為了從這種方法中獲得最佳效果,我們需要訪問大量具有匹配源文本和目標文本的高質量訓練數據。如果您已經建立了相當大的翻譯記憶庫,那么它很可能可以用于此目的。LanguageWire AI 團隊一直在努力確定 LoRA 調整的理想翻譯記憶庫大小。
現在讓我們討論第二種方法,即上下文學習或小樣本學習。
情境學習是一種讓模型根據專門設計的提示引入的少量示例進行動態學習的方法。這種方法也稱為小樣本學習。
在機器翻譯的背景下,小樣本學習的工作原理如下:
- 系統會分析傳入的源內容。通常,源內容由一個或多個句子或片段組成。
- 系統嘗試找到類似的源內容片段及其各自的翻譯的例子。
- 系統創建一個提示,其中包括要翻譯的源內容和以前翻譯的示例。
- LLM 通過實例不斷學習,創建高質量的原文翻譯。
少樣本學習對機器翻譯的流暢性、語調和術語合規性有積極影響。它需要使用更少的示例,最多三到五個。事實上,樣本量越大效率越低,因此將所有翻譯記憶都包含在一個提示中對它沒有好處。實驗表明,LLM 不能很好地處理大型提示上下文,結果的質量甚至可能會下降!
通過結合 LoRA 和小樣本學習的優勢,我們可以在大型語言模型中實現強大的優化,最終實現超個性化、高質量的機器翻譯。
您的語言數據是關鍵!
如果沒有大量高質量、最新的各種語言對雙語文本語料庫,這些技術都無法發揮作用。您的翻譯記憶庫是此數據集的理想來源。
然而,在使用它之前,您必須考慮幾個重要方面:
- 質量。所有數據都應是高質量的,最好由合格的人工翻譯人員翻譯,并在四人工作流程中驗證,即由兩個人批準。
- 噪音。翻譯記憶庫中的數據可能并非全部相關。部分數據可能較舊、不相關或涉及已丟棄的產品。定期清理翻譯記憶庫以刪除不相關的材料非常重要。
- 大小。您需要一定的數據量來確保微調效果良好。如果質量保持不變,數據量越大越好。
如果您使用 LanguageWire 平臺,自動化翻譯記憶庫管理模塊將為您處理這些方面,無需任何手動操作。
如果您有現有的外部翻譯記憶庫,并希望將其用于我們的平臺和機器翻譯服務,我們的工程師可以幫您實現這一目標。LanguageWire 工程師創建了導入 API、清理腳本和語言質量評估工具,以幫助您充分利用最寶貴的語言資產。
LanguageWire 解決方案
那么,我們如何將所有這些整合到一個典型的翻譯項目中呢?讓我們來看一個例子。
LanguageWire 提供的解決方案與我們的技術生態系統完全集成。下圖 1 中高級步驟對此進行了演示。
在此示例中,我們采用了一個簡單的工作流程,客戶想要翻譯 PDF 或辦公文件。用戶只需使用 LanguageWire 項目門戶上傳內容文件即可。從此,一切都自動安排好了:
- 對傳入的數據進行分析并將其轉換為 XLIFF 文件。
- 該系統根據翻譯記憶庫匹配和機器翻譯創建預翻譯。
- 我們的人工專家社區提供后期編輯和校對服務。
- 下一步,翻譯后的 XLIFF 將被重新組合成輸出文件,并保留布局。
- 最后,客戶可以從門戶網站下載翻譯后的文件。
圖 1:現有 LanguageWire 平臺結果中的簡單翻譯項目

在示例 2 中,我們重點關注使用基于 LLM 技術的機器翻譯的預翻譯步驟。如下圖 2 所示,客戶的語言數據起著核心作用。
- 對于每段文本,LanguageWire 系統都會在翻譯記憶庫中找到“K 個最近鄰” 。這些雙語結果被用作特殊小樣本學習提示的基礎,并傳遞給 LLM 的機器翻譯 API。
- 在模型層,我們加載了一個 LoRA 模塊,該模塊可根據客戶的語調和詞匯量定制 LLM。同樣,這是基于從翻譯記憶庫編譯的數據集。我們將該數據集應用于使用 LoRA 的 PEFT 調整,以創建加載到模型上下文中的新模型權重。這種調整可以定期進行,例如每兩周一次,以反映 TM 中的新更新和內容。
圖 2:使用大型語言模型、混合 LoRA 定制和優化的上下文學習提示的翻譯示例。
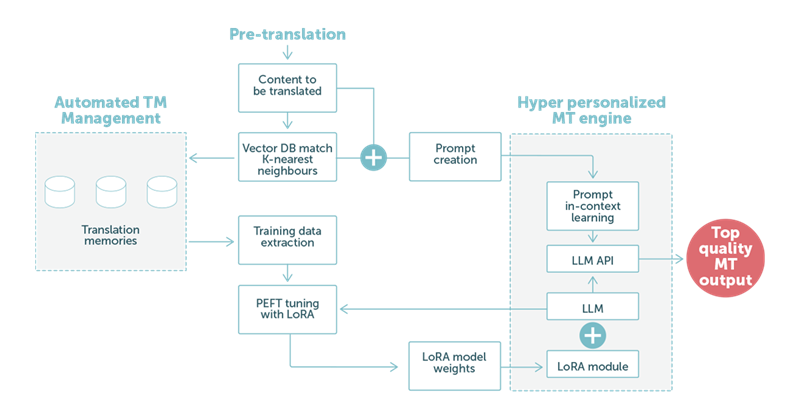
當我們專門設計的提示由 LLM 處理時,LoRA 模塊中的自定義權重將有助于獲得高質量的機器翻譯 輸出。完成后,此輸出將自動進入流程的下一步。通常,這將是一項后期編輯任務,由人類專家參與,以實現最高的最終質量。
這對我們的客戶意味著什么?
簡而言之:我們的客戶可以期待更好的機器翻譯。機器翻譯可以自動適應不同的環境,例如不同的垂直行業,并與該垂直行業的預期語氣和用詞選擇保持一致。
這不僅可以降低譯后編輯的成本,還可以提高翻譯的交付速度。它還將為直接使用機器翻譯輸出開辟更廣泛的空間,而無需人工專家參與。
LanguageWire 還對 LLM 做了什么?
正如我們之前提到的,大型語言模型非常靈活。LanguageWire AI 團隊正在研究許多其他可以從 LLM 技術中受益的領域。
我們目前正在研究:
自動語言質量評估。LLM 可以檢查人類專家的翻譯或另一個模型的機器翻譯輸出并給出質量評分。這可以大大降低校對成本。底層的機器翻譯質量評估 (MTQE) 技術也可以應用于其他用例。
內容創作助手。通過結合使用 PEFT 與 LoRA 和少樣本學習,我們可以個性化 LLM 模型,使其專注于內容創作任務。客戶可以提供關鍵字和元數據,讓模型生成使用業務定制的語氣和詞匯選擇的文本。
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
3000+提示詞助力AI大模型
和專業工程師共享工作效率翻倍的秘密
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
自拍偷拍亚洲欧美日韩|
91免费看视频|
欧洲一区二区av|
一二三区精品福利视频|
一区二区不卡在线播放|
一区二区三区日韩欧美精品|
一区二区三区欧美日韩|
国产亚洲欧美激情|
亚洲欧美一区二区不卡|
成人午夜精品在线|
91精品国产综合久久蜜臀|
久久久久久久久久久久久夜|
色婷婷综合久久久久中文|
99re6这里只有精品视频在线观看
99re8在线精品视频免费播放
|
国产三区在线成人av|
免费成人小视频|
91污片在线观看|
91麻豆国产香蕉久久精品|
日韩欧美中文字幕公布|
国产精品美女久久久久av爽李琼|
成人午夜激情在线|
久久久久综合网|
在线综合亚洲欧美在线视频|
日韩午夜av电影|
亚洲综合久久av|
色婷婷av一区二区三区gif|
国产一区二区在线视频|
亚洲专区一二三|
日韩久久久精品|
91精品国产综合久久香蕉的特点|
国产.欧美.日韩|
亚洲国产精品传媒在线观看|
欧美午夜寂寞影院|
亚洲一区二区欧美激情|
不卡视频在线观看|
奇米亚洲午夜久久精品|
亚洲日本电影在线|
精品国产91久久久久久久妲己|
欧美中文字幕一区二区三区|
国产乱码精品一区二区三区av|
午夜日韩在线电影|
亚洲美女视频在线|
欧美经典一区二区三区|
欧美一三区三区四区免费在线看|
色综合久久久久网|
91在线视频官网|
91在线观看视频|
成人av中文字幕|
成人av电影在线观看|
懂色av一区二区三区免费看|
亚洲成av人在线观看|
91麻豆精品久久久久蜜臀|
波多野洁衣一区|
欧美羞羞免费网站|
成人免费一区二区三区视频
|
精品国产99国产精品|
www.日韩精品|
欧美日韩国产精品自在自线|
蜜桃91丨九色丨蝌蚪91桃色|
国产精品国产三级国产aⅴ中文|
欧美一区二区三区白人|
欧美综合在线视频|
日韩午夜在线播放|
一区二区在线观看免费|
精品国产一区二区三区久久久蜜月
|
亚洲国产精品v|
国产精品天天摸av网|
国产精品免费免费|
一区二区不卡在线播放|
久久精品视频一区二区三区|
欧美日本在线一区|
亚洲欧美精品午睡沙发|
亚洲精品成人在线|
午夜精品久久久久影视|
久久综合999|
2017欧美狠狠色|
免费人成精品欧美精品|
2017欧美狠狠色|
欧美成人在线直播|
日韩午夜激情视频|
欧美三级电影网|
欧美精品日日鲁夜夜添|
欧美日本免费一区二区三区|
不卡一二三区首页|
99热这里都是精品|
色综合久久六月婷婷中文字幕|
丰满岳乱妇一区二区三区|
国产69精品久久777的优势|
东方欧美亚洲色图在线|
成人国产一区二区三区精品|
顶级嫩模精品视频在线看|
一道本成人在线|
欧美电影在线免费观看|
7777精品伊人久久久大香线蕉最新版|
亚洲高清三级视频|
欧美美女一区二区三区|
国产亚洲精品久|
国产亚洲视频系列|
国产高清精品在线|
亚洲美女淫视频|
国产福利一区二区三区在线视频|
欧美这里有精品|
日韩和的一区二区|
2020国产成人综合网|
成人午夜av电影|
欧美亚洲国产一区在线观看网站|
亚洲色图制服丝袜|
欧美国产综合色视频|
久88久久88久久久|
欧美日韩视频在线观看一区二区三区|
午夜精品在线看|
久久品道一品道久久精品|
99久久伊人久久99|
欧美日韩一区二区三区视频|
亚洲精品一卡二卡|
精品一区二区三区视频在线观看|
国产成人免费在线观看|
麻豆一区二区在线|
93久久精品日日躁夜夜躁欧美|
欧美精品亚洲二区|
亚洲国产精品久久久男人的天堂|
国产福利一区二区三区在线视频|
日韩视频在线你懂得|
麻豆成人av在线|
精品久久久久久无|
韩国女主播一区二区三区|
欧美一区二区三区视频在线|
亚洲成人动漫在线观看|
国产美女精品在线|
k8久久久一区二区三区|
亚洲午夜三级在线|
欧美电视剧免费观看|
国产精品一区二区91|
亚洲一区二区三区影院|
2020国产精品自拍|
欧美日韩国产精品成人|
久久草av在线|
亚洲国产wwwccc36天堂|
国产精品乱人伦|
懂色中文一区二区在线播放|
日韩美女精品在线|
欧美成人一区二区三区片免费|
成人免费视频视频|
另类小说综合欧美亚洲|
亚洲一区二区三区小说|
色婷婷国产精品久久包臀|
中文字幕一区在线观看|
91精品国产综合久久国产大片|
日韩成人一级片|
亚洲女同一区二区|
国产精品久久久久影院色老大|
欧美三片在线视频观看
|
国产精品久久久久久久浪潮网站|
欧美精品电影在线播放|
在线亚洲人成电影网站色www|
国产经典欧美精品|
国产在线看一区|
日韩美女在线视频|
欧美日韩国产综合一区二区三区|
日韩女优毛片在线|
尤物av一区二区|
国产在线观看免费一区|
在线影院国内精品|
日韩精品一区二区三区蜜臀|
国产视频在线观看一区二区三区|
一区二区视频免费在线观看|
日本午夜精品视频在线观看
|
一区二区三区在线观看动漫
|
欧美激情综合网|
久久精品夜色噜噜亚洲a∨
|
亚洲欧美另类综合偷拍|
亚洲免费在线视频一区 二区|
精品综合免费视频观看|
91视频免费观看|
日本一区二区三区在线不卡|
91福利在线看|
日韩限制级电影在线观看|
国产1区2区3区精品美女|
欧美日韩视频在线观看一区二区三区|
国产成人综合精品三级|
老司机精品视频在线|
日本精品裸体写真集在线观看|
国产日韩综合av|
欧美在线观看视频一区二区|
欧美色综合天天久久综合精品|
一区二区高清免费观看影视大全
|
亚洲免费在线视频|
91精品免费在线观看|
风间由美一区二区三区在线观看
|
奇米一区二区三区av|
91九色最新地址|
中文字幕在线观看一区二区|
日本欧美大码aⅴ在线播放|
欧洲精品在线观看|
亚洲韩国精品一区|
91精品国产欧美日韩|
久久成人羞羞网站|
中文字幕在线不卡国产视频|
成人av免费网站|
这里是久久伊人|