
Python + BaiduTransAPI :快速檢索千篇英文文獻(附源碼)
Source API 已經引入很多版本,從 1.12 開始我們有了 Source API 的第一個版本,到 Flink 1.14 開始逐漸達到一個穩定的狀態,并標記成 Public。如果了解 Flink 的時間較長,我們之前還有 InputFormat 和 SourceFunction。請大家注意這些 API 在 2.0 都會被棄用掉,如果需要開發一個新的 Connector ,請關注最新的 Source API 。
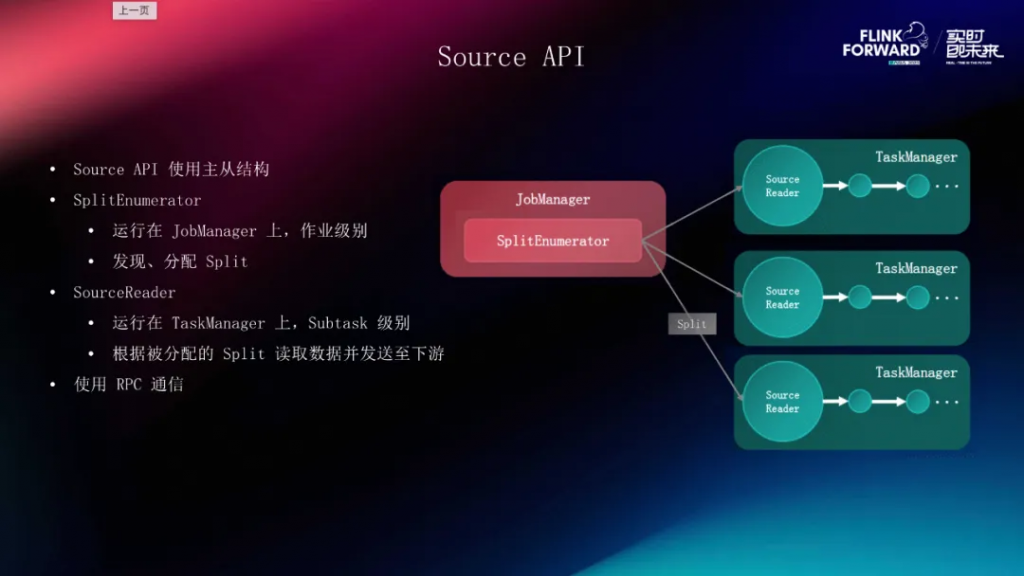
從整體的設計來看,Source API 使用了主從的結構,和 Flink 的集群結構是類似的,它分為了兩個部分,第一部分就是 SplitEnumerator ,它相當于整個 Source 的大腦,從名字上來看它的主要功能就是枚舉、分片。
分片是 Source 對外部系統的部分抽象,比如 Kafka 一個分片就是一個 Topic 里的 Partition。如果是一個文件系統的 Source ,那一個 Split 就是一個文件或者是一個文件夾。SplitEnumerator 的工作就是在外部系統當中發現這些分片并把它做成任務分配給最終真正進行干活的,我們稱為 SourceReader 。SplitEnumerator 是作業級別的,也就是每個作業或者說每個 Source 是只有一個的, SourceReader 是 Subtask 級別的,整個 Source 的并發是多少,那我們 SourceReader 的實例就有多少。SourceReader 和 Enumerator之間是通過 JM 和 TM 的 RPC 進行通信的,我們在這之上也封裝了一些事件能夠讓 Enumerator 和 Reader 之間進行溝通,我們稱之為 Source Event,這樣能夠更好地協調 Enumerator 和 Reader 之間的任務分配和全局管理的工作。
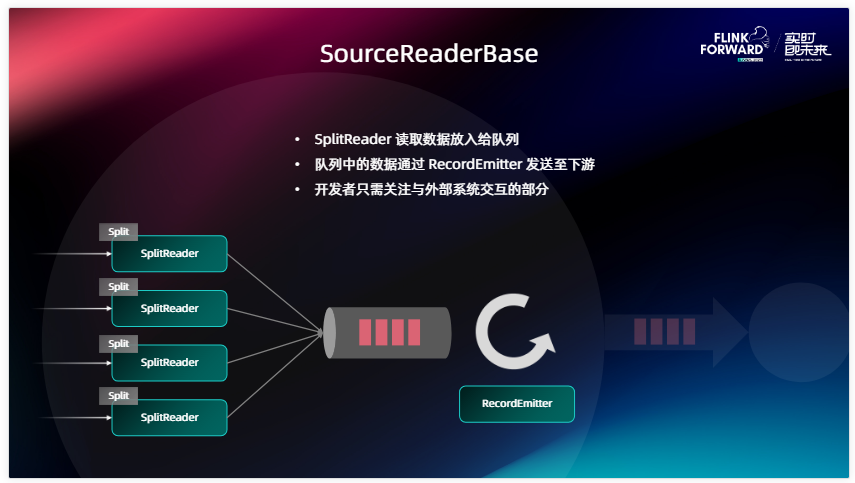
為了進一步簡化用戶對 Source 的開發過程,正如上圖所示,我們提供 SourceReaderBase 的基類,SourceReader 是一個相當于比較底層的接口,為了簡化開發難度,我們也提供了一個 SourceReaderBase ,它進一步把 Source 和外部系統之間的溝通部分和與 Flink 進行協作的部分做了一個拆分,這樣做的好處是 Source 開發者能夠更加關注和外部系統之間的交互,而不需要過多關注和 Flink 之間的 Checkpoint 處理、會不會影響 Flink 主線程的工作等問題。在 SorceReaderBase 的設計之下,我們又抽出了一個名為 SplitReader 的 API,它才是真正的從外部系統中拉取數據,根據 Enumerator 分配的分片到外部系統中讀取數據的部分。數據在讀取來之后,SplitReader 會把它放到 SourceReaderBase 中間的一個 Element 隊列,實際上就是做了和外部系統以及和 Flink 之間的隔離。在 Flink 這一側,我們真正運轉的是 Flink Task 的主線程,這是一個沒有 Box 的模型,它會不斷地從中間拉取數據,然后把數據經過 RecordEmitter 的處理后發送到下游。RecordEmitter 的工作主要就是用來做反序列化,將外部系統當中的數據格式轉換成下游當中的一些數據格式。

在開發 Source 的時候需要注意的問題有哪些,這個是我在檢查 Source 的實現和管理當中總結出來的。第一點是開發的時候一定要注意把和外部系統交互的部分以及和 Flink 交互的部分區分開,比如剛剛講的 SourceReaderBase 為什么中間要插一個隊列,這樣就是盡量把和外部系統交互的部分和與 Flink 之間交互的部分區分開。之所以這樣做是因為 Flink 的主線程是一個 mailbox 模型 ,包括 Checkpoint 和一些控制信息的傳遞都是通過這個 mailbox 的線程來做的。如果是我們用它去和外部系統做 IO 的話,這樣有可能會對下游算子以及整個 Task 的運行產生一些影響,包括 Checkpoint 的運行有可能也會受到一定程度的影響,所以在開發的時候一定要注意把做 IO 的線程和 Flink 的線程區分開。
第二點是我們 Source 當中提供了很多工具或者說方法,比如 SplitEnumeratorContext 里面有一個 callAsync 方法,很多人在開發 Enumerator 時沒有注意到它,自己去起一個線程池或者去起一個線程,很費勁地去處理各個線程之間的協調問題。那通過這個 callAsync 我們已經提供了一個能夠給外部系統做 IO 的一個線程的,叫 worker thread。大家就可以直接利用這個工具,我們會在 Flink 里面把一些線程之間的隔離問題處理好。盡量能去復用 SourceReaderBase 和 SplitReader 的時候就盡量去復用它,這樣能夠大大降低我們的開發難度,總的來說就是盡量自己少造輪子,可以復用現有的輪子。
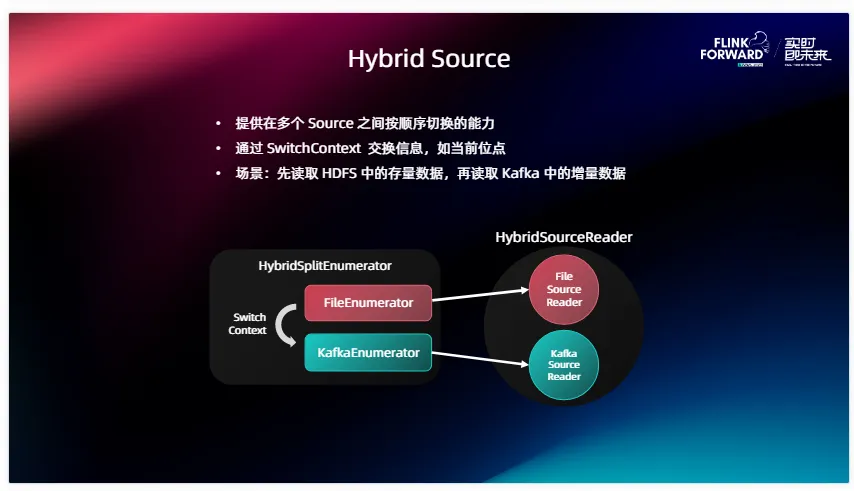
在近幾個版本中我們對 Source 的功能做了增強,首先就是 Hybrid Source ,它有一種典型的用戶場景,一些線上用戶需要首先去讀取 HDFS 或者其他文件系統存儲里面的一些存量數據,在讀取完已有的存量數據之后進行切換,比如切到 Kafka 或者其他的消息隊列來讀在線數據,那實際上是需要一個在不同 Source 之間進行切換的能力。Hybrid Source 就是在現有 Source 的基礎上,封裝這么一層,提供了這樣一個多 Source 之間按序切換的能力。兩個 Source 之間是有切換順序的,當一個 Source 比如 FileEnumerator 執行完工作之后,會產生一個 Switch context ,也就是說我會把當前的進度或狀態的信息通過這個 SwitchContext 提供給接下來要運行的 Source 。比如說剛提到的場景里面,FileEnumerator 就要告訴 Kafka 的 Enumerator 我現在讀到哪, Kafka Enumerator 會根據當前在 Switchcontext 里面提供的位點信息或者說時間信息來正確地啟動 Kafka Source 的讀取,平滑地遷移到存量階段或者在線數據的讀取當中。從這個架構圖中我們也可以觀察到,實際上 Hybrid Source 就是對我們現有的 Enumerator 還有 Reader 進行了二次封裝,并提供了這樣一個工具類來幫助它們進行切換。
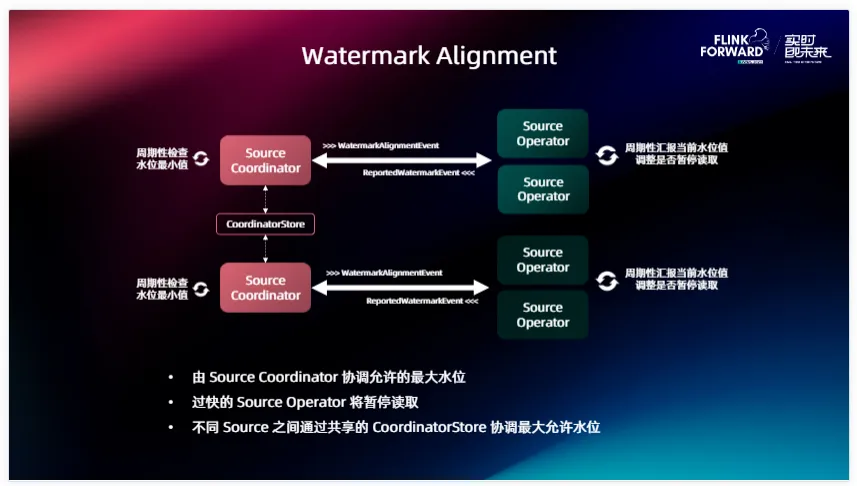
先說一下這個問題的背景,不管大家的作業當中有一個 Source 還是多個 Source ,經常會遇到的情況是不同 Source 之間讀取的進度差異會很大,比方如果是 Kafka, Source 中的某一個 Partition 因為網絡或者其他原因,它的進度遠遠落后于其他的 Partition。或者有兩個 Source ,它們之間因為讀取不同的外部系統導致產生不同的進度,這樣就會導致一些下游的算子比如說我需要做一些 Join、我需要做 Aggregate,就需要等待所有并發的 Watermark 都前進到同一個位置之后才能夠出發計算,只要有一個拖了后腿,那其他人的數據都要在狀態里面等,這樣就會導致后面某些需要用到的算子狀態會越來越大,這實際上就是讀取進度的不同所導致的。
針對這個問題,我們提出了這樣一個 Watermark Alignment 的機制,在實現的時候,如果是同一個 Source 相對會簡單一點,可以直接在這個 Source 的 Coordinator 、或者說是 Enumerator 里面就把這個事情做了。如果跨 Source 之間要實現這個能力,我們是在中間引入了一個叫 CoordinatorStore 的一個組件。它能夠讓不同的 Source 之間來交換一些信息,在這里面我們需要交換的就是 Watermark 信息, Source Operator 這邊會周期性的給自己的 Coordinator 匯報當前處理的進度怎么樣,然后 Source Coordinator 會周期性的檢查當前進度的最小值,如果發現某些 Operator 讀的太快了,有落在后面的并發或者說落在后面的 Source ,會讓它先等一等,降低一下讀取速度,等大家都追齊之后再往前讀。這就是 Watermark Alignment 實現的一個細節。
介紹完 Source 之后,我們再為大家介紹一下 Sink API 。Sink API 也是經過了很多版本的迭代,最開始我們有 OutputFormat 和 SinkFunction,同樣還要提醒大家這兩個 API 在 2.0 里面是被廢棄了的。在引入 Sink 之后我們也因為某些需求沒法滿足,所以推出了兩個版本:Sink V1 、Sink V2 ,在這里主要介紹 Sink V2。Sink API 本身的設計相對來講沒有那么復雜,它不涉及到主從結構或者說不涉及到協調能力,Sink 本身只是一個工廠類,是來構建整個 Sink 的拓撲或者說各個組件的。其中最核心的組件就是 SinkWriter ,因為 Sink 本身需要往外寫數據,所以不管是什么 Sink ,SinkWriter 一定是必不可少的,它的功能就是把上游的數據進行序列化,然后對應的寫出到外部系統。如果說 Sink想要實現 Exactly-once 或者說第二階段提交的能力,那在此基礎上需要提供一個可選的 SinkCommitter 的組件。它們兩個之間協調的方式就是在每個 Checkpoint 的時候,SinkWriter 會生成一個叫 Committable 的特殊的消息。
一般來講數據庫可能就是一個 Transaction,當 Checkpoint 觸發的時候會產生這樣一個 Committable,留給下面的 SinkCommitter,當所有的并發的 Checkpoint 都完成之后,我們會通過 SinkCommitter 將 Committable 提交到外部系統當中去,從而實現這樣一個第二階段提交的過程。有了這兩個組件之后我們還是發現有一些需求很難滿足,比如說像 Iceberg、Hive 這些 Sink ,它可能會涉及到 Checkpoint 之后再做一些小文件合并等額外的邏輯。為了更大程度地豐富 Sink 可以適用的場景,我們在此基礎上又提供了三個部分,分別是 PreWrite 、 PreCommit 、PostCommit。實際上就是允許 Sink 的開發者在 SinkWriter 和 Committer 之間可以插入任意的拓撲邏輯。我可以在在里面串聯很多的Operator也好或者說我可以給它們設計不同的并發,從而實現我 Sink 里面的特殊功能。但其實對于絕大多數的 Sink 來講,這些功能可能用到的機會很少,但是如果你發現我們現有的 Writer和Committer 沒有辦法滿足需求的時候,那就可以直接考慮用這三個自定義組件來實現自己的邏輯。

類似于剛剛介紹的 SourceReaderBase, 為了簡化 Sink 的開發,我們提供 Async Sink 的基類,它提供的能力是對一些通用的、異步輸出數據邏輯,通過這些場景來提供一個基本的抽象。在這里面涉及的概念比如 ElementConverter 會將我們上游的數據轉換成能夠對外部系統進行的真正的請求。Async Sink 本身會提供攢批的能力,用戶可以通過設置攢批的條件比如當數據達到一定的大小,然后攢批的時間是多少之后,然后將這一批請求的批量提交到外部系統當中去。同樣這里面也提供了內置的異常重試邏輯,如果是某次提交失敗了,那么在下一次提交的時候再一次嘗試把這些數據進行重試提交。基于這些邏輯我們可以看到實際上它只是實現了一個 at-least-once 語義的。但實際上我們生產當中,絕大部分的 Sink 都是 at-least-once ,因為實現一個 Exactly-once 的成本會很大,有一些 Sink 會覺得費了半天勁實現一個 Exactly-once 的 Sink 但是真正應用的人很少,那不如退而求其次,能夠把 at-least-once 語義做到極致就可以了。如果你的 Sink 只需要實現 at-least-once 語義,不妨嘗試 Async Sink ,能夠大大降低大家的開發難度。
介紹完下面兩層之后,我們再來說一下怎么把 Source Sink 集成至 Table / SQL API 上面去。
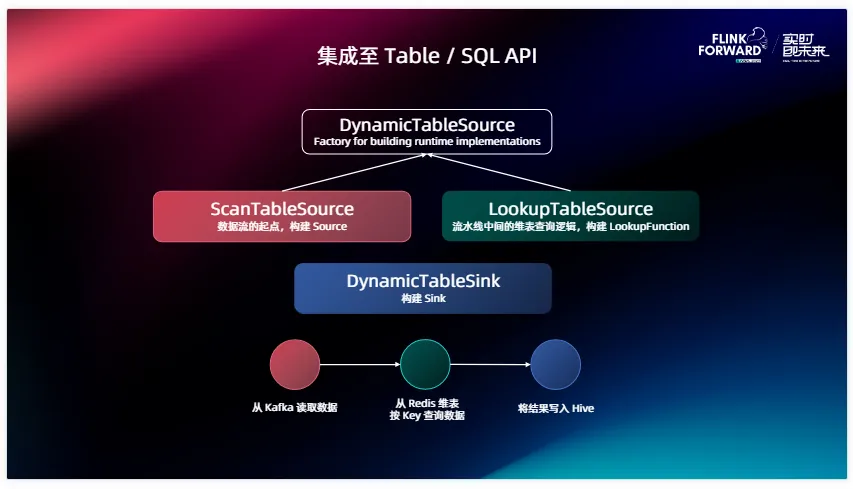
Table SQL API 對于 connector 提供的接口主要是一個層次關系, Source 最基礎的接口叫做 DynamicTableSource,它下面有兩種集成:ScanTableSource 和 LookupTableSource 。Scan 顧名思義就是對原表的掃描, Lookup 就是我們常說的對維表的典查的邏輯。這里我列了一個樣例的kafka,那 ScanTableSource 可能就是我從 Kafka 中讀取數據,再讀取完之后通過 Redis 維表提供的LookupTableSource 去 Redis 上面進行點查,最終會寫到 Sink 當中。比如說我們是 Hive ,會把這個結果通過這個 Sink 對應的接口叫做 DynamicTableSource 來寫到外部系統當中去。實際上這三個接口都是對 Source 和 Sink 或者說我們下面會介紹的 LookupFunction 的一個工廠或者說是一個構造器,那真正在下面干活的,就是我們剛剛說的 DataStream API 、Source 和 Sink 。
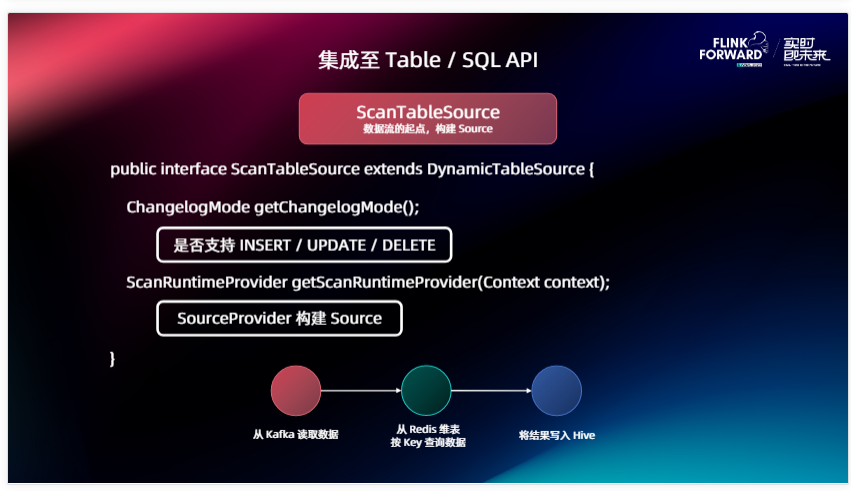
那么我們先看 ScanTableSource 的接口長什么樣。很簡單也很好理解,它有兩個方法,第一個叫 getChangelogMode,因為我們Flink Source整體是支持三種數據類型的,比如說像 INSERT / UPDATE / DELETE ,如果你的 Source 是一個三種能力都支持的 Source ,比如說我是一個滿 MySQL CDC Source ,我能夠讀取原表里的插入、更新和刪除等等,我就需要在 ChangelogMode 里面指定我是支持三個能力的。如果你是一個消息隊列的 Source ,比如說 Kafka ,那它就只支持一種 INSERT ,那這里面返回一個支持 INSERT 就可以了。這個方法會被 Planner 拿去用來對一些下游算子的校驗等等,包括你的一些邏輯,整體寫出來之后看 INSERT / UPDATE / DELETE 下游的算子能不能接受。
第二個方法就是我們怎么真正去從 Table 構建出來 Source 在底層運行的 Source API 的構造器,從 Context 里面我們是可以拿到用戶在 Source 在 CREATE TABLE 語句里面的所有配置的。我會根據這些配置,創建出對應的 Source Provider ,把最終運行在里面的 Source 構建出來。

再介紹一下 LookupTableSource ,這個剛剛說是實現了點查的邏輯,但是在 DataStream API 我們沒有提供統一的抽象的接口,就是能夠提供這樣一個典查的能力,那么在這里面我們在 Table 階段用的是叫 LookupFunction 。
它有兩個版本,一個是 LookupFunction ,一個是 AsyncLookupFunction ,分別對應的是同步的實現和異步的實現。我們在 1.16 版本里面也為維表提供了一些輔助的能力,比如說維表的 Cache 能夠快速地幫你構建出來一個 LookupFunction 這樣一些工具類,這樣大家在實現維表的時候也可以去考慮使用它。LookupTableSource 的接口比 Source 的還要簡單,它不需要提供 ChangelogMode,因為它的工作就是接一條數據然后將對應的字段到外部系統查一下就可以了。唯一提供的就是 LookupRuntimeProvider 怎么根據用戶的的配置來構建出來在 Runtime 當中使用的 LookupFunction 。
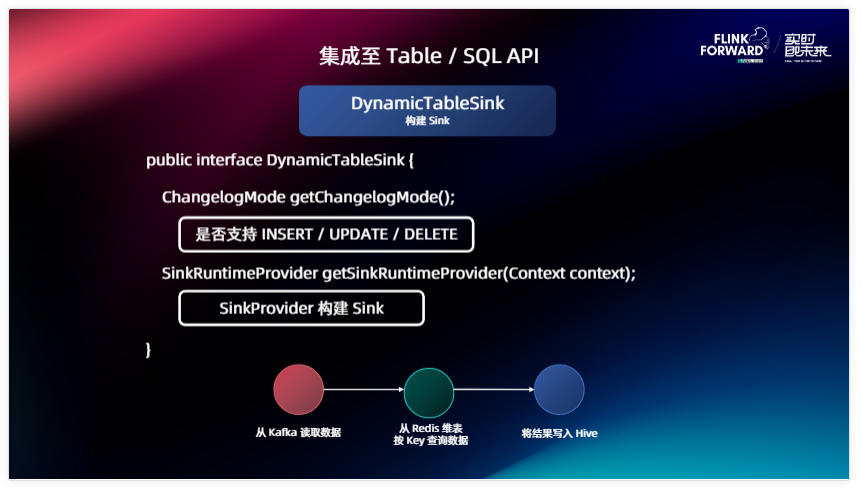
然后是 Sink ,Sink 和 Source 相似,兩個接口我是不是支持寫出 INSERT / UPDATE / DELETE ,給 Planner 做校驗,下面就是我們怎么根據用戶的配置構建出來 Sink ,這個跟 Source 基本上是完全對稱的。

除此之外我們有一些 Source 是支持高級輔助能力的,比如說我可以提供給 Planner 這個信息, Planner 可以把 Projection Pushdown 到這個 Source 里面,把 Filter Pushdown 到另一個 Source 里面,我們在這里面統一地去定義了一些接口比如說 Supports 后面是能力的名字。比如說我們有一個很厲害的 Table Source ,那它是支持 FilterPushdown 和 ProjectionPushdown 的。很簡單,我們只需要在這個類上面去實現這兩個接口就可以了,根據這些接口里面提供的方法來提供對應的信息,比如怎么把真正的 Pushdown 推到 Source 里面。大家可以在代碼里面查看這些所有支持的能力,選擇自己能夠支持的然后進行對應的實現。
在介紹完 Table 層后就是最后一部分 Catalog API 。

在這里我舉個簡單的例子,寫過 SQL 的人都知道,很頭疼的一件事就是去寫 CREATE TABLE ,我們需要給每一個字段去定義它的類型和名字,比如說我在讀取它的上游表,這個表里面定義的字段上百個,這是非常常見的情況,需要一一把它映射到 Flink 的數據類型里面,然后把它羅列在列定義里。除此之外,我們還需要為 Table 寫 With 參數,指定 Connector ,配置這個 Connector。某些 Connector 的配置非常復雜,比如說連接一個開啟了 SSL 的 Kafka 集群,可能需要寫很多的參數才可以把這個 Table 創建出來,這就是我們遇到的第一個問題:CREATE TABLE 語句太冗長了。
第二個問題是配置問題很難復用,比如說我今天為這個集群配置了這個表,寫了一堆參數,明天我還需要用這個集群,另一個表又寫了一遍參數,這個感覺就很冗余。另外還有一個問題就是剛剛提到的我要給每個字段處理它對應的類型映射,這個也很麻煩。
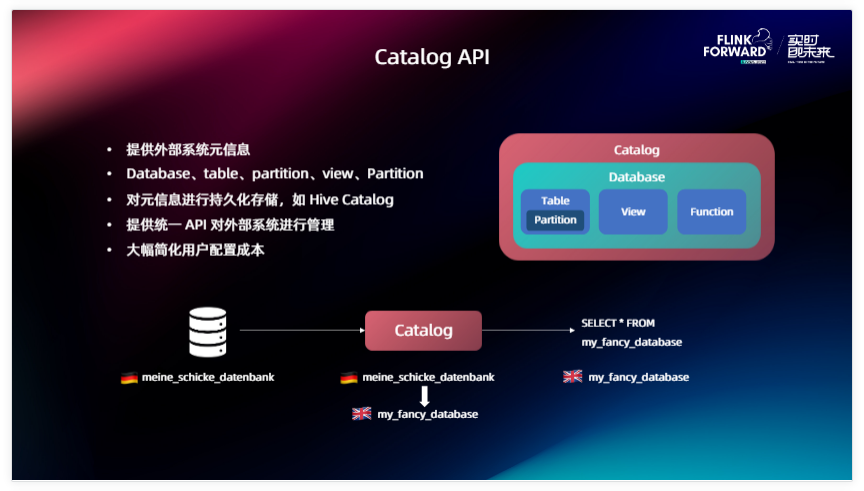
Catalog 的誕生就是為了解決這個問題。Catalog 實際上是一個能夠提供外部系統原信息的一個組件,我們在 Catalog 這個 API 里面是提供了一個統一的抽象,和 Flink、Source里面的概念相對應。比如說像 Database 、 Table 、 Partition 、 View 、Function 提供這些統一的抽象概念,我們在開發 Catalog 的時候只需要把外部系統對應的概念和它們進行一一映射就可以了。這個也不是必須的,比如說我外部系統沒有 Partition 、Function 這些的話就可以不實現它。Catalog 的其他能力還有能夠對原信息進行一個持久化的存儲,對于 Hive 的話我們可以對接到 Hive 的 Catalog 里面,把一些表的信息存儲到里面進行一個持久化,方便后面進行復用。
除此之外 Catalog 提供了一個統一的 API 能夠對外部系統進行一個統一的管理。當我們提供了 catalog 之后就可以大幅簡化用戶的配置成本。舉個例子,外部系統各種各樣,可能有各種各樣的數據庫類型,它們對自己管理數據庫的概念又不一樣,可能有的有 Schema、有的沒有 Schema,有的叫 Database 、有的叫 Namespace,經過我們統一的 Catalog API 的這層翻譯之后,能夠把它們對應的概念一一映射到 Flink 里面的概念當中,用戶在使用的時候接觸到的就只有一種概念,我們在 Flink 里面定義的這些頂層邏輯,直接通過 Catalog 里面選擇這個表就可以把這個表的數據拉出來了。
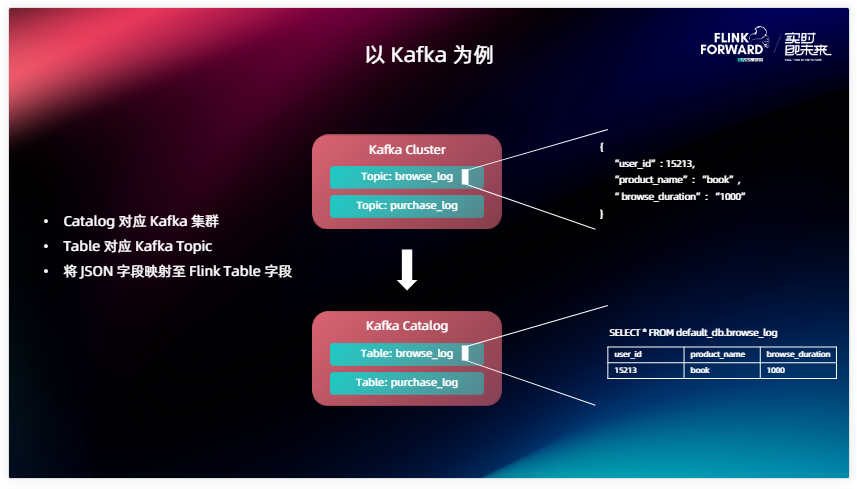
在這里舉個例子,大家可能對 MySQL 這些數據庫可能都比較好映射,它里面有 Database 、 Table 。那不典型的也不是這種結構化存儲的比如說 kafka ,它能不能支持 Catalog 呢?當然是可以的。在這里面我們把一個 Kafka Catalog 映射到一個 Kafka 集群上面,一個 Table 對 kafka 來說就是一個 Topic ,在這里面 kafka 可能沒有那么多層級的概念,可能沒有一個 Database,那我就不映射 Database,給一個默認的就可以了,在實現 Kafka Cluster 的時候可以讓用戶配置這個 Topic 里面讀取的數據類型。在這里面我舉個例子,Kafka 里面存儲的是一個 JSON 類型,那 Catalog 本身就可以對每一種字段的類型根據它 JOSN 的內容進行一個推導,把每一條數據映射到表里面的每一個行,這樣就完成了對 Kafka 統一的抽象,對終端用戶來講如果使用這個 Kafka catalog ,就沒有必要反復去配置這個 Kafka 集群的一些信息,想要哪一個 Topic 的數據,一個 SELECT 語句就可以直接拿出來,這樣能夠大大降低用戶的使用門檻。

有了 Catalog 之后,基于 Catalog 可以做一些更豐富的事情,比如血緣信息管理。在 1.18 和 1.19(還未發布)兩個版本當中 Flink 也會對血緣信息做一些支持。現在已經實現的部分 FLIP-294、Catalog Modification Listener ,也就是我們可以在 Catalog 上面注冊一個監聽器,如果 Catalog 有任何的變更,比如說加表、刪表,這些信息都會通過 Listener 匯報到對應的外部組件里面。在血緣信息管理當中,它匯報的對象就是一個 MetadataPlatform ,比如說像 Atlas、Datahub 這些原信息管理系統,相對應的如果有建表我會在原信息管理平臺上面創建對應的數據節點,刪表之后會將其進行移除。
在未來 1.19 版本里面我們預計要實現的就是這個對作業血緣的監聽,剛剛我們通過對 Katalog 的監聽是對 MetadataPlatform 的一些數據節點進行一個創建,怎么把點之間的線連接起來呢?通過 FLIP-314 之間定義的一些接口它會對作業的啟動、停止、暫停等基礎的信息進行監聽。如果一個作業啟動之后,可以通過拿到它的 Source 和 Sink 把兩個數據節點之間的線連接起來,這樣就能夠完整的獲得這個 Flink 集群上面運行的數據血緣或者說節點之間的一個上下游邏輯,方便用戶對自己的數據流向有更充分的管理。
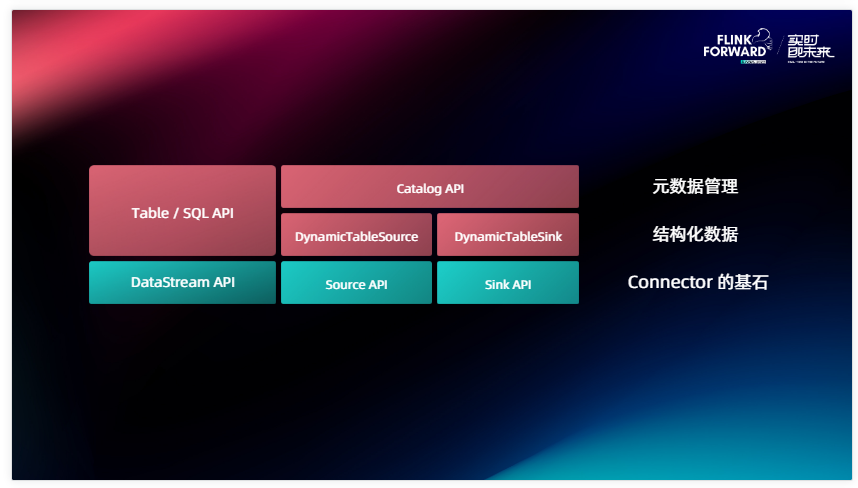
再回到這個圖,剛剛的介紹順序是由底向上的,當大家想要實現自己的 Connector 時,首先需要考慮要接觸到的一定是這個 Source 和 Sink ,它們是在 DataStream 層上面的實現,也是上面這些 API 的基石,想實現一個 Connector 一定要實現這兩個接口。如果說 Connector 想支持 SQL、還有 Table 豐富的生態,我們需要在它的基礎上實現 DynamicTableSource 和 DynamicTableSink , 它們可以理解成下面 Source 和 Sink 的構造器。如果想進一步簡化用戶使用 Connector 的成本,不要每次都寫一堆很冗長的 Table ,我們對它進行一個復用,然后就可以去對接到 Catalog API 上面,把自己外部系統的一些概念抽象到 Flink 上面去,這樣用戶可以直接從你的外部系統 Catalog 里面 Select 數據出來, 不需要反復的去定義字段、定義配置等等,能夠降低用戶的使用門檻。提供了 Catalog 之后我們就能夠天生的獲得一些血緣管理或者說原信息管理的能力。
本文章轉載微信公眾號@Apache Flink
Python + BaiduTransAPI :快速檢索千篇英文文獻(附源碼)

掌握ChatGPT API集成的方便指南
node.js + express + docker + mysql + jwt 實現用戶管理restful api
nodejs + mongodb 編寫 restful 風格博客 api
表格插件wpDataTables-將 WordPress 表與 Google Sheets API 連接
手把手教你用Python和Flask創建REST API
使用 Django 和 Django REST 框架構建 RESTful API:實現 CRUD 操作
ASP.NET Web API快速入門介紹

2024年在線市場平臺的11大最佳支付解決方案