解決,也許如果你們有另一個(gè)企業(yè),你們會(huì)解決?
哈里森·蔡斯:我的意思是,我認(rèn)為兩個(gè)明顯的領(lǐng)域是,在模型層和數(shù)據(jù)庫(kù)層。
所以我們沒(méi)有構(gòu)建向量數(shù)據(jù)庫(kù),我認(rèn)為思考正確的存儲(chǔ)是什么非常有趣。但你知道我們沒(méi)有在做那個(gè)。我們沒(méi)有構(gòu)建基礎(chǔ)模型。我們也沒(méi)有進(jìn)行模型的微調(diào),像我們想要幫助數(shù)據(jù)整理的部分。絕對(duì)不是。但我們沒(méi)有像為微調(diào)構(gòu)建基礎(chǔ)設(shè)施那樣做。有Fireworks和其他公司。我認(rèn)為這些非常有趣。我認(rèn)為這些可能是人們目前立即遇到的基礎(chǔ)設(shè)施層面的問(wèn)題。
我確實(shí)認(rèn)為有第二個(gè)問(wèn)題,有第二個(gè)思考過(guò)程,那就是,如果代理確實(shí)成為未來(lái),比如,會(huì)出現(xiàn)什么樣的基礎(chǔ)設(shè)施問(wèn)題?正因?yàn)槿绱耍裕艺J(rèn)為我們現(xiàn)在說(shuō),我們會(huì)或不會(huì)做這些事情還為時(shí)過(guò)早?因?yàn)樘拱渍f(shuō),我們還沒(méi)有到達(dá)代理足夠可靠,有這種整個(gè)代理經(jīng)濟(jì)出現(xiàn)的地步。
但我認(rèn)為,你知道,代理的身份驗(yàn)證,代理的許可,代理的付款,有一個(gè)非常酷的啟動(dòng),為代理支付,實(shí)際上,這是相反的,代理可以付錢(qián)給人類(lèi)做事,對(duì)吧?所以我認(rèn)為,我認(rèn)為這真的很有趣,比如如果代理真的變得普遍,比如,需要什么工具和基礎(chǔ)設(shè)施,我認(rèn)為這與開(kāi)發(fā)者社區(qū)需要什么東西來(lái)構(gòu)建 LLM 應(yīng)用程序有點(diǎn)不同,因?yàn)槲艺J(rèn)為 LLM 應(yīng)用程序就在這里。代理商開(kāi)始到達(dá)這里,但還沒(méi)有完全到達(dá)這里。所以我認(rèn)為這些類(lèi)型的公司的成熟度不同。
5、微調(diào)與提示是互補(bǔ)的
索妮婭·黃:哈里森,你提到了微調(diào),以及你們不會(huì)去那里。看起來(lái)提示和架構(gòu)調(diào)用以及微調(diào)幾乎是相互替代的。
你如何看待當(dāng)前人們應(yīng)該使用提示與微調(diào)的狀態(tài),以及你認(rèn)為這將如何發(fā)揮作用?
哈里森·蔡斯:是的,我不認(rèn)為微調(diào)和認(rèn)知架構(gòu)是相互替代的。我不認(rèn)為它們是,實(shí)際上我認(rèn)為它們?cè)诤芏喾矫媸腔パa(bǔ)的,因?yàn)楫?dāng)你有更多定制的認(rèn)知架構(gòu)時(shí),你所要求的每個(gè)代理、每個(gè)節(jié)點(diǎn)或系統(tǒng)的每一部分所做的范圍就會(huì)變得非常有限。這實(shí)際上對(duì)微調(diào)來(lái)說(shuō)非常非常有趣。
6、LangSmith和LangGraph?
索妮婭·黃:也許實(shí)際上,就這一點(diǎn)而言,你能談一談LangSmith和LangGraph嗎?就像帕特剛剛問(wèn)你的,你沒(méi)有解決什么問(wèn)題?我很好奇,你解決了什么問(wèn)題?以及它與我們之前討論的所有智能體問(wèn)題有何關(guān)聯(lián),比如,你所做的使?fàn)顟B(tài)管理更易于管理,使智能體更可控,你的產(chǎn)品如何幫助人們解決這些問(wèn)題?
哈里森·蔡斯:是的,也許回溯一點(diǎn)。當(dāng)LangChain剛發(fā)布時(shí),我認(rèn)為L(zhǎng)angChain開(kāi)源項(xiàng)目確實(shí)解決和處理了幾個(gè)問(wèn)題。
我認(rèn)為其中之一基本上就是為所有這些不同的組件標(biāo)準(zhǔn)化接口。所以我們有大量的集成與不同的模型、不同的向量存儲(chǔ)、不同的工具、不同的數(shù)據(jù)庫(kù)等等。所以這一直是LangChain的大賣(mài)點(diǎn),以及人們使用LangChain的原因。
在LangChain中,也有一些更高層次的接口,可以輕松地開(kāi)始使用RAG或SQL問(wèn)答或其他東西。還有一個(gè)更底層的運(yùn)行時(shí),用于動(dòng)態(tài)構(gòu)建鏈。
通過(guò)鏈,我的意思是,我們可以稱(chēng)它們?yōu)镈AG,就像定向流程。我認(rèn)為這種區(qū)分很重要,因?yàn)楫?dāng)我們談?wù)揕angGraph以及LangGraph存在的原因時(shí),它是要解決一個(gè)稍微不同的編排問(wèn)題,即你想要這些可定制和可控的具有循環(huán)的東西,它們?nèi)匀辉诰幣趴臻g內(nèi)。但我在鏈和這些循環(huán)和循環(huán)之間做了這種區(qū)分。
我認(rèn)為,有了LangGraph,當(dāng)你開(kāi)始有循環(huán)時(shí),就會(huì)出現(xiàn)很多其他問(wèn)題,其中之一是持久層,這樣你就可以恢復(fù),你可以讓它們?cè)诤笈_(tái)以異步方式運(yùn)行。所以我們開(kāi)始越來(lái)越多地考慮部署這些長(zhǎng)期運(yùn)行的、循環(huán)的、人類(lèi)參與的應(yīng)用程序。所以我們將開(kāi)始越來(lái)越多地解決這個(gè)問(wèn)題。
然后跨越所有這些的是LangSmith,自從公司成立以來(lái),我們一直在研究它。那是可觀(guān)測(cè)性和LLM應(yīng)用程序的測(cè)試。所以從一開(kāi)始,我們就注意到你將LLM置于系統(tǒng)的中心。LLM是非確定性的,你必須要有良好的可觀(guān)測(cè)性和測(cè)試,以便有信心將其投入生產(chǎn)。
所以我們開(kāi)始構(gòu)建LangSmith。它與LangChain一起使用。還有像提示中心這樣的東西,以便你可以管理提示,人類(lèi)注釋隊(duì)列以允許這種人類(lèi)審查,我實(shí)際上認(rèn)為這是至關(guān)重要的,像在所有這些中,重要的是要問(wèn),這里實(shí)際上有什么新鮮事?我認(rèn)為L(zhǎng)LM的主要新特性是它們是非確定性的,所以可觀(guān)測(cè)性更加重要。然后測(cè)試也更加困難。具體來(lái)說(shuō),你可能希望人類(lèi)比審查軟件測(cè)試更頻繁地審查事情。所以很多工具、路由和LangSmith在這方面有所幫助。
7、現(xiàn)有的可觀(guān)測(cè)性工具,哪些運(yùn)行在LLM上哪些運(yùn)行在其他地方?
帕特·格雷迪:實(shí)際上,哈里森,你有沒(méi)有一個(gè)經(jīng)驗(yàn)法則,現(xiàn)有的可觀(guān)測(cè)性、現(xiàn)有的測(cè)試,你知道,現(xiàn)有的填空將在LLM上工作的地方?與LLM足夠不同,以至于你需要一個(gè)新產(chǎn)品,或者你需要一個(gè)新的架構(gòu),一種新的方法?
哈里森·蔡斯:是的,我在測(cè)試方面想過(guò)這個(gè)問(wèn)題,從可觀(guān)測(cè)性方面。我感覺(jué)這里幾乎更明顯需要新的東西。我認(rèn)為這可能是因?yàn)槭褂枚嗖襟E應(yīng)用程序,你需要一定程度的可觀(guān)測(cè)性來(lái)獲得這些洞見(jiàn)。
我認(rèn)為很多“產(chǎn)品”,像Datadog,我認(rèn)為它們真的很有目標(biāo),它們有這種很好的監(jiān)控。但對(duì)于特定的跟蹤,我不認(rèn)為你可以像使用LangSmith那樣容易地獲得相同級(jí)別的洞見(jiàn)。我認(rèn)為很多人花時(shí)間查看特定的跟蹤,因?yàn)樗麄冊(cè)噲D調(diào)試在特定跟蹤上出錯(cuò)的事情,因?yàn)楫?dāng)你使用LLM時(shí)會(huì)發(fā)生所有這種非確定性。所以可觀(guān)測(cè)性一直感覺(jué)像是需要在那里構(gòu)建新的東西。
測(cè)試非常有趣。我對(duì)此思考了很多,我認(rèn)為有兩個(gè)可能像是測(cè)試中新的獨(dú)特的東西。一個(gè)是基本上就是成對(duì)比較的想法。所以當(dāng)我運(yùn)行軟件測(cè)試時(shí),我通常不會(huì)比較結(jié)果,大多數(shù)情況下,它要么通過(guò)要么失敗。如果我比較它們,可能是比較延遲峰值或類(lèi)似的東西,但不一定是兩個(gè)單獨(dú)的單元測(cè)試的成對(duì)比較。但如果我們看看LLM的一些評(píng)估,人們信任的主要評(píng)估是這個(gè)LLMSYS,有點(diǎn)像競(jìng)技場(chǎng),聊天機(jī)器人競(jìng)技場(chǎng)風(fēng)格的東西,你真的可以并排判斷兩件事。所以我認(rèn)為這種成對(duì)的東西非常重要,與傳統(tǒng)的軟件測(cè)試非常不同。
我認(rèn)為另一個(gè)組成部分基本上是,根據(jù)你設(shè)置評(píng)估的方式,你可能在任何給定時(shí)間都沒(méi)有100%的通過(guò)率。所以實(shí)際上隨著時(shí)間的跟蹤這一點(diǎn)變得很重要,看看你正在改進(jìn)或者至少?zèng)]有退步。我認(rèn)為這與軟件測(cè)試不同,因?yàn)槟阃ǔR磺卸纪ㄟ^(guò)了。
然后第三點(diǎn)只是人類(lèi)參與其中的部分。所以我認(rèn)為你仍然希望人類(lèi)查看結(jié)果,就像,我不想說(shuō)可能是錯(cuò)誤的詞,因?yàn)檫@樣做有很多缺點(diǎn),比如需要很多人類(lèi)時(shí)間來(lái)查看這些東西。但像這些通常比一些自動(dòng)化系統(tǒng)更可靠。如果你將它與軟件測(cè)試進(jìn)行比較,像軟件可以像我通過(guò)看它就知道2等于2一樣好地測(cè)試2等于2。因此,弄清楚如何讓人類(lèi)參與到這個(gè)測(cè)試過(guò)程中也非常有趣、獨(dú)特和新穎。
帕特·格雷迪:我有幾個(gè)非常籠統(tǒng)的問(wèn)題要問(wèn)你。
哈里森·蔡斯:酷,我喜歡一般性的問(wèn)題。
帕特·格雷迪:你在AI領(lǐng)域最欽佩的人是誰(shuí)?
哈里森·蔡斯:這是個(gè)好問(wèn)題。我的意思是,我認(rèn)為OpenAI在過(guò)去一年半里所做的一切都令人難以置信。所以我認(rèn)為Sam,但還有那里的每個(gè)人,我認(rèn)為從各方面來(lái)說(shuō),我都非常欽佩他們做事的方式。
我認(rèn)為L(zhǎng)ogan在那里時(shí)在向人們傳達(dá)這些概念方面做得非常出色。Sam顯然值得很多贊譽(yù),很多事情都發(fā)生了。他們不太知名,但是像David Dohan這樣的研究人員,我認(rèn)為絕對(duì)了不起。他做了一些早期的模型級(jí)聯(lián)論文,我很早就在LangChain上和他聊過(guò)。是的,他對(duì)我思考問(wèn)題的方式有很大的影響。所以我對(duì)他做事的方式有很多欽佩。
另外,你知道,我觸及了所有可能的答案,但是我認(rèn)為像馬克·扎克伯格和Facebook,我認(rèn)為他們用Llama和很多開(kāi)源軟件做得非常好。而且我也認(rèn)為,作為CEO和領(lǐng)導(dǎo)者,他和公司接受這種方式的方式非常令人印象深刻。所以對(duì)此我非常欽佩。
帕特·格雷迪:說(shuō)到這個(gè),有沒(méi)有一位CEO或者領(lǐng)導(dǎo)者,你嘗試效仿他?或者你從他身上學(xué)到了很多關(guān)于你自己領(lǐng)導(dǎo)風(fēng)格的東西?
哈里森·蔡斯:這是個(gè)好問(wèn)題,我確實(shí)認(rèn)為自己更像是以產(chǎn)品為中心的CEO。所以我認(rèn)為扎克伯格在這方面的觀(guān)察很有趣。Brian Chesky,我去年在紅杉基礎(chǔ)營(yíng)地聽(tīng)他演講,非常欽佩他思考產(chǎn)品和公司建設(shè)的方式。所以Brian通常是我對(duì)此問(wèn)題的答案。但我不能說(shuō)我已經(jīng)深入了解了他所做的一切。
帕特·格雷迪:如果你給當(dāng)前或有志于建立AI的創(chuàng)始人一個(gè)建議,你的一個(gè)建議會(huì)是什么?
哈里森·蔡斯:只是建造,嘗試建造?一切都還非常早期,有很多可以建造的東西?
你知道,GPT-5將會(huì)問(wèn)世,它可能會(huì)使你做的一些事情變得無(wú)關(guān)緊要,但在這個(gè)過(guò)程中你會(huì)學(xué)到很多東西。我非常非常相信這是一種變革性技術(shù),所以你對(duì)它了解得越多越好。
帕特·格雷迪:關(guān)于這個(gè)有一個(gè)快速的軼事。只是因?yàn)槲蚁矚g那個(gè)答案。我記得在2023年初我們第一次AI Ascent上,當(dāng)我們剛開(kāi)始更好地了解你時(shí)。我記得你坐在那里整天推代碼。就像人們?cè)谖枧_(tái)上講話(huà),你在聽(tīng)。你坐在那里整天推代碼。所以當(dāng)建議是建造時(shí),你顯然是一個(gè)采納自己建議的人。
哈里森·蔡斯:我想,那是OpenAI發(fā)布插件的那一天,所以有很多要做的事情,我認(rèn)為我沒(méi)有在今年的紅杉Ascent上這么做,所以在這方面讓你失望了。
本文由智能小巨人科技編譯
來(lái)源 | 王錚Silvia(ID:silviawz2023)
原文 | 紅杉美國(guó)