
使用Node.js、Express和MySQL構(gòu)建REST API
而好的 API 讓維護(hù)者和使用者能夠很容易理解到設(shè)計時要傳達(dá)的模型。帶來理解、調(diào)試、測試、代碼擴(kuò)展和系統(tǒng)維護(hù)性的提升 。
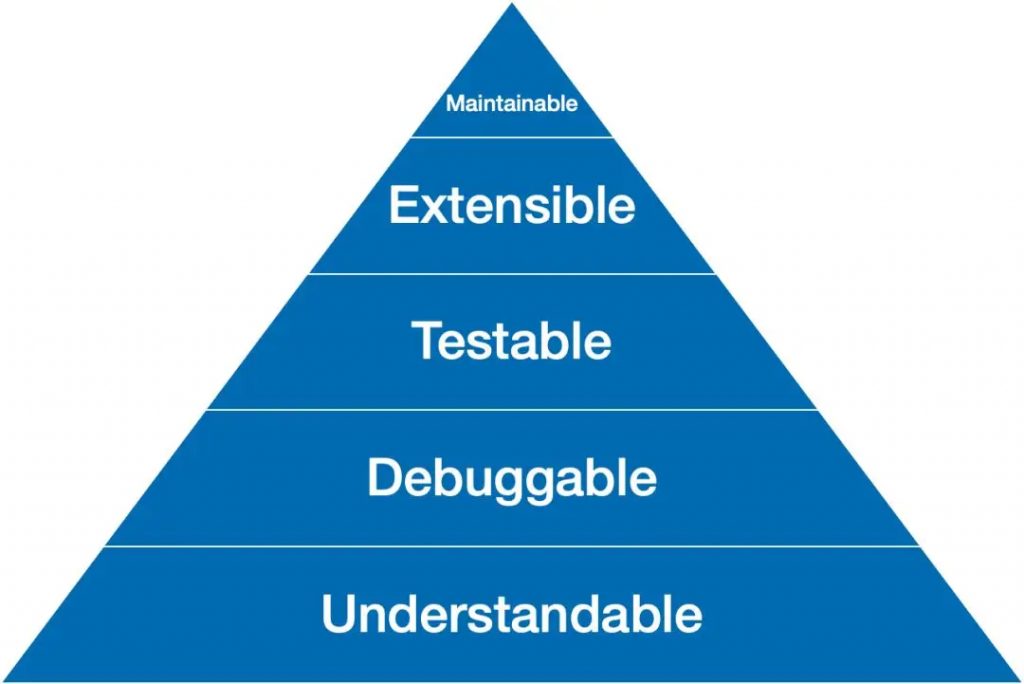
“Make things as simple as possible, but no simpler.” 在實(shí)際的系統(tǒng)中,尤其是考慮到系統(tǒng)隨著需求的增加不斷地演化,我們絕大多數(shù)情況下見到的問題都是過于復(fù)雜的設(shè)計,在 API 中引入了過多的實(shí)現(xiàn)細(xì)節(jié)(見下一條),同時也有不少的例子是Oversimplification 引起的,一些不該被合并的改變合并了,導(dǎo)致設(shè)計很不合理。
過于簡單化的例子:過去曾經(jīng)見過一個系統(tǒng),將一個用戶的資源賬戶模型的 account balance 和 transactions 都簡化為用 transactions 一個模型來表達(dá),邏輯在于 account balance 可以由歷史的 transactions 累計得到。但是這樣的過于簡化的模型設(shè)計帶來了很多的問題,尤其在引入分期付款、預(yù)約交易等概念之后,暴露了很多復(fù)雜的邏輯給一些只需要獲取簡單信息的客戶端(如計算這個用戶是否還有足夠的余額交易變得和很多業(yè)務(wù)邏輯耦合),屬于典型的模型過度簡化帶來的設(shè)計復(fù)雜度上升的案例。
這個原則看上去更具體,也是我非常喜歡的一個原則。Sanjay Ghemawat 常常提到該原則。一般來說,在討論 API 設(shè)計時常常被提到的原則是解耦性原則或者說松耦合原則。然而相比于松耦合原則,這個原則更加有可核實(shí)性:如果一個 API 自身可以有多個完全不同的實(shí)現(xiàn),一般來說這個API已經(jīng)有了足夠好的抽象,那么一般也不會出現(xiàn)和外部系統(tǒng)耦合過緊的問題。因此這個原則更本質(zhì)一些。
舉個例子,比如我們已經(jīng)有一個簡單的 API
QueryOrderResponse queryOrder(string orderQuery)
但是有場景需求希望總是讀取到最新更新數(shù)據(jù),不接受緩存,于是工程師考慮。
QueryOrderResponse queryOrder(string orderQuery, boolean useCache)
增加一個字段 useCache 來判斷如何處理這樣的請求。
這樣的改法看上去合理,但實(shí)際上泄漏了后端實(shí)現(xiàn)的細(xì)節(jié)(后端采用了緩存),后續(xù)如果采用一個新的不帶緩存的后端存儲實(shí)現(xiàn),再支持這個 useCache 的字段就很尷尬了。
在工程中,這樣的問題可以用不同的服務(wù)實(shí)例來解決,通過不同訪問的 endpoint 配置來區(qū)分。
本部分則試圖討論一些更加詳細(xì)、具體的建議,可以讓 API 的設(shè)計更容易滿足前面描述的基礎(chǔ)原則。
想想優(yōu)秀的API例子:POSIX File API
如果說 API 的設(shè)計實(shí)踐只能列一條的話,那么可能最有幫助的和最可操作的就是這一條。本文也可以叫做“通過 File API 體會 API 設(shè)計的最佳實(shí)踐”。
所以整個最佳實(shí)踐可以總結(jié)為一句話:“想想 File API 是怎么設(shè)計的。”
首先回顧一下 File API 的主要接口(以C為例,很多是 Posix API,選用比較簡單的I/O接口為例【1】:
int open(const char *path, int oflag, .../*,mode_t mode */);
int close (int filedes);
int remove( const char *fname );
ssize_t write(int fildes, const void *buf, size_t nbyte);
ssize_t read(int fildes, void *buf, size_t nbyte);例如同樣是打開文件的接口,底層實(shí)現(xiàn)完全不同,但是通過完全一樣的接口,不同的路徑以及 Mount 機(jī)制,實(shí)現(xiàn)了同時支持。其他還有 Procfs, pipe 等。
int open(const char *path, int oflag, .../*,mode_t mode */);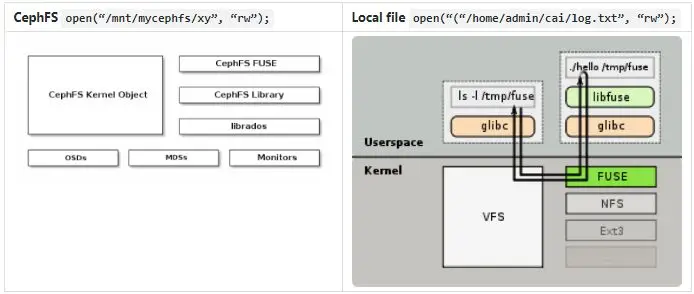
上圖中,cephfs 和本地文件系統(tǒng),底層對應(yīng)完全不同的實(shí)現(xiàn),但是上層 client 可以不用區(qū)分對待,采用同樣的接口來操作,只通過路徑不同來區(qū)分。
基于上面的這些原因,我們知道 File API 為什么能夠如此成功。事實(shí)上,它是如此的成功以至于今天的 *-nix 操作系統(tǒng),everything is filed based.
盡管我們有了一個非常好的例子 File API,但是要設(shè)計一個能夠長期保持穩(wěn)定的 API是一項(xiàng)及其困難的事情,因此僅有一個好的參考還不夠,下面再試圖展開去討論一些更細(xì)節(jié)的問題。
寫詳細(xì)的文檔,并保持更新。 關(guān)于這一點(diǎn),其實(shí)無需贅述,現(xiàn)實(shí)是,很多API的設(shè)計和維護(hù)者不重視文檔的工作。
在一個面向服務(wù)化/Micro-service 化架構(gòu)的今天,一個應(yīng)用依賴大量的服務(wù),而每個服務(wù) API 又在不斷的演進(jìn)過程中,準(zhǔn)確的記錄每個字段和每個方法,并且保持更新,對于減少客戶端的開發(fā)踩坑、減少出問題的幾率,提升整體的研發(fā)效率至關(guān)重要。
如果適合的話,選用“資源”加操作的方式來定義。今天很多的 API 都可以采用這樣一個抽象的模式來定義,這種模式有很多好處,也適合于 HTTP 的 RESTful API 的設(shè)計。但是在設(shè)計 API 時,一個重要的前提是對 Resource 本身進(jìn)行合理的定義。什么樣的定義是合理的? Resource 資源本身是對一套 API 操作核心對象的一個抽象Abstraction。
抽象的過程是去除細(xì)節(jié)的過程。在我們做設(shè)計時,如果現(xiàn)實(shí)世界的流程或者操作對象是具體化的,抽象的 Object 的選擇可能不那么困難,但是對于哪些細(xì)節(jié)應(yīng)該包括,是需要很多思考的。例如對于文件的API,可以看出,文件 File 這個 Resource(資源)的抽象,是“可以由一個字符串唯一標(biāo)識的數(shù)據(jù)記錄”。這個定義去除了文件是如何標(biāo)識的(這個問題留給了各個文件系統(tǒng)的具體實(shí)現(xiàn)),也去除了關(guān)于如何存儲的組織結(jié)構(gòu)(again,留給了存儲系統(tǒng))細(xì)節(jié)。
雖然我們希望API簡單,但是更重要的是選擇對的實(shí)體來建模。在底層系統(tǒng)設(shè)計中,我們傾向于更簡單的抽象設(shè)計。有的系統(tǒng)里面,域模型本身的設(shè)計往往不會這么簡單,需要更細(xì)致的考慮如何定義 Resource。一般來說,域模型中的概念抽象,如果能和現(xiàn)實(shí)中的人們的體驗(yàn)接近,會有利于人們理解該模型。選擇對的實(shí)體來建模往往是關(guān)鍵。結(jié)合域模型的設(shè)計,可以參考相關(guān)的文章,例如阿白老師的文章【2】。
與前面的一個問題密切相關(guān)的,是在定義對象時需要選擇合適的 Level of abstraction (抽象的層級)。不同概念之間往往相互關(guān)聯(lián)。仍然以 File API 為例。在設(shè)計這樣的 API 時,選擇抽象的層級的可能的選項(xiàng)有多個,例如:
這些不同的層級的抽象方式,可能描述的是同一個東西,但是在概念上是不同層面的選擇。當(dāng)設(shè)計一個 API 用于與數(shù)據(jù)訪問的客戶端交互時,“文件 File “是更合適的抽象,而設(shè)計一個 API 用于文件系統(tǒng)內(nèi)部或者設(shè)備驅(qū)動時,數(shù)據(jù)塊或者數(shù)據(jù)塊設(shè)備可能是合適的抽象,當(dāng)設(shè)計一個文檔編輯工具時,可能會用到“文本圖像混合對象”這樣的文件抽象層級。
又例如,數(shù)據(jù)庫相關(guān)的 API 定義,底層的抽象可能針對的是數(shù)據(jù)的存儲結(jié)構(gòu),中間是數(shù)據(jù)庫邏輯層需要定義數(shù)據(jù)交互的各種對象和協(xié)議,而在展示(View layer)的時候需要的抽象又有不同【3】。
當(dāng) API 定義了一個資源對象,下面一般需要的是提供命名/標(biāo)識( Naming and identification )。在 naming/ID 方面,一般有兩個選擇(不是指系統(tǒng)內(nèi)部的 ID,而是會暴露給用戶的):
何時選擇哪個方法,需要具體分析。采用 Free-form string 的方式定義的命名,為系統(tǒng)的具體實(shí)現(xiàn)留下了最大的自由度。帶來的問題是命名的內(nèi)在結(jié)構(gòu)(如路徑)本身并非API強(qiáng)制定義的一部分,轉(zhuǎn)為變成實(shí)現(xiàn)細(xì)節(jié)。如果命名本身存在結(jié)構(gòu),客戶端需要有提取結(jié)構(gòu)信息的邏輯,這是一個需要做的平衡。
例如文件 API 采用了 free-form string 作為文件名的標(biāo)識方式,而文件的 URL 則是文件系統(tǒng)具體實(shí)現(xiàn)規(guī)定。這樣,就容許 Windows 操作系統(tǒng)采用 “D:\Documents\File.jpg” 而 Linux 采用 “/etc/init.d/file.conf” 這樣的結(jié)構(gòu)了。而如果文件命名的數(shù)據(jù)結(jié)構(gòu)定義為:
{
disk: string,
path: string
}這樣結(jié)構(gòu)化的方式,透出了 “disk” 和 “path” 兩個部分的結(jié)構(gòu)化數(shù)據(jù),那么這樣的結(jié)構(gòu)可能適應(yīng)于 Windows 的文件組織方式,而不適應(yīng)于其他文件系統(tǒng),也就是說泄漏了實(shí)現(xiàn)細(xì)節(jié)。
如果資源 Resource 對象的抽象模型自然包含結(jié)構(gòu)化的標(biāo)識信息,則采用結(jié)構(gòu)化方式會簡化客戶端與之交互的邏輯,強(qiáng)化概念模型。這時犧牲掉標(biāo)識的靈活度,換取其他方面的優(yōu)勢。例如,銀行的轉(zhuǎn)賬賬號設(shè)計,可以表達(dá)為:
{
account: number
routing: number
}這樣一個結(jié)構(gòu)化標(biāo)識,由賬號和銀行間標(biāo)識兩部分組成,這樣的設(shè)計含有一定的業(yè)務(wù)邏輯在內(nèi),但是這部分業(yè)務(wù)邏輯是被描述的系統(tǒng)內(nèi)在邏輯而非實(shí)現(xiàn)細(xì)節(jié),并且這樣的設(shè)計可能有助于具體實(shí)現(xiàn)的簡化以及避免一些非結(jié)構(gòu)化的字符串標(biāo)識帶來的安全性問題等。因此在這里結(jié)構(gòu)化的標(biāo)識可能更適合。
另一個相關(guān)的問題是,何時應(yīng)該提供一個數(shù)字 unique ID ? 這是一個經(jīng)常遇到的問題。有幾個問題與之相關(guān)需要考慮:
如果這些問題都有答案而且不是什么阻礙,那么使用數(shù)字 ID 是可以的,否則要慎用數(shù)字ID。
Conceptually what are the meaningful operations on this resource? 對于該對象來說,什么操作概念上是合理的?
在確定下來了資源/對象以后,我們還需要定義哪些操作需要支持。這時,考慮的重點(diǎn)是“ 概念上合理(Conceptually reasonable)”。換句話說,operation + resource 連在一起聽起來自然而然合理(如果 Resource 本身命名也比較準(zhǔn)確的話。當(dāng)然這個“如果命名準(zhǔn)確”是個 big if,非常不容易做到)。操作并不總是CRUD(create, read, update, delete)。
例如,一個 API 的操作對象是額度(Quota ),那么下面的操作聽上去就比較自然:
但是如果試圖 Create Quota,聽上去就不那么自然,因額度這樣一個概念似乎表達(dá)了一個數(shù)量,概念上不需要創(chuàng)建。額外需要思考一下,這個對象是否真的需要創(chuàng)建?我們真正需要做的是什么?
For update operations, prefer idempotency whenever feasible 更新操作,盡量保持冪等性
Idempotency 冪等性,指的是一種操作具備的性質(zhì),具有這種性質(zhì)的操作可以被多次實(shí)施并且不會影響到初次實(shí)施的結(jié)果“the property of certain operations in mathematics and computer science whereby they can be applied multiple times without changing the result beyond the initial application.”【3】
很明顯 Idempotency 在系統(tǒng)設(shè)計中會帶來很多便利性,例如客戶端可以更安全地重試,從而讓復(fù)雜的流程實(shí)現(xiàn)更為簡單。但是 Idempotency 實(shí)現(xiàn)并不總是很容易。
IncrementBy 這樣的語義重試的時候難以避免出錯,而 SetNewTotal(3)(總量設(shè)置為x)語義則比較容易具備冪等性。
當(dāng)然在這個例子里面,也需要看到,IncrementBy 也有優(yōu)點(diǎn),即多個客戶請求同時增加的時候,比較容易并行處理,而 SetTotal 可能導(dǎo)致并行的更新相互覆蓋(或者相互阻塞)。
這里,可以認(rèn)為 更新增量和_設(shè)置新的總量_這兩種語義是不同的優(yōu)缺點(diǎn),需要根據(jù)場景來解決。如果必須優(yōu)先考慮并發(fā)更新的情景,可以使用_更新增量_的語義,并輔助以 Deduplication token 解決冪等性。
API的變更需要兼容,兼容,兼容!重要的事情說三遍。這里的兼容指的是向后兼容,而兼容的定義是不會 Break 客戶端的使用,也即老的客戶端能否正常訪問服務(wù)端的新版本(如果是同一個大版本下)不會有錯誤的行為。這一點(diǎn)對于遠(yuǎn)程的API(HTTP/RPC)尤其重要。關(guān)于兼容性,已經(jīng)有很好的總結(jié),例如【4】提供的一些建議。
常見的不兼容變化包括(但不限于):
另一個關(guān)于兼容性的重要問題是,如何做不兼容的API變更?通常來說,不兼容變更需要通過一個 Deprecation process,在大版本發(fā)布時來分步驟實(shí)現(xiàn)。關(guān)于Deprecation process,這里不展開描述,一般來說,需要保持過去版本的兼容性的前提下,支持新老字段/方法/語義,并給客戶端足夠的升級時間。這樣的過程比較耗時,也正是因?yàn)槿绱耍覀儾判枰绱酥匾旳PI的設(shè)計。
有時,一個面向內(nèi)部的 API 升級,往往開發(fā)的同學(xué)傾向于選擇高效率,采用一種叫”同步發(fā)布“的模式來做不兼容變更,即通知已知的所有的客戶端,自己的服務(wù)API要做一個不兼容變更,大家一起發(fā)布,同時更新,切換到新的接口。這樣的方法是非常不可取的,原因有幾個:
因此,對于在生產(chǎn)集群已經(jīng)得到應(yīng)用的API,強(qiáng)烈不建議采用“同步升級”的模式來處理不兼容API變更。
批量更新如何設(shè)計是另一個常見的API設(shè)計決策。這里我們常見有兩種模式:

API的設(shè)計者可能會希望實(shí)現(xiàn)一個服務(wù)端的批量更新能力,但是我們建議要盡量避免這樣做。除非對于客戶來說提供原子化+事務(wù)性的批量很有意義( all-or-nothing),否則實(shí)現(xiàn)服務(wù)端的批量更新有諸多的弊端,而客戶端批量更新則有優(yōu)勢:
Be aware of the risks in full replace 警惕全體替換更新模式的風(fēng)險
所謂 Full replacement 更新,是指在 Mutation API 中,用一個全新的Object/Resource 去替換老的 Object/Resource 的模式。
API寫出來大概是這樣的:
UpdateFoo(Foo newFoo);這是非常常見的 Mutation 設(shè)計模式。但是這樣的模式有一些潛在的風(fēng)險作為 API 設(shè)計者必須了解。
使用 Full replacement 的時候,更新對象 Foo 在服務(wù)端可能已經(jīng)有了新的成員,而客戶端尚未更新并不知道該新成員。服務(wù)端增加一個新的成員一般來說是兼容的變更,但是,如果該成員之前被另一個知道這個成員的client設(shè)置了值,而這時一個不知道這個成員的 client 來做 full-replace,該成員可能就會被覆蓋。
更安全的更新方式是采用 Update mask,也即在 API 設(shè)計中引入明確的參數(shù)指明哪些成員應(yīng)該被更新。
UpdateFoo {
Foo newFoo;
boolen update_field1; // update mask
boolen update_field2; // update mask
}或者 update mask 可以用 repeated “a.b.c.d“這樣方式來表達(dá)。
不過由于這樣的 API 方式維護(hù)和代碼實(shí)現(xiàn)都復(fù)雜一些,采用這樣模式的 API 并不多。所以,本節(jié)的標(biāo)題是 “be aware of the risk“,而不是要求一定要用 update mask。
Don’t create your own error codes or error mechanism 不要試圖創(chuàng)建自己的錯誤碼和返回錯誤機(jī)制
API 的設(shè)計者有時很想創(chuàng)建自己的 Error code,或者是表達(dá)返回錯誤的不同機(jī)制,因?yàn)槊總€ API 都有很多的細(xì)節(jié)的信息,設(shè)計者想表達(dá)出來并返回給用戶,想著“用戶可能會用到”。但是事實(shí)上,這么做經(jīng)常只會使API變得更復(fù)雜更難用。
Error-handling 是用戶使用 API 非常重要的部分。為了讓用戶更容易的使用 API,最佳的實(shí)踐應(yīng)該是用標(biāo)準(zhǔn)、統(tǒng)一的 Error Code,而不是每個 API 自己去創(chuàng)立一套。例如 HTTP 有規(guī)范的 error code 【7】,Google Could API 設(shè)計時都采用統(tǒng)一的Error code 等【5】。
更多的Design patterns,可以參考[5] Google Cloud API guide,[6] Microsoft API design best practices等。不少這里提到的問題也在這些參考的文檔里面有涉及,另外他們還討論到了像versioning,pagination,filter等常見的設(shè)計規(guī)范方面考慮。這里不再重復(fù)。
【1】File wiki
【2】阿白,域模型設(shè)計系列文章
【3】Idempotency, wiki
【4】Compatibility
【5】API Design patterns for Google Cloud
【6】API design best practices, Microsoft
【7】Http status code
【8】A philosophy of software design, John Ousterhout
文章轉(zhuǎn)自微信公眾號@阿里云開發(fā)者






微信截圖_17404716235516.png)