GraphRAG:基于PolarDB+通義千問api+LangChain的知識圖譜定制實踐
如上圖所示,一個完整的推薦系統包含召回、排序(粗排、精排、重排、端排序)、業務過濾層等幾個重要的邏輯分層。這多年雖然很多論文層出不窮,但是主要框架沒有發生很大的變化,圍繞這個架構的各個層進行深入優化,通過分階段的貪心的方式來優化算法的效果,來提升整體的業務指標,算法“卷”起來。
對于現在的整個推薦系統而言,雖然看似是一個智能化的推薦系統,但是本質還是在通過過擬合用戶在場景內的行為來進行各種預測。過擬合是個毒藥,效果好,但是會出現各種各樣的問題(冷啟動用戶、買了還推、內容單一),于是也出現了很多算法來解決這一類問題的,怎么提高推薦系統的多樣性?怎么了提高推薦系統的驚喜性。所以說舊時代的推薦系統,還是不是一個真正意義上的智能的推薦系統,依靠過擬合用戶行為來學習用戶興趣,并沒有真正的了解用戶的心智變化。
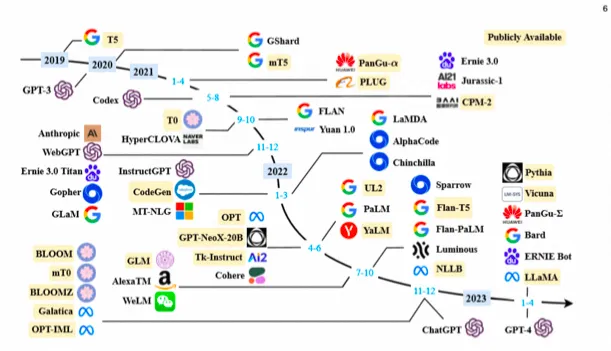
一般認為NLP領域的大模型>=10 Billion參數(也有人認為是6B、7B, 工業界用, 開始展現涌現能力);經典大模型有GPT-3、BLOOM、Flan-T5、GPT-NeoX、OPT、GLM-130B、PaLM、LaMDA、LLaMA等;
那么LLM為什么會被這么關注呢?大模型有哪些能力嗎?
涌現
涌現, Emerge(abilities), 即一般指在大模型中出現而小模型沒有的能力。所謂“涌現”,在大模型領域指的是當模型突破某個規模時,性能顯著提升,表現出讓人驚艷、意想不到的能力。比如語言理解能力、生成能力、邏輯推理能力等。一般來說,模型在100億到1000億參數區間,可能產生能力涌現。關于涌現能力的更加詳細的介紹可以讀一下《大語言模型的涌現能力:現象和解釋》。
上下文學習(ICL)是指不需要微調,只需要少數幾個樣例作為示例,就能在未知任務上取得不錯的效果(提升few-shot能力)。
ICL主要思路是,給出少量的標注樣本,設計任務相關的指令形成提示模板,用于指導待測試樣本生成相應的結果。?
ICL的過程,并不涉及到梯度的更新,因為整個過程不屬于fine-tuning范疇。而是將一些帶有標簽的樣本拼接起來,作為prompt的一部分,引導模型在新的測試數據輸入上生成預測結果。
COT能力,也是一種奇妙的能力,大模型涌現出來的COT能力,讓模型可以解決復雜問題,而且具有了可解釋性。
ICL方法的表現大幅度超越了Zero-Shot-Learning,為少樣本學習提供了新的研究思路。因為ICL離不開與Prompt的結合,感興趣的可以去讀一下《A Survey on In-context Learning》和《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》這兩個綜述。
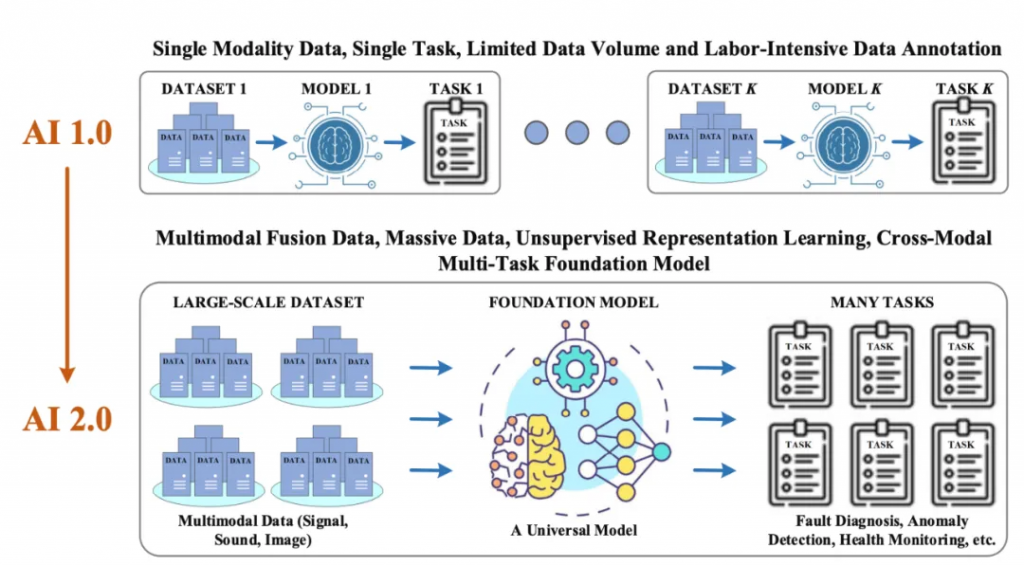
LLM有很多特性可以被用來對推薦系統來進行改進。
總的來說,已經嘗試的工作可以分為下面的三大類,當然有很多的劃分方式:
1、LLM Embeddings + RS
這種建模范式將語言模型視為特征提取器,將物品和用戶的特征饋送到LLMs中,并輸出相應的嵌入。傳統的推薦系統模型可以利用知識感知嵌入來完成各種推薦任務。
2、LLM Tokens + RS
這種方法基于輸入的物品和用戶特征生成token。通過語義挖掘,生成的token可以捕捉潛在的偏好,這些偏好可以融入到推薦系統的決策過程中。
3、LLM AS RS
這種方式直接把LLM作為一個RS系統,不過這種對LLM精準性要求比較高。
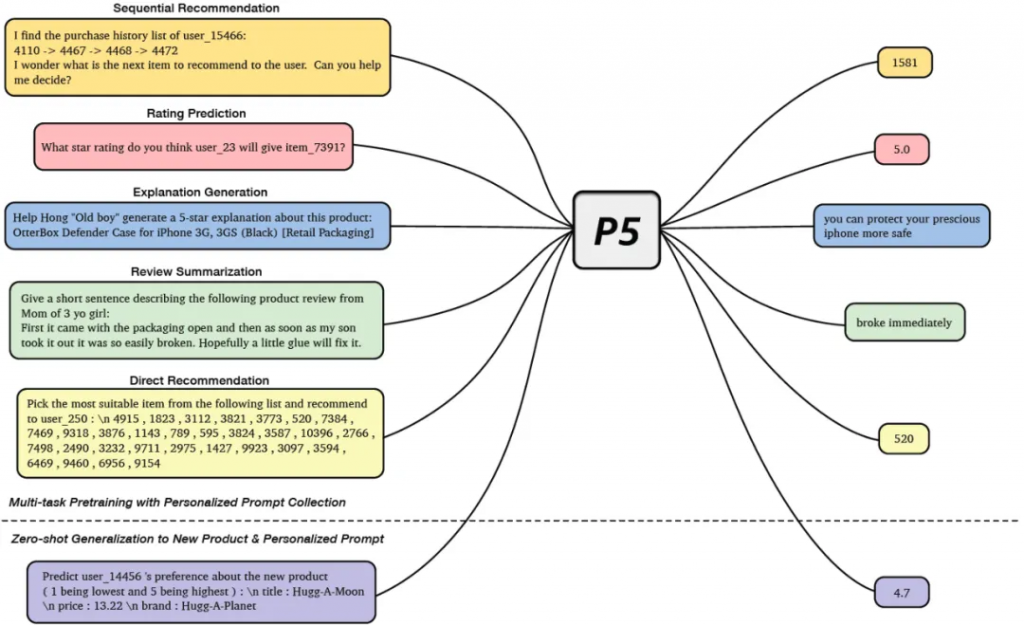
Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)
在這個論文中作者提出了一個統一的架構來利用大模型來進行推薦。文章提出來對目前主流的推薦場景(序列推薦、評分預測、可解釋性推薦、評論總結等)多個任務都進行了統一,構造了一個模型P5。在預訓練階段,采用統一的一個模型結構,設計不同的prompt模版來進行個性化的推理,所有的任務做到很大程度的統一。預訓練模型用了T5模型。通過自己場景的數據Pretraining之后,在各個數據集上的表現都還是不錯的,不過在各個數據集合上的表現是不一樣的。但是這個論文感覺還是蠻不錯的,可以做到各個任務的統一,而且最終效果還是可圈可點的。這個論文值得精讀一下。
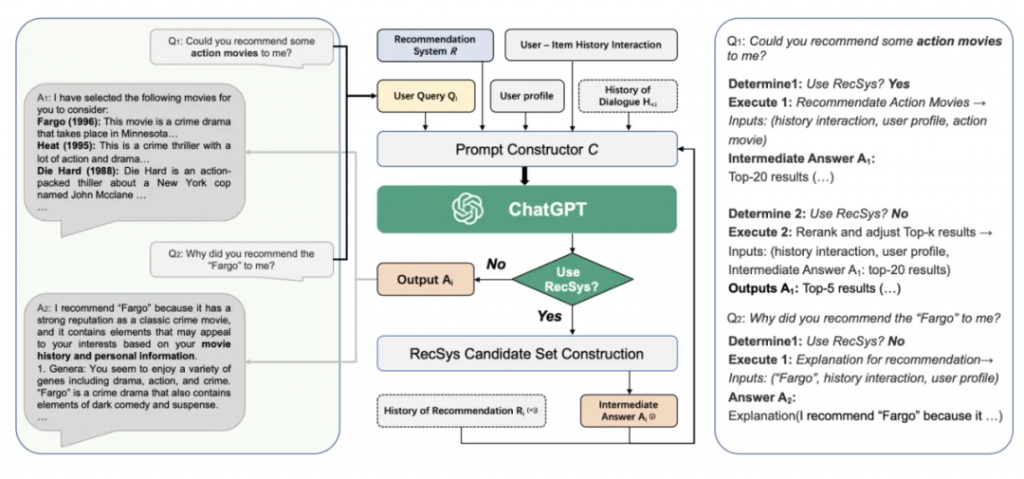
Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
本文中提出了一種用 LLMs 增強傳統推薦的范式 ,通過將用戶畫像和歷史交互轉換為 Prompt,Chat-Rec 可以有效地學習用戶的偏好,它不需要訓練,而是完全依賴于上下文學習,并可以有效推理出用戶和產品之間之間的聯系。通過 LLM 的增強,在每次對話后都可以迭代用戶偏好,更新候選推薦結果。和基于檢索增強的QA一樣,LLM與傳統搜推系統結合,為了保證結果更加可靠,還需要增強一下。論文圖如下,流程還是蠻清晰的。給推薦系統怎么使用LLM指明了一條路。
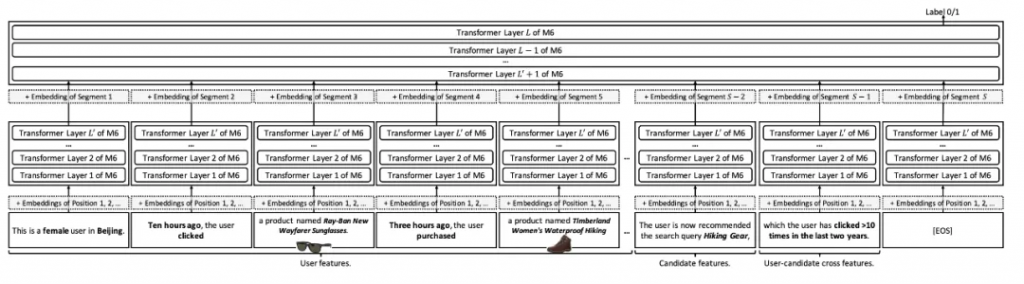
M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems
整個推薦的思路是基于達摩院的M6的模型上進行的探索,并將推薦系統中的任務轉換成了語言模型可以處理的語言理解或語言生成任務,主要貢獻有這么幾條:
1、作者提出了一種統一的推薦框架思路,這個框架是基于M6之上的,不僅可以做開放域的推薦,還可以針對下游任務進行簡單的微調就可以用
2、為了減小推薦系統的推理延遲,本文在late interaction的基礎上提出了multi-segment late interaction. 簡單來說就是把transform的前幾層的結果先緩存起來。
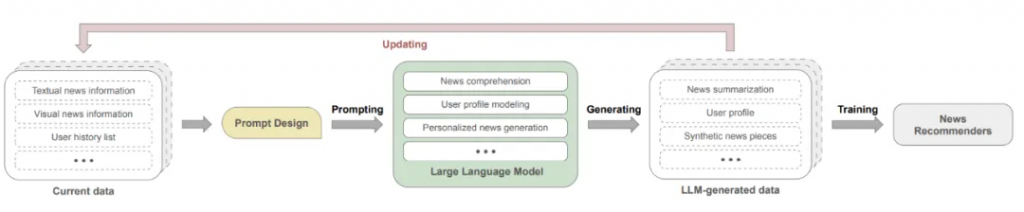
A First Look at LLM-Powered Generative News Recommendation
對于傳統的新聞推薦,往往有如下的幾個問題:
1. 冷啟動。對于長尾或新用戶,模型無法較好的建模和理解他們的興趣。冷啟動是推薦系統經常遇到的問題
2. 用戶畫像建模。出于隱私保護的考量,現有的數據集可能無法包含詳細的用戶畫像信息。另外用戶的興趣往往是多樣的,怎么能比較精準的客戶還是蠻有挑戰性的。
3. 新聞內容理解。由于新聞數據中標題和內容存在不一致的問題,導致難以識別新聞中的關鍵概念和主題。而且新聞一般內容都會比較多。
本文提出來GENRE框架,這個框架可以提供一種靈活的,可以配置的,能快速把LLM的相關的能力引入進來來進行相關的推薦。
Is ChatGPT a Good Recommender? A Preliminary Study
這個文章是阿里內部自己寫的一個文章,文章主要講是設計了一系列的prompt并評估了 ChatGPT 在五種推薦場景的性能。在這個文章里面,并沒有對LLM來進行微調,只是依靠prompt來進行全流程設計。
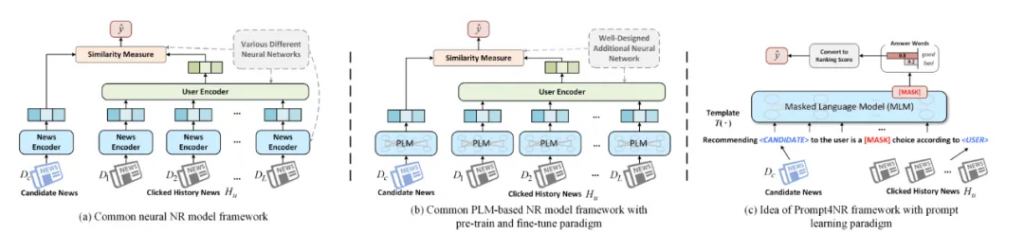
Prompt Learning for News Recommendation
代碼:https://github.com/resistzzz/prompt4nr?
采用了一種稱為prompt learning的預訓練、提示和預測范式。在這個框架中,任務被轉化成一個填空式掩碼預測任務,通過設計個性化的提示模板和相應的答案空間,以充分利用預訓練過程中嵌入的豐富語義信息和語言知識。這種方式通過prompt learning的方式在預測的時候可以保證很好的性能,應用價值比較高。
Zero-Shot Next-Item Recommendation using Large Pretrained Language Models
代碼:https://github.com/AGI-Edgerunners/LLM-Next-Item-Rec?
在這個論文里面作者提出了一種新的prompt策略來進行商品推薦,主要可以理解分為下面幾個步驟:
1、候選生成
類似搜索檢索增強一樣,把推薦系統的召回部分保持不動,交給傳統的(協同過濾或者其他向量)等方式來進行
2、Prompt策略
本文提出了多個環節設計Prompt:用戶偏好理解Prompt、候選商品二次選擇Prompt、最終推薦結果生成Prompt。用戶偏好理解Prompt主要是對用戶的行為進行理解。候選商品二次選擇Prompt主要是根據用戶偏好和候選商品,設計Prompt來選擇對候選商品來排序。最終的推薦結果是在第二個基礎上來對最終的結果進行選擇組合。
3、結果抽取
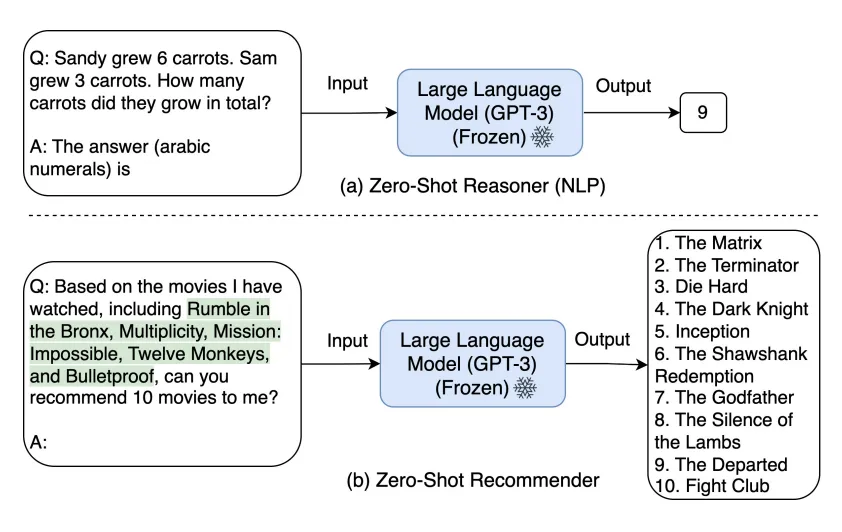
Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach
這個論文主要思想是,用戶的偏好或需求可以用自然語言描述(稱為指令),以便LLMs能夠理解并進一步執行指令以滿足推薦任務。主要是提出推薦系統的指令調優方法,名為InstructRec。該方法允許用戶在與推薦系統交互時,用自然語言指令自由表達他們的信息需求。考慮與用戶需求表達相關的三個關鍵方面,即偏好、意圖和任務形式來設計指令。本文采用3B Flan-T5-XL作為骨干型號。由于Flan-T5基于T5進行了微調。
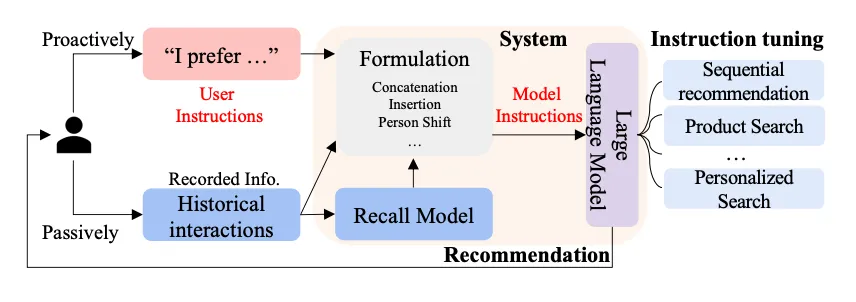
Language Models as Recommender Systems:Evaluations and Limitations
Uncovering ChatGPT’s Capabilities in Recommender Systems
代碼數據:https://github.com/rainym00d/LLM4RS?
這篇論文從IR的角度,分別從point-wise, pair-wise, 和 list-wise ranking三個方面來對chatgpt在recommendation的角度來進行了能力分析。作者并沒有對模型進行finetune,只是設計了很多domain-specific的prompt工程,并得到下面的幾個不錯的結論:1、chatgpt相對于其他LLM模型,在三個ranking的方式上效果都是很明顯;這本質還是由模型自己的精度來保證的;2、綜合性價比額,作者任務chatgpt在list-wise ranking 方面效果更好;
3、chatgpt在冷啟動場景效果會更加顯著一點(主要偷取外部知識);
A Survey on Large Language Models for Recommendation
這個綜述是組內中科大的AIR實習生的一個組的老師發的,王老師把最近的一些關于LLM相關的推薦論文進行了詳細的了解和梳理。
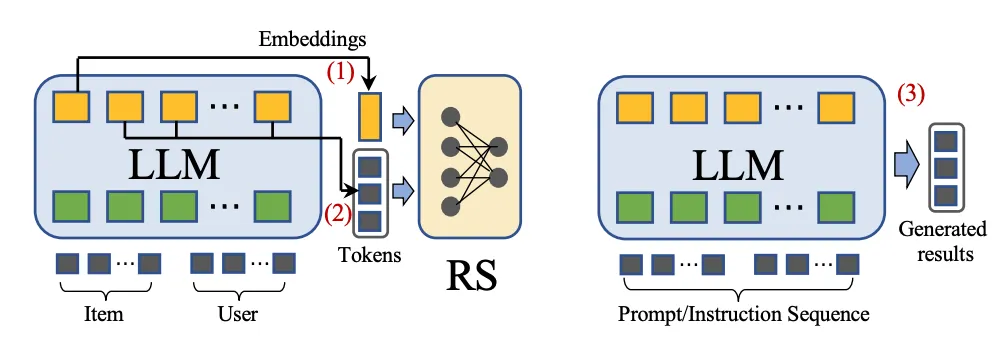
剛好我們在通過對相關的推薦場景快速的進行個性化升級之后,在新聞類的文章領域SOTA相關的論文有很多,在最近嘗試了基于LLM相關的推薦改造,目前從離線來看效果還是蠻不錯的。
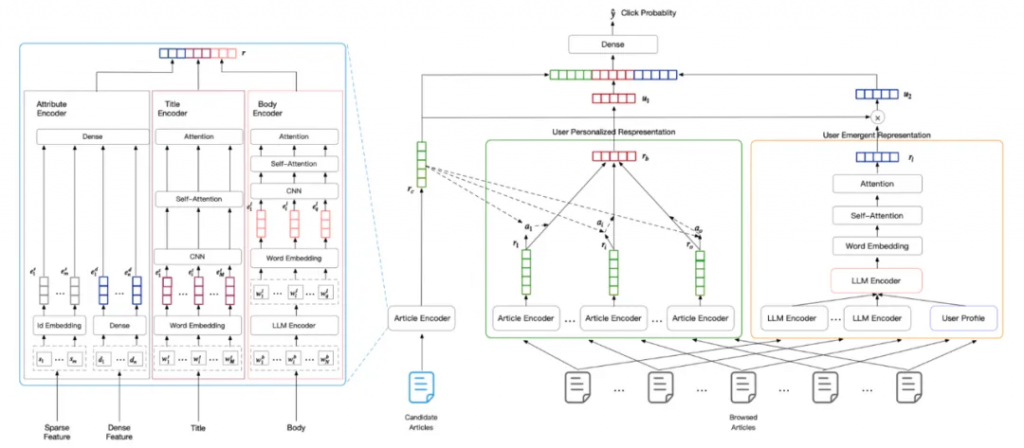
幾個改進點:
1、利用大模型的總結和推理能力來對長文檔進行總結,因為本身長文檔就是有很強的邏輯性的,普通的向量建模方式只能一定程度表征語義,如果用bert等傳統的來說還有字數限制,對文章的內容進行高精準的提取(文章的表征放到離線),對于文章來說可以采用下面三種方式來進行總結。
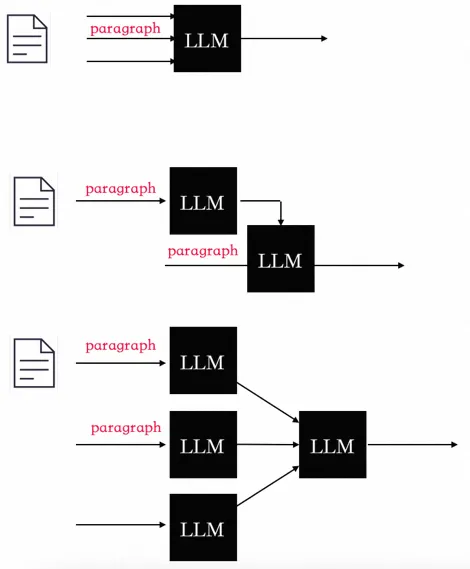
2、利用大模型的推理能力來對用戶上線文來進行離線的推理,對用戶行為進行建模,從用戶繁雜的行為中找到背后的邏輯(用戶的理解也放到離線),用戶歷史瀏覽的文章都會首先被LLM表征,然后利用LLM的COT能力來對上線文進行總結和表征。
3、這里需要涉及兩個Prompt,一個Prompt是對長文檔進行summarize,另外一個Prompt是對用戶瀏覽歷史做summarize。?
目前效果:
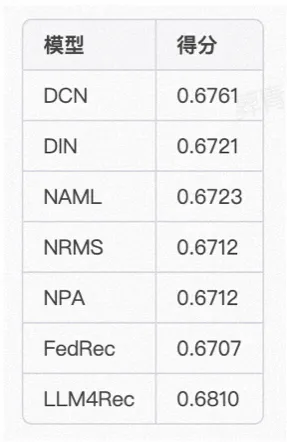
我們的場景式技術類文章的推薦場景(類似知乎、簡書、CSDN等),這些場景的特點是技術文章邏輯性很強、文章通常很長。新文章也比較多,文章需要經過很長時間之后才能出來比較熱的文章。我們在約1000W的樣本量,30W+的候選長文檔,模型可以選擇(chatglm6b/chatm6等)是做的實驗,實驗效果如下:(其中NAML/NRMS/NPA/FedRec都是新聞領域SOTA的推薦排序模型)
一些消融實驗的效果:

從上面的實驗可以初步得到一個結論,LLM對于文檔類推薦效果還是比較顯著,不論是用來做商品理解還是用戶上下文理解。
不管你是主動接受還是被動接受,LLM相關的從底層硬件到上層應用已經全面開花。
大模型是目前推薦系統領域的熱門話題之一,其將信息檢索、自然語言處理和深度學習技術相結合,能夠捕捉更多的用戶興趣和行為,提高推薦的準確性和效果。
未來,大模型在推薦系統中的應用將會越來越廣泛。一方面,隨著數據量的不斷增長,大模型能夠更好地處理這些數據,并從中發掘更深層次的用戶興趣和行為;另一方面,隨著模型算法的不斷升級,大模型將不斷提高推薦的效果,并能夠更好地應對多樣化的推薦需求。
此外,大模型還有很多未被發掘的潛力。例如,將大模型應用于社交網絡中的推薦、個性化廣告推薦、音視頻推薦等領域,都有很大的發展空間。
總之,大模型是未來推薦系統發展的一個趨勢。同時大模型也給我們提供了一個統一的方式未來。
[1]Zero-Shot Next-Item Recommendation using Large Pretrained Language Models:https://arxiv.org/pdf/2304.03153.pdf
[2]Is ChatGPT a Good Recommender? A Preliminary Study:https://arxiv.org/pdf/2304.10149.pdf
[3]Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System:https://arxiv.org/pdf/2303.14524.pdf
[4]A First Look at LLM-Powered Generative News Recommendation:https://arxiv.org/pdf/2305.06566.pdf
[5]Language Models as Recommender Systems: Evaluations and Limitations:https://openreview.net/pdf?id=hFx3fY7-m9b
[6]Prompt Learning for News Recommendation:https://arxiv.org/pdf/2304.05263.pdf
[7]Generating Personalized Recommendations via Large Language Models (LLMs):https://www.tdcommons.org/cgi/viewcontent.cgi?article=6685&context=dpubs_series
[8]Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5):https://arxiv.org/pdf/2203.13366.pdf
[9]Uncovering ChatGPT’s Capabilities in Recommender Systems:https://arxiv.org/pdf/2305.02182.pdf
[10]Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach::https://arxiv.org/pdf/2305.07001.pdf
[11]A Survey on Large Language Models for Recommendation:https://arxiv.org/pdf/2305.19860.pdf
[12]M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems
[13]PBNR: Prompt-based News Recommender System:https://arxiv.org/pdf/2304.07862.pdf
[14]LLM4Rec相關的論文:https://github.com/nancheng58/Awesome-LLM4RS-Papers
[15]Rethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models:https://arxiv.org/pdf/2305.13112.pdf
[16]Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction:https://arxiv.org/abs/2305.06474
[17]TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation
[18]推薦策略產品經理必讀系列—第二講推薦系統的架構:https://www.woshipm.com/pmd/5541932.html
[19]《大語言模型的涌現能力:現象和解釋》:https://zhuanlan.zhihu.com/p/621438653
文章轉自微信公眾號@阿里云開發者