試想一下場景,我們在使用數(shù)據(jù)地圖或指標(biāo)查詢時(shí),指標(biāo)預(yù)存信息為“欠款金額”,而我們搜索的指標(biāo)為“未還款金額”,雖然語義上很接近,但是ES的分詞詞典中并沒有“未還款”,匹配不上,會(huì)導(dǎo)致我們搜索不到指標(biāo)信息。為了提升搜索效果,通常會(huì)給ES配置同義詞表,把預(yù)存的指標(biāo)信息和開發(fā)、業(yè)務(wù)人員常使用的指標(biāo)名稱做同義詞配置,提高查詢效果。
而基于Embedding進(jìn)行語義檢索的過程大致如下:
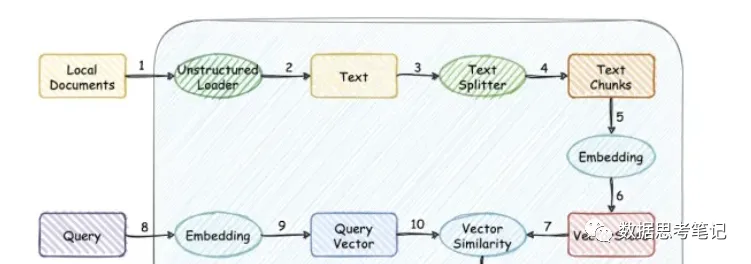
1.?對(duì)預(yù)存指標(biāo)信息生成語義向量(Embedding),存入向量數(shù)據(jù)庫作為基準(zhǔn);2.?將用戶搜索指標(biāo)信息向量化后,檢索向量數(shù)據(jù)庫;3.?計(jì)算兩者之間的向量距離(如余弦相似度距離),找出與用戶搜索詞最近的幾個(gè)向量。那最近的幾個(gè)向量,其實(shí)就是語義和搜索詞相似的,而并不一定需要相同的關(guān)鍵詞。
2. 搭建領(lǐng)域知識(shí)庫,提供私域問答
通常我們遇到以下場景會(huì)考慮搭建本地知識(shí)庫:1.?我們所需的行業(yè)知識(shí)比較專業(yè),大模型不能確保準(zhǔn)確、高效的提供;2.?在利用大模型能力的過程中,我們內(nèi)部的數(shù)據(jù)跟環(huán)境不能對(duì)外暴露,需完全可控,避免任何的數(shù)據(jù)隱私泄露以及安全風(fēng)險(xiǎn)。該需求比較普遍,通常采用Embedding + 向量檢索引擎 + LLM?的方式,處理過程流程如下:
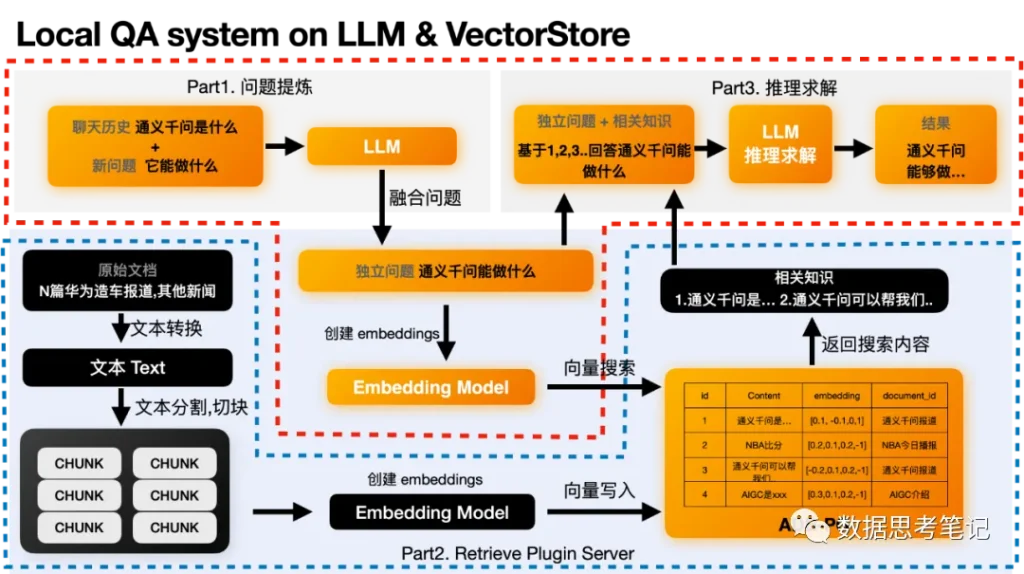
處理的過程包括:
1. 先將原始文檔中的文本內(nèi)容全部提取出來。然后根據(jù)語義切塊,切成多個(gè)chunk,可以理解為可以完整表達(dá)一段意思的文本段落。在這個(gè)過程中還可以額外做一些元數(shù)據(jù)抽取,敏感信息檢測等行為。
2. 將這些Chunk都丟給embedding模型,來求取這些chunk的embedding。
3. 將embedding和原始chunk一起存入到向量數(shù)據(jù)庫中。
問題提煉:這個(gè)部分是可選的,之所以存在是因?yàn)橛行﹩栴}是需要依賴于上下文的。因?yàn)橛脩魡柕男聠栴}可能沒辦法讓LLM理解這個(gè)用戶的意圖。
向量檢索:獨(dú)立問題求取embedding這個(gè)功能會(huì)在text2vec模型中進(jìn)行。在獲得embedding之后就可以通過這個(gè)embedding來搜索已經(jīng)事先存儲(chǔ)在向量數(shù)據(jù)庫中的數(shù)據(jù)。推理求解:在獲得最相關(guān)的知識(shí)之后,我們就可以讓LLM基于最相關(guān)的知識(shí)和獨(dú)立問題來進(jìn)行求解推理,得到最終的答案。? ?
3. Text2SQL代碼生成,結(jié)果可視化
大模型可以根據(jù)自然語言輸入快速生成SQL代碼片段,并通過可視化的方式展示結(jié)果,從而協(xié)助數(shù)據(jù)人員的日常工作。這減少了編寫復(fù)雜查詢所花費(fèi)的時(shí)間,因此可以投入更多時(shí)間來理解業(yè)務(wù)和分析查詢結(jié)果,以此從數(shù)據(jù)結(jié)果中獲取決策支持。
可以通過大模型創(chuàng)建一個(gè) SQL 查詢來獲取一組特定的數(shù)據(jù),例如:“顯示 2022 年每月的平均收入。”
大模型可以將其轉(zhuǎn)換為 SQL 查詢,如下:
SELECT AVG(revenue) AS average_revenue, MONTH(date) AS month
FROM sales
WHERE YEAR(date) = 2022
GROUP BY MONTH(date);
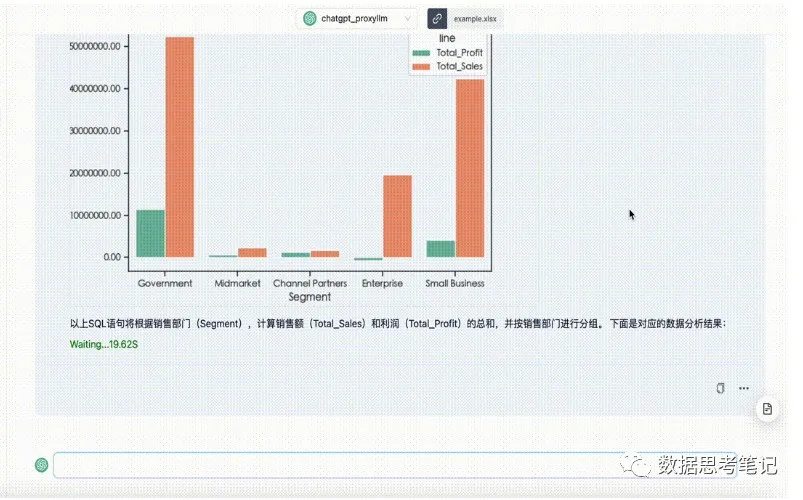
集成可視化功能后的效果圖如下:
4. 數(shù)據(jù)集探索性數(shù)據(jù)分析
EDA數(shù)據(jù)分析師在分析之前往往需要花費(fèi)大量時(shí)間準(zhǔn)備和清理數(shù)據(jù)。利用大模型可以提供數(shù)據(jù)預(yù)處理技術(shù),如處理缺失值、處理異常值、變量相關(guān)性分析以及解決用戶數(shù)據(jù)質(zhì)量問題的建議。通過數(shù)據(jù)預(yù)處理建議,有助于簡化數(shù)據(jù)準(zhǔn)備過程,并確保分析質(zhì)量。該能力屬于大模型的通用基礎(chǔ)能力。
總結(jié)
本文簡要介紹了大模型LLM在數(shù)據(jù)領(lǐng)域應(yīng)用的思路,具體方案會(huì)在后續(xù)專題中逐步展開。大模型的快速發(fā)展為企業(yè)數(shù)據(jù)體系帶來了新機(jī)遇,企業(yè)思考在數(shù)據(jù)治理、數(shù)據(jù)安全、數(shù)據(jù)整合、數(shù)據(jù)分析與挖掘以及業(yè)務(wù)應(yīng)用等方面,通過大模型應(yīng)用來提高生產(chǎn)力。隨著OpenAI開發(fā)者大會(huì)召開,ChatGPT使用成本也逐步降低,并且國產(chǎn)大模型百花齊放,模型效果逐漸提高,將助力大模型應(yīng)用在各行各業(yè)中大放異彩。
原文轉(zhuǎn)自 微信公眾號(hào)@數(shù)據(jù)思考筆記
熱門推薦
一個(gè)賬號(hào)試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
3000+提示詞助力AI大模型
和專業(yè)工程師共享工作效率翻倍的秘密
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
性欧美疯狂xxxxbbbb|
国产精品88888|
国产校园另类小说区|
亚洲午夜电影在线观看|
91视频xxxx|
亚洲人成网站精品片在线观看|
国产mv日韩mv欧美|
日韩精品一区二区三区视频播放
|
在线不卡免费欧美|
美女被吸乳得到大胸91|
欧美一区二视频|
久久99国产精品免费网站|
2欧美一区二区三区在线观看视频
337p粉嫩大胆噜噜噜噜噜91av
|
中文字幕第一页久久|
风流少妇一区二区|
亚洲九九爱视频|
欧美喷潮久久久xxxxx|
五月天亚洲婷婷|
久久久精品国产免大香伊|
成人午夜碰碰视频|
亚洲国产aⅴ天堂久久|
久久这里只有精品首页|
91网址在线看|
精油按摩中文字幕久久|
国产精品福利影院|
日韩欧美国产成人一区二区|
成人免费高清视频|
肉色丝袜一区二区|
国产精品久久久久影院亚瑟|
日韩一区二区三区高清免费看看
|
欧美日韩精品欧美日韩精品一综合|
婷婷激情综合网|
中文字幕中文字幕一区|
欧美成人女星排行榜|
成人av网站免费观看|
免费成人av在线播放|
亚洲三级免费电影|
亚洲国产高清在线观看视频|
欧美酷刑日本凌虐凌虐|
播五月开心婷婷综合|
亚洲va韩国va欧美va|
精品一区二区三区日韩|
国产综合久久久久久鬼色|
亚洲精选视频在线|
中文字幕日本不卡|
国产精品人人做人人爽人人添|
欧美不卡一区二区|
亚洲精品在线观看网站|
欧美一区二区精品|
欧美丰满少妇xxxxx高潮对白|
成人av电影在线播放|
国产成人自拍在线|
thepron国产精品|
99re这里只有精品视频首页|
99久久久久久99|
99久久久免费精品国产一区二区|
www.欧美亚洲|
色婷婷精品大在线视频|
成人av免费观看|
国产一区日韩二区欧美三区|
国产永久精品大片wwwapp|
国产精品一区免费在线观看|
成人做爰69片免费看网站|
成人激情小说网站|
色综合天天综合网国产成人综合天|
99国产欧美另类久久久精品|
99精品热视频|
7777精品伊人久久久大香线蕉|
欧美精品少妇一区二区三区|
精品三级在线观看|
国产精品高潮呻吟久久|
午夜精品福利久久久|
国产美女娇喘av呻吟久久|
www.99精品|
欧美一区二区三区在线|
国产精品私房写真福利视频|
亚洲一区二区精品久久av|
久国产精品韩国三级视频|
一本色道久久综合精品竹菊|
欧美一区二区三区四区高清|
中文字幕av不卡|
亚洲v精品v日韩v欧美v专区
|
亚洲一区二区三区四区在线观看
|
欧美日韩国产综合视频在线观看
|
91成人免费网站|
久久综合中文字幕|
亚洲电影一级片|
岛国av在线一区|
日韩一区二区麻豆国产|
亚洲另类色综合网站|
国产一区二区三区视频在线播放|
一本一本大道香蕉久在线精品|
日韩欧美黄色影院|
亚洲sss视频在线视频|
91麻豆精品视频|
国产精品美女久久久久av爽李琼|
天天综合日日夜夜精品|
一本久久综合亚洲鲁鲁五月天|
国产午夜精品在线观看|
蜜臀av一区二区|
欧美一区二区在线播放|
午夜一区二区三区视频|
av不卡免费在线观看|
欧美激情一区在线|
国产一二三精品|
国产色婷婷亚洲99精品小说|
国产毛片精品一区|
欧美国产精品中文字幕|
成人激情开心网|
成人免费在线播放视频|
av亚洲精华国产精华精华|
亚洲欧洲三级电影|
色呦呦一区二区三区|
亚洲精品伦理在线|
欧美色偷偷大香|
日韩主播视频在线|
欧美一区二区三区啪啪|
久久精品国产99国产精品|
精品成人一区二区三区四区|
国产综合色视频|
国产精品美女久久福利网站|
91在线一区二区|
亚洲成人综合在线|
日韩欧美的一区二区|
国产精品亚洲一区二区三区妖精
|
91麻豆精品国产91久久久久|
麻豆91小视频|
国产精品视频观看|
欧美综合在线视频|
蜜臀av性久久久久av蜜臀妖精|
日韩精品中文字幕一区|
国产精品一线二线三线精华|
欧美激情一区二区三区不卡|
99麻豆久久久国产精品免费
|
8x8x8国产精品|
国产麻豆一精品一av一免费|
亚洲久草在线视频|
精品欧美一区二区久久|
99re成人精品视频|
免费成人美女在线观看|
中文字幕在线一区|
欧美一区二区三区爱爱|
av在线不卡电影|
久久国产精品99久久人人澡|
中文字幕中文字幕一区二区|
777午夜精品免费视频|
不卡视频一二三四|
美女爽到高潮91|
亚洲综合在线电影|
国产精品美女www爽爽爽|
精品日韩在线观看|
欧美日韩国产乱码电影|
99久久综合狠狠综合久久|
极品少妇一区二区|
日本不卡高清视频|
婷婷亚洲久悠悠色悠在线播放|
国产精品传媒在线|
国产欧美一区二区精品忘忧草|
91精品国产综合久久久蜜臀图片
|
亚洲激情图片qvod|
中文字幕一区二区视频|
久久免费电影网|
日韩你懂的在线播放|
在线电影欧美成精品|
精品视频色一区|
精品视频在线免费看|
欧美优质美女网站|
91成人在线精品|
欧美熟乱第一页|
欧美三级日韩三级|
欧美日产国产精品|
欧美乱熟臀69xxxxxx|
欧美日韩免费在线视频|
欧美精选午夜久久久乱码6080|
在线国产电影不卡|
欧美在线观看视频一区二区
|
成人黄色软件下载|
91在线播放网址|
色噜噜狠狠成人网p站|
在线看国产日韩|
欧美人牲a欧美精品|
日韩一区二区精品葵司在线|
欧美xxx久久|
中文字幕乱码一区二区免费|
中文字幕一区二区在线观看|
亚洲综合一二三区|
奇米在线7777在线精品
|
日韩成人伦理电影在线观看|
国产一区二区三区最好精华液|
国产九九视频一区二区三区|
99久久精品国产网站|
欧美嫩在线观看|
国产无遮挡一区二区三区毛片日本|
国产精品视频看|
亚洲成人av资源|
国产成人精品亚洲日本在线桃色|
日本乱码高清不卡字幕|
久久久久久综合|
婷婷亚洲久悠悠色悠在线播放|
成人激情综合网站|