
AI視頻剪輯工具:解鎖創作的無限可能
向值班工程師詢問關鍵服務,他們通常會提到由于警報優先級設置不當而帶來的額外開銷。例如,假設一個分布式應用程序擁有 20 個 API。即使為這些 API 設置了跨延遲、錯誤和流量的基本警報監視器,最終也需要監控和維護 60 個警報定義,這是一項龐大的任務。為了在避免監控盲點和防止警報疲勞之間取得平衡,運營團隊必須對所有事件有清晰的了解,并優先為支持關鍵流量的事件配置警報。
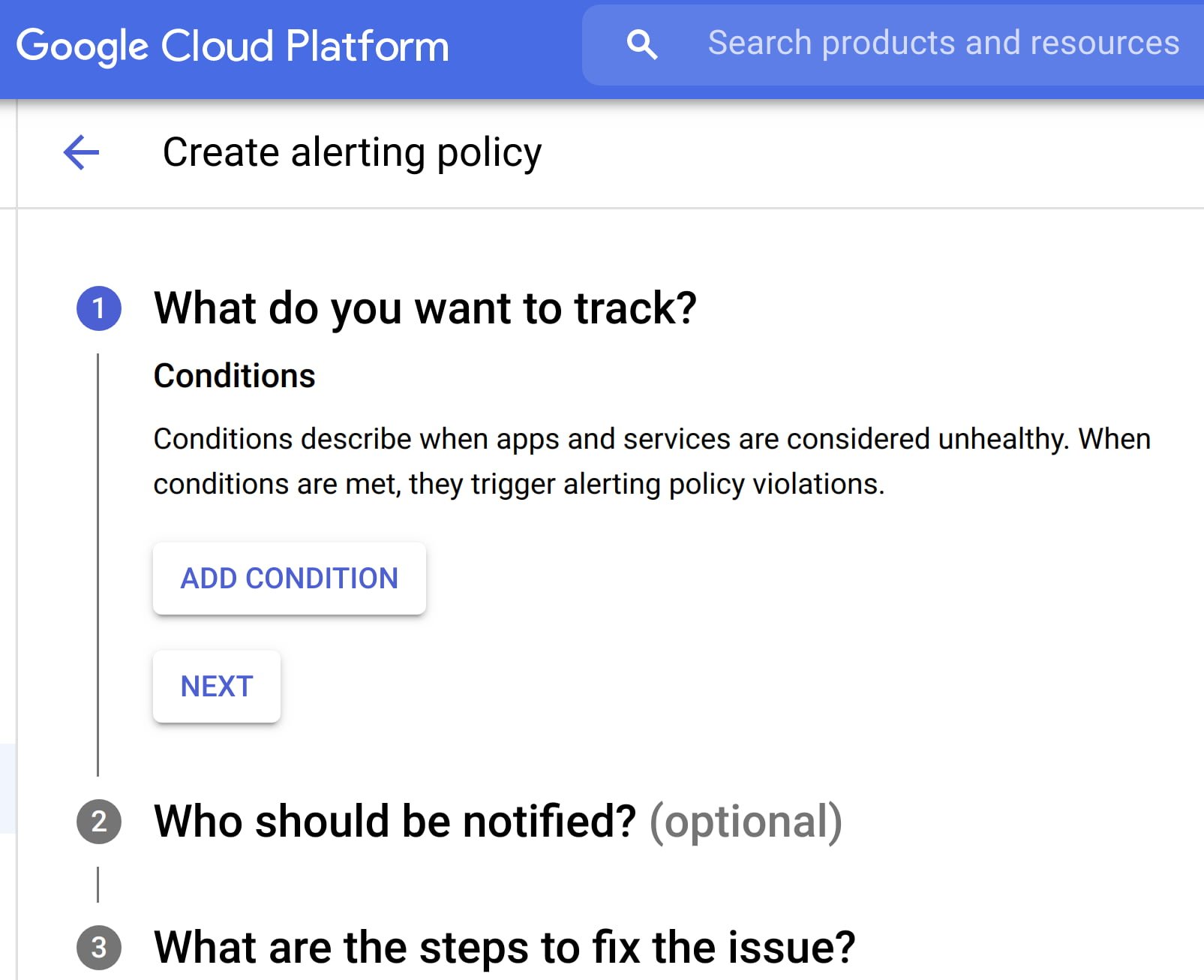
在定義新的警報條件時,應注重質量而非數量,每個新條件都應具備緊急性、可操作性,并且能夠主動或立即對用戶可見。每個警報條件還應包含需要用戶積極參與的智能機制,而不僅僅依賴于自動化響應。Apigee 的 API 監控功能允許根據指標或日志創建警報條件,同時提供可操作的信息(例如狀態代碼、速率等)和詳細的診斷手冊。
在當今的多層系統中,一個團隊遇到的癥狀(“出了什么問題?”)可能是另一個下游系統的原因(“為什么會這樣?”)。即使某些事件不適合作為可操作的警報,故障仍需向下游系統廣播信息,以減輕上游依賴性的影響。在這種情況下,投資于自動化警報、將多個事件分組到通知渠道以及事件跟蹤是必要的。例如,Apigee 允許將警報通知集成和分組到 Slack、PagerDuty、Webhooks 等渠道。
現代生產系統不斷演進,當前罕見的警報可能會變得頻繁且可自動化。類似于工單積壓管理,定期審查警報策略以識別新情況,并使用新的閾值、優先級和關聯性來優化現有警報是必要的。Advanced API Ops 等控制工具利用人工智能(AI)和機器學習(ML)技術,檢測與隨機波動不同的異常流量,幫助定義更加準確的警報條件。
根據谷歌的《站點可靠性工程》一書,通過構建儀表板來實現有效診斷的案例表明,這些儀表板能夠回答有關每項服務的基本問題,通常包括四種黃金信號中的某種形式——延遲、流量、錯誤和飽和度。然而,僅捕捉不同粒度級別的這些黃金指標可能會迅速堆積。與所有軟件系統一樣,監控可能成為一個無盡的復雜深淵,難以更改且維護成本高昂。在同一本書中,創建功能良好的獨立系統的最有效方法是收集和聚合基本指標,并與警報和儀表板配合使用。
對于運行大型 API 程序并由專門團隊進行監控的組織,可以利用 API 管理解決方案中的現成監控儀表板(例如 Apigee 的 API 監控)來收集有關 API 的實時見解,包括 API 性能、可用性、延遲和錯誤。在其他情況下,可以使用云監控等解決方案,這些解決方案提供整個應用程序堆棧的可見性,并通過豐富的查詢語言對各個指標、事件和元數據進行可視化,便于快速分析。利用單一系統對應用程序堆棧進行監控不僅提供了上下文中的可觀察性,還減少了在不同系統之間導航所需的時間。Apigee 客戶可以默認使用 Cloud Monitoring,也可以通過 Cloud Monitoring API 與其他系統集成。
即使在收集和匯總指標之后,擁有有影響力的數據可視化以快速了解問題并在診斷過程中識別相關性也至關重要。在數據可視化中,關注過多的儀表板會導致學習曲線陡峭,并增加每次診斷的平均時間。例如,Apigee API Monitoring 提供以下標準可視化,以平衡簡單性和效率:
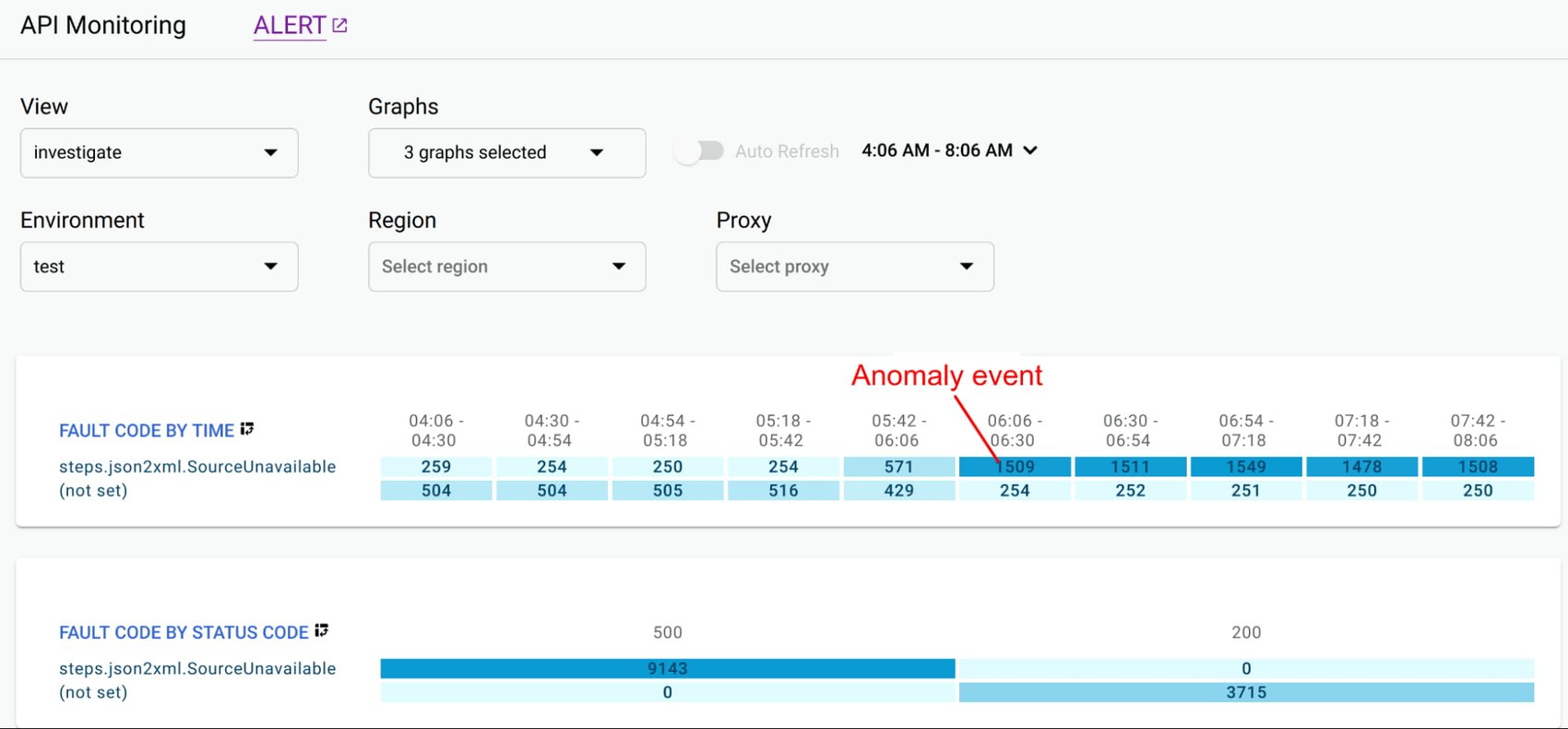
這些可視化工具使運營團隊能夠迅速識別和隔離問題區域,提高診斷效率,確保 API 的穩定運行和高性能。
現代應用程序開發加速了云、容器、API、微服務架構、DevOps、SRE 等技術和實踐的采用。雖然這提升了發布速度,但也增加了應用程序堆棧的復雜性和故障點。例如,客戶請求的緩慢響應可能涉及多個團隊管理和監控的微服務,這些團隊可能未能單獨觀察到任何性能問題。缺乏請求的端到端上下文視圖,幾乎無法隔離高延遲點。
在這種情況下,分布式跟蹤成為 DevOps、運營和 SRE 獲取服務運行狀況、缺陷根本原因或分布式系統性能瓶頸等問題答案的最佳方式。組織應投資使用 OpenCensus 和 Zipkin 等開源標準來檢測分布式應用程序。利用 Cloud Trace 等工具,這些工具具有廣泛的平臺、語言和環境支持,能夠輕松從任何來源(開放儀器或專有代理)獲取數據。
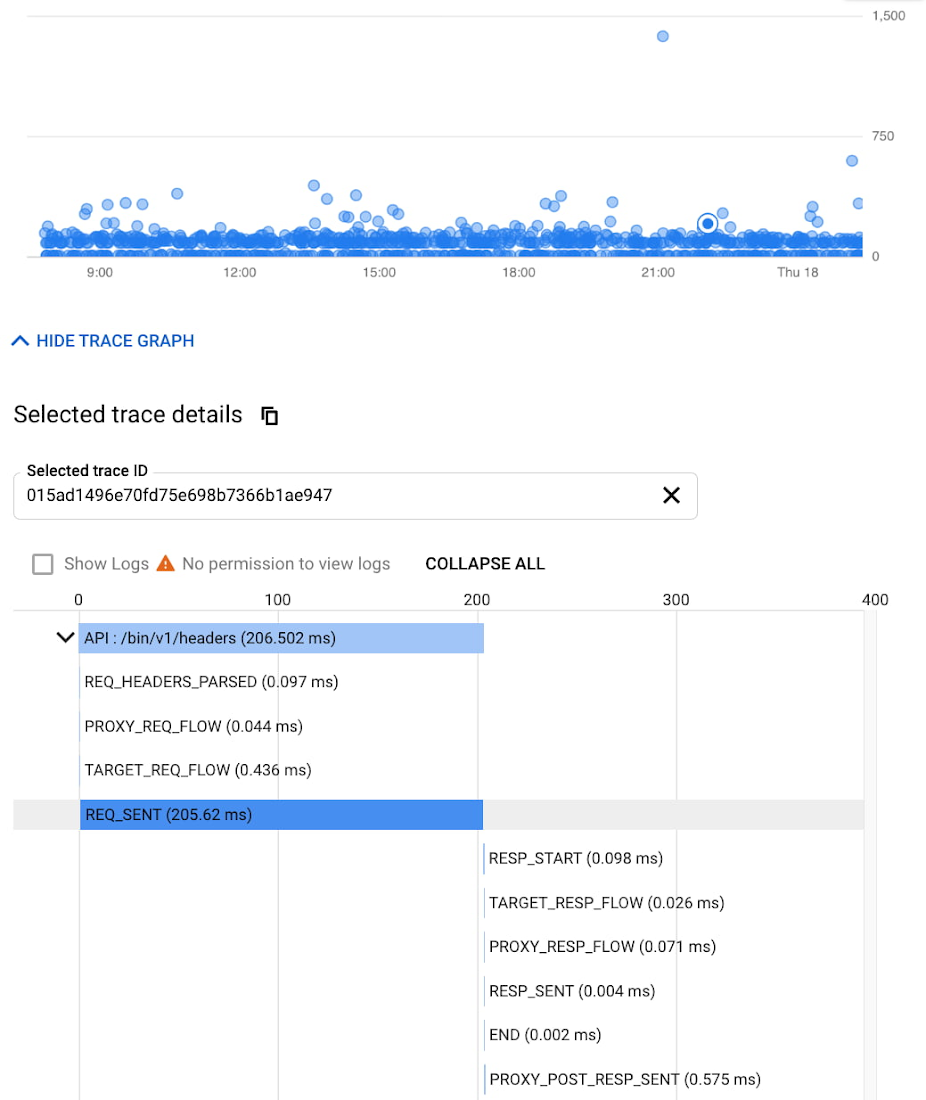
盡管分布式跟蹤有助于縮小問題范圍至特定服務,但在某些情況下,可能需要進一步的上下文來查明根本原因。例如,即使已將性能問題的根源隔離到 API 代理,識別正在執行的多個策略中的正確瓶頸仍然繁瑣。Apigee 的調試工具能夠放大 API 代理流程,深入探查每個步驟的詳細信息,包括策略執行、性能問題和路由等內部細節。
一旦請求跨越多個微服務,分布式跟蹤和調試工具便成為監控策略的關鍵要素。當分布式系統中的每個服務都生成跟蹤數據時,數據量迅速增長,導致經典的“大海撈針”問題。在這種情況下,正確提出問題并在基于頭部的采樣(隨機選擇分析的跟蹤)與基于尾部的采樣(觀察所有跟蹤信息并對異常延遲或錯誤的跟蹤進行采樣)之間進行選擇,變得至關重要,具體取決于應用程序的復雜性。
分布式跟蹤不僅提供了全面的請求路徑視圖,還能夠幫助識別跨服務的性能瓶頸和錯誤源。通過整合分布式跟蹤,運營團隊能夠更快速地定位和解決問題,確保應用程序的高可用性和卓越性能。
Apigee 的 API 監控功能(基于系統內部公開的指標)與現有的監控基礎架構配合使用,能夠縮短平均診斷時間并提升應用程序的彈性。具體而言,運營團隊可以利用以下功能:
使用 Apigee 的 API 監控,可以通過全面的控制保持高應用程序彈性,從而縮短診斷和解決問題的平均時間。
原文鏈接:3 best practices to reduce application downtime with Google Cloud’s API monitoring tools






