
使用這些基本 REST API 最佳實踐構建出色的 API
有時,樣本也被稱為幀,這與視頻幀的概念相似。音頻樣本(或幀)是一組數值,它們共同表示同一時間點每個硬件設備通道的音頻信號強度。但請注意,一些官方文檔對此持有不同觀點:它們明確定義樣本僅為單個數值,而幀則是所有通道這些數值的集合。那么,為什么我們不將采樣率稱為幀速率呢?請再次觀察上面的圖表。在那里,樣本寬度(即列寬)保持為16位,無論我們有多少個通道(即下面的行數)。樣本格式(在我們的例子中為有符號整數)也始終保持不變。采樣率是指1秒內音頻的列數,這與聲道的數量無關。因此,我根據自己的邏輯理解了音頻樣本的定義(盡管其他人可能有不同的定義),而您的邏輯可能與我不同,這完全沒問題。
樣本大小(或幀大小)是處理數字音頻時經常使用的另一個屬性。它只是一個常量值,方便我們在字節數和音頻樣本數之間進行轉換:
int sample_size = sample_width/8 * channels;
int bytes_in_buffer = samples_in_buffer * sample_size;當然,我們還可以為音頻緩沖區設定更多參數,例如緩沖區的長度(可以是以毫秒或字節為單位來衡量),這是調控聲音延遲的關鍵屬性。但請注意,每種設備對于這一參數都有其自身的限制:若設備不支持,我們無法將長度設定得過低。對我而言,250毫秒對于多數應用程序而言是個不錯的起點,不過,一些實時應用程序為了盡可能降低延遲,會接受更高的CPU使用率,這完全取決于您的具體應用場景。
在開啟音頻設備時,若我們使用的API返回“格式錯誤”的提示,這意味著我們選擇的音頻格式未得到底層軟件或物理設備的支持,對此我們應始終有所準備。此時,我們應挑選更合適的格式并重新創建緩沖區。
值得注意的是,一個物理設備在同一時間內只能被打開一次,我們無法將兩個或多個音頻緩沖區連接到同一設備,否則將會引發混亂。然而,在實際應用中,我們可能會遇到多個音頻應用程序希望通過單個設備并行播放音頻的情況。Windows在WASAPI中通過引入共享模式和獨占模式來解決這一問題。在共享模式下,我們將音頻緩沖區附加到虛擬設備上,該設備會將來自不同應用程序的所有音頻流進行混合,并可能應用一些過濾效果(例如聲音衰減),然后將處理后的數據傳遞給物理設備。Linux上的PulseAudio在ALSA上的工作原理與此相同。當然,共享模式的缺點是可能會帶來更高的延遲和CPU使用率。另一方面,在獨占模式下,我們幾乎可以直接與音頻設備驅動程序建立連接,這意味著我們可以獲得最高的音質和最小的延遲,但在使用該模式時,其他應用程序將無法訪問此設備。
步驟3:在我們準備并配置好音頻緩沖區后,就可以開始使用了:向其寫入數據進行播放,或從中讀取數據進行音頻錄制。音頻緩沖區實際上是一個循環緩沖區,其中的讀寫操作會以環形的方式無限循環進行。

但有一個關鍵問題:當在同一個內存緩沖區上執行輸入/輸出(I/O)操作時,CPU 必須與音頻設備保持同步。否則,CPU 可能會全速運行并在音頻緩沖區上執行數百萬次操作,而音頻設備可能才剛剛完成第一輪操作。因此,CPU 必須等待音頻設備緩慢地完成其工作。隨后,CPU 會在一段時間后短暫地喚醒,以便從設備獲取更多的音頻數據(在錄制模式下)或向設備提供新的數據(在播放模式下),然后 CPU 會繼續進入休眠狀態。這里,音頻緩沖區長度參數就顯得尤為重要:緩沖區越小,CPU 需要喚醒以執行工作的次數就越多。循環緩沖區可能處于三種不同的狀態:空、半滿和已滿,我們需要了解如何在代碼中正確處理這些狀態。
在錄制模式下,如果緩沖區為空,則意味著我們當前沒有可用的音頻樣本,必須等待音頻設備將新的數據放入其中。
播放時 如果緩沖區為空,則意味著我們可以隨時將音頻數據寫入緩沖區。然而,如果音頻設備正在運行且沒有更多數據可供讀取,就意味著我們沒有跟上設備的節奏,這種情況被稱為緩沖區下溢。如果發生這種情況,我們應該暫停設備,填充音頻緩沖區,然后恢復正常操作。
錄制時緩沖區半滿意味著緩沖區內有一些音頻樣本,但尚未完全填滿。我們應該盡快處理可用數據,并將此數據區域標記為已讀(或無用),以避免下次重復處理。
播放流的半滿緩沖區意味著我們可以向其中添加更多數據。
如果緩沖區已滿,則意味著我們在讀取可用數據方面落后于音頻設備。此時,音頻設備已經完全填滿了緩沖區,沒有更多空間來容納新數據。這種狀態被稱為緩沖區上溢。在這種情況下,我們必須重置緩沖區并恢復(取消暫停)設備以繼續正常操作。
播放流的緩沖區已滿是正常情況,我們應該等到有空閑空間可用。
關于如何執行等待過程,一些API提供了訂閱通知的方法,以實現盡可能低的I/O延遲。例如,ALSA能在將數據寫入音頻錄制緩沖區后,向我們的進程發送信號。而WASAPI在獨占模式下,則可通過Windows內核事件對象進行通知。但對于那些不需要高度精確性的應用程序,我們可以簡單地使用自己的計時器,或者采用類似的方法。在使用這些方法時,我們需確保休眠時間不超過音頻緩沖區長度的一半。例如,對于500毫秒的緩沖區,我們可以將計時器設置為250毫秒,并在每次緩沖區旋轉時執行兩次I/O操作。當然,您也明白,對于極小的緩沖區,我們無法可靠地做到這一點,因為即使是輕微的延遲也可能導致音頻卡頓。不過,在本教程中,我們并不需要高度精確性,但我們需要的是易于理解的小代碼段。
步驟 4。對于播放緩沖區,還有一項需要注意的事項。在我們完成向音頻緩沖區寫入所有數據后,仍需等待其處理完這些數據。換句話說,我們應確保緩沖區被完全耗盡。有時,我們可能需要手動向緩沖區添加靜音,以防止播放舊的無效數據,從而避免音頻偽影的出現。當我們觀察到整個緩沖區已清空后,即可停止設備并關閉緩沖區。
此外,請記住,在正常操作期間可能會出現以下問題:
細心的程序員必須始終檢查所有可能的情況,檢查我們調用的 API 函數的所有返回代碼并處理它們,或者向用戶顯示錯誤消息。我沒有在我的示例代碼中這樣做,只是因為本教程是為了讓您了解音頻 API。而這個目的可以通過盡可能短的代碼供你閱讀來實現 – 在這種情況下,到處都是錯誤檢查會使情況變得更糟。
當然,在我們完成后,我們必須關閉音頻緩沖區和設備的處理程序,釋放分配的內存區域。但請注意,如果我們只是想播放另一個音頻文件,那么重新準備新的音頻緩沖區可能會花費大量時間,因此我們應始終嘗試盡可能重用現有的緩沖區。
現在我們來談談音頻數據實際上是如何組織的以及如何分析它。音頻緩沖區有兩種類型:交錯和非交錯。Interleaved buffer 是一個連續的內存區域,其中的音頻樣本集逐個進行。這是 16 位立體聲音頻的樣子:
short[0][L]
short[0][R]
short[1][L]
short[1][R]
...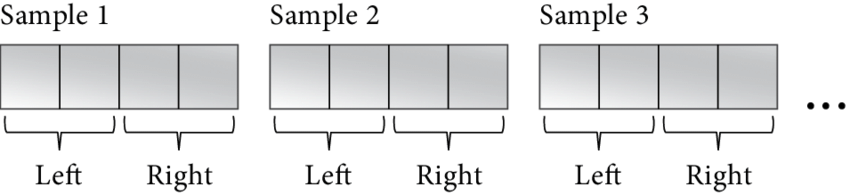
其中,0 和 1 是樣本索引,L 和 R 是通道。例如,我們如何讀取樣本 #9 的兩個通道的值,方法是將樣本索引乘以通道數:
short *samples = (short*)buffer;
short sample_9_left = samples[9*2];
short sample_9_right = samples[9*2 + 1];這些 16 位有符號值是信號強度,其中 0 表示靜音。但信號強度通常以 dB 值來衡量。以下是我們將整數值轉換為 dB 的方法:
short sample = ...;
double gain = (double)sample * (1 / 32768.0);
double db = log10(gain) * 20;在這里,我們首先將整數轉換為浮點數 – 這是增益值,其中 0.0 是靜音,+/-1.0 – 最大信號。然后,使用公式將增益轉換為 dB 值。如果我們想進行相反的轉換,我們可以使用以下代碼:gain = 10 ^ (db / 20)
#include <emmintrin.h> // SSE2 functions. All AMD64 CPU support them.
double db = ...;
double gain = pow(10, db / 20);
double d = gain * 32768.0;
short sample;
if (d < -32768.0)
sample = -0x8000;
else if (d > 32768.0 - 1)
sample = 0x7fff;
else
sample = _mm_cvtsd_si32(_mm_load_sd(&d));我不是音頻數學專家,我只是向您展示我是如何做到的,但您可能會找到更好的解決方案。
最流行的音頻編解碼器和大多數音頻 API 使用交錯音頻數據格式。
相比之下,非交錯緩沖區(Non-interleaved buffer)則是一個數組,它(可能)由不同的內存區域組成,每個通道占據一個區域。
L -> {
short[0][L]
short[1][L]
...
}
R -> {
short[0][R]
short[1][R]
...
}例如,主流的 Vorbis 和 FLAC 音頻編解碼器就采用了這種格式。如您所見,在非交錯緩沖區中操作單個通道內的樣本非常簡單。例如,交換左右聲道僅需幾個 CPU 周期來交換指針即可完成。
我認為我們已經掌握了足夠的理論知識,現在讓我們通過一些真實的代碼來實踐,這些代碼將使用真實的音頻 API。
ALSA 是 Linux 的默認音頻子系統,因此我們從它開始了解。ALSA 由兩部分組成:位于內核空間的音頻驅動程序和提供對驅動程序通用訪問的用戶空間 API。我們將學習的是用戶態 ALSA API,這是在用戶態下訪問聲音硬件的最低級別接口。
首先,我們需要在 Fedora 上安裝 ALSA 的開發包。安裝完成后,我們就可以在代碼中包含相關的庫了,即 libalsa-devel。
#include <alsa/asoundlib.h>當鏈接我們的二進制文件時,我們添加了 flag。
首先,遍歷系統中所有可用的聲卡,直到得到 -1 索引:
int icard = -1;
for (;;) {
snd_card_next(&icard);
if (icard == -1)
break;
...
}對于每個聲卡索引,我們可以準備一個以 NULL 結尾的字符串來作為此聲卡的唯一標識符。我們通過調用 snd_ctl_open() 函數,并傳入這個標識符,來接收對應的聲卡處理程序。在處理完畢后,我們使用 snd_ctl_close() 函數來關閉這個聲卡處理程序,從而結束對其的使用。
char scard[32];
snprintf(scard, sizeof(scard), "hw:%u", icard);
snd_ctl_t *sctl = NULL;
snd_ctl_open(&sctl, scard, 0);
...
snd_ctl_close(sctl);對于每個聲卡,我們遍歷其所有設備,直到得到 -1 索引:
int idev = -1;
for (;;) {
if (0 != snd_ctl_pcm_next_device(sctl, &idev)
|| idev == -1)
break;
...
}現在,我們準備一個以 NULL 結尾的字符串,例如 plughw:0,0,這是我們在后續分配音頻緩沖區時可能會使用的設備ID。前綴 plughw: 表示 ALSA 將在必要時嘗試應用一些音頻轉換。如果我們希望直接使用硬件設備,應該使用 hw: 前綴來代替。對于默認設備,我們可能會使用某個特定的字符串,但理論上這個字符串可能不可用——因此,您應該為用戶提供一種選擇特定設備的方法。請注意,plughw:hw: 是不正確的用法,正確的應該是直接使用 hw: 后跟設備編號,如 hw:0,0,或者在使用 plughw: 前綴時也指定設備編號,如 plughw:0,0。
char device_id[64];
snprintf(device_id, sizeof(device_id), "plughw:%u,%u", icard, idev);現在我們知道了設備 ID,我們可以使用 為其分配新的音頻緩沖區。請注意,我們無法兩次打開同一個 ALSA 設備。如果系統 PulseAudio 進程使用此設備,則在我們按住它時,系統中的其他應用程序將無法使用音頻。
snd_pcm_t *pcm;
const char *device_id = "plughw:0,0";
int mode = (playback) ? SND_PCM_STREAM_PLAYBACK : SND_PCM_STREAM_CAPTURE;
snd_pcm_open(&pcm, device_id, mode, 0);
...
snd_pcm_close(pcm);接下來,我們需要設置緩沖區的參數。在這個過程中,我們會告知 ALSA,我們打算使用 mmap 風格的函數來直接訪問其緩沖區,并且我們期望的是一個交錯的緩沖區。隨后,我們會設定音頻格式以及緩沖區長度。值得注意的是,如果設備不支持我們提供的這些值,ALSA 會自動為我們更新部分值。然而,如果設備不支持我們指定的示例格式,那么我們就需要通過使用?snd_pcm_hw_params_get_format_mask()?和?snd_pcm_format_mask_test()?等函數來進行檢查和處理。在現實生活中,您應當在高級代碼中驗證這些新配置是否被支持。
snd_pcm_hw_params_t *params;
snd_pcm_hw_params_alloca(¶ms);
snd_pcm_hw_params_any(pcm, params);
int access = SND_PCM_ACCESS_MMAP_INTERLEAVED;
snd_pcm_hw_params_set_access(pcm, params, access);
int format = SND_PCM_FORMAT_S16_LE;
snd_pcm_hw_params_set_format(pcm, params, format);
u_int channels = 2;
snd_pcm_hw_params_set_channels_near(pcm, params, &channels);
u_int sample_rate = 48000;
snd_pcm_hw_params_set_rate_near(pcm, params, &sample_rate, 0);
u_int buffer_length_usec = 500 * 1000;
snd_pcm_hw_params_set_buffer_time_near(pcm, params, &buffer_length_usec, NULL);
snd_pcm_hw_params(pcm, params);最后,我們需要記住幀大小和整個緩沖區大小(以字節為單位)。
int frame_size = (16/8) * channels;
int buf_size = sample_rate * (16/8) * channels * buffer_length_usec / 1000000;要開始錄制,我們調用 :
snd_pcm_start(pcm);在正常操作期間,我們向 ALSA 請求一些新的音頻數據,這些數據返回緩沖區、有效區域的偏移量和有效幀數。要使此函數正常工作,我們應該首先調用 which 更新緩沖區的內部指針。處理完數據后,必須處理數據。
for (;;) {
snd_pcm_avail_update(pcm);
const snd_pcm_channel_area_t *areas;
snd_pcm_uframes_t off;
snd_pcm_uframes_t frames = buf_size / frame_size;
snd_pcm_mmap_begin(pcm, &areas, &off, &frames);
...
snd_pcm_mmap_commit(pcm, off, frames);
}當我們獲得 0 個可用幀時,這意味著緩沖區是空的。如有必要,啟動錄制流,然后等待更多數據。我使用 100 毫秒的間隔,但實際上它應該使用實際緩沖區大小來計算。
if (frames == 0) {
int period_ms = 100;
usleep(period_ms*1000);
continue;
}在我們獲得一些數據后,我們獲得指向實際交錯數據和此區域中可用字節數的指針:
const void *data = (char*)areas[0].addr + off * areas[0].step/8;
int n = frames * frame_size;寫入音頻與讀取音頻的過程幾乎相同。我們首先通過?snd_pcm_mmap_begin()?獲取緩沖區,然后將數據復制到該緩沖區中,接著使用?snd_pcm_mmap_commit()?將其標記為處理完成。當緩沖區已滿時,我們會收到指示,表明沒有可用的空閑幀。在這種情況下,我們會首次啟動播放流,并隨后開始等待,直到緩沖區中再次出現一些可用空間。
if (frames == 0) {
if (SND_PCM_STATE_RUNNING != snd_pcm_state(pcm))
snd_pcm_start(pcm);
int period_ms = 100;
usleep(period_ms*1000);
continue;
}要耗盡播放緩沖區,我們不需要做任何特殊的事情。首先,我們檢查 buffer 中是否還有一些數據,如果有,請等待 buffer 完全清空。
for (;;) {
if (0 >= snd_pcm_avail_update(pcm))
break;
if (SND_PCM_STATE_RUNNING != snd_pcm_state(pcm))
snd_pcm_start(pcm);
int period_ms = 100;
usleep(period_ms*1000);
}但是,我們為何總是需要檢查緩沖區的狀態,并在必要時調用 snd_pcm_start(),這是因為 ALSA 不會自動開始音頻流的傳輸。我們需要在緩沖區填滿后手動啟動它,并且在每次遇到緩沖區溢出等錯誤時也需要重新啟動。此外,即使我們沒有完全填充緩沖區,有時也需要啟動它。
在使用 ALSA 時,大多數函數都會返回一個整數結果代碼。成功時返回 0,失敗時則返回非零的錯誤代碼。為了將這些錯誤代碼轉換為用戶友好的錯誤消息,我們可以使用 snd_strerror() 函數。同時,我還建議記錄返回錯誤的函數名稱,這樣用戶就能獲得關于具體錯誤的完整信息。
然而,處理錯誤還遠遠不夠。在正常播放或錄制音頻的過程中,我們還需應對緩沖區溢出或欠載的情況。那么,該如何處理呢?首先,我們需要檢查錯誤代碼是否為?-EPIPE。如果是,那么就需要調用?snd_pcm_prepare()?來重置緩沖區。如果重置失敗,那么我們就無法繼續正常操作,這是一個致命錯誤。但如果重置成功,我們就可以像沒有發生緩沖區溢出一樣繼續正常操作。
if (err == -EPIPE)
assert(0 == snd_pcm_prepare(pcm));我們需要特殊錯誤處理的下一個情況是在我們調用 function 之后。問題是,即使它返回了一些數據而不是錯誤代碼,我們仍然需要檢查是否所有數據都被處理了。如果沒有,我們自己設置錯誤代碼,然后我們可以用上面顯示的相同代碼來處理它。
err = snd_pcm_mmap_commit(pcm, off, frames);
if (err >= 0 && (snd_pcm_uframes_t)err != frames)
err = -EPIPE;接下來,這些函數可能會返回錯誤代碼,這意味著由于某種原因,我們當前使用的設備已暫時停止或暫停。如果發生這種情況,我們應該等到設備再次上線,定期檢查狀態。然后我們調用以重置緩沖區并照常繼續。
if (err == -ESTRPIPE) {
while (-EAGAIN == snd_pcm_resume(pcm)) {
int period_ms = 100;
usleep(period_ms*1000);
}
snd_pcm_prepare(pcm);
}不要忘記,在處理完這些錯誤之后,我們需要調用 start 緩沖區。對于錄制流,我們會立即執行此操作,對于播放流,我們會在緩沖區已滿時執行此操作。
PulseAudio 工作在 ALSA 之上,它并不能替代 ALSA,而只是作為一個音頻層,提供了一些在圖形多應用程序環境中非常有用的功能,比如混音、轉換、重新路由以及播放音頻通知。因此,與 ALSA 不同,PulseAudio 能夠允許多個應用程序共享單個音頻設備——我認為這是它最為有用的特性。
請注意,在 Fedora 上,PulseAudio 不再是默認的音頻層,它被 PipeWire 和另一個音頻 API 所取代(盡管 PulseAudio 應用程序將繼續通過 PipeWire-PulseAudio 層工作)。但是,在 PipeWire 不是其他流行的 Linux 發行版的默認選擇之前,PulseAudio 總體上更有用。
首先,我們需要安裝 Fedora 的開發包。現在,我們可以將其包含在我們的代碼中:libpulse-devel。
#include <pulse/pulseaudio.h>當鏈接我們的二進制文件時,我們添加了 flag。-lpulse
關于 PulseAudio 與其他產品的不同之處。PulseAudio 采用客戶端-服務器設計,這意味著我們不直接在音頻設備上操作,而只是向 PulseAudio 服務器發出命令并從中接收響應。因此,我們總是從連接到 PulseAudio 服務器開始。我們必須實現一些復雜的邏輯來做到這一點,因為我們和服務器之間的交互是異步的:我們必須向服務器發送命令,然后等待它處理我們的命令并接收結果,所有這些都通過套接字 (UNIX) 連接完成。當然,這種通信需要一些時間,我們可以在等待服務器響應的同時做一些其他事情。但是,對于這里的示例代碼,我們不會那么復雜:我們只會同步等待響應,這樣更容易理解。
我們首先創建一個單獨的線程,它將為我們處理套接字 I/O 操作。不要忘記在完成 PulseAudio 后停止此線程并關閉其處理程序。
pa_threaded_mainloop *mloop = pa_threaded_mainloop_new();
pa_threaded_mainloop_start(mloop);
...
pa_threaded_mainloop_stop(mloop);
pa_threaded_mainloop_free(mloop);使用 PulseAudio 時首先要記住的是,我們必須在持有此 I/O 線程的內部鎖的同時執行所有操作。“鎖定線程”,對 PA 對象執行必要的調用,然后“解鎖線程”。未能正確鎖定線程可能隨時導致爭用條件。此鎖是遞歸的,這意味著從同一線程多次鎖定它是安全的。只需調用 unlocking 函數相同次數即可。但是,我看不出鎖遞歸在現實生活中有什么用處。遞歸鎖通常意味著我們的架構很糟糕,它們可能會導致難以發現的問題 – 我從不建議使用此功能。
pa_threaded_mainloop_lock(mloop);
...
pa_threaded_mainloop_unlock(mloop);現在開始連接到PA服務器。請注意,即便連接尚未建立,function通常會立即返回。我們稍后會在設置的回調函數中接收到連接的結果。完成后,別忘了斷開與服務器的連接。pa_context_connect() pa_context_set_state_callback()
pa_mainloop_api *mlapi = pa_threaded_mainloop_get_api(mloop);
pa_context *ctx = pa_context_new_with_proplist(mlapi, "My App", NULL);
void *udata = NULL;
pa_context_set_state_callback(ctx, on_state_change, udata);
pa_context_connect(ctx, NULL, 0, NULL);
...
pa_context_disconnect(ctx);
pa_context_unref(ctx);在我們發出 connection 命令后,除了等待結果之外,我們別無他法。我們詢問連接狀態,如果它還沒有準備好,我們調用 which 阻塞我們的線程,直到收到信號。
while (PA_CONTEXT_READY != pa_context_get_state(ctx)) {
pa_threaded_mainloop_wait(mloop);
}下面是我們的?on-state-change?回調函數的樣子,它并不復雜:我們只是向我們的線程發出信號,讓它從我們當前掛起的位置退出。請注意,此函數并非由我們自己的線程(它仍處于掛起狀態)調用,而是由之前啟動的 I/O 線程調用。作為一般原則,請盡量保持這些回調函數中的代碼簡短。你的函數被調用時,接收結果并向你的線程發送一個信號,這樣通常就足夠了。至于?pa_threaded_mainloop_wait()?和?pa_threaded_mainloop_start(),它們在這段描述中并未直接涉及。
void on_state_change(pa_context *c, void *userdata)
{
pa_threaded_mainloop_signal(mloop, 0);
}我希望這個調用堆棧圖能讓您更清楚地了解 PA 服務器連接邏輯:
[Our Thread]
|- pa_threaded_mainloop_start()
| [PA I/O Thread]
|- pa_context_connect() |
|- pa_threaded_mainloop_wait() |
| |- on_state_change()
| |- pa_threaded_mainloop_signal()
[pa_threaded_mainloop_wait() returns]相同的邏輯適用于使用我們的回調函數處理所有操作結果。
建立與 PA 服務器的連接后,我們繼續列出可用設備。我們使用回調函數創建一個新操作。我們也可以傳遞一些指向回調函數的指針,但我只使用 value。操作完成后,不要忘記釋放指針。當然,這段代碼應該只在持有 mainloop 線程鎖時執行。
pa_operation *op;
void *udata = NULL;
if (playback)
op = pa_context_get_sink_info_list(ctx, on_dev_sink, udata);
else
op = pa_context_get_source_info_list(ctx, on_dev_source, udata);
...
pa_operation_unref(op);現在等待操作完成。
for (;;) {
int r = pa_operation_get_state(op);
if (r == PA_OPERATION_DONE || r == PA_OPERATION_CANCELLED)
break;
pa_threaded_mainloop_wait(mloop);
}當我們這樣做時,I/O 線程正在從服務器接收數據,并對我們的回調函數執行幾次成功的調用,我們可以在其中訪問每個可用設備的所有屬性。當發生錯誤或沒有更多設備時,parameter 將設置為非零值。發生這種情況時,我們只需將信號發送到我們的線程。列出播放設備的函數如下所示:
void on_dev_sink(pa_context *c, const pa_sink_info *info, int eol, void *udata)
{
if (eol != 0) {
pa_threaded_mainloop_signal(mloop, 0);
return;
}
const char *device_id = info->name;
}列出錄制設備的函數看起來類似:
void on_dev_source(pa_context *c, const pa_source_info *info, int eol, void *udata)我們創建一個新的音頻緩沖區,并將我們的連接上下文傳遞給它、我們的應用程序的名稱和我們想要使用的聲音格式。
pa_sample_spec spec;
spec.format = PA_SAMPLE_S16LE;
spec.rate = 48000;
spec.channels = 2;
pa_stream *stm = pa_stream_new(ctx, "My App", &spec, NULL);
...
pa_stream_unref(stm);接下來,我們將緩沖區附加到設備。我們將緩沖區長度設置為特定字節數,并將所有其他參數保留為默認值(即將它們設置為-1)。同時,我們分配了一個callback函數,該函數會在每次音頻I/O完成時被調用。我們可以使用在枚舉設備時獲得的device_id值,或者將device_id設置為NULL以使用默認設備。相關的函數調用包括pa_stream_connect_(),設置pa_buffer_attr::t.length,以及pa_stream_set__callback()。
pa_buffer_attr attr;
memset(&attr, 0xff, sizeof(attr));
int buffer_length_msec = 500;
attr.tlength = spec.rate * 16/8 * spec.channels * buffer_length_msec / 1000;對于錄制流,我們執行以下操作:
void *udata = NULL;
pa_stream_set_read_callback(stm, on_io_complete, udata);
const char *device_id = ...;
pa_stream_connect_record(stm, device_id, &attr, 0);
...
pa_stream_disconnect(stm);對于播放流:
void *udata = NULL;
pa_stream_set_write_callback(stm, on_io_complete, udata);
const char *device_id = ...;
pa_stream_connect_playback(stm, device_id, &attr, 0, NULL, NULL);
...
pa_stream_disconnect(stm);像往常一樣,我們必須等到操作完成。我們使用(某種方法)來讀取緩沖區的當前狀態:如果狀態是 PA_STREAM_READY,則表示錄制已成功開始,我們可以繼續正常操作;如果狀態是 PA_STREAM_FAILED,則表示發生了錯誤。
for (;;) {
int r = pa_stream_get_state(stm);
if (r == PA_STREAM_READY)
break;
else if (r == PA_STREAM_FAILED)
error
pa_threaded_mainloop_wait(mloop);
}當我們掛起時,回調函數將在 I/O 線程內的某個時間點被調用。現在我們只需向主線程發送一個信號。
void on_io_complete(pa_stream *s, size_t nbytes, void *udata)
{
pa_threaded_mainloop_signal(mloop, 0);
}我們使用 PulseAudio 獲取包含音頻樣本的數據區域,處理完后,丟棄此數據。
for (;;) {
const void *data;
size_t n;
pa_stream_peek(stm, &data, &n);
if (n == 0) {
// Buffer is empty. Process more events
pa_threaded_mainloop_wait(mloop);
continue;
} else if (data == NULL && n != 0) {
// Buffer overrun occurred
} else {
...
}
pa_stream_drop(stm);
}pa_stream_peek() 函數在緩沖區為空時會返回 0 個樣本。在這種情況下,我們無需調用它,而是應該等待更多數據到達。當緩沖區溢出發生時,這只是給我們的一個通知,我們可以通過再次調用 pa_stream_peek()來繼續處理。不過,需要注意的是,連續調用 pa_stream_drop() 和 pa_stream_peek() 并不是處理溢出的標準或推薦方式,如果緩沖區溢出,可能需要更復雜的邏輯來處理數據流,例如調整讀取速率或請求更少的數據。
當我們將數據寫入音頻設備時,我們首先必須用 獲取音頻緩沖區中的可用空間量。當緩沖區已滿時,它返回 0,我們必須等到有可用空間后再試一次。
size_t n = pa_stream_writable_size(stm);
if (n == 0) {
pa_threaded_mainloop_wait(mloop);
continue;
}我們得到緩沖區,我們可以在其中復制音頻樣本。填滿緩沖區后,我們調用 to release this memory region.
void *buf;
pa_stream_begin_write(stm, &buf, &n);
...
pa_stream_write(stm, buf, n, NULL, 0, PA_SEEK_RELATIVE);為了耗盡緩沖區,我們創建一個 drain 操作,并將我們的回調函數傳遞給它,該函數將在 draining 完成時調用。
void *udata = NULL;
pa_operation *op = pa_stream_drain(stm, on_op_complete, udata);
...
pa_operation_unref(op);現在等待我們的回調函數向我們發出信號。
for (;;) {
int r = pa_operation_get_state(op);
if (r == PA_OPERATION_DONE || r == PA_OPERATION_CANCELLED)
break;
pa_threaded_mainloop_wait(mloop);
}我們的回調函數如下所示:
void on_op_complete(pa_stream *s, int success, void *udata)
{
pa_threaded_mainloop_signal(mloop, 0);
}WASAPI 是從 Windows Vista 開始的默認聲音子系統。它是 DirectSound API 的后繼者,我們在這里不討論,由于我懷疑您可能不希望支持舊的 Windows XP 系統,因此在這里我們不對 DirectSound API 進行討論。但如果您確實需要支持 Windows XP,請自行查閱 ffaudio 中的相關代碼。WASAPI 可以在 2 種不同的模式下工作:共享模式和獨占模式。在共享模式下,多個應用程序可以使用同一物理設備,這是適合通常播放/錄制應用程序的模式。在獨占模式下,我們可以獨占訪問音頻設備,這適用于專業的實時聲音應用程序。
請注意,在使用 WASAPI 的 include 指令之前,必須確保有預處理器定義 COBJMACROS,以確保純 C 定義能夠正常工作。
#define COBJMACROS
#include <mmdeviceapi.h>
#include <audioclient.h>在執行任何其他操作之前,我們必須初始化 COM 接口子系統。
CoInitializeEx(NULL, 0);我們必須使用鏈接器標志鏈接所有 WASAPI 應用程序。
大多數 WASAPI 函數在成功時返回 0,在失敗時返回非零。
我們使用 CoCreateInstance()創建設備枚舉器對象。完成后,請不要忘記發布它。
IMMDeviceEnumerator *enu;
const GUID _CLSID_MMDeviceEnumerator = {0xbcde0395, 0xe52f, 0x467c, {0x8e,0x3d, 0xc4,0x57,0x92,0x91,0x69,0x2e}};
const GUID _IID_IMMDeviceEnumerator = {0xa95664d2, 0x9614, 0x4f35, {0xa7,0x46, 0xde,0x8d,0xb6,0x36,0x17,0xe6}};
CoCreateInstance(&_CLSID_MMDeviceEnumerator, NULL, CLSCTX_ALL, &_IID_IMMDeviceEnumerator, (void**)&enu);
...
IMMDeviceEnumerator_Release(enu);我們使用這個設備枚舉器對象來獲取可用設備的數組。
IMMDeviceCollection *dcoll;
int mode = (playback) ? eRender : eCapture;
IMMDeviceEnumerator_EnumAudioEndpoints(enu, mode, DEVICE_STATE_ACTIVE, &dcoll);
...
IMMDeviceCollection_Release(dcoll);通過要求返回指定數組索引的設備處理程序來枚舉設備。
for (int i = 0; ; i++) {
IMMDevice *dev;
if (0 != IMMDeviceCollection_Item(dcoll, i, &dev))
break;
...
IMMDevice_Release(dev);
}然后,獲取此設備的屬性集。
IPropertyStore *props;
IMMDevice_OpenPropertyStore(dev, STGM_READ, &props);
...
IPropertyStore_Release(props);使用 讀取單個屬性值。下面介紹如何獲取設備的用戶友好名稱。
PROPVARIANT name;
PropVariantInit(&name);
const PROPERTYKEY _PKEY_Device_FriendlyName = {{0xa45c254e, 0xdf1c, 0x4efd, {0x80, 0x20, 0x67, 0xd1, 0x46, 0xa8, 0x50, 0xe0}}, 14};
IPropertyStore_GetValue(props, &_PKEY_Device_FriendlyName, &name);
const wchar_t *device_name = name.pwszVal;
...
PropVariantClear(&name);現在我們需要列出設備的主要原因是:我們使用 IMMDevice_GetId().
wchar_t *device_id = NULL;
IMMDevice_GetId(dev, &device_id);
...
CoTaskMemFree(device_id);要獲取系統默認設備,我們使用?IMMDeviceEnumerator_GetDefaultAudioEndpoint()?方法。之后,我們可以采用與上述步驟完全相同的方式來獲取該設備的 ID 和 name。
IMMDevice *def_dev = NULL;
IMMDeviceEnumerator_GetDefaultAudioEndpoint(enu, mode, eConsole, &def_dev);
IMMDevice_Release(def_dev);這是在共享模式下打開音頻緩沖區的最簡單方法。我們再次從創建一個設備枚舉器對象開始。
IMMDeviceEnumerator *enu;
const GUID _CLSID_MMDeviceEnumerator = {0xbcde0395, 0xe52f, 0x467c, {0x8e,0x3d, 0xc4,0x57,0x92,0x91,0x69,0x2e}};
const GUID _IID_IMMDeviceEnumerator = {0xa95664d2, 0x9614, 0x4f35, {0xa7,0x46, 0xde,0x8d,0xb6,0x36,0x17,0xe6}};
CoCreateInstance(&_CLSID_MMDeviceEnumerator, NULL, CLSCTX_ALL, &_IID_IMMDeviceEnumerator, (void**)&enu);
...
IMMDeviceEnumerator_Release(enu);現在,我們要么使用默認捕獲設備,要么已經知道特定的設備 ID。無論哪種情況,我們都會得到設備描述符。
IMMDevice *dev;
wchar_t *device_id = NULL;
if (device_id == NULL) {
int mode = (playback) ? eRender : eCapture;
IMMDeviceEnumerator_GetDefaultAudioEndpoint(enu, mode, eConsole, &dev);
} else {
IMMDeviceEnumerator_GetDevice(enu, device_id, &dev);
}
...
IMMDevice_Release(dev);我們創建一個音頻捕獲緩沖區,并向其傳遞 identificator。
IAudioClient *client;
const GUID _IID_IAudioClient = {0x1cb9ad4c, 0xdbfa, 0x4c32, {0xb1,0x78, 0xc2,0xf5,0x68,0xa7,0x03,0xb2}};
IMMDevice_Activate(dev, &_IID_IAudioClient, CLSCTX_ALL, NULL, (void**)&client);
...
IAudioClient_Release(client);由于我們希望在共享模式下打開 WASAPI 音頻緩沖區,因此無法使其使用所需的音頻格式。音頻格式是系統級配置的主題,我們只需要遵守它。這種格式很可能是 16bit/44100/立體聲或 24bit/44100/立體聲,但我們無法確切知道。值得注意的是,盡管 WASAPI 有時能夠接受與我們提供的樣本不同的格式(例如,我們提供 float32 格式,而 WASAPI 自動將其轉換為 16 位),但我們不能依賴這種自動轉換行為。要獲得正確的音頻格式,最可靠的方法是調用相關函數讓它為我們創建一個 WAVE 格式標頭,這種標頭格式與 .wav 文件中使用的相同。此外,請注意,在 Windows 中,音頻格式有兩種不同的設置,這取決于我們的緩沖區是分配給哪個設備的。要獲取混合格式,可以使用?IAudioClient_GetMixFormat()?方法。
WAVEFORMATEX *wf;
IAudioClient_GetMixFormat(client, &wf);
...
CoTaskMemFree(wf);現在我們只需使用這種音頻格式來設置我們的緩沖區。請注意,我們在這里使用 flag,這意味著我們想要在共享模式下配置緩沖區。緩沖區長度參數必須以 100 納秒為間隔。請記住,這只是一個提示,在函數成功返回后,我們應該始終獲取 WASAPI 選擇的實際緩沖區長度。
int buffer_length_msec = 500;
REFERENCE_TIME dur = buffer_length_msec * 1000 * 10;
int mode = AUDCLNT_SHAREMODE_SHARED;
int aflags = 0;
IAudioClient_Initialize(client, mode, aflags, dur, dur, (void*)wf, NULL);
u_int buf_frames;
IAudioClient_GetBufferSize(client, &buf_frames);
buffer_length_msec = buf_frames * 1000 / wf->nSamplesPerSec;我們初始化了緩沖區,但它沒有為我們提供可用于執行 I/O 的接口。在我們的記錄流中,我們必須從中獲取接口對象。
IAudioCaptureClient *capt;
const GUID _IID_IAudioCaptureClient = {0xc8adbd64, 0xe71e, 0x48a0, {0xa4,0xde, 0x18,0x5c,0x39,0x5c,0xd3,0x17}};
IAudioClient_GetService(client, &_IID_IAudioCaptureClient, (void**)&capt);準備工作已完成,我們已準備好開始錄制。
IAudioClient_Start(client);為了獲取一段錄制的音頻數據,我們調用?IAudioCaptureClient_GetBuffer()?方法。當緩沖區內沒有未讀數據時,該方法會返回?AUDCLNT_S_BUFFER_EMPTY?錯誤。在這種情況下,我們只需等待一段時間,然后再嘗試調用一次。處理完音頻樣本后,我們使用?IAudioCaptureClient_ReleaseBuffer()?方法來釋放緩沖區。
for (;;) {
u_char *data;
u_int nframes;
u_long flags;
int r = IAudioCaptureClient_GetBuffer(capt, &data, &nframes, &flags, NULL, NULL);
if (r == AUDCLNT_S_BUFFER_EMPTY) {
// Buffer is empty. Wait for more data.
int period_ms = 100;
Sleep(period_ms);
continue;
} else (r != 0) {
// error
}
...
IAudioCaptureClient_ReleaseBuffer(capt, nframes);
}播放音頻與錄音非常相似,但我們需要使用另一個接口進行 I/O。這次我們傳入 identificator 并獲取接口對象。
IAudioRenderClient *render;
const GUID _IID_IAudioRenderClient = {0xf294acfc, 0x3146, 0x4483, {0xa7,0xbf, 0xad,0xdc,0xa7,0xc2,0x60,0xe2}};
IAudioClient_GetService(client, &_IID_IAudioRenderClient, (void**)&render);
...
IAudioRenderClient_Release(render);正常的播放操作是,一旦緩沖區中有一些空閑空間,我們就會在循環中向音頻緩沖區添加更多數據。為了獲得已用空間量,我們調用 。為了獲得可用空間量,我們使用打開緩沖區時獲得的緩沖區 () 的大小。這些數字以樣本為單位,而不是以字節為單位。
u_int filled;
IAudioClient_GetCurrentPadding(client, &filled);
int n_free_frames = buf_frames - filled;當緩沖區已滿時,該函數將已用空間數設置為 0。現在,我們第一次擁有完整的緩沖區必須開始播放。
if (!started) {
IAudioClient_Start(client);
started = 1;
}我們獲得了 free buffer region,在用音頻樣本填充它之后,我們使用 IAudioRenderClient_ReleaseBuffer() 來釋放并提交這個緩沖區。而在此之前,我們是通過 IAudioRenderClient_GetBuffer() 來獲取這個 free buffer region 的。
u_char *data;
IAudioRenderClient_GetBuffer(render, n_free_frames, &data);
...
IAudioRenderClient_ReleaseBuffer(render, n_free_frames, 0);我們永遠不會忘記在關閉之前耗盡音頻緩沖區,否則不會播放最后一個音頻數據,因為我們沒有給它足夠的時間。該算法與 ALSA 相同。我們得到仍需播放的樣本數量,當緩沖區為空時,耗盡完成。
for (;;) {
u_int filled;
IAudioClient_GetCurrentPadding(client, &filled);
if (filled == 0)
break;
...
}如果我們的輸入數據太小,甚至無法填滿我們的音頻緩沖區,那么此時我們仍然沒有開始播放。我們這樣做,否則永遠不會用 “buffer empty” 條件向我們發出信號。
if (!started) {
IAudioClient_Start(client);
started = 1;
}大多數 WASAPI 函數在成功時返回 0,在失敗時返回錯誤代碼。此錯誤代碼的問題在于,有時我們無法直接將其轉換為用戶友好的錯誤消息 – 我們必須手動進行。首先,我們檢查它是否是 code。在這種情況下,我們必須根據值設置自己的錯誤消息。例如,我們可能為每個可能的代碼都有一個字符串數組。不要忘記索引越界檢查!
int err = ...;
if ((err & 0xffff0000) == MAKE_HRESULT(SEVERITY_ERROR, FACILITY_AUDCLNT, 0)) {
err = err & 0xffff;
static const char audclnt_errors[][39] = {
"",
"AUDCLNT_E_NOT_INITIALIZED", // 0x1
...
"AUDCLNT_E_RESOURCES_INVALIDATED", // 0x26
};
const char *error_name = audclnt_errors[err];
}但是如果它不是代碼,我們可以以通常的方式從 Windows 獲取錯誤消息。
wchar_t buf[255];
int n = FormatMessageW(FORMAT_MESSAGE_FROM_SYSTEM | FORMAT_MESSAGE_IGNORE_INSERTS | FORMAT_MESSAGE_MAX_WIDTH_MASK
, 0, err, 0, buf, sizeof(buf)/sizeof(*buf), 0);
if (n == 0)
buf[0] = '\0';存儲返回錯誤的函數的名稱始終是一種很好的做法。用戶必須知道到底哪個函數失敗了,它返回了哪個代碼以及錯誤描述。
OSS 是 FreeBSD 和其他一些操作系統上的默認音頻子系統。在 ALSA(高級 Linux 聲音架構)取代它之前,OSS 也曾是 Linux 上的默認音頻子系統。盡管一些文檔指出,現代 Linux 仍然支持 OSS 層,但普遍認為它對于新軟件的開發已不再具有主要作用。與其他音頻 API 相比,OSS API 顯得尤為簡單,因為它僅使用標準的系統調用。OSS 的 I/O 操作與常規文件的 I/O 操作類似,這使得 OSS 極易理解和使用。
包括必要的頭文件:
#include <sys/soundcard.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>打開系統混音器設備的方式與我們打開常規文件的方式完全相同。
int mixer = open("/dev/mixer", O_RDONLY, 0);
...
close(mixer);我們通過以下方式發出命令與此設備通信。獲取具有設備控制代碼的已注冊設備的數量。
oss_sysinfo si = {};
ioctl(mixer, SNDCTL_SYSINFO, &si);
int n_devs = si.numaudios;我們使用SNDCTL_AUDIOINFO_EX 獲取每個設備的屬性。
for (int i = 0; i != n_devs; i++) {
oss_audioinfo ainfo = {};
ainfo.dev = i;
ioctl(mixer, SNDCTL_AUDIOINFO_EX, &ainfo);
...
}因為我們遍歷所有設備(包括播放設備和錄制設備),所以我們必須使用特定的字段來過濾出我們所需的內容:PCM_CAP_OUTPUT?表示這是一個播放設備,而?PCM_CAP_INPUT?則意味著這是一個錄制設備。我們從同一個對象中獲取其他必要的信息,其中最重要的是設備 ID。相關的結構體或類是?oss_audioinfo。
int is_playback_device = !!(ainfo.caps & PCM_CAP_OUTPUT);
int is_capture_device = !!(ainfo.caps & PCM_CAP_INPUT);
const char *device_id = ainfo.devnode;
const char *device_name = ainfo.name;我們使用 open() 函數打開音頻設備并獲取設備描述符。如果要使用默認設備,我們傳遞相應的設備路徑。我們需要將正確的標志傳遞給 open() 函數:O_WRONLY 用于播放,O_RDONLY 用于錄制(因為我們將從設備中讀取數據)。此外,我們還可以在這里使用 O_NONBLOCK 標志,這使得我們的描述符是非阻塞的,即讀/寫函數不會阻塞,而是會立即返回一個錯誤(通常會設置 errno 為 EAGAIN 來表示資源暫時不可用)。
const char *device_id = NULL;
if (device_id == NULL)
device_id = "/dev/dsp";
int flags = (playback) ? O_WRONLY : O_RDONLY;
int dsp = open(device_id, flags | O_EXCL, 0);
...
close(dsp);讓我們為要使用的音頻格式配置設備。我們將要使用的值傳遞給 ioctl(),并在返回時使用設備驅動程序設置的實際值對其進行更新。當然,這個值可以與我們傳遞的值不同。在實際代碼中,我們必須檢測此類情況,并通知用戶格式更改或退出并出現錯誤。
int format = AFMT_S16_LE;
ioctl(dsp, SNDCTL_DSP_SETFMT, &format);
int channels = 2;
ioctl(dsp, SNDCTL_DSP_CHANNELS, &channels);
int sample_rate = 44100;
ioctl(dsp, SNDCTL_DSP_SPEED, &sample_rate);要設置音頻緩沖區長度,我們首先獲取設備的 “fragment size” 屬性。然后,我們使用此值將緩沖區長度轉換為片段數。片段不是音頻幀,片段大小不是樣本的大小!然后我們使用控制代碼設置 fragment 的數量。請注意,如果我們不想設置自己的緩沖區長度并使用默認緩沖區長度,則可以跳過本節。
audio_buf_info info = {};
if (playback)
ioctl(dsp, SNDCTL_DSP_GETOSPACE, &info);
else
ioctl(dsp, SNDCTL_DSP_GETISPACE, &info);
int buffer_length_msec = 500;
int frag_num = sample_rate * 16/8 * channels * buffer_length_msec / 1000 / info.fragsize;
int fr = (frag_num << 16) | (int)log2(info.fragsize); // buf_size = frag_num * 2^n
ioctl(dsp, SNDCTL_DSP_SETFRAGMENT, &fr);我們已經完成了設備的準備工作。現在我們獲得用于播放或錄制流的實際緩沖區長度。
audio_buf_info info = {};
int r;
if (playback)
r = ioctl(dsp, SNDCTL_DSP_GETOSPACE, &info);
else
r = ioctl(dsp, SNDCTL_DSP_GETISPACE, &info);
buffer_length_msec = info.fragstotal * info.fragsize * 1000 / (sample_rate * 16/8 * channels);
int buf_size = info.fragstotal * info.fragsize;
frame_size = 16/8 * sample_rate * channels;最后,我們分配所需大小的緩沖區。
void *buf = malloc(buf_size);
...
free(buf);沒有什么比使用 OSS 進行音頻 I/O 更容易的了。我們使用通常的函數將我們的音頻緩沖區和其中的最大可用字節數傳遞給它。它返回讀取的字節數。該函數還會在緩沖區為空時阻止執行,因此無需為我們調用 sleep 函數。
int n = read(dsp, buf, buf_size);對于播放流,我們首先將音頻樣本寫入緩沖區,然后使用write() .它返回實際寫入的字節數。這些函數在緩沖區已滿時阻止執行。
int n = write(dsp, buf, n);為了耗盡并同步緩沖區,我們僅使用?SNDCTL_DSP_SYNC?控制代碼。它會阻塞進程,直到播放操作完成。
ioctl(dsp, SNDCTL_DSP_SYNC, 0);失敗時,open()、ioctl()、read()?或?write()?會返回負值,并設置?errno。我們可以像往常一樣使用?strerror()?將?errno?轉換為錯誤消息。
int err = ...;
const char *error_message = strerror(err);CoreAudio 是 macOS 和 iOS 上的默認聲音子系統。我對此沒有什么經驗,因為我不喜歡 Apple 的產品。我只是向您展示它對我的工作方式,但理論上可能有比我更好的解決方案。必要的包括:
#include <CoreAudio/CoreAudio.h>
#include <CoreFoundation/CFString.h>鏈接時,我們傳遞鏈接器標志。
我們首先需要知道要為數組分配的最小字節數,為此我們使用 AudioObjectGetPropertyDataSize() 來獲得所需的大小。然后,我們可以用這個信息來分配適當的數組,并使用 AudioObjectGetPropertyData() 來填充該數組。
const AudioObjectPropertyAddress prop_dev_list = { kAudioHardwarePropertyDevices, kAudioObjectPropertyScopeGlobal, kAudioObjectPropertyElementMaster };
u_int size;
AudioObjectGetPropertyDataSize(kAudioObjectSystemObject, &prop_dev_list, 0, NULL, &size);
AudioObjectID *devs = (AudioObjectID*)malloc(size);
AudioObjectGetPropertyData(kAudioObjectSystemObject, &prop_dev_list, 0, NULL, &size, devs);
int n_dev = size / sizeof(AudioObjectID);
...
free(devs);然后我們遍歷數組以獲取設備 ID。
for (int i = 0; i != n_dev; i++) {
AudioObjectID device_id = devs[i];
...
}對于每個設備,我們可以獲得一個用戶友好的名稱,但我們必須使用 CFStringGetCString().
const AudioObjectPropertyAddress prop_dev_outname = { kAudioObjectPropertyName, kAudioDevicePropertyScopeOutput, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress prop_dev_inname = { kAudioObjectPropertyName, kAudioDevicePropertyScopeInput, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress *prop = (playback) ? &prop_dev_outname : &prop_dev_inname;
u_int size = sizeof(CFStringRef);
CFStringRef cfs;
AudioObjectGetPropertyData(devs[i], prop, 0, NULL, &size, &cfs);
CFIndex len = CFStringGetMaximumSizeForEncoding(CFStringGetLength(cfs), kCFStringEncodingUTF8);
char *device_name = malloc(len + 1);
CFStringGetCString(cfs, device_name, len + 1, kCFStringEncodingUTF8);
CFRelease(cfs);
...
free(device_name);如果我們想使用默認設備,以下是獲取其 ID 的方法。
AudioObjectID device_id;
const AudioObjectPropertyAddress prop_odev_default = { kAudioHardwarePropertyDefaultOutputDevice, kAudioObjectPropertyScopeGlobal, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress prop_idev_default = { kAudioHardwarePropertyDefaultInputDevice, kAudioObjectPropertyScopeGlobal, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress *a = (playback) ? &prop_odev_default : &prop_idev_default;
u_int size = sizeof(AudioObjectID);
AudioObjectGetPropertyData(kAudioObjectSystemObject, a, 0, NULL, &size, &device_id);獲取支持的音頻格式。似乎 CoreAudio 默認使用 float32 樣本。
const AudioObjectPropertyAddress prop_odev_fmt = { kAudioDevicePropertyStreamFormat, kAudioDevicePropertyScopeOutput, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress prop_idev_fmt = { kAudioDevicePropertyStreamFormat, kAudioDevicePropertyScopeInput, kAudioObjectPropertyElementMaster };
AudioStreamBasicDescription asbd = {};
u_int size = sizeof(asbd);
const AudioObjectPropertyAddress *a = (playback) ? &prop_odev_fmt : &prop_idev_fmt;
AudioObjectGetPropertyData(device_id, a, 0, NULL, &size, &asbd);
int sample_rate = asbd.mSampleRate;
int channels = asbd.mChannelsPerFrame;創建音頻長度為 500 毫秒的緩沖區。請注意,我們在這里使用自己的 ring buffer 在回調函數和 I/O 循環之間傳輸數據。
int buffer_length_msec = 500;
int buf_size = 32/8 * sample_rate * channels * buffer_length_msec / 1000;
ring_buf = ringbuf_alloc(buf_size);
...
ringbuf_free(ring_buf);注冊 I/O 回調函數,當 CoreAudio 有更多數據需要我們(用于錄制)或當它想要從我們那里讀取一些數據(用于播放)時,它將調用該函數。我們可以將 ring buffer 作為用戶參數傳遞。返回值是一個指針,我們稍后使用它來控制流。
AudioDeviceIOProcID io_proc_id = NULL;
void *udata = ring_buf;
AudioDeviceCreateIOProcID(device_id, proc, udata, &io_proc_id);
...
AudioDeviceDestroyIOProcID(device_id, io_proc_id);回調函數如下所示:
OSStatus io_callback(AudioDeviceID device, const AudioTimeStamp *now,
const AudioBufferList *indata, const AudioTimeStamp *intime,
AudioBufferList *outdata, const AudioTimeStamp *outtime,
void *udata)
{
...
return 0;
}我們從 AudioDeviceStart()開始錄制。
AudioDeviceStart(device_id, io_proc_id);然后,一段時間后,我們的回調函數被調用。在內部,我們必須將所有音頻樣本添加到我們的 ring 緩沖區中。
const float *d = indata->mBuffers[0].mData;
size_t n = indata->mBuffers[0].mDataByteSize;
ringbuf *ring = udata;
ringbuf_write(ring, d, n);
return 0;在我們的 I/O 循環中,我們嘗試從緩沖區讀取一些數據。如果緩沖區為空,則等待,然后重試。我在這里的 ring buffer 實現允許我們直接使用 buffer。我們獲取緩沖區,對其進行處理,然后釋放它。
ringbuffer_chunk buf;
size_t h = ringbuf_read_begin(ring_buf, -1, &, NULL);
if (.len == 0) {
// Buffer is empty. Wait until some new data is available
int period_ms = 100;
usleep(period_ms*1000);
continue;
}
...
ringbuf_read_finish(ring_buf, h);在回調函數中,我們將音頻樣本從環形緩沖區寫入 CoreAudio 的緩沖區。請注意,我們從緩沖區中讀取 2 次,因為一旦我們到達環形緩沖區中內存區域的末尾,我們就必須從頭開始。如果緩沖區中沒有足夠的數據,我們會傳遞 silence (數據區域填充為零),以便在播放這些數據時不會聽到意外。
float *d = outdata->mBuffers[0].mData;
size_t n = outdata->mBuffers[0].mDataByteSize;
ringbuf *ring = udata;
ringbuffer_chunk buf;
size_t h = ringbuf_read_begin(ring, n, &buf, NULL);
memcpy(buf.ptr, d, buf.len);
ringbuf_read_finish(ring, h);
d = (char*)d + buf.len;
n -= buf.len;
if (n != 0) {
h = ringbuf_read_begin(ring, n, &buf, NULL);
memcpy(buf.ptr, d, buf.len);
ringbuf_read_finish(ring, h);
d = (char*)d + buf.len;
n -= buf.len;
}
if (n != 0)
memset(d, 0, n);在我們的主 I/O 循環中,我們首先獲得空閑緩沖區,我們在其中寫入新的音頻樣本。當緩沖區已滿時,我們第一次啟動流并等待調用我們的回調函數。
ringbuffer_chunk buf;
size_t h = ringbuf_write_begin(ring_buf, 16*1024, &buf, NULL);
if (buf.len == 0) {
if (!started) {
AudioDeviceStart(device_id, io_proc_id);
started = 1;
}
// Buffer is full. Wait.
int period_ms = 100;
usleep(period_ms*1000);
continue;
}
...
ringbuf_write_finish(ring_buf, h);要耗盡緩沖區,我們只需等待環形緩沖區為空。當環形緩沖區為空時(意味著所有數據都已處理完畢),我們再進行后續操作。請注意,如果輸入的數據量小于緩沖區的大小,那么我們的音頻流可能還未真正啟動。若遇到這種情況,我們應先調用?AudioDeviceStop()?停止音頻設備,然后再根據需要調用?AudioDeviceStart()?重新啟動。
size_t free_space;
ringbuffer_chunk d;
ringbuf_write_begin(ring_buf, 0, &d, &free_space);
if (free_space == ring_buf->cap) {
AudioDeviceStop(device_id, io_proc_id);
break;
}
if (!started) {
AudioDeviceStart(device_id, io_proc_id);
started = 1;
}
// Buffer isn't empty. Wait.
int period_ms = 100;
usleep(period_ms*1000);我認為我們已經介紹了最常見的音頻API及其用例,希望您能從中學到一些新的和有用的知識。然而,有幾項內容并未在本教程中涵蓋:
原文鏈接:https://habr.com/en/articles/663352/