
2024年七大最佳免費(fèi)貨幣轉(zhuǎn)換API
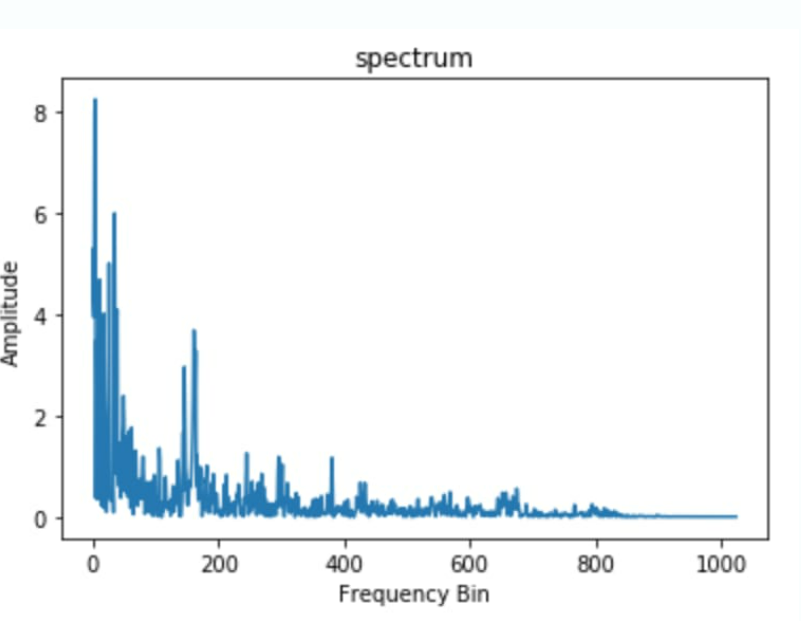
頻譜或頻譜圖是一個圖表,其中 X 軸顯示聲波的頻率,而 Y 軸表示其振幅。這種類型的聲音數(shù)據(jù)可視化可幫助您分析頻率內(nèi)容,但會遺漏時間分量。
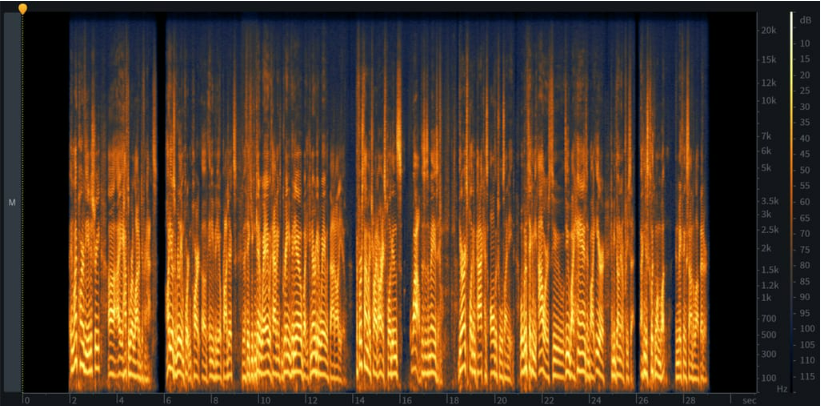
頻譜圖是信號的詳細(xì)視圖,涵蓋了聲音的所有三個特征。您可以從 x 軸了解時間,從 y 軸了解頻率,從顏色了解振幅。事件越響亮,顏色越亮,而寂靜則以黑色表示。在一個圖表上擁有三個維度非常方便:它允許您跟蹤頻率如何隨時間變化,檢查聲音的所有完整度,并通過視覺發(fā)現(xiàn)各種問題區(qū)域(如噪聲)和模式。
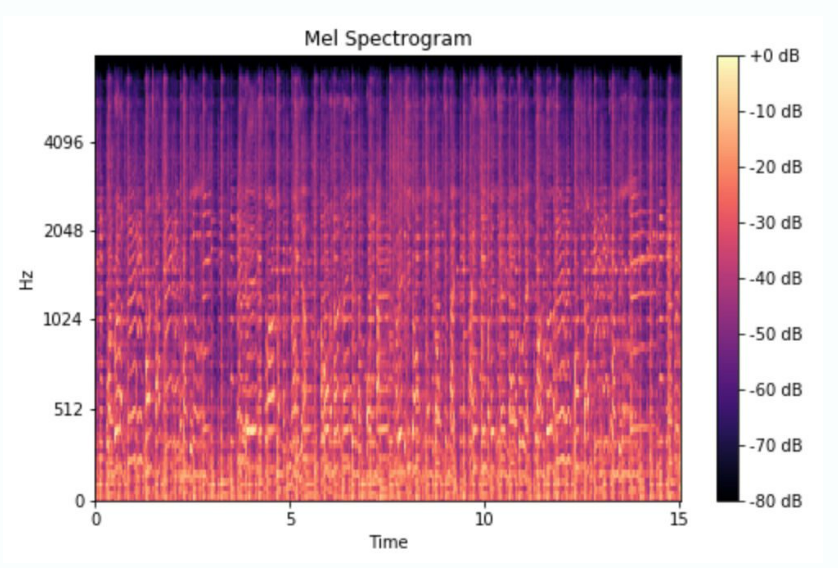
Mel頻譜圖,其中mel代表旋律,是基于描述人們?nèi)绾胃兄曇籼卣鞯膍el尺度的頻譜圖類型。我們的耳朵比高頻更能區(qū)分低頻。你可以自己檢查一下:嘗試播放 500 到 1000 Hz 的音調(diào),然后播放 10,000 到 10,500 Hz 的音調(diào)。前者的頻率范圍似乎比后者寬得多,但實際上它們是相同的。梅爾頻譜圖結(jié)合了人類聽覺的這一獨(dú)特特征,將赫茲的值轉(zhuǎn)換為梅爾標(biāo)度。這種方法廣泛用于流派分類、歌曲中的樂器檢測和語音情感識別。
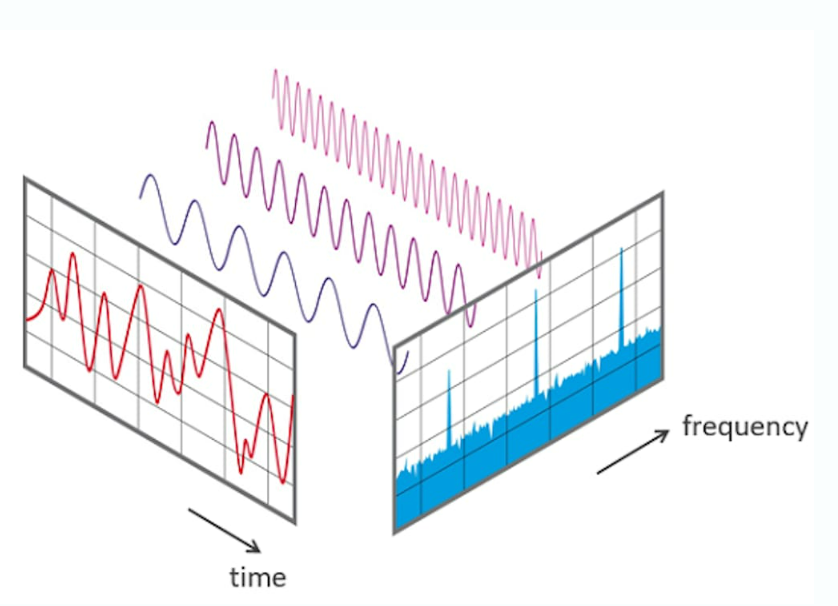
傅里葉變換 (FT)?是一種數(shù)學(xué)函數(shù),可將信號分解為不同幅度和頻率的尖峰。我們用它來將波形轉(zhuǎn)換為相應(yīng)的頻譜圖,以便從不同的角度查看相同的信號并執(zhí)行頻率分析。這是理解信號和排除其中錯誤的有力工具。
快速傅里葉變換 (FFT)?是計算傅里葉變換的算法。
短時傅里葉變換 (STFT) 是將波形轉(zhuǎn)換為頻譜圖的傅里葉變換序列。
當(dāng)然,您不需要手動執(zhí)行轉(zhuǎn)換。您也不需要了解 FT、STFT 和音頻分析中使用的其他技術(shù)背后的復(fù)雜數(shù)學(xué)。所有這些任務(wù)和許多其他任務(wù)都由音頻分析軟件自動完成,在大多數(shù)情況下,該軟件支持以下操作:
以下是音頻分析中使用的最流行的工具列表。
Audacity?是一個免費(fèi)的開源音頻編輯器,用于拆分錄音、去除噪聲、將波形轉(zhuǎn)換為頻譜圖并對其進(jìn)行標(biāo)記。Audacity 不需要編碼技能。然而,其音頻分析的工具并不十分先進(jìn)。要執(zhí)行后續(xù)步驟,您需要將數(shù)據(jù)集加載到?Python?或切換到專門專注于分析和/或機(jī)器學(xué)習(xí)的平臺。
Tensorflow-io 包用于準(zhǔn)備和增強(qiáng)音頻數(shù)據(jù),讓你能夠執(zhí)行廣泛的操作,包括噪聲消除、將波形轉(zhuǎn)換為頻譜圖、頻率和時間掩碼以使聲音清晰可聽等。該工具屬于開源 TensorFlow 生態(tài)系統(tǒng),涵蓋端到端機(jī)器學(xué)習(xí)工作流程。因此,在預(yù)處理后,您可以在同一平臺上訓(xùn)練 ML 模型。
Torchaudio 是 PyTorch 的音頻處理庫。它提供了多種用于處理和轉(zhuǎn)換音頻數(shù)據(jù)的工具。它支持各種音頻格式,并提供必要的數(shù)據(jù)加載和預(yù)處理功能。
Librosa 是一個幾乎包含音頻和音樂分析所需的一切的開源Python庫。它支持顯示音頻文件的特征、創(chuàng)建所有類型的音頻數(shù)據(jù)可視化以及從中提取功能,僅舉幾例。
MathWorks 的 Audio Toolbox?提供了許多用于音頻數(shù)據(jù)處理和分析的工具,從標(biāo)記到估計信號指標(biāo),再到提取某些特征。它還附帶了預(yù)先訓(xùn)練的機(jī)器學(xué)習(xí)和深度學(xué)習(xí)模型,可用于語音分析和聲音識別。
現(xiàn)在我們已經(jīng)對聲音數(shù)據(jù)有了基本的了解,讓我們快速瀏覽一下端到端音頻分析項目的關(guān)鍵階段。

您可以通過三種方式獲取數(shù)據(jù)以訓(xùn)練機(jī)器學(xué)習(xí)模型:使用免費(fèi)的聲音庫或音頻數(shù)據(jù)集,從數(shù)據(jù)提供商處購買數(shù)據(jù),或者讓領(lǐng)域?qū)<覅⑴c收集數(shù)據(jù)。
網(wǎng)絡(luò)上有很多這樣的來源。但在這種情況下,我們無法控制數(shù)據(jù)的質(zhì)量和數(shù)量,以及記錄的一般方法。
聲音庫是按主題分組的免費(fèi)音頻片段。Freesound?和?BigSoundBank?等來源提供錄音、環(huán)境聲音、噪音,以及各種類型的內(nèi)容。例如,你可以找到掌聲的聲音景觀和帶滑板聲音的集合。
最重要的是,聲音庫并不是專門為機(jī)器學(xué)習(xí)項目準(zhǔn)備的。因此,我們需要在布景完成、標(biāo)簽和質(zhì)量控制方面執(zhí)行額外的工作。
相反,音頻數(shù)據(jù)集的創(chuàng)建考慮了特定的機(jī)器學(xué)習(xí)任務(wù)。例如,由機(jī)器聽覺實驗室提供的鳥類音頻檢測數(shù)據(jù)集包含在生物聲學(xué)監(jiān)測項目中收集的7000多個片段。另一個例子是ESC-50:環(huán)境聲音分類數(shù)據(jù)集,包含2000個帶標(biāo)簽的音頻錄音。每個文件長5秒,屬于五個類別中的50個語義類之一。
Google的AudioSet是最大的音頻數(shù)據(jù)集合之一。它包括超過 200 萬個從 YouTube 視頻中提取的人工標(biāo)記的 10 秒聲音剪輯。該數(shù)據(jù)集涵蓋 632 個類別,從音樂和語音到碎片和牙刷聲音。
就數(shù)據(jù)完整性而言,用于機(jī)器學(xué)習(xí)的商業(yè)音頻集肯定比免費(fèi)音頻集更可靠。我們可以推薦?ProSoundEffects?銷售數(shù)據(jù)集,以訓(xùn)練語音識別、環(huán)境聲音分類、音頻源分離和其他應(yīng)用程序的模型。該公司總共有 357,000 個由電影聲音專家錄制的文件,分為 500+ 個類別。
但是,如果你正在尋找的聲音數(shù)據(jù)過于特殊或罕見怎么辦?如果你需要完全控制錄音和標(biāo)記怎么辦?那么最好與同一行業(yè)中可靠的專家合作進(jìn)行你的機(jī)器學(xué)習(xí)項目。
在使用 Sleep.ai 時,我們的任務(wù)是創(chuàng)建一個能夠識別磨牙癥患者在睡眠中通常發(fā)出的磨擦聲的模型。顯然,我們需要特殊數(shù)據(jù),而這些數(shù)據(jù)無法通過開源獲得。此外,數(shù)據(jù)可靠性和質(zhì)量必須是最佳的,這樣我們才能獲得值得信賴的結(jié)果。
為了獲得這樣的數(shù)據(jù)集,這家初創(chuàng)公司與睡眠實驗室合作,科學(xué)家們在人們睡覺時對其進(jìn)行監(jiān)測,以定義健康的睡眠模式并診斷睡眠障礙。專家使用各種設(shè)備來記錄大腦活動、運(yùn)動和其他事件。他們?yōu)槲覀儨?zhǔn)備了一個帶有大約12,000個樣本的標(biāo)記數(shù)據(jù)集,包括磨牙和打鼾的聲音。
在 Sleep.io 的情況下,我們的團(tuán)隊跳過了這一步,將我們項目的數(shù)據(jù)準(zhǔn)備任務(wù)委托給睡眠專家。這同樣適用于從數(shù)據(jù)提供商處購買帶注釋的聲音集合的人。但是,如果您只有原始數(shù)據(jù),即以其中一種音頻文件格式保存的錄音,則需要為機(jī)器學(xué)習(xí)做好準(zhǔn)備。
數(shù)據(jù)標(biāo)注或注釋是用正確的答案標(biāo)記原始數(shù)據(jù)以運(yùn)行監(jiān)督式機(jī)器學(xué)習(xí)的過程。在訓(xùn)練過程中,您的模型將學(xué)習(xí)識別新數(shù)據(jù)中的模式,并根據(jù)標(biāo)簽做出正確的預(yù)測。因此,它們的質(zhì)量和準(zhǔn)確性對于 ML 項目的成功至關(guān)重要。
盡管標(biāo)記意味著軟件工具的幫助和一定程度的自動化,但在大多數(shù)情況下,它仍然由專業(yè)注釋者和/或領(lǐng)域?qū)<沂謩訄?zhí)行。在我們的磨牙癥檢測項目中,睡眠專家聽取了錄音,并用磨牙或打鼾標(biāo)簽標(biāo)記它們。
除了使用有意義的標(biāo)簽豐富數(shù)據(jù)外,我們還必須對可靠的數(shù)據(jù)進(jìn)行預(yù)處理,以實現(xiàn)更好的預(yù)測準(zhǔn)確性。以下是語音識別和聲音分類項目的最基本步驟。
Framing?是指將連續(xù)的聲音流切割成相同長度(通常為 20-40 ms)的短片段(幀),以便進(jìn)一步進(jìn)行分段處理。
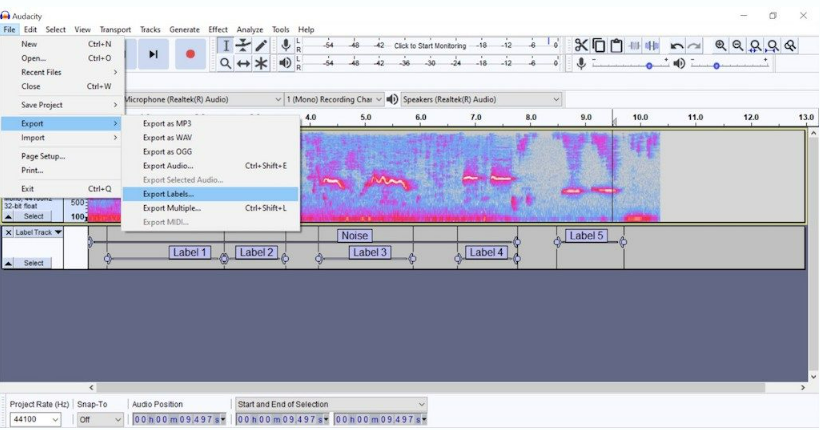
窗口化是一種基本的音頻處理技術(shù),用于最大限度地減少頻譜泄漏,頻譜泄漏是一種常見的錯誤,會導(dǎo)致頻率模糊并降低振幅精度。有幾種窗口函數(shù)(Hamming、Hanning、Flat Top 等)適用于不同類型的信號,盡管 Hanning 變體在?95%?的情況下效果很好。
基本上,所有窗口都執(zhí)行相同的操作:減小或平滑每幀開頭和結(jié)尾的振幅,同時在中心增加振幅以保持平均值。
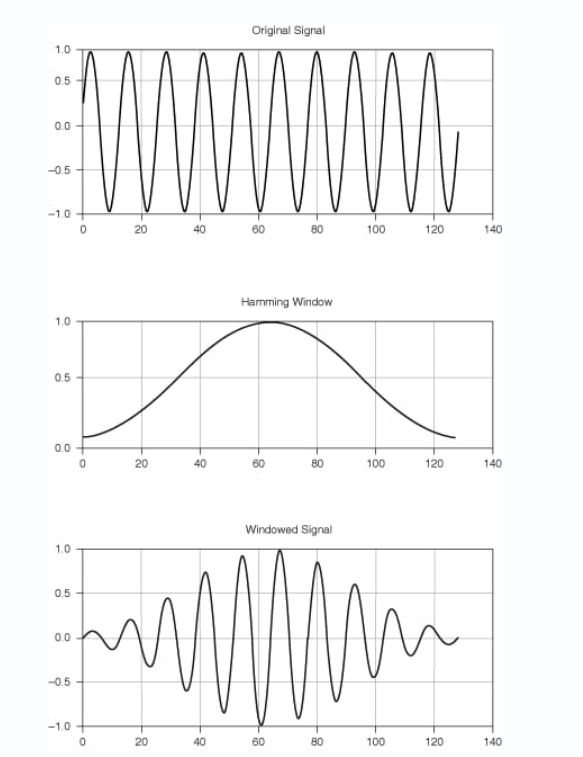
重疊添加 (OLA)?方法可防止丟失可能由窗口化引起的重要信息。OLA 在相鄰幀之間提供 30-50% 的重疊,允許修改它們而不會有失真的風(fēng)險。并能夠從窗口中準(zhǔn)確重構(gòu)原始信號。
音頻特征或描述符是從預(yù)處理后的音頻數(shù)據(jù)可視化計算得出的信號屬性,它們可以分為以下三個領(lǐng)域:
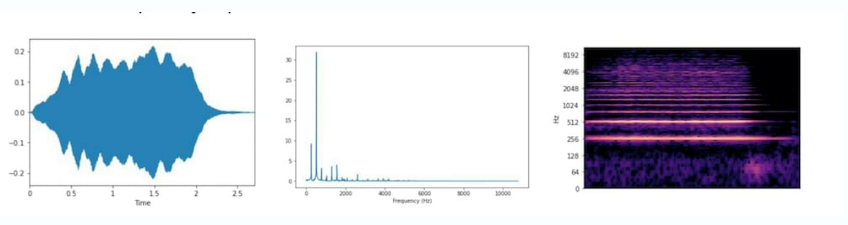
正如我們之前提到的,時域或時間特征是直接從原始波形中提取的。請注意,波形本身并不包含太多有關(guān)聲音實際聽起來如何的信息。它們僅指示振幅如何隨時間變化。在下圖中,我們可以看到空調(diào)和警報器波形看起來很相似,但可以肯定的是,這些聲音不會相似。
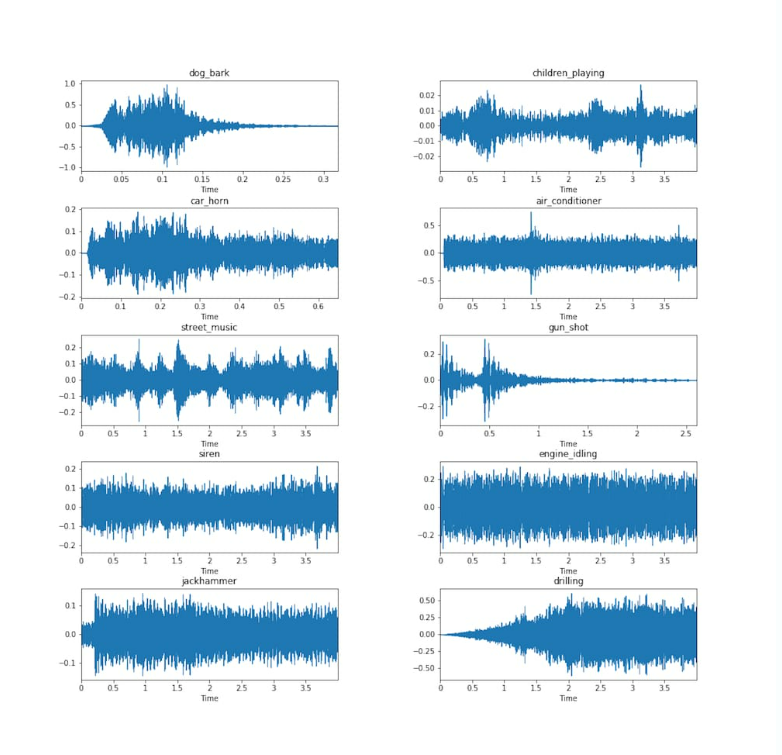
現(xiàn)在讓我們來看看我們可以從波形中提取的一些關(guān)鍵特征。
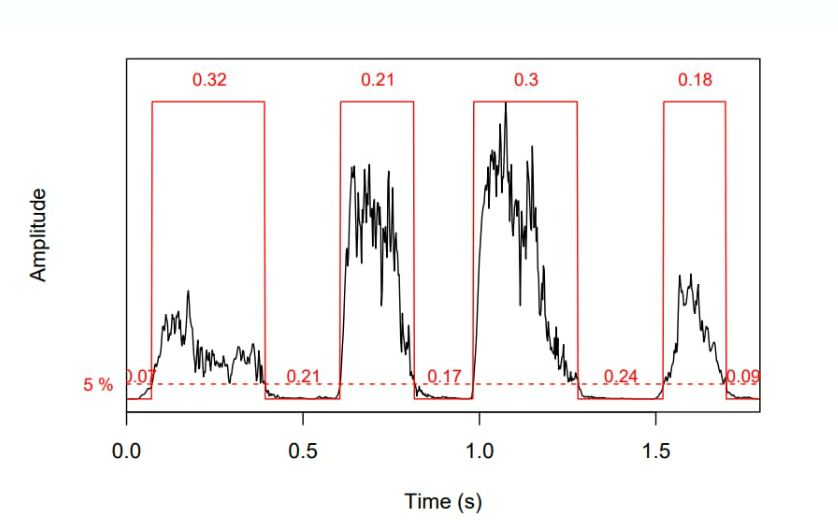
振幅包絡(luò) (AE) 跟蹤幀內(nèi)的振幅峰值,并顯示它們?nèi)绾坞S時間變化。使用 AE,您可以自動測量聲音不同部分的持續(xù)時間(如下圖所示)。AE 廣泛用于起始檢測以指示某個信號何時開始,以及用于音樂流派分類。
短時能量 (STE)?顯示短語音幀內(nèi)的能量變化。它是一個強(qiáng)大的工具,用于分離有聲和無聲片段。
均方根能量(RMSE)提供了對信號平均能量的理解。它可以根據(jù)波形或頻譜圖計算。在第一種情況下,您將更快地獲得結(jié)果。然而,頻譜圖可以更準(zhǔn)確地表示能量隨時間的變化。RMSE 對于音頻分段和音樂流派分類特別有用。
過零率 (ZCR)?計算信號波在幀內(nèi)穿過水平軸的次數(shù)。它是最重要的聲學(xué)特征之一,廣泛用于檢測語音的存在與否,以及區(qū)分噪聲與沉默、音樂與語音。
頻域特征比時域特征更難提取,因為該過程涉及使用 FT 或 STFT 將波形轉(zhuǎn)換為頻譜圖或頻譜圖。然而,正是頻率內(nèi)容揭示了許多在時域中不可見或難以看到的重要聲音特征。
最常見的頻域特征包括
當(dāng)然,這個領(lǐng)域還有許多其他特性值得研究。概括地說,它告訴我們聲能如何在頻率之間傳播,而時域則顯示信號如何隨時間變化。
該域結(jié)合了時間和頻率分量,并使用各種類型的頻譜圖作為聲音的視覺表示。您可以從應(yīng)用短時傅里葉變換的波形中獲得頻譜圖。
最流行的時頻域特征組之一是?mel 頻率倒譜系數(shù) (MFCC)。它們在人類聽覺范圍內(nèi)工作,因此基于我們之前討論的梅爾標(biāo)度和梅爾頻譜圖。
毫無疑問,MFCC 的最初應(yīng)用是語音和語音識別。但它們也被證明對音樂處理和醫(yī)療目的的聲學(xué)診斷有效,包括打鼾檢測。例如,工程學(xué)院(東密歇根大學(xué))最近開發(fā)的一個深度學(xué)習(xí)模型就是在 1000 張打鼾聲的 MFCC 圖像(頻譜圖)上訓(xùn)練的。
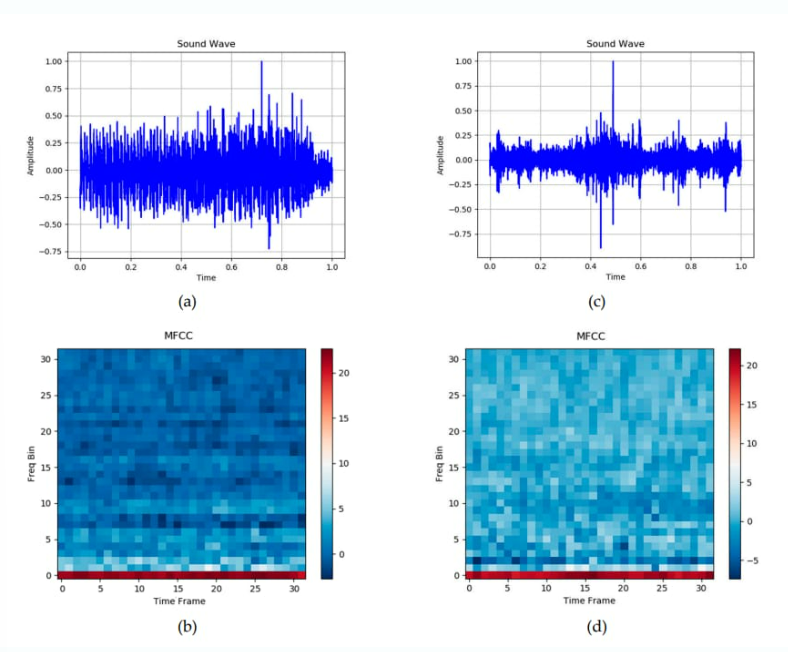
為了為 Sleep.ai 項目訓(xùn)練模型,我們的數(shù)據(jù)科學(xué)家從時域和頻域中選擇了一組最相關(guān)的特征。通過結(jié)合這些特征,他們創(chuàng)建了磨牙和打鼾聲音的豐富檔案。
由于音頻特征以視覺形式出現(xiàn)(主要以頻譜圖的形式出現(xiàn)),因此它們成為依賴于深度神經(jīng)網(wǎng)絡(luò)的圖像識別對象。有幾種流行的架構(gòu)在聲音檢測和分類方面表現(xiàn)出色。在這里,我們只關(guān)注兩種常用的通過聲音來識別睡眠問題的方法。
長短期記憶網(wǎng)絡(luò) (LSTM)?以其能夠發(fā)現(xiàn)數(shù)據(jù)中的長期依賴關(guān)系并記住許多先前步驟中的信息而聞名。根據(jù)睡眠呼吸暫停檢測研究,當(dāng)使用 MFCC 特征作為輸入來區(qū)分正常的打鼾聲和異常的打鼾聲時,LSTM 可以達(dá)到?87%?的準(zhǔn)確率。
另一項研究顯示了更好的結(jié)果:LSTM 以?95.3%?的準(zhǔn)確率對正常和異常的打鼾事件進(jìn)行分類。該神經(jīng)網(wǎng)絡(luò)使用了包括MFCCs和時間域中的短時能量在內(nèi)的五種類型的特征進(jìn)行訓(xùn)練。它們共同代表了打鼾的不同特征。
卷積神經(jīng)網(wǎng)絡(luò)在醫(yī)療保健和其他行業(yè)的計算機(jī)視覺領(lǐng)域處于領(lǐng)先地位。它們通常被稱為圖像識別任務(wù)的自然選擇。CNN 架構(gòu)在頻譜圖處理中的效率再次證明了這一說法的有效性。
在工程學(xué)院(東密歇根大學(xué))的上述項目中,基于 CNN 的深度學(xué)習(xí)模型在打鼾聲和非打鼾聲的分類中達(dá)到了?96%?的準(zhǔn)確率。
CNN 和 LSTM 架構(gòu)的組合報告了幾乎相同的結(jié)果。埃因霍溫理工大學(xué)的科學(xué)家小組應(yīng)用 CNN 模型從頻譜圖中提取特征,然后運(yùn)行 LSTM 將 CNN 輸出分類為打鼾和非打鼾事件。準(zhǔn)確率值范圍為?94.4% 到 95.9%,具體取決于用于錄制打鼾聲的麥克風(fēng)的位置。
對于 Sleep.io 項目,AltexSoft 數(shù)據(jù)科學(xué)團(tuán)隊使用了兩個 CNN(用于打鼾和磨擦檢測),并在 TensorFlow 平臺上對其進(jìn)行訓(xùn)練。在模型達(dá)到 80% 以上的準(zhǔn)確率后,它們被投入生產(chǎn)。隨著從真實用戶那里收集到的輸入數(shù)據(jù)不斷增加,它們的結(jié)果也在不斷改進(jìn)。
為了讓我們的音頻分類算法面向更廣泛的受眾,我們將它們打包到一個 iOS 應(yīng)用程序?Do I Snore 或 Grind?中,您可以從 App Store 免費(fèi)下載。我們的用戶體驗團(tuán)隊創(chuàng)建了一個統(tǒng)一的流程,使用戶能夠記錄睡眠期間的噪音、跟蹤他們的睡眠周期、監(jiān)控振動事件,并接收有關(guān)影響睡眠的因素的信息以及有關(guān)如何調(diào)整習(xí)慣的提示。所有音頻數(shù)據(jù)分析都在設(shè)備上執(zhí)行,因此即使沒有 Internet 連接,您也會獲得結(jié)果。
請注意,無論智能程度如何,沒有任何健康應(yīng)用程序可以替代真正的醫(yī)生。AI 得出的結(jié)論必須經(jīng)過您的牙醫(yī)、醫(yī)生或其他醫(yī)學(xué)專家的驗證。
原文鏈接:https://www.altexsoft.com/blog/audio-analysis/
2024年七大最佳免費(fèi)貨幣轉(zhuǎn)換API

如何通過Smart Image Cropping API自動裁剪圖像?

News API + React:創(chuàng)建一個卓越的實時新聞應(yīng)用程序

30款免費(fèi)開放的API,助力營銷人員與內(nèi)容開發(fā)者

免費(fèi)獲取韻達(dá)快遞查詢API的使用指南

OpenAI ChatGPT API 與 React JS 的完美結(jié)合:全面指南

面向營銷人員的 API:前 7 名免費(fèi) REST API

常用文檔轉(zhuǎn)換API匯總

2024年國內(nèi)熱門天氣環(huán)境API