
視覺AI
視覺應(yīng)用特別廣泛:從感知增強,感知到視覺最初的一個信息,然后到怎么把這些信息傳輸出去,對這些信息的一個認知和理解,它安全性、搜索,還有生成、編輯重建、 3D 重建以及互動這一系列的技術(shù)。它實際上在感知端,云計算,或者交互端,它是無處不在的,這些也是它存在的非常廣泛的一個原因。
視覺AI 在各個場景的應(yīng)用
比如說我們在手淘就可能會用到其中的一個圖像搜索(一個視覺相關(guān)的技術(shù)),這是當(dāng)前在視覺搜索領(lǐng)域最大的搜索引擎基礎(chǔ)。當(dāng)然也會在特別大的城市級別例如數(shù)字平行世界,這上面也有非常多的視覺相關(guān)的核心技術(shù),同時也包括像醫(yī)療,養(yǎng)豬或者生產(chǎn)安全等等這一系列上面都會用到各種各樣的感知、理解類的視覺技術(shù)。
當(dāng)然還有很多大類,例如生產(chǎn)編輯類的技術(shù),比如說早期的時候做的像 鹿班banner 的生成,或者服裝設(shè)計、包裝設(shè)計,視頻的編輯、短視頻生產(chǎn)等等,這上面用到了一系列的偏生產(chǎn)類的視覺技術(shù),大家也能夠感知到它在各個地方都有網(wǎng)上的一個應(yīng)用。
“人”的一天中用到的視覺技術(shù)

用另外一個視角,比如說我們一個人一天當(dāng)中從起床,到工作,到去玩或者社交等等一系列的動作中,其實也有很多能夠用到視覺技術(shù)的地方。比如要打卡時要用自己的照片生成一個卡牌,從圖片中摳出人像,然后要通過打卡機或考勤機識別是誰。或者除了識別人臉以外還需要識別有什么一系列的動作?比如說做一些仰臥起坐,俯臥撐等等這一系列的。
或者有時可能照片不是那么清晰,老照片做一些畫質(zhì)的提升或者美化或者變成數(shù)字人等等,這些都是在生活當(dāng)中與視覺技術(shù)相關(guān)的。
視覺技術(shù)分類樹
前面是一些示例,是從行業(yè)/人類生活碰到的視覺技術(shù),接下來我們也可以從這幾個維度去分享,視覺一般有這么幾種模態(tài):
最早研究的是平面圖像-二維的圖像,如果二維圖像我們加上一個時間軸的信息,變成有時間序列的,那就變成視頻的模態(tài)。
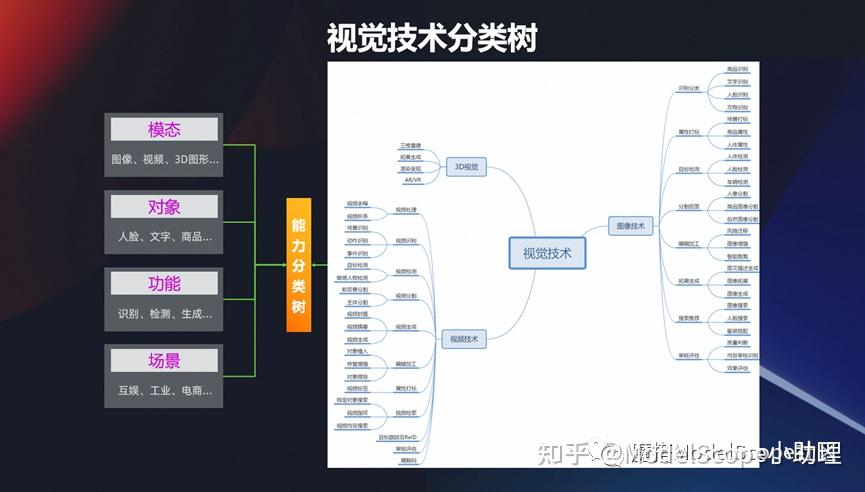
前一陣子元宇宙特別火的時候,就是在原來 2D 這種維度上再加一個維度,它變成一個 3D 的一個維度,然后從這些維度其實可以區(qū)分這種模態(tài)的一個分類的方式。
從另外一個維度看。視覺真正的目標千變?nèi)f化的,針對人,文字或者商品的都有,所以從這個維度又可以分出若干個技術(shù)。
還有一個最基本的,視覺技術(shù)是為了完成什么樣的功能,用來識別/檢測/生成還是分割?從這個維度也可以去區(qū)分。
技術(shù)想要真的在行業(yè)當(dāng)中應(yīng)用,還根據(jù)不同的場景,可以細分成互娛互樂,社交,工業(yè)或電商。
所以從 4 個維度,可以對視覺技術(shù)進行一個相對比較合理的分類。從視覺樹中可以看到視覺在模態(tài)、對象、功能、場景上面有各種各樣的應(yīng)用,這是從分類的體系來說。
趨勢:從理解到生產(chǎn)
可以看到,人一出生而首先我要認識這個世界,理解世界。像讀文章要先能夠讀懂,到后面可以寫文章,然后可以去修改我的視覺內(nèi)容,可以生產(chǎn)這些視覺內(nèi)容。所以趨勢肯定是從先理解,再到生產(chǎn)。
最近大家關(guān)注 AIGC 的內(nèi)容是偏生產(chǎn)編輯這一類的。
趨勢:從小到大,從單到多,從閉到開
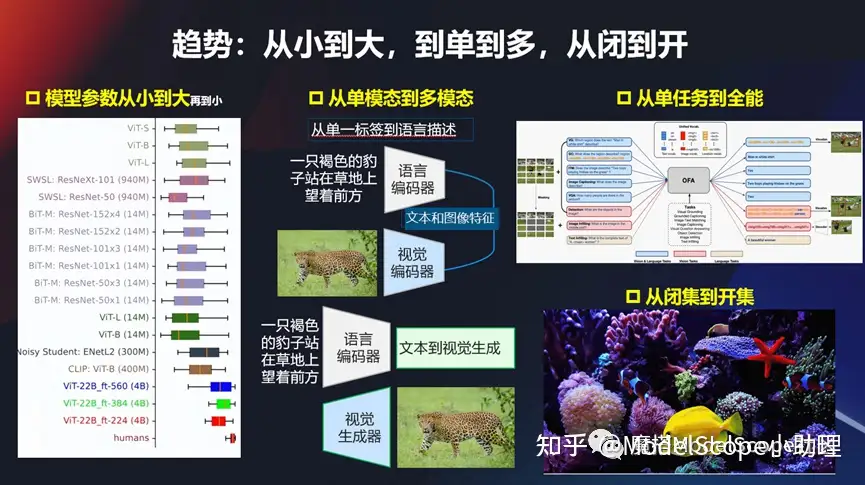
(1)從小到大
另外一個趨勢,像現(xiàn)在各種各樣的模型,從早期的比較經(jīng)典的、比較小的模型,到現(xiàn)在的模型越來越大,像初期的比較經(jīng)典的 VGG 的 ,到現(xiàn)在 VIT 的再到現(xiàn)在多模態(tài)的這種技術(shù),發(fā)展得越來越快,所以這個參數(shù)量也會越來越大。從萬級別、百萬級別、千萬,再到億,還有更大萬億級別的,模型參數(shù)從小到大,也是當(dāng)前的一個趨勢。
(2)從單模態(tài)到多模態(tài)
從單模態(tài)到多模態(tài),尤其大模型開始流行起來以后,是非常典型的一種趨勢。早期給一張圖,打一個標,或者給個分值等。現(xiàn)在基本上是圖相對自然語言的描述,作為訓(xùn)練模型的輸入,同時進行encoding,然后再來進行訓(xùn)練。現(xiàn)在大部分都是文本,視覺或者圖像這一塊的多模態(tài)。當(dāng)然在對聲音或者對其他的東西也可能是多模態(tài)的方式。總而言之,從單模態(tài)到多模態(tài)這個趨勢非常明顯。
(3)從單任務(wù)到全能
以前只解決檢測問題,或者只解決分割問題,甚至它只能解決對某一個特定對象,特定場景的。但是從不久以前,阿里做了一個新的模型開始,就開始強調(diào)全能/多功能的模態(tài),既可以做視覺的任務(wù),也可以做文本的任務(wù)等等。所以從單任務(wù)到多任務(wù)的進行,也是一種趨勢。這種趨勢最后會發(fā)展成什么樣的狀態(tài)?是不是真的能夠從一個全能/全任務(wù)的模型解決所有問題?這個可能有待考察和發(fā)展。
(4)從閉集到開集
另外可能還有一個經(jīng)常會遇到的方式,以前的模型或者數(shù)據(jù)集,只能在一些閉集當(dāng)中去做,比如說我們在訓(xùn)練得到它的標簽就是在這個集合當(dāng)中,當(dāng)出來openset 的一個問題,它能不能解?其實現(xiàn)在這個趨勢也是比較明顯的,尤其是像現(xiàn)在的多模態(tài)大模型,其實它很多的時候能夠解決就這種這個問題,可以解決以前在訓(xùn)練的過程當(dāng)中或者是閉集的狀態(tài)走上一個開集的狀態(tài),這也是其中一個趨勢。
趨勢:基于知識和反饋的訓(xùn)練

在訓(xùn)練的時候,可能需要把這種人的知識以及反饋,例如像 ChatGPT 半監(jiān)護,半反饋的強化學(xué)習(xí)(RHLF)的方式加入到訓(xùn)練當(dāng)中去,這也是一個趨勢,使得我們的模型的表征能力越來越強。
視覺感知理解技術(shù)
事實上視覺感知理解,應(yīng)該是人類獲取認識這個世界最主要的最基本的任務(wù)。
視覺理解

例如最基礎(chǔ)需要先識別上方圖像中有什么東西?想知道是個貓還是個狗?然后要知道這個貓和狗在圖像當(dāng)中的位置,這是更進一步。當(dāng)要知道每一個像素是什么東西的時候,就要做分割的問題,這是最經(jīng)典的幾類任務(wù)。
當(dāng)然視覺理解還有一些表征或者識別行為等等一系列的任務(wù)。總的來說,基本上它的模式是輸一個圖,然后出來一個標簽,一個 tag 這種方式,也可能是一個 score 或者是一個數(shù)字等等,所以我們可以從日常的生活當(dāng)中發(fā)現(xiàn)非常多的有關(guān)于識別或者檢測、理解相關(guān)的一些任務(wù)。
人的識別及檢測

最經(jīng)典的是去地鐵站坐車或者坐飛機,打卡等等,或者要識別一個人,或者識別有多少人等等這一系列的任務(wù),都是屬于這類的。
生物識別系列模型
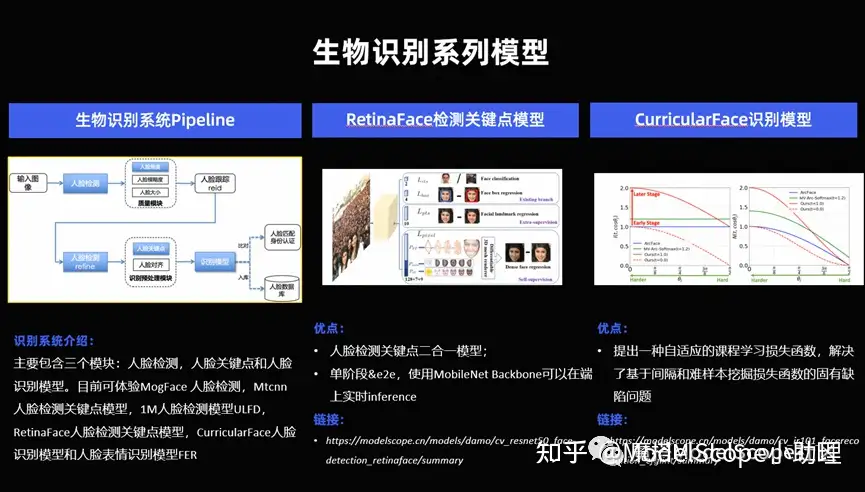
識別系列模型其實有很多,這里只舉個幾個最典型的,比如說對人臉的一個關(guān)鍵點識別, 1: 1 的識別或者 1: n 的識別。
(1)對人臉的識別來說,有三個關(guān)鍵的核心的模塊,對于人臉的檢測,人臉關(guān)鍵點的識別,人臉的識別本身。當(dāng)然還有一些前序的,例如人臉的質(zhì)量,圖像質(zhì)量的糾正,還有事后的等等也有非常多的模型,在人臉這個最經(jīng)典的研究的最早的視覺任務(wù),上面也另外沉淀非常多的技術(shù)。這個技術(shù)可以在 Model Scope 的官網(wǎng)去訪問。

(2)分類檢測上面也有非常多實際的任務(wù)可以去研究。

(3)在工業(yè)場景下面,例如給一個電池版,或者給一個果凍,能不能檢測到其中有些瑕疵?這些都可能是現(xiàn)實當(dāng)中碰到的問題,這可能是檢測問題,也可能是分割問題,或者是識別問題。這就是對這種工業(yè)場景下面的一個場景理解。

(4)達摩院也開放了DAMO-YOLO這個非常厲害的檢測模型,它可以兼顧速度和精度同時去識別。大家都知道,視覺任務(wù)做到最后都面臨精度、速度、成本等等的兼顧平衡,只有這樣的話才能夠使得這個模型真正的能夠落到行業(yè)當(dāng)中去,所以這是經(jīng)典的檢測模型,可以對單個人檢測,也可以對多種目標、多種物體、動態(tài)的、靜態(tài)的等等都可以去做檢測。

(5)延展一下,自然圖像例如手機照片,是普通的 RGB 圖,但事實上還有很多,例如CT 圖還是 X光,MRI ,超分,超聲或者是 PET 等等這一系列的針對物體或者人體內(nèi)部的掃描結(jié)構(gòu)得到的影像,也算一種特殊的一種視覺。在這個層面也有很多事情可做,比如說對各個器官的一個分割/檢測/識別,對病灶/病的種類等等這一系列,這些都是對人的內(nèi)部,外部的感知理解的一系列的視覺技術(shù)。

(6)前面舉的例子都是對靜態(tài)的識別,同時可能對一個動態(tài)的視頻,想要知道這個人做什么動作,識別出來是什么動作,以及做的標不標準,或者對人進行一個教學(xué),做這個動作做得好不好?做了多少個?等等這一系列技術(shù)其實就是對人體的關(guān)鍵點,以及對人體連起來骨架,基于這個去做的動作識別。這個可以用于做一些app,或者記錄今天做了哪些事情等有意思的應(yīng)用。

(7)在城市級別或者是交通感知,交通事件等也有很多的視覺技術(shù)可以使用,比如識別車或者是交通是不是有擁堵,事故,違法等等都是視覺技術(shù)可以發(fā)揮價值的地方。此類發(fā)揮價值是通過城市級別,或者交通系統(tǒng)級別,對實時采集到的攝像頭的數(shù)據(jù),進行分析理解。所以這塊除了算法技術(shù)以外,實際上還有一系列系統(tǒng)級的工程技術(shù)去配合的系統(tǒng)。

分割摳圖-難點
除了前面的識別檢測以外,還有技術(shù)相對不太一樣的地方。比如說可能需要針對圖像像素點是屬于什么類別的檢測識別問題,實際上屬于分割摳圖的問題。
如果經(jīng)常使用PS等,就會經(jīng)常使用到它。比如面對復(fù)雜背景/遮擋/發(fā)絲/或者是透明材質(zhì),像婚紗等等這一系列都是在識別當(dāng)中會遇到的挑戰(zhàn)。這些挑戰(zhàn) 還有一個很大的問題在于標注成本非常多,導(dǎo)致高質(zhì)量的數(shù)據(jù)本身也會嚴重不足。
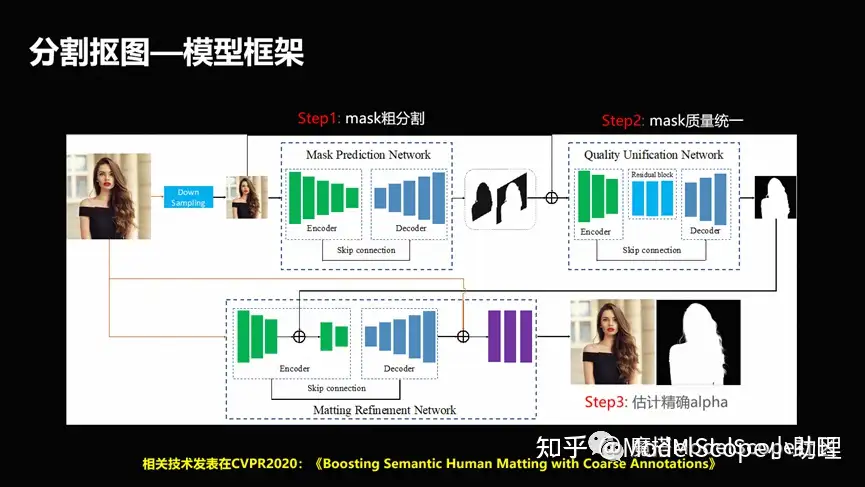
(1)分割摳圖-模型框架
在解決這個問題上也有很多的方法,這里只列出一個例子。例如解決高質(zhì)量的標注語料問題時,設(shè)計了粗分割精分割相互結(jié)合的方式,去促使這個方法可以快速的既能夠兼顧粗分割,就是低級分割所帶來的圖像數(shù)量比較多,同時我們又能夠利用精分割的質(zhì)量比較高的情況,使得這個分割能夠兼顧效果和數(shù)量上的統(tǒng)一。
(2)分割摳圖-效果展示
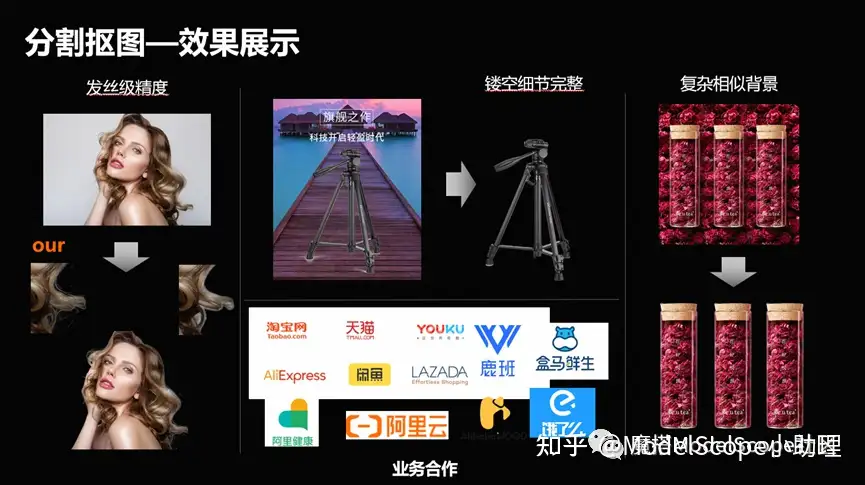
發(fā)絲級別的這種精度,或者圖像它是鏤空,或者是它跟背景相似的時候,怎么把它分割出來?這是一個非常有技術(shù)含量和應(yīng)用面在里面的事情。
(3)分割摳圖-圖元解析

同時還有一個非常有意思的分割,是更復(fù)雜的圖源解析的一個問題。如果大家用過 PS 就應(yīng)該知道,一張圖如果是 PSD 結(jié)構(gòu)的話,它實際上是多個圖層合起來變成一個圖像的。
但反過來給一張圖,你是否能把里頭的各種元素,各種圖層反向識別出來,分割出來?這就是一個對圖像的反向解析的過程,這是相對更復(fù)雜的一個對圖像的理解的問題。
感知理解系列開放模型
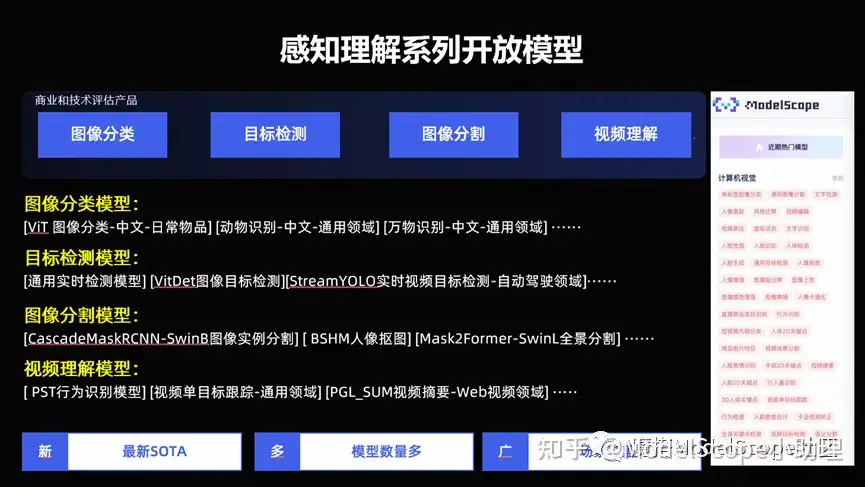
在 ModelScope 上面開放了這么幾大類,包括分類、檢測、分割,還包括視頻里的一系列的理解能力,這個是最基礎(chǔ)的一系列能力。
當(dāng)然另外一系列能力例如先認識世界、感知理解到了世界,然后這個時候我要改造或者是生成我們的視覺信息,那么我們就可以歸結(jié)為生成編輯類。
經(jīng)典生成編輯技術(shù)
編輯類的大家可能知道,由于現(xiàn)代 ATC 大模型技術(shù)發(fā)展,可以把它分成兩個階段,一個階段是經(jīng)典的生成編輯技術(shù),這里主要是指這一塊。
視覺生產(chǎn)的定義
相當(dāng)于輸入一個視覺,然后出來一個視覺,產(chǎn)生一個新的視覺表達,它產(chǎn)生的不是一個標簽,也不是一個特征。而且它輸出的和輸入的還不一樣。
比如說經(jīng)典的我生成一個從 0 到1,或者是我有了一個圖,我生成更多的圖是從 1 到n,或者是我有一個摘要,或者是一個升維,包括前面的平面圖像到視頻,或者是從視頻到 3D 的圖像,當(dāng)然還有一些從 a 到b 增強/變換,或者我把兩張圖合到一起,或者是想從一個視覺當(dāng)中移除一個東西。
視覺生產(chǎn)通用框架
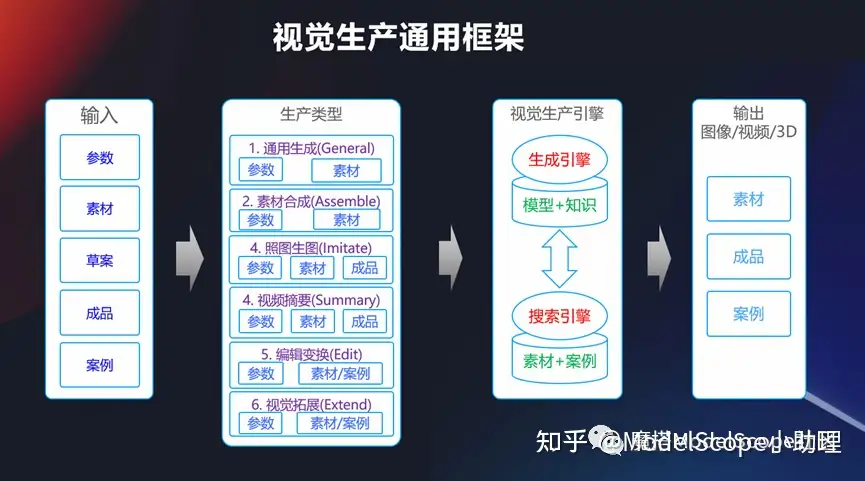
從上面可以看到,視覺生產(chǎn)實際上是包含了非常多的任務(wù),這其中最經(jīng)典的,是一個通用的框架,我們可以輸入?yún)?shù)、素材或者是各種各的成品,當(dāng)然也可以在早期的時候通過模型+知識的方式生成引擎去做,也可以通過一個搜索引擎去做,找相似的素材和案例,去產(chǎn)生一個輸出,所以這是個通用框架。
視覺生成技術(shù)發(fā)展
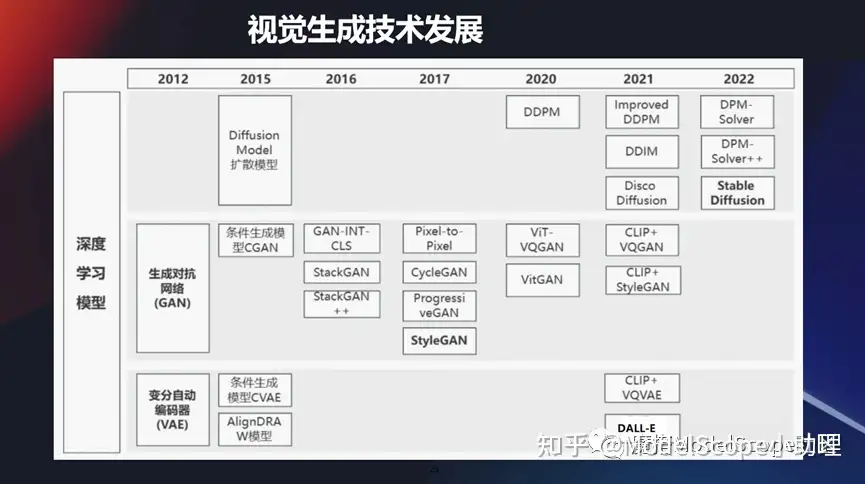
當(dāng)然視覺生成技術(shù)其實發(fā)展的時間也比較長,雖然它跟理解力技術(shù)對比還是在之后的。包括我們最早些時候,大家應(yīng)該知道,大概11年 12 年的時候,一個非常火的模型叫 GAN,它可以通過對抗的方式,通過判別器和識別器然后對抗的方式來獲得圖像的生成。
它是早期的一個最經(jīng)典的生成式模型。當(dāng)然之后也有很多的技術(shù)在發(fā)展,像 GAN 技術(shù)它也會有很多一系列的發(fā)展,包括條件生成CGAN 或者是styleGAN等等這一系列技術(shù)在當(dāng)前還在不斷地往前發(fā)展。
當(dāng)然現(xiàn)在也有兩大類非常火的技術(shù),像那個 VAE 技術(shù),變分自動編碼器,這里面也有條件生成。運用的面最廣的,當(dāng)前最火的是基于擴散模型方式的一個生成方式。
視覺生成-五個關(guān)鍵維度
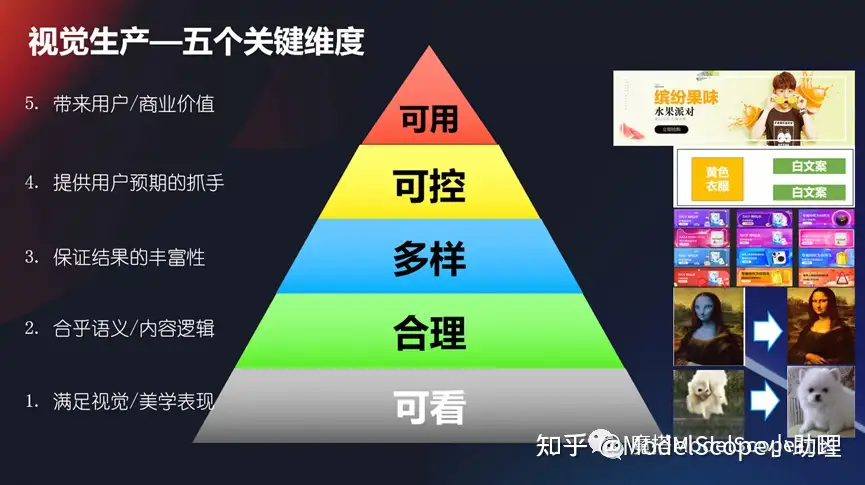
要想使得視覺生產(chǎn)技術(shù)或者生產(chǎn)技術(shù)能滿足業(yè)務(wù)的需要,那么我們應(yīng)該在哪些方面來衡量它呢?
(1)比如說我們首先肯定要滿足視覺或者美學(xué)的一個表現(xiàn),是可看的,不能說我們生成一個東西你看起來都不認識或者不知道,那這個肯定是沒法滿足的。
(2)第二個它相對來說要合理,它要合乎語義的邏輯或者是內(nèi)容的邏輯,這點也很重要,我不能說生成個a,結(jié)果你給我個b這也不行。
(3)還有一個你要保證你結(jié)果的豐富性,它是個多樣可變的,你不能說每次生成的都一模一樣,它也是一個不是那么可用的狀態(tài)。
(4)還有它要是可控的,我想要生成什么樣子,它就要生成什么樣子。不能說生成a,結(jié)果它生成b,或者說我沒法控制它,這個也是不成的,所以我們要提供一個給用戶預(yù)期的抓手。
(5)最后達成一個目標,使得這個結(jié)果生成結(jié)果是可用的,它能夠給用戶帶來使用價值或者商業(yè)價值,這是最核心的。
所以從可看、合理、多樣、可控和可用上面這幾個維度來看,我們可以回過頭去看一看我們的視覺生產(chǎn)這個過程,這個技術(shù)是不是合理的。
視頻增強相關(guān)能力
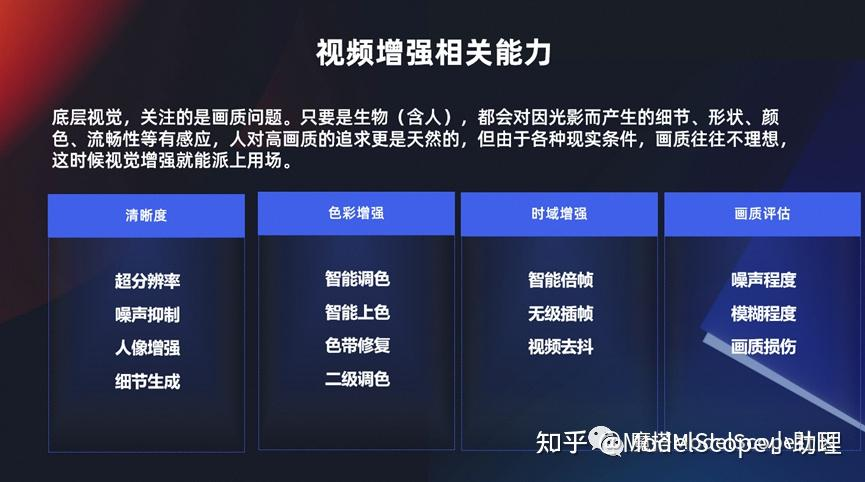
前面介紹到有若干種視覺生產(chǎn),這里介紹兩個最主要的。第一個就是視頻增強技術(shù),實際上是滿足從 a 到 b 的一個過程。如果大家了解過底層視覺,就是比如說我一個視覺,那么我一出生以來,我不管是人,一只狗,或者是一個貓,或者是只要有眼睛能感知光的,那么它可能就對這個圖像的清晰度、細節(jié)或者色彩或者它是否流暢等等這一方面東西它天然的就能夠感知得到,這就是所謂的底層視覺。
對底層視覺我們永遠是追求更高畫質(zhì)的視覺表現(xiàn),包括我們在清晰度上面更清晰,然后在色彩上面要更鮮艷,然后在流暢度上面要刷新的更快,這些都是跟視頻增強相關(guān)的一系列能力。
圖像與視頻的畫質(zhì)問題

視頻增強的問題從哪來的?其實有很多,比如從采集,運輸處理,還有存儲等等各方面,由于我們早期的時候在拍攝圖像,它的設(shè)備/環(huán)境/其它的東西導(dǎo)致的各種各樣的內(nèi)容不夠,甚至更早期的時候圖像只有黑白等情況。這些情況基本上可以分為三大類:
(1)一大類是細節(jié)損傷,分辨的不夠,或丟失了一些信息,這是第一類的。
(2)第二類色彩表現(xiàn)不好,以前可能是黑白的,后面只有8bit,或者就是馬賽克形式,10bit的像素的表達,所以這種色彩的表現(xiàn),有可能是RGB三個通道,也可能ARGB的四個通道。這一系列也是屬于色彩表現(xiàn)添加的問題。
(3)或者可能是跳幀的,它連續(xù)性不夠流暢等等。從這幾方面來說的話,從傳統(tǒng)的圖像處理理論當(dāng)中來說,想要把這些問題修復(fù)其實是非常困難的。所以也就是相當(dāng)于在這幾個方面,可以有很多的技術(shù)去專門攻克這一塊。
空域增長-超分
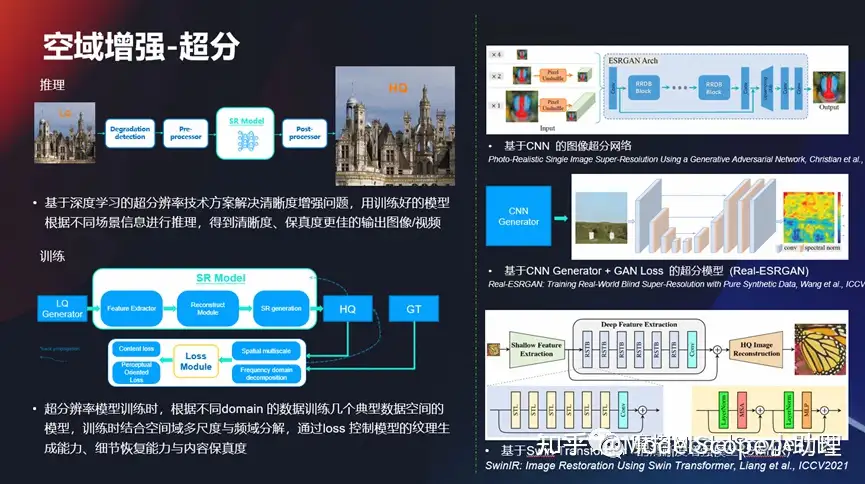
在空域增強上面,在細節(jié)上面做一些超分的任務(wù),超分任務(wù)其實是比較典型的底層視覺的問題,而且這塊問題其實發(fā)展的時間也非常長了,從早期的基于 CN 的圖像超分,一直到現(xiàn)在利用這種domain手段去做這種增強任務(wù),所以這一系列的技術(shù)也在不停地往前發(fā)展,使得的效果也不斷地去往前提升,使得從早期的720P,到1080P,然后到后面的4K、2K,或者甚至到現(xiàn)在的 8K 的視頻,細節(jié)越來越豐富,這是最基本的問題。
色彩增強示例

另外色彩,有時可能不是那么通透,或者是帶有一點點灰蒙蒙這種感覺,使得從8位的一個像素深度變成一個 10 位,或使得色彩表現(xiàn)力更豐富。上圖這里應(yīng)該是從 SDR 到HDR,大家用過電視機或者是比較好的一些手機都支持 HDR 的方式,但早期的時候很多是都是 SDR 的格式,所以在這些方面都可以做很多的事情,使得即便當(dāng)時的視頻質(zhì)量不是那么好,經(jīng)過 AI 的處理以后它可以變得更好一些。
圖像去噪開放模型
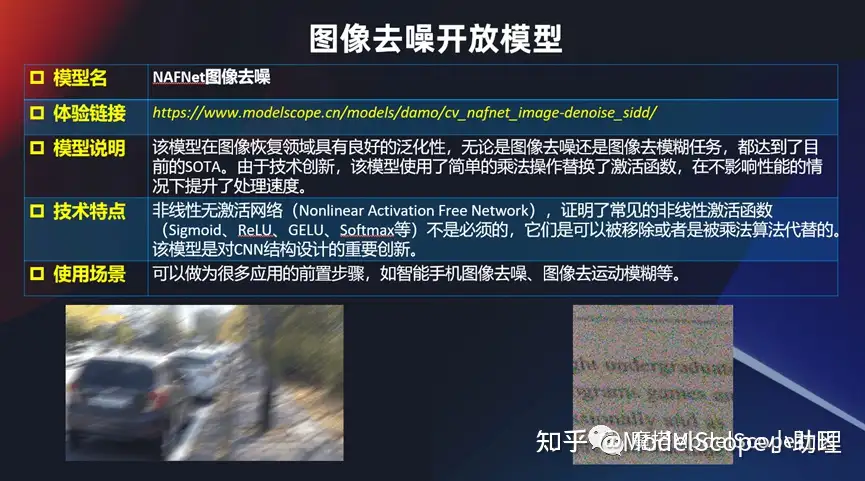
同時也開放了一些其他的跟底層視覺相關(guān)的一些模型或者算法,比如說兩個最經(jīng)典的。圖像拍的特別模糊,或者是噪聲點特別多,那么這個時候能不能有個辦法呢?其實也有一些專門的辦法去解,比如不管是對文字的噪點的去除,還是對拍攝過程當(dāng)中因為運動模糊帶來的一系列的問題都可以去解。
人像增強開放模型

還有針對人像的增強,在github 上很早就開放了GPEN 人像增強模型。基于 StyleGAN2 作為 decoder 的方式嵌進去的一個方式實現(xiàn)的。在這一塊的話可以對一些老照片來進行修復(fù)。
例如早期拍的家庭合照或者早期的一些影視劇,質(zhì)量不好的時候可以使用這個模型,把其中相對于人的這塊識別做的更好一點。
生成編輯相關(guān)能力

增強相對來說偏底層視覺相關(guān)的,但是生成編輯還有非常多的其他任務(wù)。包括對這個風(fēng)格變化,或者是從 0 到 1 生成一個東西,或者生成以后對它進行一個增、刪、查、改等等一系列的視覺能力。
視覺編輯開放模型
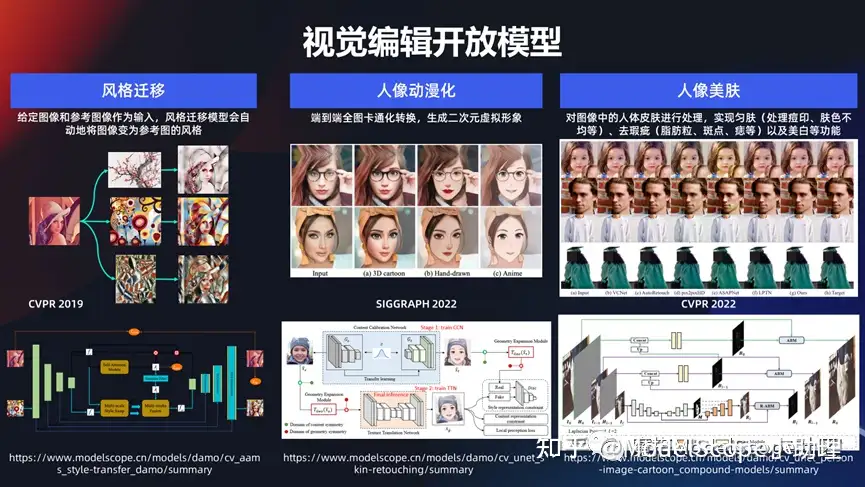
如果接觸到玩得非常火一系列的風(fēng)格變換,給個圖變成各種各樣的風(fēng)格,這些風(fēng)格當(dāng)然很多時候都是色彩+內(nèi)容的變化,還有卡通畫:把一個正常的人變成一個各種各樣的模式的卡通畫,或者是變一個風(fēng)格。是比較清新的風(fēng)格?還是迪士尼的風(fēng)格?還是 3D 的風(fēng)格?等等。
或者一個人的皮膚不是那么好,但是又想使這個人美化以后還能保持真實的感覺,這是相對比較高級的美膚能力,這一系列都是屬于視覺編輯。一張圖生成各種文的風(fēng)格,這些風(fēng)格也可能是日漫風(fēng)、 3D 風(fēng)、手繪風(fēng)、迪士尼風(fēng),而且這一個當(dāng)前買可以定制化的。

比如以上是一個非常受歡迎的一個例子,例如給一張圖,可以生成各種各樣的風(fēng)格,這些風(fēng)格可能是日漫風(fēng),3D風(fēng),迪士尼風(fēng),或者還可以定制化,例如我希望得到一個風(fēng)格,那么可以上傳若干個風(fēng)格的圖片,然后根據(jù)這幾張圖片提取其中的一個風(fēng)格特性,同時生成這種方式。所以這也是玩法非常多的一個方式,如果大家去試用會覺得很有趣。
電商海報設(shè)計
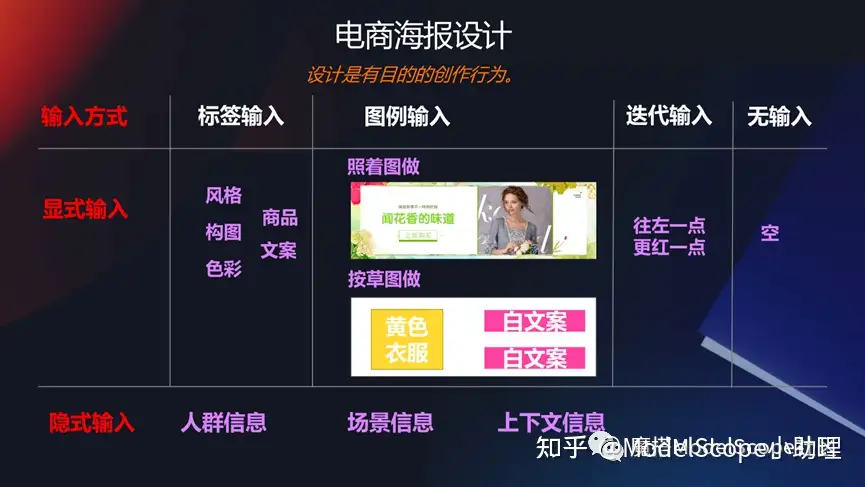
在一些特定的領(lǐng)域,比如說電商的海報領(lǐng)域,能不能生成一些banner圖/廣告圖?如果大家早期關(guān)注過阿里的鹿班這個產(chǎn)品,就應(yīng)該關(guān)注到這其中的一系列。
例如可以通過給一個商品主圖以及一些文本,去生成一段背景,同時這個背景還能夠非常好的和前景以及商品相互融合起來,包括這些細節(jié)也是非常使用的一個技術(shù),是非常經(jīng)典的生成編輯的能力。
視覺大模型技術(shù)
隨著大模型技術(shù)的發(fā)展,以及算力,還有數(shù)據(jù)規(guī)模化的不斷發(fā)展,還有多模態(tài)技術(shù)等等這一系列。前面的這些經(jīng)典的像感知理解類的技術(shù),或者生成編輯類的技術(shù),現(xiàn)在都在往前發(fā)展。
視覺統(tǒng)一分割任務(wù)模型:SAM

對這種感知理解的技術(shù),大家如何關(guān)注?前不久,Meta公司發(fā)表 SAM,通過模型可以對所有視覺分割任務(wù)進行統(tǒng)一的處理,且是zero shot 的問題。他可以對看得到、認識到之前識別不到的一系列目標對象進行識別分割,且能夠達到精準的像素級別分割。這塊它也可以在視頻當(dāng)中去做,比如我們看到視頻當(dāng)中有一個人,就能夠把他檢測出來,并且能夠給出識別。在 3D 領(lǐng)域也都是可以去做的。
所以這個模型在兩個地方很有意義,第一個解決很多目標中的分割問題。另外數(shù)據(jù)量也是非常龐大的。訓(xùn)練圖像應(yīng)該有 1000 多萬,做一個 billion 的一個 mask, 去做監(jiān)督的訓(xùn)練。
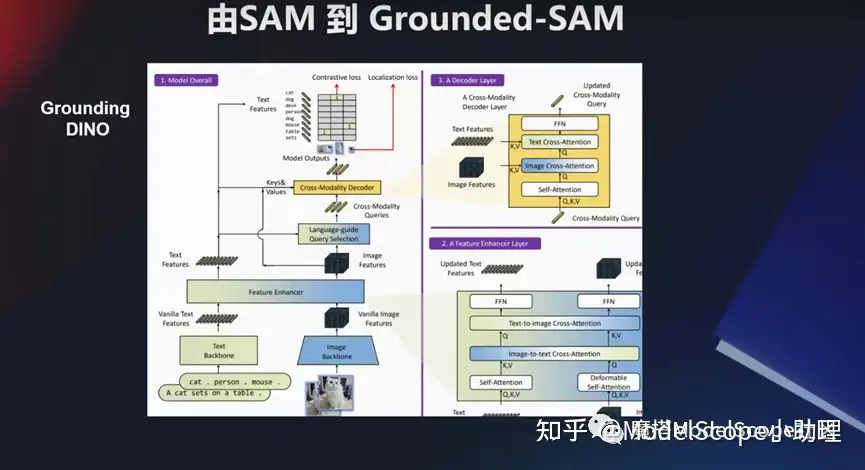
這個模型也可以結(jié)合其他的模型做綜合玩法。比如說像國內(nèi) grounding DINO 這個檢測模型,然后跟這個 SAM 模型結(jié)合起來。還可以把一些像生成類的模型,例如Stable Diffusion,甚至 ChatGPT 這種領(lǐng)域的一些問題,或者語音領(lǐng)域的一些問題。可以結(jié)合起來去做一些事情。
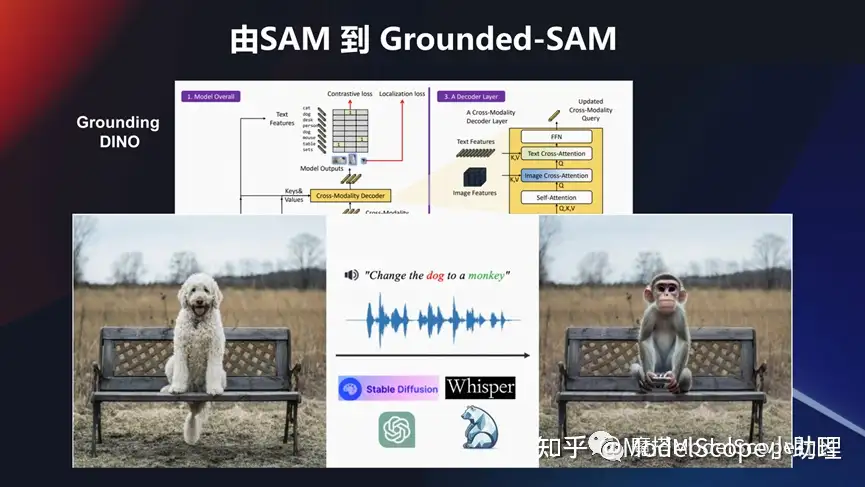
例如希望把這個坐在椅子上面的狗狗換成 一個猴子, change the dog to a monkey,這也是一個多模態(tài)的輸入,結(jié)合這個分割模型,把這個狗識別出來,同時結(jié)合生成的技術(shù),把這個前景的這個目標換掉,然后變成一個新的猴子這個目標,這也是非常有意思的一個玩法。
文生圖大模型發(fā)展
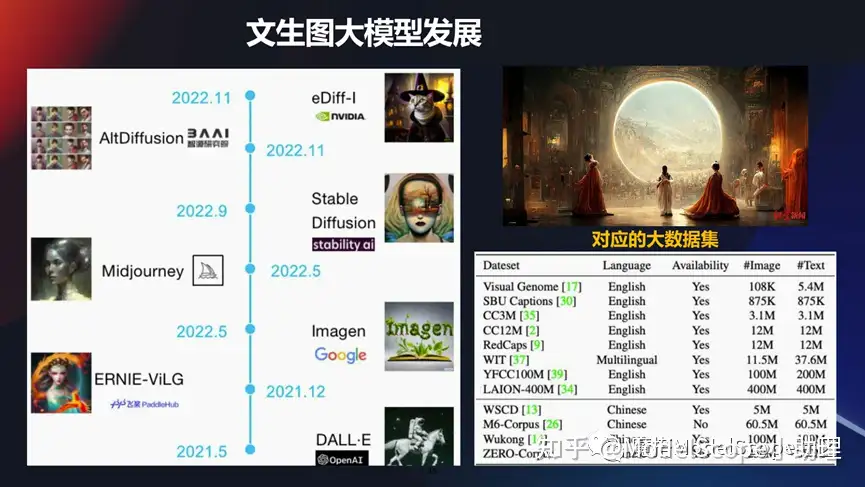
像文生圖這種模型,其實最近是特別火的。右上角這一張圖,是MJ公司一戰(zhàn)成名生成的一個圖像。文生圖這個領(lǐng)域越來越成熟,應(yīng)用越來越多。同時也有非常多的經(jīng)典的大模型的發(fā)展,包括早期的像 DALLE,到谷歌的imagen 方法,然后到現(xiàn)在最火的形成Stable Diffusion 。
這其中國內(nèi)外也涌現(xiàn)了一批比較知名的專門在這個領(lǐng)域做,且做的得非常好的產(chǎn)品。業(yè)界中公認的做的最好的是Midjourney。
國內(nèi)像文心一格,包括阿里也發(fā)布了若干個相關(guān)的一些文生圖的大模型。當(dāng)然想要把這些模型訓(xùn)練出來也是非常不容易的,這里也舉例了干個大數(shù)據(jù)集,如果真的想要 去訓(xùn)練起來一個大模型,我們可能要消耗好幾百塊的 GPU 卡,而且是需要訓(xùn)練很長的過程,其中除了算法本身以外,在算力和數(shù)據(jù)方面還有很多工作要做。所以要想做這一類的大模型其實是一個系統(tǒng)工程的問題。
“通義”預(yù)訓(xùn)練大模型系列

阿里發(fā)布了一系列的通義預(yù)訓(xùn)練大模型,包括M6-OFA這種包括文生圖,這系列的基礎(chǔ)模型都可以訪問。
我們關(guān)注的是跟視覺領(lǐng)域相關(guān)的技術(shù)更多一些,在自己的這個文生圖大模型上面,其實是基于一個知識重組的大模型訓(xùn)練。
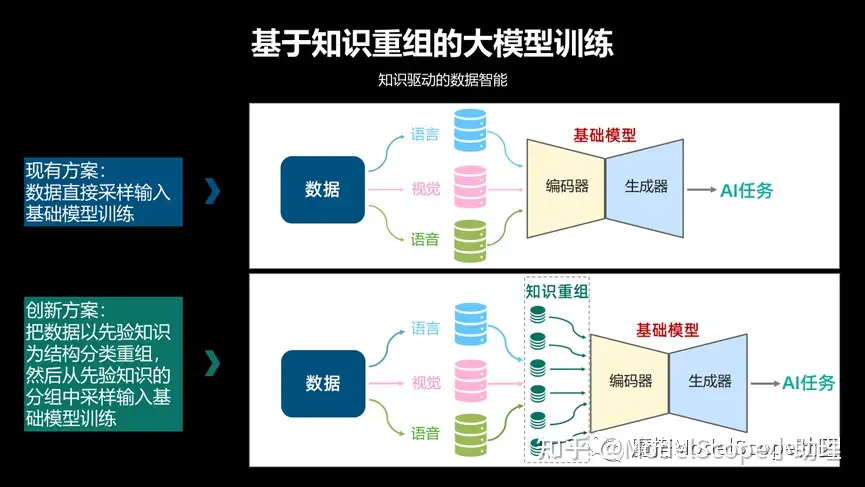
相當(dāng)于把知識信息這種先驗信息,不管是語言的,視覺的或語音的,通過知識重組方式或者分組的方式作為編碼器輸入訓(xùn)練得到大模型,此時在規(guī)模越大的時候會產(chǎn)生更加良好的一個效果。

上圖是舉的幾個例子,像生成這種動物或者 3D 的動物,或者跟人相關(guān)的,卡通畫的人相關(guān)的。用的比較多的可能是國外的Midjourney或者是開源社區(qū)的 Stable Diffusion,此類文生圖的大模型用的比較多,同時也歡迎大家去Model Scope 上使用。
基于擴散模型的圖像超分
除了文生圖以外基于擴散模型,其實還可以帶來對于其他任務(wù)的一系列的增強和更新。比如說我們在前面說的圖像超分其實也可以利用這種擴散模型去做,使得它的效果能夠變得非常好。

這款它有自己特定的問題需要去解答。比如說在這種任務(wù)上面,我們怎么能夠使得這個成本降低,速度加快,然后能夠真的可以部署?這是一個現(xiàn)實的問題,因為大模型在生成的效率上面和消耗上面還是有比較多的問題。另外很多的任務(wù)可能不一定需要文本引導(dǎo)或需要多模態(tài),它可能就是一個純粹的視覺領(lǐng)域的問題。這也是在這個領(lǐng)域嘗試的用大模型技術(shù)去解決的問題。
可控的圖像生成:ControlNet
還有一種情況,我們希望以一種更可控的去做圖像生成。去年年底的時候出的ControlNet模型在這個領(lǐng)域目前應(yīng)用最廣的,它可以對我們生成的目標進行一個預(yù)期的控制,無論是在輪廓上面還是在骨架上面、動作行為或者色彩上面,都可以通過這種方式去做。
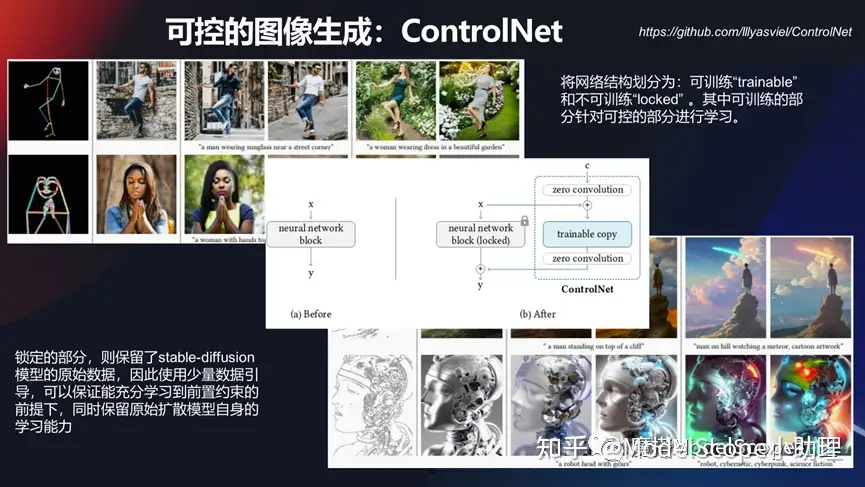
其實它是將某個結(jié)構(gòu)分成可訓(xùn)練的部分和不可訓(xùn)練部分,然后分別去針對這種模型進行充分的迭代,既能保留非常明顯自身的學(xué)習(xí)能力,同時又能使得約束及控制存在。
可組合圖像生成:Composer
當(dāng)然在可控的投入量生產(chǎn)我們在達摩院上面也做了一個非常有意思的研究,此研究的核心特點是可以支持多個條件引導(dǎo)的圖像合成,可以更加可控的生成方式去完成圖片可控的生產(chǎn)。
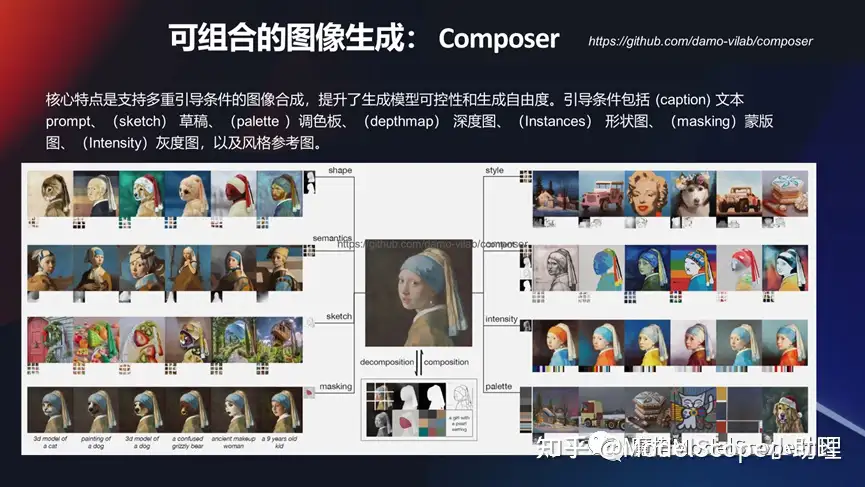
例如在 8 個維度上,不管是形狀還是深度形狀或者 mask 等等,這上面都可以對生產(chǎn)的結(jié)果進行一系列的可控。
除了純粹的文生圖以外,怎么可控的去生產(chǎn)?舉了兩個例子,一個是那個業(yè)界用的比較早期的ControlNet,包括我們達摩院自研的一個 Composer 的一個模型。
文本生成圖像

其實文本生成圖像,現(xiàn)在的視頻越來越用得廣,那么文本能不能直接生成視頻?其實這一塊達摩院也在做相應(yīng)的研究。
視頻的生成確實要比圖像的生成質(zhì)量和可控性相對來說差一點,離真正的使用還是有一定的距離,它不像Midjourney或者文心一格,或者我們自己發(fā)布的一系列圖像的生成產(chǎn)品慢慢的已經(jīng)達到可用或者是商業(yè)可用的狀態(tài)。但是對于視頻的生產(chǎn)還是有比較多的問題要去解決。

發(fā)布的通義大模型文本生成視頻,業(yè)界大家如何關(guān)注到?Runway 公司有個Gen-2, 也就是Gen的一代、二代都可以生成一系列的視頻。已經(jīng)可以預(yù)測到文生視頻的巨大潛力,這也是一個非常有前景,有意思,有挑戰(zhàn)的技術(shù)方向。

當(dāng)然文生視頻其實還有另外一個做成的方式,例如想要做一個通用的文生視頻其實非常難,生成的結(jié)果質(zhì)量,不管是高清的這方面還是流暢性的這種控制還是語義的符合,是有非常大的一個挑戰(zhàn)。那么我們在特定的環(huán)境或者是特定的范式下面能不能做一些事情?
例如我們希望什么樣的人,在什么樣的地方做什么樣的動作,這樣一個特定的模式能不能做呢?是可以的。比如說,我們做一個在蓋有城堡的沙灘上跳舞,然后右邊就是我希望秋天的樹葉,在這個下跳舞。
這就是我們可以把這種特定范式下的視頻生成做得相對可控和高清。
達摩院視覺AI開發(fā)服務(wù)
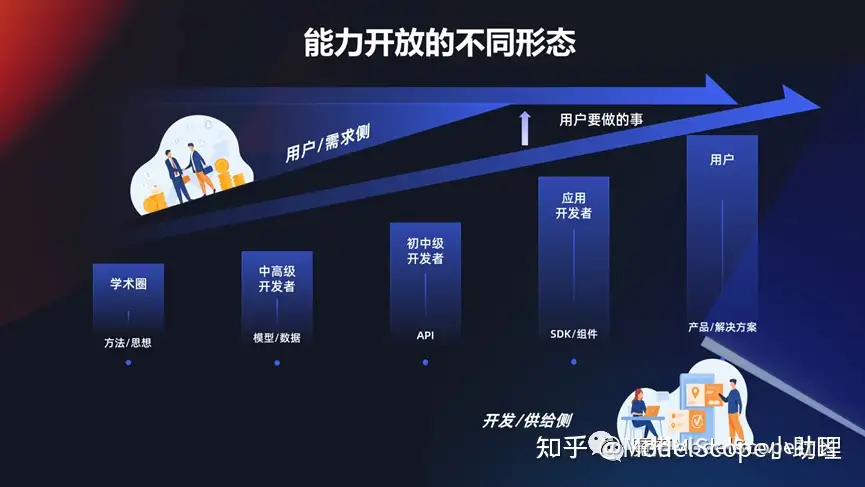
能力開放的不同形態(tài)
上面介紹到的這些能力達摩院和業(yè)界或者學(xué)業(yè)界做了非常多的探索,這些能力想要放開的話,無外乎是要要通過一個方式使得開發(fā)者/研發(fā)者/供給社研發(fā)出的模型或能力,能夠滿足用戶的需要。這些需要是多個層面的,例如對于學(xué)生或?qū)W術(shù)圈來說,可能發(fā)一篇論文就夠,把方法思想開放出去。對一些中高級的開發(fā)者,需要使用模型,使用數(shù)據(jù),還有一些需要直接調(diào)用 API ,甚至有些人只需要一個組件或者一個 SDK 就可以滿足。當(dāng)然對于行業(yè),政企,大行業(yè)或者解決方案的時候,需要提供一系列完整的產(chǎn)品和解決方案去滿足用戶的需求。
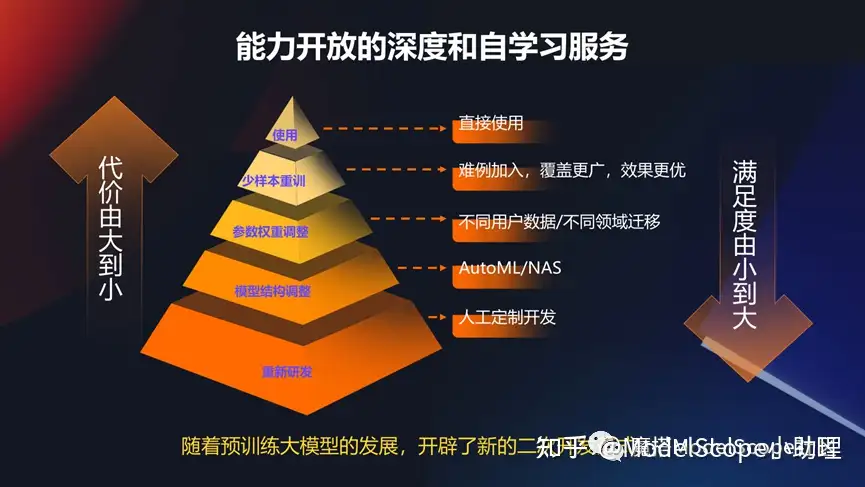
能力開放的深度和自學(xué)習(xí)服務(wù)
所以隨著預(yù)訓(xùn)的大模型的發(fā)展,還有非常重要的是,怎么能夠基于這些預(yù)訓(xùn)練模型進行二次開發(fā),基于統(tǒng)一的范式去滿足一次開發(fā)或基礎(chǔ)模型不能滿足用戶定制化需求的時候的一種方式。
達摩院視覺AI開放服務(wù)
所以達摩院開放了開放了兩種模式,一種是模型即服務(wù)的方式ModelScope,一種就是通過 API 平臺去滿足業(yè)界所有的需要,也就是前面所說的所有的模型或者 API 都可以從這兩個地方去找得到。

文章轉(zhuǎn)載自 @ModelScope小助理?