
如何快速實現(xiàn)REST API集成以優(yōu)化業(yè)務(wù)流程
注意:通過查看
part-1分支,您將能夠從相同的起點跟蹤文章。
要啟動PostgreSQL,請從real-world-grading-app文件夾運行以下命令:
docker-compose up -d注意:Docker 將使用
docker-compose.yml文件啟動 PostgreSQL 容器。
在著手構(gòu)建后端系統(tǒng)時,準確理解問題域是至關(guān)重要的第一步。問題域,亦稱問題空間,涵蓋了定義問題及其解決方案約束的全部信息。通過深入剖析問題域,我們能夠清晰地勾勒出數(shù)據(jù)模型的輪廓和結(jié)構(gòu)。
針對在線評分系統(tǒng),我們確定了以下核心實體:
(注:實體既可以表示物理對象,也可以是無形的概念。例如,用戶對應(yīng)的是真實的人,而課程則是一個抽象的概念。)
為了更直觀地展示這些實體及其在關(guān)系數(shù)據(jù)庫(本例中為PostgreSQL)中的表示,我們可以構(gòu)建一幅圖表。該圖表不僅列出了每個實體及其外鍵,還詳細描述了實體間的關(guān)聯(lián)關(guān)系及對應(yīng)的列。
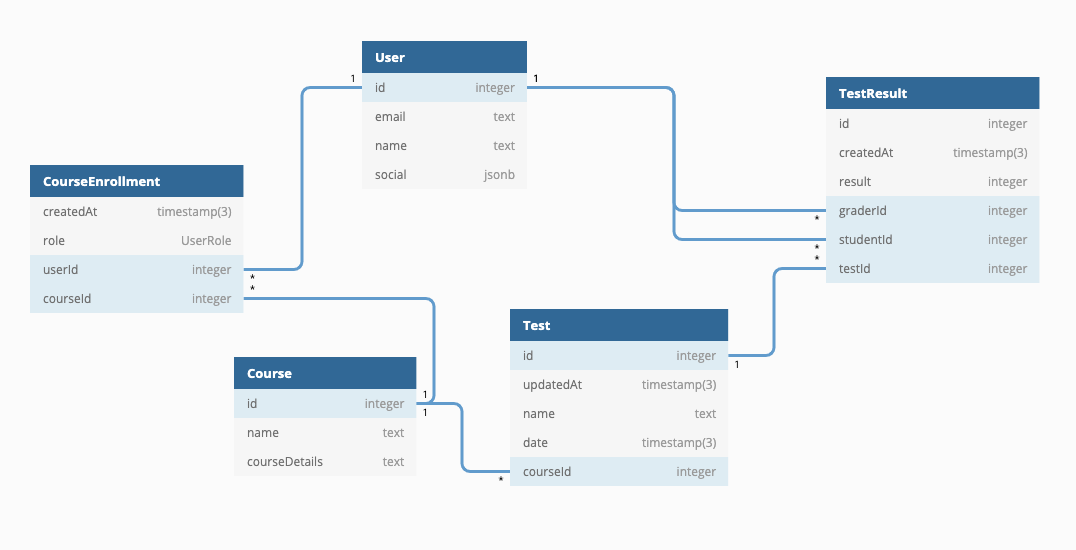
關(guān)于該圖,首先要注意的是,每個實體都映射到一個數(shù)據(jù)庫表。
該圖具有以下關(guān)系:
1-N):
M-N):
注意:關(guān)系表(也稱為JOIN表)用于連接兩個或多個其他表,從而在它們之間建立關(guān)系。在SQL中,創(chuàng)建關(guān)系表是表示不同實體之間關(guān)系的常見數(shù)據(jù)建模實踐。本質(zhì)上,這意味著“在數(shù)據(jù)庫中,一個m-n關(guān)系被建模為兩個1-n關(guān)系”。
要在數(shù)據(jù)庫中創(chuàng)建表,首先需要定義Prisma架構(gòu)。Prisma架構(gòu)是數(shù)據(jù)庫表的聲明性配置,Prisma Migrate將使用此配置在數(shù)據(jù)庫中創(chuàng)建表。與上面的實體圖類似,它定義了數(shù)據(jù)庫表之間的列和關(guān)系。
(Prisma架構(gòu)是生成的Prisma客戶端和Prisma Migrate創(chuàng)建數(shù)據(jù)庫架構(gòu)的真實來源。)
項目的Prisma架構(gòu)可以在prisma/schema.prisma中找到。在架構(gòu)中,您將找到在此步驟中定義的模型(對應(yīng)數(shù)據(jù)庫表)的占位符和一個datasource塊。datasource塊定義了要連接的數(shù)據(jù)庫類型以及連接字符串。通過使用env(“DATABASE_URL”),Prisma將從環(huán)境變量中加載數(shù)據(jù)庫連接URL。
注意:將秘密隱藏在代碼庫之外被認為是最佳實踐。因此,在datasource塊中定義了env(“DATABASE_URL”)。通過設(shè)置環(huán)境變量,您可以將秘密隱藏在代碼庫之外。
Prisma架構(gòu)的核心組成部分是model。每個model都直接對應(yīng)數(shù)據(jù)庫中的一個表。
以下是一個示例,展示了model的基本結(jié)構(gòu):
model User {
id Int @default(autoincrement()) @id
email String @unique
firstName String
lastName String
social Json?
}在這里,您定義了一個帶有多個字段的User模型。每個字段都有一個名稱,后跟一個類型和可選的字段屬性。例如,id字段可以分解如下:
| 名字 | 類型 | 標量與關(guān)系 | 類型修飾符 | 屬性 |
|---|---|---|---|---|
id | Int | 標量 | – | @id(表示主鍵)和 @default(autoincrement())(設(shè)置默認自增值) |
email | String | 標量 | – | @unique |
firstName | String | 標量 | – | – |
lastName | String | 標量 | – | – |
social | Json | 標量 | ? (自選) | – |
Prisma 提供了一系列數(shù)據(jù)類型,這些數(shù)據(jù)類型會根據(jù)您所使用的數(shù)據(jù)庫自動映射到相應(yīng)的本機數(shù)據(jù)庫類型。
其中,Json 數(shù)據(jù)類型允許您存儲自由格式的 JSON 數(shù)據(jù)。這對于在 User 記錄中存儲可能不一致或頻繁變更的信息特別有用,因為這些變更可以在不影響后端核心功能的情況下輕松進行。在上面的 User 模型中,Json 數(shù)據(jù)類型被用于存儲如 Twitter、LinkedIn 等社交鏈接。當您需要向 social 字段添加新的社交配置文件鏈接時,無需進行數(shù)據(jù)庫遷移。
在充分理解問題域并掌握了使用 Prisma 進行數(shù)據(jù)建模的方法后,您現(xiàn)在可以將以下模型添加到 prisma/schema.prisma 文件中:
model User {
id Int @default(autoincrement()) @id
email String @unique
firstName String
lastName String
social Json?
}
model Course {
id Int @default(autoincrement()) @id
name String
courseDetails String?
}
model Test {
id Int @default(autoincrement()) @id
updatedAt DateTime @updatedAt
name String // Name of the test
date DateTime // Date of the test
}
model TestResult {
id Int @default(autoincrement()) @id
createdAt DateTime @default(now())
result Int // Percentage precise to one decimal point represented as result * 10^-1
}每個模型都有所有相關(guān)的字段,而忽略關(guān)系(將在下一步中定義)。
在此步驟中,您將在 Test 和 TestResult 之間定義一個一對多關(guān)系。
首先,考慮在上一步中定義的Test和TestResult模型:
model Test {
id Int @default(autoincrement()) @id
updatedAt DateTime @updatedAt
name String
date DateTime
}
model TestResult {
id Int @default(autoincrement()) @id
createdAt DateTime @default(now())
result Int // Percentage precise to one decimal point represented result * 10^-1
}要定義兩個模型之間的一對多關(guān)系,請?zhí)砑右韵氯齻€字段:
model Test {
id Int @default(autoincrement()) @id
updatedAt DateTime @updatedAt
name String
date DateTime
testResults TestResult[]// relation field
}
model TestResult {
id Int @default(autoincrement()) @id
createdAt DateTime @default(now())
result Int // Percentage precise to one decimal point represented result * 10^-1
testId Int // relation scalar field
test Test @relation(fields: [testId], references: [id]) // relation field
}關(guān)系字段,如test和testResults,可以通過其值類型指向另一個模型(例如Test和TestResult)來識別。這些字段的名稱將影響使用Prisma客戶端以編程方式訪問關(guān)系的方式,但它們并不代表真實的數(shù)據(jù)庫列。
在此步驟中,您將在 User 和 Course 模型之間定義一個多對多關(guān)系。
多對多關(guān)系在 Prisma 架構(gòu)中可以是隱式的,也可以是顯式的。在這一部分中,您將了解兩者之間的區(qū)別以及何時選擇隱式或顯式。
首先,考慮在上一步中定義的 Test 和 TestResult 模型:
model User {
id Int @default(autoincrement()) @id
email String @unique
firstName String
lastName String
social Json?
}
model Course {
id Int @default(autoincrement()) @id
name String
courseDetails String?
}要創(chuàng)建隱式多對多關(guān)系,請將關(guān)系字段定義為關(guān)系兩側(cè)的列表:
model User {
id Int @default(autoincrement()) @id
email String @unique
firstName String
lastName String
social Json?
courses Course[]
}
model Course {
id Int @default(autoincrement()) @id
name String
courseDetails String?
members User[]
}這樣,Prisma 將根據(jù)所定義的屬性來構(gòu)建關(guān)系表,從而支持分級系統(tǒng):
然而,評分系統(tǒng)的一個關(guān)鍵需求是允許用戶以教師或?qū)W生的身份與課程相關(guān)聯(lián)。這意味著我們需要一種機制來存儲關(guān)于數(shù)據(jù)庫中關(guān)系的“附加信息”。
為了滿足這一需求,我們可以采用顯式的多對多關(guān)系。具體來說,我們需要為連接User和Course的關(guān)系表添加一個名為CourseEnrollment的新模型,并在該關(guān)系表中添加額外的字段來指明用戶是課程的教師還是學生。使用顯式的多對多關(guān)系允許我們在關(guān)系表上定義這些額外的字段。
為此,我們將對User和Course模型進行更新,將它們的courses和members字段的類型更改為CourseEnrollment[],如下所示:
model User {
id Int @default(autoincrement()) @id
email String @unique
firstName String
lastName String
social Json?
courses CourseEnrollment[]
}
model Course {
id Int @default(autoincrement()) @id
name String
courseDetails String?
members CourseEnrollment[]
}
model CourseEnrollment {
createdAt DateTime @default(now())
role UserRole
// Relation Fields
userId Int
user User @relation(fields: [userId], references: [id])
courseId Int
course Course @relation(fields: [courseId], references: [id])
@@id([userId, courseId])
@@index([userId, role])
}
enum UserRole {
STUDENT
TEACHER
}關(guān)于CourseEnrollment模型的幾點說明:
@@id([userId, courseId])定義了兩個字段的多字段主鍵。這確保了每個用戶只能以特定角色(學生或教師)與每個課程關(guān)聯(lián)一次,但不能同時擁有兩種角色。@@index([userId, role])為userId和role字段創(chuàng)建了索引,這有助于提高基于這些字段進行查詢的效率。現(xiàn)在您已經(jīng)了解了關(guān)系的定義方式,請使用以下內(nèi)容更新 Prisma 架構(gòu):
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model User {
id Int @id @default(autoincrement())
email String @unique
firstName String
lastName String
social Json?
// Relation fields
courses CourseEnrollment[]
testResults TestResult[] @relation(name: "results")
testsGraded TestResult[] @relation(name: "graded")
}
model Course {
id Int @id @default(autoincrement())
name String
courseDetails String?
// Relation fields
members CourseEnrollment[]
tests Test[]
}
model CourseEnrollment {
createdAt DateTime @default(now())
role UserRole
// Relation Fields
userId Int
courseId Int
user User @relation(fields: [userId], references: [id])
course Course @relation(fields: [courseId], references: [id])
@@id([userId, courseId])
@@index([userId, role])
}
model Test {
id Int @id @default(autoincrement())
updatedAt DateTime @updatedAt
name String
date DateTime
// Relation Fields
courseId Int
course Course @relation(fields: [courseId], references: [id])
testResults TestResult[]
}
model TestResult {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
result Int // Percentage precise to one decimal point represented as result * 10^-1
// Relation Fields
studentId Int
student User @relation(name: "results", fields: [studentId], references: [id])
graderId Int
gradedBy User @relation(name: "graded", fields: [graderId], references: [id])
testId Int
test Test @relation(fields: [testId], references: [id])
}
enum UserRole {
STUDENT
TEACHER
}請注意,TestResult模型與User模型之間存在兩個關(guān)系:student和gradedBy。student關(guān)系代表參加考試的學生,而gradedBy關(guān)系則代表給考試評分的老師。當一個模型與另一個模型之間存在多個關(guān)系時,我們需要使用@relation參數(shù)在關(guān)系的name屬性上指定,以消除這些關(guān)系之間的歧義。
在定義了Prisma模式之后,接下來您將使用Prisma Migrate在數(shù)據(jù)庫中創(chuàng)建實際的表結(jié)構(gòu)。
首先,在本地設(shè)置 DATABASE_URL 環(huán)境變量,以便Prisma可以連接到您的數(shù)據(jù)庫。
export DATABASE_URL="postgresql://prisma:prisma@127.0.0.1:5432/grading-app"注意:本地數(shù)據(jù)庫的用戶名和密碼都定義為
prisma中的docker-compose.yml。
要使用 Prisma Migrate 創(chuàng)建并運行遷移,請在終端中運行以下命令:
npx prisma migrate dev --preview-feature --skip-generate --name "init"該命令將執(zhí)行兩項操作:
prisma/migrations注意:Prisma Migrate 當前處于預(yù)覽模式。這意味著不建議在生產(chǎn)中使用 Prisma Migrate。
檢查點:您應(yīng)該在輸出中看到如下內(nèi)容:
Prisma Migrate created and applied the following migration(s) from new schema changes:
migrations/
└─ 20201202091734_init/
└─ migration.sql
Everything is now in sync.恭喜,您已成功設(shè)計數(shù)據(jù)模型并創(chuàng)建數(shù)據(jù)庫架構(gòu)。在下一步中,您將使用 Prisma Client 對數(shù)據(jù)庫執(zhí)行 CRUD 和聚合查詢。
Prisma Client 是為您的數(shù)據(jù)庫架構(gòu)量身定制的自動生成的數(shù)據(jù)庫客戶端。它的工作原理是解析 Prisma 架構(gòu)并生成一個 TypeScript 客戶端,您可以將其導(dǎo)入到代碼中。
生成 Prisma 客戶端通常需要三個步驟:
generator定義添加到您的Prisma模式: generator client { provider = "prisma-client-js" }@prisma/client npm包 :npm install --save @prisma/clientnpx prisma generate檢查點:您應(yīng)該在輸出中看到以下內(nèi)容:? Generated Prisma Client to ./node_modules/@prisma/client in 57ms
在此步驟中,您將使用 Prisma Client 編寫種子腳本,目的是用一些示例數(shù)據(jù)來填充您的數(shù)據(jù)庫。
在這個上下文中,種子腳本其實就是一組利用 Prisma Client 執(zhí)行的 CRUD(創(chuàng)建、讀取、更新和刪除)操作。此外,您還可以利用嵌套寫入的功能,在單個操作中為相關(guān)的數(shù)據(jù)庫實體創(chuàng)建記錄。
打開框架src/seed.ts文件,您將在其中找到導(dǎo)入的Prisma Client和兩個Prisma Client函數(shù)調(diào)用:一個用于實例化Prisma Client,另一個用于在腳本完成運行時斷開連接。
開始,在 main 函數(shù)中創(chuàng)建一個用戶,如下所示:
const grace = await prisma.user.create({
data: {
email: 'grace@hey.com',
firstName: 'Grace',
lastName: 'Bell',
social: {
facebook: 'gracebell',
twitter: 'therealgracebell',
},
},
})該操作將在User表中創(chuàng)建一行,并返回創(chuàng)建的用戶(包括創(chuàng)建的id)。值得注意的是,user將推斷出在User中定義的類型@prisma/client:
export type User = {
id: number
email: string
firstName: string
lastName: string
social: JsonValue | null
}要執(zhí)行seed腳本并創(chuàng)建 User 記錄,可以在 seed 中使用 package.json腳本,如下所示:
npm run seed在執(zhí)行接下來的步驟時,您可能需要多次運行種子腳本。為了防止因重復(fù)運行而遇到唯一性約束錯誤(例如主鍵沖突或唯一索引沖突),您可以在?main?函數(shù)的開頭添加代碼來清空數(shù)據(jù)庫的內(nèi)容。
await prisma.testResult.deleteMany({})
await prisma.courseEnrollment.deleteMany({})
await prisma.test.deleteMany({})
await prisma.user.deleteMany({})
await prisma.course.deleteMany({})注意:這些命令將刪除每個數(shù)據(jù)庫表中的所有行。請謹慎使用,并在生產(chǎn)中避免這種情況!
在此步驟中,您將創(chuàng)建一個課程并使用嵌套寫入創(chuàng)建相關(guān)測試。
將以下內(nèi)容添加到 main 函數(shù):
const weekFromNow = add(new Date(), { days: 7 })
const twoWeekFromNow = add(new Date(), { days: 14 })
const monthFromNow = add(new Date(), { days: 28 })
const course = await prisma.course.create({
data: {
name: 'CRUD with Prisma',
tests: {
create: [
{
date: weekFromNow,
name: 'First test',
},
{
date: twoWeekFromNow,
name: 'Second test',
},
{
date: monthFromNow,
name: 'Final exam',
},
],
},
},
})這將會在 Course 表中插入一行數(shù)據(jù),并且在 Tests 表中插入三個與之相關(guān)聯(lián)的行(由于 Course 和 Tests 之間存在一對多的關(guān)系,因此可以這樣做)。
如果您希望將上一步中創(chuàng)建的用戶與本課程的教師角色建立關(guān)聯(lián),那么應(yīng)該怎么做呢?
User 和 Course 之間存在一個顯式的多對多關(guān)系。這意味著我們需要在 CourseEnrollment 表中插入一行數(shù)據(jù),并通過分配一個特定的角色來將 User 與 Course 關(guān)聯(lián)起來。
這可以按如下方式完成(添加到上一步的查詢中):
const weekFromNow = add(new Date(), { days: 7 })
const twoWeekFromNow = add(new Date(), { days: 14 })
const monthFromNow = add(new Date(), { days: 28 })
const course = await prisma.course.create({
data: {
name: 'CRUD with Prisma',
tests: {
create: [
{
date: weekFromNow,
name: 'First test',
},
{
date: twoWeekFromNow,
name: 'Second test',
},
{
date: monthFromNow,
name: 'Final exam',
},
],
},
members: {
create: {
role: 'TEACHER',
user: {
connect: {
email: grace.email,
},
},
},
},
},
include: {
tests: true,
},
})注意:
include參數(shù)允許你獲取結(jié)果中的關(guān)系。這將有助于在后面的步驟中將測試結(jié)果與測試相關(guān)聯(lián)
當采用嵌套寫入(例如為 members 和 tests)時,您有兩個選項可供選擇:
在 tests 的例子中,你傳遞了一個對象數(shù)組,這些對象與剛剛創(chuàng)建的課程存在關(guān)聯(lián)。
至于 members 的情況,create 和 connect 兩者都會被用到。這是至關(guān)重要的,因為即便用戶數(shù)據(jù)已經(jīng)存在于數(shù)據(jù)庫中,也仍然需要在關(guān)系表(即 CourseEnrollment,它引用了 members)中插入一行新的數(shù)據(jù)。這行新數(shù)據(jù)會利用 connect 與之前已創(chuàng)建的用戶數(shù)據(jù)建立起關(guān)系。
在上一步中,您創(chuàng)建了課程、相關(guān)測試,并為該課程分配了一名教師。在此步驟中,您將創(chuàng)建更多用戶,并將他們作為學生與課程關(guān)聯(lián)。
添加以下語句:
const shakuntala = await prisma.user.create({
data: {
email: 'devi@prisma.io',
firstName: 'Shakuntala',
lastName: 'Devi',
courses: {
create: {
role: 'STUDENT',
course: {
connect: { id: course.id },
},
},
},
},
})
const david = await prisma.user.create({
data: {
email: 'david@prisma.io',
firstName: 'David',
lastName: 'Deutsch',
courses: {
create: {
role: 'STUDENT',
course: {
connect: { id: course.id },
},
},
},
},
})看看TestResult模型,它有三個關(guān)系:student、gradedBy和test。要為Shakuntala和大衛(wèi)添加測試結(jié)果,您將使用與前面步驟類似的嵌套寫入。
以下是TestResult模型再次供參考:
model TestResult {
id Int @default(autoincrement()) @id
createdAt DateTime @default(now())
result Int // Percentage precise to one decimal point represented as result * 10^-1
// Relation Fields
studentId Int
student User @relation(name: "results", fields: [studentId], references: [id])
graderId Int
gradedBy User @relation(name: "graded", fields: [graderId], references: [id])
testId Int
test Test @relation(fields: [testId], references: [id])
}添加單個測試結(jié)果將如下所示:
await prisma.testResult.create({
data: {
gradedBy: {
connect: { email: grace.email },
},
student: {
connect: { email: shakuntala.email },
},
test: {
connect: { id: test.id },
},
result: 950,
},
})要為這三個測試中的每一個添加 David 和 Shakuntala 的測試結(jié)果,您可以創(chuàng)建一個循環(huán):
const testResultsDavid = [650, 900, 950]
const testResultsShakuntala = [800, 950, 910]
let counter = 0
for (const test of course.tests) {
await prisma.testResult.create({
data: {
gradedBy: {
connect: { email: grace.email },
},
student: {
connect: { email: shakuntala.email },
},
test: {
connect: { id: test.id },
},
result: testResultsShakuntala[counter],
},
})
await prisma.testResult.create({
data: {
gradedBy: {
connect: { email: grace.email },
},
student: {
connect: { email: david.email },
},
test: {
connect: { id: test.id },
},
result: testResultsDavid[counter],
},
})
counter++
}恭喜您!如果您已經(jīng)順利完成了上述步驟,那么就意味著您已經(jīng)在數(shù)據(jù)庫中成功創(chuàng)建了用戶、課程、測試以及測試結(jié)果的示例數(shù)據(jù)。
為了直觀地查看并瀏覽這些數(shù)據(jù),您可以運行 Prisma Studio。Prisma Studio 是一個功能強大的數(shù)據(jù)庫可視化工具。要啟動 Prisma Studio,您只需在終端中輸入并執(zhí)行以下命令:
npx prisma studioPrisma Client 允許您對模型的數(shù)字字段(例如 和 )執(zhí)行聚合操作。聚合操作從一組 Importing 值(即表中的多行)計算單個結(jié)果。例如,計算一組行中列的最小值、最大值和平均值。IntFloatresultTestResult
在此步驟中,您將運行兩種聚合操作:
1.對于所有學生的課程中的每個測試,生成表示測試難度或班級對測試主題的理解的聚合:
for (const test of course.tests) {
const results = await prisma.testResult.aggregate({
where: {
testId: test.id,
},
avg: { result: true },
max: { result: true },
min: { result: true },
count: true,
})
console.log(test: ${test.name} (id: ${test.id}), results)
}這將導(dǎo)致以下結(jié)果:
test: First test (id: 1) {
avg: { result: 725 },
max: { result: 800 },
min: { result: 650 },
count: 2
}
test: Second test (id: 2) {
avg: { result: 925 },
max: { result: 950 },
min: { result: 900 },
count: 2
}
test: Final exam (id: 3) {
avg: { result: 930 },
max: { result: 950 },
min: { result: 910 },
count: 2
}2.對于所有測試中的每個學生,生成表示學生在課程中的表現(xiàn)的聚合:
// Get aggregates for David
const davidAggregates = await prisma.testResult.aggregate({
where: {
student: { email: david.email },
},
avg: { result: true },
max: { result: true },
min: { result: true },
count: true,
})
console.log(David's results (email: ${david.email}), davidAggregates)
// Get aggregates for Shakuntala
const shakuntalaAggregates = await prisma.testResult.aggregate({
where: {
student: { email: shakuntala.email },
},
avg: { result: true },
max: { result: true },
min: { result: true },
count: true,
})
console.log(Shakuntala's results (email: ${shakuntala.email}), shakuntalaAggregates)這將導(dǎo)致以下終端輸出:
David's results (email: david@prisma.io) {
avg: { result: 833.3333333333334 },
max: { result: 950 },
min: { result: 650 },
count: 3
}
Shakuntala's results (email: devi@prisma.io) {
avg: { result: 886.6666666666666 },
max: { result: 950 },
min: { result: 800 },
count: 3
}本文廣泛涵蓋了多個基礎(chǔ)領(lǐng)域,從問題域的初步探索,到數(shù)據(jù)建模的深入研究,再到Prisma Schema的解析、使用Prisma Migrate進行數(shù)據(jù)庫遷移的方法,以及借助Prisma Client執(zhí)行CRUD操作和聚合的技巧。
在著手編寫代碼之前,明智之舉是先規(guī)劃出問題域。因為問題域?qū)⒅笇?dǎo)數(shù)據(jù)模型的設(shè)計思路,進而對后端的各個環(huán)節(jié)產(chǎn)生深遠影響。
盡管Prisma致力于簡化關(guān)系數(shù)據(jù)庫的使用流程,但深入理解底層數(shù)據(jù)庫的運作機制仍大有裨益。
建議您查閱Prisma的數(shù)據(jù)指南,以獲取關(guān)于數(shù)據(jù)庫工作原理的詳盡信息、數(shù)據(jù)庫選擇的策略,以及如何將數(shù)據(jù)庫與應(yīng)用程序高效融合,從而充分發(fā)揮其效能。
在本文系列的后續(xù)篇章中,我們將深入介紹以下主題:
原文鏈接:https://www.prisma.io/blog/backend-prisma-typescript-orm-with-postgresql-data-modeling-tsjs1ps7kip1



鍵.png)



