本章探討了利用財務文本數據進行股票市場預測的相關研究工作。首先回顧了早期研究中采用的基于詞嵌入的技術,這些技術雖然能夠提取文本數據中的信息,但缺乏對語境的深入理解。例如,一些研究通過分析金融新聞流中的情感分數、社交媒體帖子來預測股票價格,但這些方法未能充分利用文本的上下文信息。
接著,本章介紹了大型語言模型(LLMs)的分類和它們在量化投資中的應用。LLMs通過在大量文本數據上進行預訓練,學習到了通用的語言模式。文中詳細討論了三種類型的LLMs:僅編碼器模型、僅解碼器模型和編碼器-解碼器混合模型,以及它們如何通過預訓練和微調來適應特定的下游任務。特別提到了參數高效的微調技術,如低秩適應(LoRA),這種技術通過在預訓練模型參數中引入低秩變化來減少計算和內存需求。
最后,本章還概述了近期的研究工作,這些工作利用LLMs作為特征提取器,直接從文本中提取預測信號。一些研究通過微調預訓練的LLMs來進行更準確的財務情感分析,而其他研究則通過在生成性LLMs上使用prompt來提取金融新聞和價格歷史中的關鍵因素。這些研究表明,LLMs在量化投資領域具有巨大的潛力,能夠提供從文本到股票未來表現的直接建模能力。
3.1 問題陳述:
如何利用大型語言模型(LLMs)來預測股票回報以支持股票選擇。在這一部分中,作者設定了一個包含多只股票的投資宇宙,并解釋了量化投資者如何根據定量標準從這個宇宙中選擇股票來構建投資組合。隨著市場條件的不斷變化,投資者需要定期更新或重新平衡他們的投資組合,這就需要一個有效的股票選擇過程。
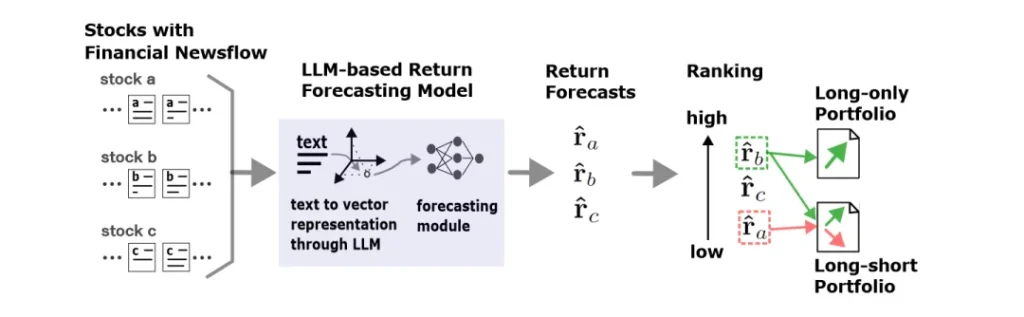
作者指出,傳統的股票選擇過程通常涉及多步驟的特征提取和驗證,這可能耗時且需要額外的標記數據和持續的改進。為了簡化這一過程,作者提出了利用LLMs直接從財務新聞文本中預測股票回報的方法。這種方法的核心是將文本數據轉換為數值向量,這些向量能夠捕捉文本的語義信息,并作為預測未來股票表現的特征。
在構建預測模型時,作者提出了一個由文本表示模塊和預測模塊組成的復合結構模型。文本表示模塊負責將輸入的文本序列編碼為數值向量,而預測模塊則基于這些向量來預測股票的n步未來回報。為了實現這一目標,作者使用了一種特殊的訓練方法,即聯合微調預訓練的LLM作為文本表示模塊,并訓練一個密集層作為預測模塊,以最小化預測值與真實值之間的均方誤差。
此外,作者還描述了如何構建用于訓練的數據實例集合。每個實例都是通過將投資宇宙中的股票標識符與相關新聞鏈接起來,并使用回顧時間窗口來選擇可用新聞。這種方法允許模型學習新聞文本與股票未來表現之間的關系。
3.2 方法論:
探討了構建基于LLM的股票回報預測模型的方法論,這一模型由文本表示模塊和預測模塊組成,旨在將財務新聞文本轉化為股票回報的數值預測。文本表示模塊利用預訓練的LLM將輸入的文本序列轉換成高維向量表示,這些向量捕捉了文本的語義信息。具體來說,作者討論了編碼器-only和解碼器-only LLMs在文本表示上的差別,編碼器模型如BERT和DeBERTa通過遮蔽語言建模任務學習上下文嵌入,而解碼器模型如GPT-3和Mistral通過自回歸的下一個詞預測任務進行訓練。這些模型的不同預訓練目標導致它們在處理文本時采用不同的策略,從而影響最終的文本表示。
此外,本節還介紹了兩種將LLMs生成的token級向量整合到預測模塊的方法:瓶頸表示和聚合表示。瓶頸表示通過在輸入序列末尾添加一個特殊的結束序列(EOS)標記,利用其向量表示來壓縮整個序列的信息。這種方法對于編碼器模型在微調過程中與預訓練的一致性可能更為有利。相對地,聚合表示則是通過簡單平均或更復雜的機制(如注意力機制)將所有token的向量表示合并起來,以獲得整個序列的統一表示。作者選擇了簡單平均方法來實現聚合表示,因為它不需要額外的訓練參數,并且可以清晰地與瓶頸表示進行比較。
最后,第3.2節還討論了模型的實現細節,包括使用低秩適應(LoRA)技術對LLMs進行微調,以及其他技術如梯度檢查點、混合精度訓練和DeepSpeed來減少GPU內存使用。這些技術的運用使得模型能夠在有限的資源下進行有效的訓練。通過這些方法,研究者能夠在不同的投資宇宙上進行實驗,評估模型在股票回報預測任務上的性能,并探索不同類型LLMs在量化投資策略中的適用性。
本章詳細記錄了利用大型語言模型(LLMs)進行股票回報預測的實證研究過程和分析結果。研究使用了2003年至2019年間的公司級財務新聞流數據,這些數據包括了新聞內容和相關公司標識符。同時,研究涵蓋了北美、歐洲和新興市場的股票投資宇宙數據集,包含了股票標識符和對應日期的真實月度前向回報。
實驗中,每個數據實例是通過將投資宇宙數據中的股票標識符與相關新聞通過回溯時間窗口(例如一周)鏈接起來構建的。具體來說,北美市場的數據集包含了630只股票,平均每只股票有2.5條新聞,共有366011個訓練實例和241367個測試實例;歐洲市場的數據集包含了350只股票,平均每只股票有1.9條新聞,共有100403個訓練實例和121705個測試實例;新興市場的數據集則包含了370只股票,平均每只股票有2.6條新聞,共有71610個訓練實例和183608個測試實例。
模型訓練使用了批量大小為32,學習率為1e-5,并采用了100步的預熱階段后接線性衰減的策略。LLMs的微調采用了低秩適應(LoRA)技術,所有模型均在最大上下文長度為4k的情況下訓練了10個周期,并使用了2個A100 GPU。
在投資組合構建方面,Long-only投資組合是通過選擇基于回報預測排名位于頂部9/10的股票構建的,而long-short投資組合則包括了排名在頂部9/10和底部1/10的股票。所有投資組合中的股票均采用等權重。
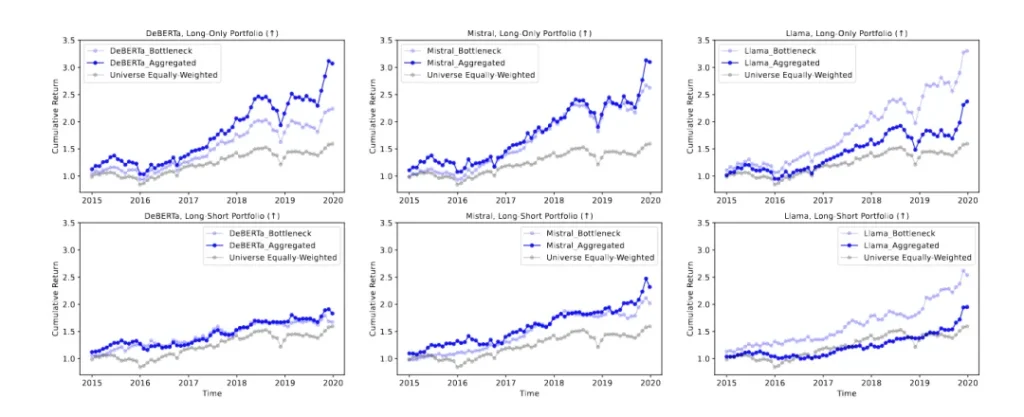
回測評估采用了月度再平衡的方式,模擬了每月構建的投資組合的交易情況,并報告了累積回報圖表和測試期間的性能統計數據,如年化回報和夏普比率。
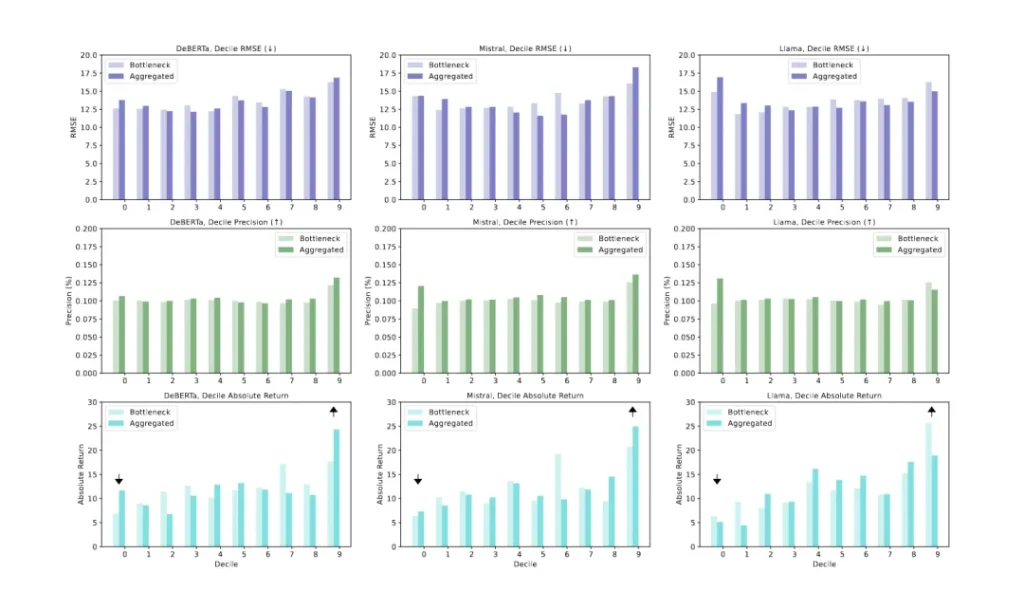
具體到評估指標,研究使用了分位數RMSE、分位數精確度和分位數回報三個指標來衡量預測模型的性能。分位數RMSE衡量了基于預測排名的分位數內實際回報與預測回報之間的誤差;分位數精確度表示了實際高回報股票被正確預測在高回報分位數的比例;分位數回報則是基于預測分位數的股票實際回報。
實驗結果顯示,在北美市場中,使用聚合表示的Mistral和Llama模型在long-only投資組合中實現了較高的年化回報,分別為25.15%和27.00%,夏普比率分別為1.20和1.32。在long-short投資組合中,使用聚合表示的DeBERTa和Mistral模型也展現出了較高的年化回報和夏普比率,分別為12.87%和1.49,以及18.30%和1.26。在歐洲市場中,Mistral的聚合表示在long-only投資組合中表現最佳,年化回報為15.12%,夏普比率為1.02;在long-short投資組合中,同樣使用聚合表示的Mistral模型年化回報為9.07%,夏普比率為1.04。新興市場的結果與北美和歐洲市場類似,其中Llama的聚合表示在long-only投資組合中年化回報最高,為12.76%,夏普比率為0.90。
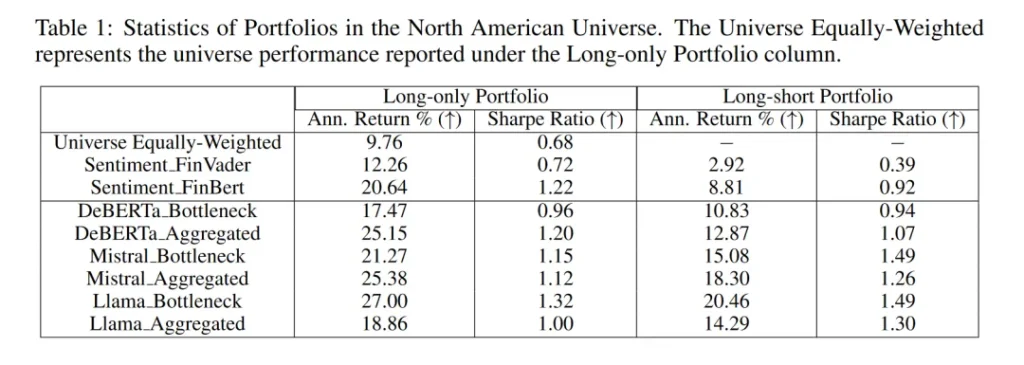
與基于情感分析的投資組合相比,基于LLMs的預測投資組合在多數情況下表現更佳。例如,在北美市場中,基于FinBERT和FinVader情感分析的long-only投資組合年化回報分別為20.64%和12.26%,夏普比率分別為1.22和0.72,而基于DeBERTa聚合表示的預測投資組合年化回報為25.15%,夏普比率為1.20。在long-only投資組合中,基于情感分析的投資組合表現不佳,特別是FinBert,年化回報和夏普比率均為負值。
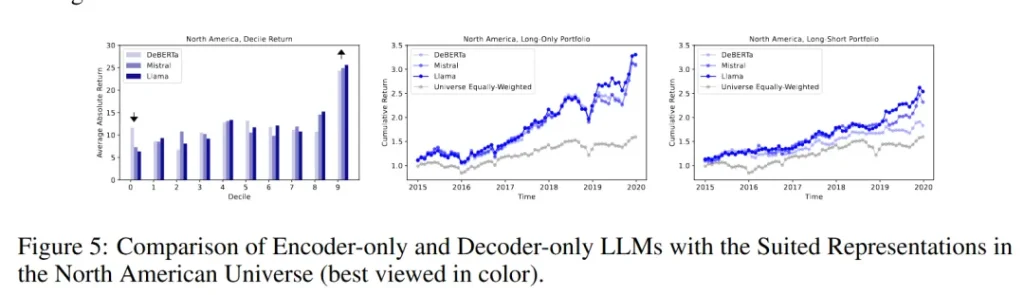
此外,研究還發現,雖然聚合表示在某些情況下提供了更高的分位數回報,但這并不總是意味著較低的分位數RMSE。例如,在北美市場中,DeBERTa和Mistral的聚合表示在頂部9/10分位數的分位數回報較高,但相應的分位數RMSE也較高。這表明,盡管預測可能不夠精確,但只要預測結果仍然落在正確的分位數內,投資組合的回報就不會受到影響。
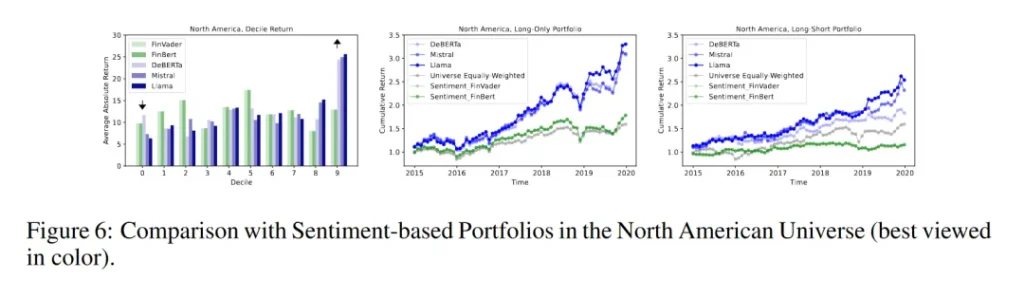
本文證明了通過微調大型語言模型(LLMs)來直接建立財務新聞文本表示與股票未來回報之間的關系是可行的,并且能夠為量化投資組合構建提供有價值的信號。研究發現,使用LLMs的token級嵌入的聚合表示通常能夠提高僅多頭和多空投資組合的表現;在較大的投資宇宙中,基于解碼器的LLMs預測模型能夠產生更強的投資組合,而在較小的投資宇宙中,不同模型的表現則沒有一致性。在所研究的三種LLMs(DeBERTa、Mistral、Llama)中,Mistral在不同投資宇宙中表現更為穩健。此外,基于LLMs文本表示的回報預測相較于傳統情感分析方法,在投資組合構建中表現更佳。盡管如此,論文也指出了一些未解決的問題,例如需要進一步研究編碼器-only模型在大型投資宇宙中表現不佳的原因,以及不同小宇宙中性能變化的原因,為未來的研究提供了方向。
最后,為大家提供一下好用且高效的大語言模型API:
原文轉自 微信公眾號@QuantML