在計算語言學領域基礎模型取得成功后,越來越多的研究致力于將這種成功復制到另一種序列數據類型上:時間序列。
與大型語言模型(LLMs)類似,大型時間序列基礎模型(LTSM)旨在從龐大且多樣的時間序列數據集中學習以進行預測。
訓練好的基礎模型隨后可以針對各種任務(如異常檢測或時間序列分類)進行微調。
盡管時間序列基礎模型的概念已存在一段時間,并且已經探索了多種神經網絡架構(如MLP、RNN、CNN),但由于數據數量和質量的問題,尚未實現零樣本預測。
在LLMs取得成功之后,人們開始投入更多努力,旨在利用從自然語言數據中學習到的序列信息來進行時間序列建模。
語言模型與時間序列模型之間的主要聯系在于,它們的輸入數據都是序列數據。
主要區別在于數據如何被編碼以供模型捕捉不同類型的模式和結構。
對于大型語言模型,輸入句子中的單詞首先通過分詞被編碼為整數序列,然后通過嵌入查找過程轉換為數值向量。
類似地,時間序列數據也可以被分詞為一系列符號表示。
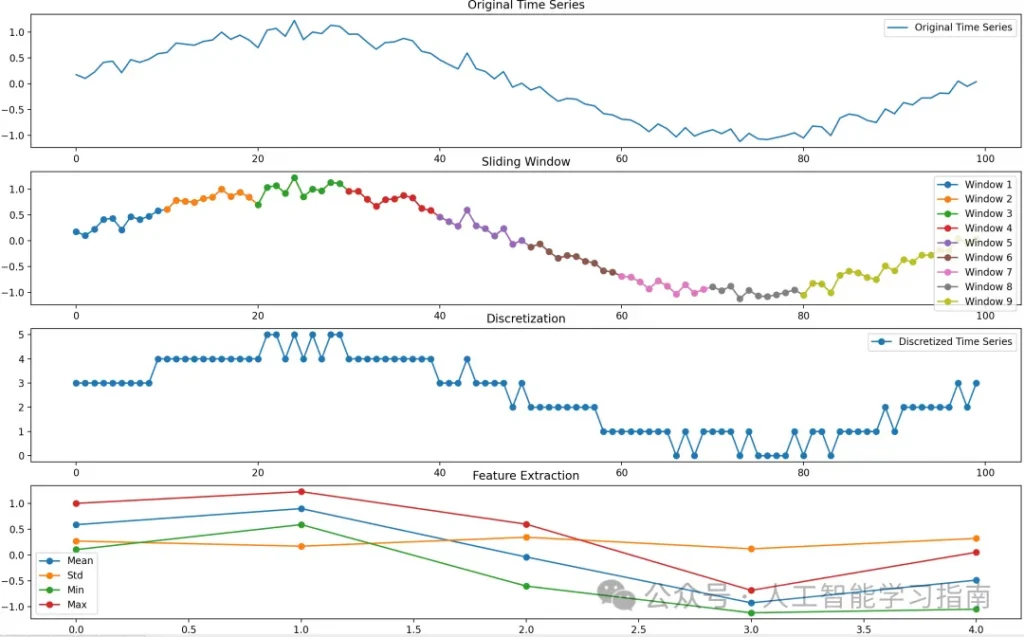
下圖展示了一個將包含100個時間戳的時間序列轉換為長度為5的序列的示例,其中序列中的每一步都由一個4維特征向量表示。
時間序列可以通過滑動窗口進行分割,并進行離散化處理以提取統計值(如均值、標準差、最小值、最大值)來表示每個窗口。
這樣,一個在廣泛語料庫上訓練的大型語言模型可以被視為與從現實世界中廣泛數值模式中學習的大型時間序列模型(LTSM)類似。
因此,時間序列預測問題可以被構造成一個類似于下一個單詞預測的問題。
實現最佳性能和零樣本/少樣本預測的關鍵挑戰在于對齊時間序列符號和自然語言符號之間的語義信息。
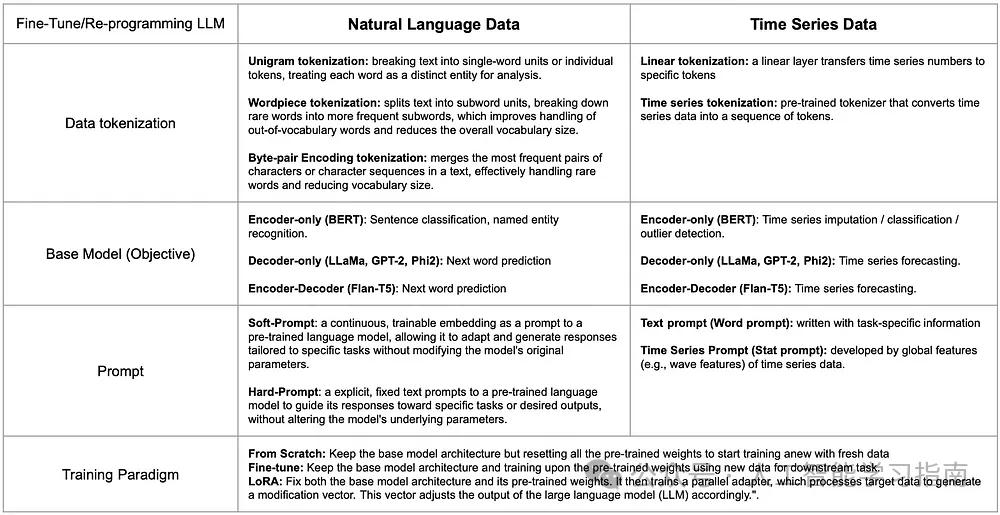
為了應對這一挑戰,研究人員正在從訓練大型語言模型的各個角度研究如何彌合時間序列與自然語言之間的信息鴻溝。下表展示了這兩種數據類型在組件上的比較以及每個組件的代表性工作。
一般來說,將大型語言模型(LLM)重新編程用于時間序列建模,與針對特定領域進行微調的過程相似。
這一過程包含幾個關鍵步驟:數據分詞、基礎模型選擇、提示工程以及定義訓練范式。
對于LLM來說,時間序列數據的分詞可以通過符號化表示來實現。
這避免了手動離散化和啟發式特征提取的復雜性,可以通過簡單的線性層或預訓練的分詞器[3]將時間序列數據的片段映射到潛在嵌入空間中的標記上,從而使分詞后的時間序列數據更好地適應LLM。
在選擇基礎模型時,可以通過比較不同架構的目標任務來進行。
例如,句子分類可以與時間序列分類或異常檢測相對應,而下一個詞的預測則可以對應于時間序列預測。
對時間序列數據進行提示時,可以依賴于數據的文本信息(如數據集或任務描述),或者從每個時間序列中提取全局統計特征,以突出不同數據集之間的總體差異。
時間序列數據的訓練范式通常遵循自然語言處理中使用的類似方法。
這些方法包括:使用相同模型架構但不包含預訓練權重的從頭開始訓練、在預訓練權重上進行微調,或訓練一個并行適配器(如LoRA)以使LLM適應時間序列數據。
每種方法都有不同的計算成本,而這些成本并不一定與性能結果成正比。
因此,鑒于每個步驟中的多樣選擇,我們如何確定最佳選項,以創建一個具有最優性能且更具泛化能力的模型呢?
深入理解大型時間序列模型訓練中的不同設計選擇
為了全面評估每一步選擇的優勢與劣勢,論文《LTSM-bundle》研究了在開源基準數據集上不同選擇組合的效果,并提供了一個開源基準框架,使公眾能夠針對自己的時間序列數據重新編程和基準測試不同的LLM(大型語言模型)選擇。
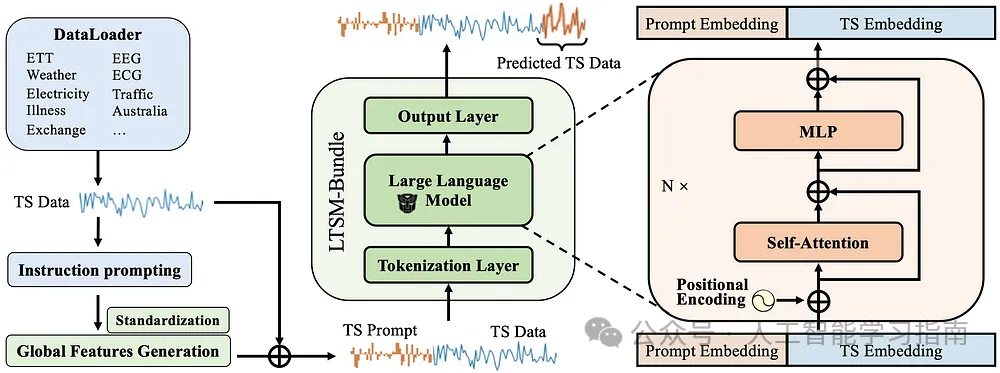
這篇論文深入探討了訓練LTSM(長短期記憶)模型的多種因素,包括模型提示的不同方式、數據分割策略、訓練方法、基礎模型的選擇、數據量的多少以及數據集的多樣性等。
在審視現有方法的基礎上,我們提出了一種新的概念——“時間序列提示”(Time Series Prompt)。
這種新方法通過從訓練數據中提取關鍵特征來生成提示,為每個數據集提供了堅實的統計概覽。
我們基于預測誤差(均方誤差/平均絕對誤差)來評估不同的選擇,誤差值越低,模型性能越好。
研究中的一些關鍵發現包括:
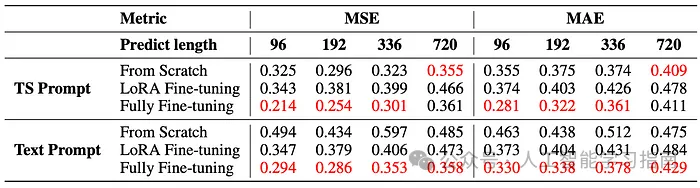
簡單的統計提示(TS Prompt)在提升LTSM模型訓練方面優于文本提示,并且與不使用任何提示的場景相比,使用統計提示能帶來更優的性能表現。

使用可學習的線性層對時間序列進行分詞,在訓練LTSM模型時表現更佳,特別是在同時處理來自不同領域的數據時,這一方法相較于其他分詞方法更具優勢。

雖然從頭開始訓練模型在初期可能表現良好,但由于參數眾多,存在過擬合的風險。全面微調通常能達到最佳性能,并且收斂速度是從頭開始訓練的兩倍,從而確保了預測的高效性和準確性。
在長期預測(336步和720步)中,小型模型表現出高達2%的性能優勢;而在短期預測(96步和192步)中,中等大小的模型則優于大型模型,這可能是因為大型模型存在潛在的過擬合問題。

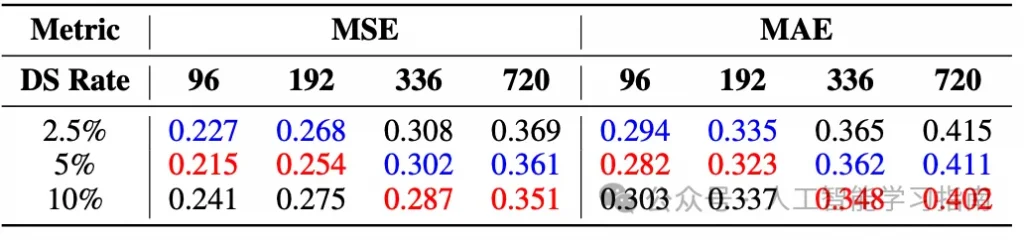
數據量的增加并不總是能帶來模型性能的改善,因為每個數據集的數據量增加會提高訓練時間序列的粒度,反而可能降低模型的泛化能力。但增加數據集的多樣性通常能提升性能。
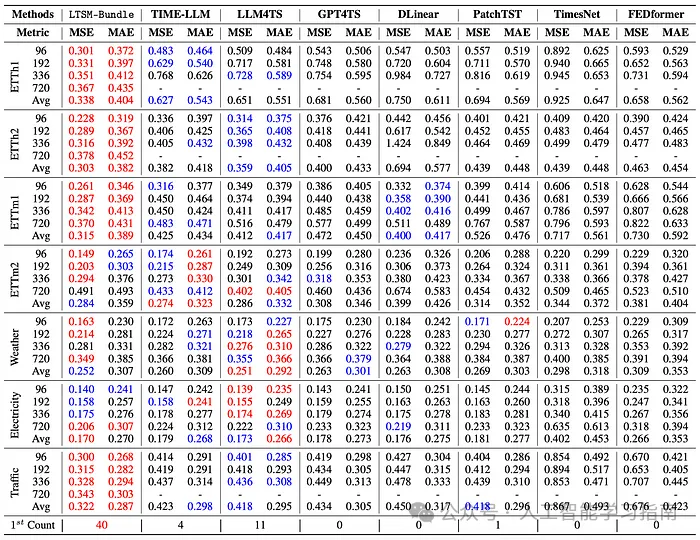
綜合以上發現,作者創建了LTSM-Bundle模型,該模型在重新編程用于時間序列的LLM(大型語言模型)和基于Transformer的時間序列預測模型方面,表現優于所有現有方法。
如果大家想嘗試自己重新編程LTSM,以下是LTSM-bundle的教程鏈接:https://github.com/daochenzha/ltsm/blob/main/tutorial/README.md
步驟1:創建一個虛擬環境。克隆并安裝所需的依賴項和倉庫。
conda create -n ltsm python=3.8.0
conda activate ltsm
git clone git@github.com:daochenzha/ltsm.gitclone git@github.com:daochenzha/ltsm.git
cd ltsm
pip3 install -e .
pip3 install -r requirements.txt步驟2:準備你的數據集。確保你的本地數據文件夾結構如下所述。
- ltsm/ - datasets/ DATA_1.csv/ DATA_2.csv/ DATA_3.csv/
...步驟3:?從訓練、驗證和測試數據集中生成時間序列提示
python3 prompt_generate_split.pypy步驟4:在‘./prompt_data_split’文件夾中找到生成的時間序列提示。然后運行以下命令以完成提示的定制。
# normalizing the promptspython3 prompt_normalization_split.py --mode fit#export the prompts to the "./prompt_data_normalize_split" folder
python3 prompt_normalization_split.py --mode transform最后步驟:使用時間序列提示和線性分詞在gpt2-medium上訓練你自己的LTSM模型。
python3 main_ltsm.py \ --model LTSM \ --model_name_or_path gpt2-medium \ --train_epochs 500 \ --batch_size 10 \ --pred_len 96 \ --data_path "DATA_1.csv DATA_2.csv" \"DATA_1.csv DATA_2.csv" \ --test_data_path_list "DATA_3.csv" \ --prompt_data_path "prompt_bank/prompt_data_normalize_split" \ --freeze 0 \ --learning_rate 1e-3 \ --downsample_rate 20 \
--output_dir [Your_Output_Path] \論文和GitHub倉庫:
論文鏈接:
https://arxiv.org/pdf/2406.14045
代碼倉庫:
https://github.com/daochenzha/ltsm/
參考文獻:
原文轉自 微信公眾號@人工智能學習指南