
ChatGPT生態系統的安全漏洞導致第三方網站賬戶和敏感數據泄露
Elastic 的推理 API 可讓開發人員在 Elastic 環境中輕松訪問人工智能模型并對其執行推理。 該 API 無需自托管模型或通過外部 API 進行單獨的推理調用,從而簡化了在 Elastic 中創建和查詢矢量索引的過程。 值得注意的是,無需手動遍歷現有詞法搜索索引中的每個文檔來添加向量嵌入,只需調用一次 API,即可創建推理攝取管道并重新為數據建立索引。
Cohere 的整個 Embed v3 模型系列–包括我們最先進的英語嵌入模型(embed-english-v3.0)和多語言嵌入模型(embed-multilingual-v3.0)–現在可通過 Elastic 的推理 API 在 Elastic Cloud 和 Elastic 自管理環境中使用。
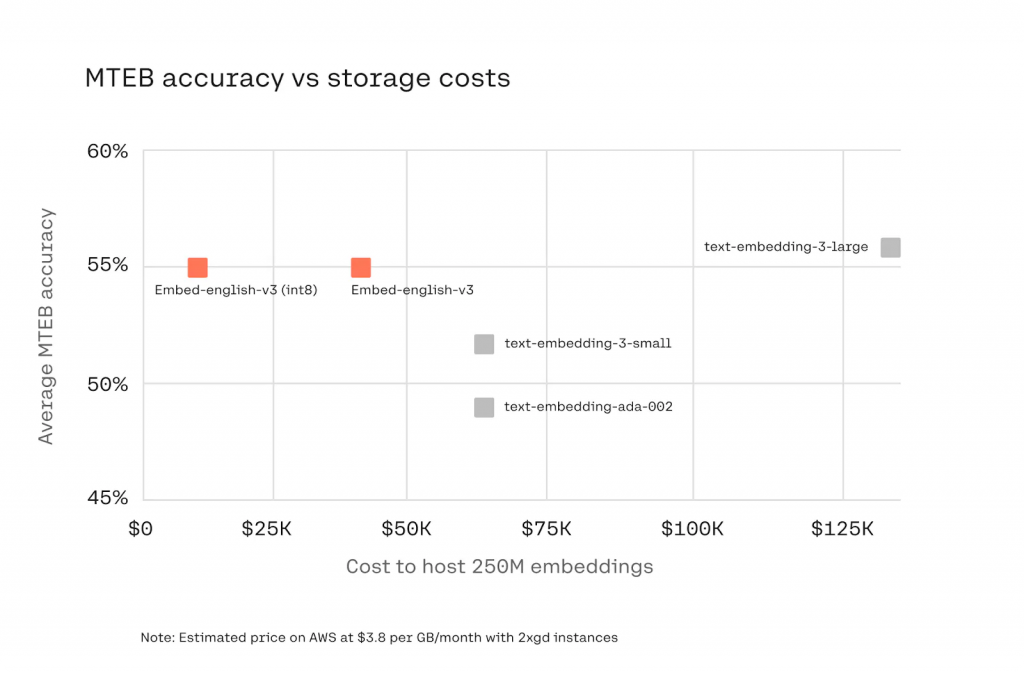
我們還很高興地宣布,推理 API 原生支持浮點和 int8(或字節)嵌入。 Int8 壓縮允許用戶利用 Elastic 對字節矢量的支持,將嵌入的大小減少 4倍,而對搜索質量的影響卻很小。 由于矢量數據庫的成本在一定程度上與存儲矢量的大小相關,因此開發人員可以在不影響準確性的情況下降低存儲成本。 Cohere 的嵌入模型在使用 int8(字節)壓縮時,其性能可與 OpenAI 的嵌入模型相媲美,而存儲成本僅為后者的一小部分。 下圖顯示了各種嵌入模型的 MTEB 精度與約 2.5 億嵌入數據集的存儲成本的比較。
我們很高興 Elastic 行業領先的平臺能讓開發人員更輕松地訪問我們的嵌入式產品。
使用推理應用程序接口(Inference API)實現 Cohere 的嵌入只需調用幾個應用程序接口。
首先,創建一個推理模型,指定一個 Cohere 的嵌入模型。 在本例中,我們將使用 Cohere 的基準英語模型 “embed-english-v3.0″,并使用 int8 壓縮。 要在 Elastic 中使用 int8 壓縮,我們將指定embedding_type為byte。
PUT _inference/text_embedding/cohere_embeddings
{
"service": "cohere",
"service_settings": {
"api_key": "<cohere_api_key>",
"model_id": "embed-english-v3.0",
"embedding_type": "byte"
}
}接下來,為包含嵌入內容的新索引創建索引映射。 在此,您將指定由您選擇的向量和壓縮技術決定的某些參數。
PUT cohere-embeddings
{
"mappings": {
"properties": {
"content_embedding": {
"type": "dense_vector",
"dims": 1024,
"element_type": "byte"
},
"content": {
"type": "text"
}
}
}
}接下來,創建一個帶有推理處理器的攝取管道,以便在將內容攝取到索引時自動計算嵌入。
PUT _ingest/pipeline/cohere_embeddings
{
"processors": [
{
"inference": {
"model_id": "cohere_embeddings",
"input_output": {
"input_field": "content",
"output_field": "content_embedding"
}
}
}
]
}要完成新索引的設置,請使用您剛剛創建的攝取管道重新索引現有來源的數據。 新索引將包含管道中指定的輸入字段中所有文本數據的嵌入,供您在語義搜索中使用。
POST _reindex?wait_for_completion=false
{
"source": {
"index": "test-data",
"size": 50
},
"dest": {
"index": "cohere-embeddings",
"pipeline": "cohere_embeddings"
}
}現在您的索引已經創建,您可以使用 KNN 向量搜索和 Cohere 的嵌入來輕松查詢。
GET cohere-embeddings/_search
{
"knn": {
"field": "content_embedding",
"query_vector_builder": {
"text_embedding": {
"model_id": "cohere_embeddings",
"model_text": "Elasticsearch and Cohere"
}
},
"k": 10,
"num_candidates": 100
},
"_source": [
"id",
"content"
]
}就是這樣! 利用 Cohere 嵌入在您的 Elastic 索引中進行語義搜索。 要開始使用,請為 Cohere 創建一個試用 API 密鑰,并嘗試使用 Elastic 的推理 API 和 Cohere 的嵌入。
冪簡集成是國內領先的API集成管理平臺,專注于為開發者提供全面、高效、易用的API集成解決方案。冪簡API平臺提供了多種維度發現API的功能:通過關鍵詞搜索API、從API Hub分類瀏覽API、從開放平臺分類瀏覽企業間接尋找API等。
此外,冪簡集成開發者社區會編寫API入門指南、多語言API對接指南、API測評等維度的文章,讓開發者選擇符合自己需求的API。
本文翻譯源自:https://cohere.com/blog/elastic-inference-api







