
2024年您產品必備的10大AI API推薦
初級RAG主要在三個方面面臨挑戰:檢索質量低、生成質量差和增強過程難。
要解決上面的問題,需要在檢索前和檢索后做一些優化,這就衍生出了高級RAG的解決方案。
高級RAG相比于初級RAG,基于初級RAG范式,圍繞著知識檢索做優化,新增了檢索前、檢索中以及檢索后的優化策略,用于解決索引、檢索和生成的問題。
檢索前優化
檢索前優化集中在知識切分、索引方式和query改寫的優化上。
知識切分主要把較長的文本按照語義內聚性的分析切成小塊,解決核心知識湮沒以及語義截斷的問題。
索引方式優化技術通過優化數據索引組織方式提升檢索效果。比如去除無效數據或插入某些數據來提高索引覆蓋程度,從而達到與用戶問題的高匹配度問題。
query改寫主要需要理解用戶想表達的意圖,把用戶原始的問題轉換成適合知識庫檢索的問題,從而提高檢索的精準程度。
檢索優化
檢索階段的目標是召回知識庫中最相關知識。
通常,檢索基于向量搜索,它計算查詢與索引數據之間的語義相似性。因此,大多數檢索優化技術都圍繞嵌入模型展開:
微調嵌入模型,將嵌入模型定制為特定領域的上下文,特別是對于術語不斷演化或罕見的領域。例如,BAAI/bge是一個高性能的嵌入模型,可以進行微調。
動態嵌入根據單詞的上下文進行調整,而靜態嵌入則為每個單詞使用單一向量。例如,OpenAI的embeddings-ada-02是一個復雜的動態嵌入模型,可以捕獲上下文理解。
除了向量搜索之外,還有其他檢索技術,例如混合搜索,通常是指將向量搜索與基于關鍵字的搜索相結合的概念。如果您的檢索需要精確的關鍵字匹配,則此檢索技術非常有益。
檢索后優化
對檢索到的上下文進行額外處理可以幫助解決一些問題,例如超出上下文窗口限制或引入噪聲,從而阻礙對關鍵信息的關注。在RAG調查中總結的檢索后優化技術包括:
提示壓縮:通過刪除無關內容并突出重要上下文,減少整體提示長度。
重新排序:使用機器學習模型重新計算檢索到的上下文的相關性得分。
隨著 RAG 技術的進一步發展和演變,新的技術突破了傳統的檢索 – 生成框架,基于此催生了模塊化RAG 的概念。在結構上它更加自由的和靈活,引入了更多的具體功能模塊,例如查詢搜索引擎、融合多個回答。技術上將檢索與微調、強化學習等技術融合。流程上也對 RAG 模塊之間進行設計和編排,出現了多種的 RAG 模式。
然而,模塊化RAG并不是突然出現的,三個范式之間是繼承與發展的關系。Advanced RAG是Modular RAG的一種特例形式,而Naive RAG則是Advanced RAG的一種特例。??
基于上面六大模塊,可快速組合出屬于自己業務的RAG,每個模塊高度可擴展,靈活性極大。
比如:RR模式,即可構建出傳統的Naive RAG;RRRR模式可構架出Advanced RAG;
還可以實現基于檢索結果和用戶評價的獎懲機制,用戶強化和糾正檢索器的行為。
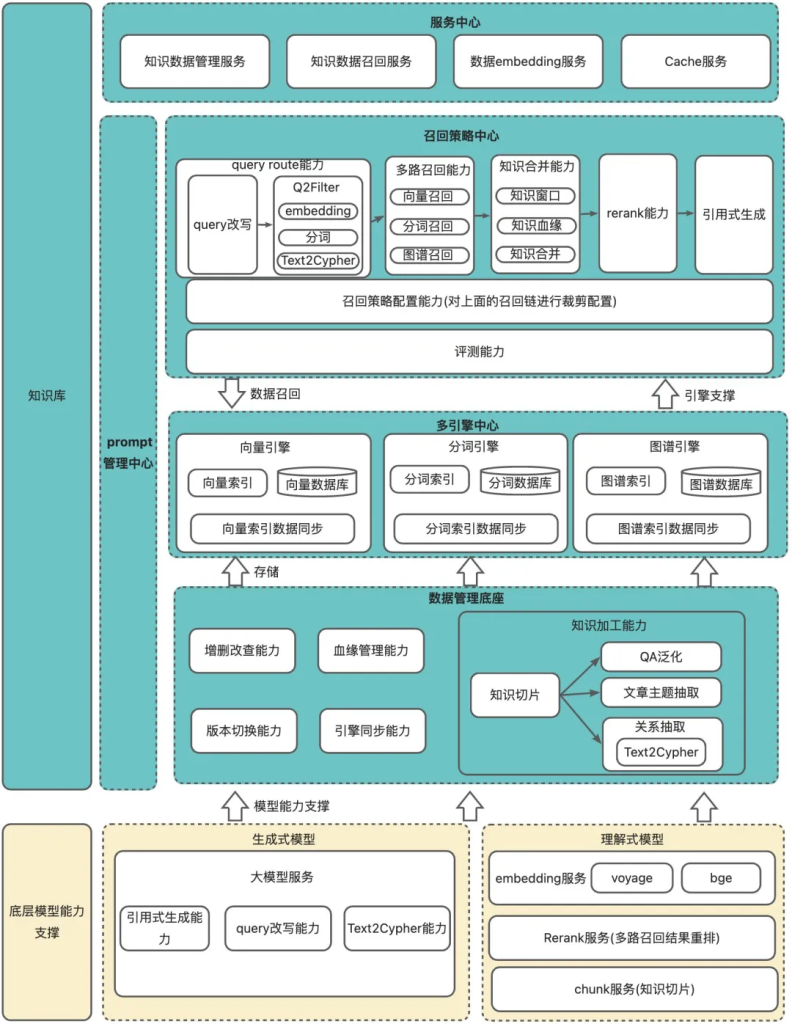
我們實踐的RAG技術架構主要可分為一底座三中心,分別是數據管理底座、模型中心、多引擎中心、召回策略中心。
在工程架構上,每個子系統按照能力劃分子Modular,在上層配置調度策略并統一調度,符合Modular RAG的技術規范;
在檢索技術上,圍繞著檢索做了大量的索引降噪、多路召回、知識去重、重排等操作,符合Advanced RAG的技術規范。
基礎數據底座中包含數據生產和數據加工的能力。
數據生產中有數據版本、血緣管理、引擎同步等能力,
知識加工主要包含數據切片、索引優化等能力
模型中心主要包含生成式大模型和理解式小模型。
生成式大模型主要提供:
理解式小模型主要提供:
多引擎中心包含向量、分詞以及圖譜引擎,在引擎中心提供多種檢索方式,以提高知識的命中率。
召回策略中心在整個RAG建設中起到調度的作用,在這里去執行query改寫、多路召回、檢索后置處理以及大模型引用式生成答案。
基于上面的一底座兩中心架構,每個子能力模塊化,并在上層配置調度策略,符合Modular RAG的技術規范。
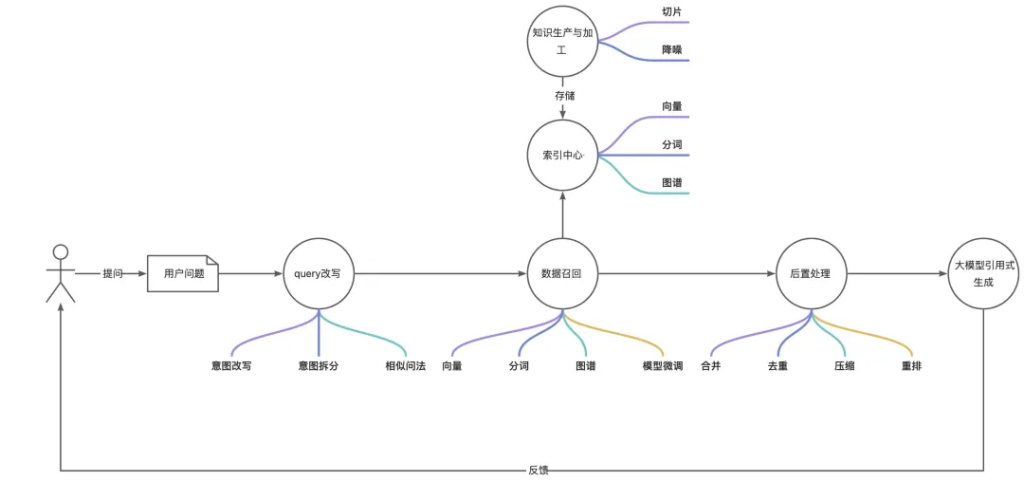
RAG整體業務鏈路主要分為5大步驟:知識生產與加工、query改寫、數據召回、后置處理以及大模型生產。
第一階段保證系統可用。
知識生產與加工
先按照固定字符切分,預留冗余字符來保證語義不被截斷。
query改寫
結合上下文,先使用大模型的理解能力,突出用戶意圖,以便更好的回答用戶問題。
數據召回
第一步可以先實現向量召回,多路召回中,向量召回的比重是最大的,也是最關鍵的一種召回方式,需要找一個和自己業務比較契合的embedding模型和向量數據庫。
數據后置處理
因為數據召回只有向量召回,這一步可以只使用向量近似得分做排序,設置符合業務預期的閾值篩選數據。并把篩選后的知識數據提供給大模型,生成答案。
第二階段的主要目標是提升RAG的檢索效果。
知識生產與加工
query改寫
數據召回
數據后置處理
第三階段的主要目標是在工程上提升可擴展性,各個業務功能做模塊化設計,通過召回策略配置中心,配置出業務所需要的RAG流程。
文檔片段過長會給知識檢索造成很大影響,主要有兩部分的問題:1)索引混淆:核心關鍵詞被湮沒在大量的無效信息中,導致建立的索引,核心知識占的比重比較小,無論時語義匹配、分詞匹配還是圖譜檢索,都很難精準命中關鍵數據,從而影響生成答案的質量;;
2)token過長導致語義會被截斷:知識數據在embedding時,可能會因為token超長導致語義截斷;知識檢索結束后,知識片段越長,輸入給大模型的信息條數就越少,導致大模型也無法獲取足夠的有價值的輸入,從而影響生成答案的質量。
按固定字符拆分知識,通過設置冗余字符來降低句子截斷的問題,使一個完整的句子要么在上文,要么在下文,這種方式能盡量避免在句子中間斷開的問題。
這種實現方式成本最低,在業務起步階段,可以先使用這種方式。
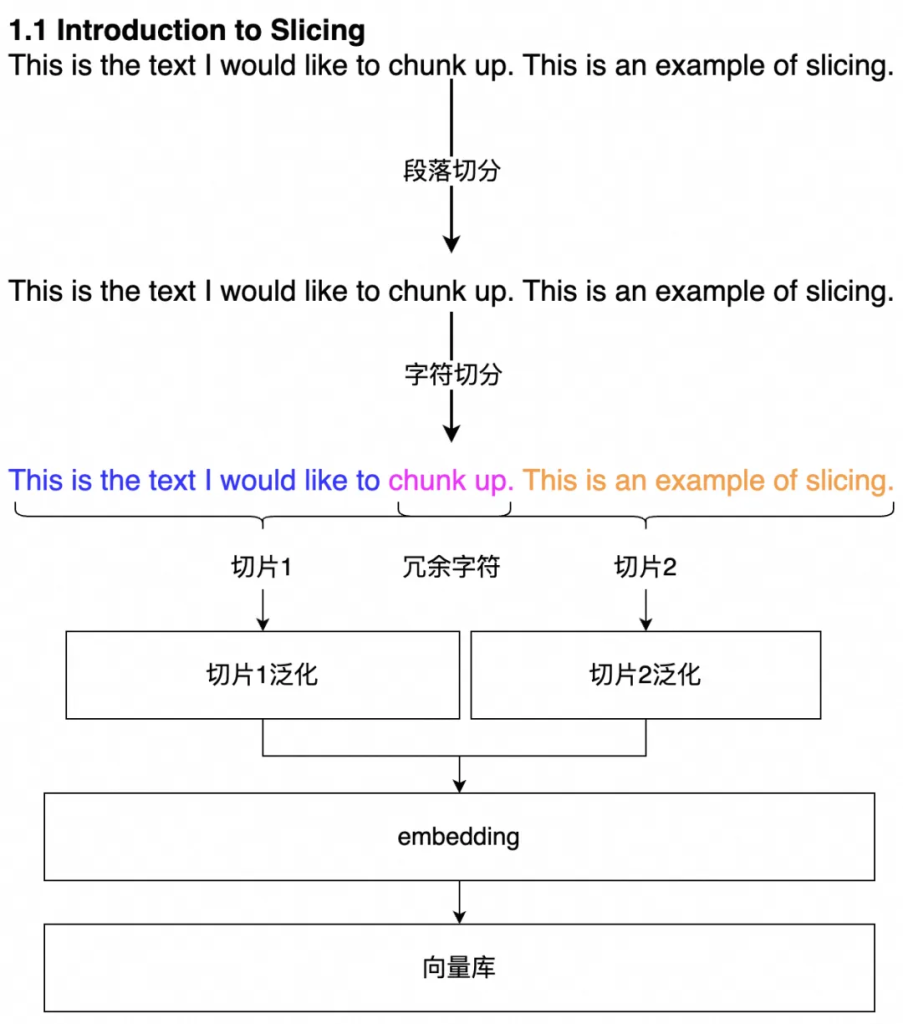
按固定字符切,有時候會遇到句子含義聯系比較緊密的片段被切分成了兩條數據,導致數據質量比較差。可以通過語義理解小模型進行句子拆分,使拆分出來的知識片段語義更加完整。
原始的文檔和用戶問題一對一匹配,會存在匹配容錯率低的問題,一旦知識一次沒匹配上,那就無法被召回。
優化方案
處理后的知識數據,為了提高知識的覆蓋范圍,可針對知識數據預先用大模型生成一些有關聯的假設性問題,當命中這些假設性問題時,也可搜索到相應的知識數據。
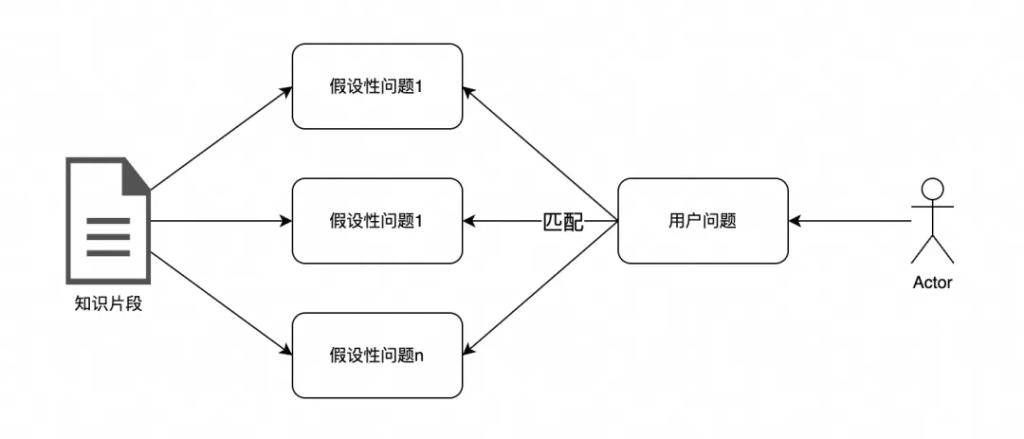
索引降噪主要根據業務特點,去除索引數據中的無效成分,突出其核心知識,降低噪音的干擾。針對QA-pair對和文章片段的知識,處理起來的方法也類似。
QA-pair對類型知識
這種數據一般會以Q作為索引列,與用戶的問題組成QQ搜索模式,這樣數據召回時匹配難度會低。如果使用原始的Q做索引,又會存在無效此干擾的問題,比如:
| 用戶query | 匹配到的query |
| How can I start to sell on Alibaba? | How can I register an account on Alibaba.com? |
句子中,無效的相似成分超過60%,這就會對索引匹配造成很大的干擾。
優化方案
通過大模型泛化向量索引中的Q,突出核心關鍵詞,并且把對應的Answer的主題利用大模型抽取,Q和A都突出關鍵詞。
How can I register an account on Alibaba.com? –> register an account. + Answer主題。
突出核心主題,降低無效數據的干擾。?
文章片段類知識
文章片段類知識,由于篇幅長,且在語義上與問題可能差異較大,導致無法很好的匹配。
優化方案
會通過HyDE生成假設性問題,然后組成QA-pair對的形式,然后再利用大模型抽取核心關鍵詞,用來降噪。
近似檢索和傳統數據庫檢索不同,近似檢索通過聚類或HNSW建立索引后,在檢索時,會有一定的近似誤差,如果在大量的知識庫中檢索,會產生檢索準確度和性能的問題,在大型數據庫的情況下,一種有效的方法是創建兩個索引——一個由摘要組成,另一個由文檔塊組成,并分兩步搜索,首先通過摘要過濾掉相關文檔,然后只在這個相關組內搜索。
直接使用原始query進行檢索,會存在以下幾個問題:
1)知識庫內的數據無法直接回答,需要組合知識才能找到答案。
2)涉及細節比較多的問題時,大模型往往無法進行高質量的回答。
業務提出了RAG-Fusion和Step-Back Prompting的兩種優化方案。
RAG-Fusion可以認為是MultiQueryRetriever的進化版,RAG-Fusion首先根據原始question從不同角度生成多個版本的新question,用以提升question的質量;然后針對每個question進行向量檢索,到此步為止都是MultiQueryRetriever的功能;與之不同的是,RAG-Fusion在喂給LLM生成答案之前增加了一個排序的步驟。
RAG-Fusion主要流程如下圖所示:
查詢生成/改寫:使用 LLM 模型對用戶的初始查詢,進行改寫生成多個查詢。
向量搜索:對每個生成的查詢進行基于向量的搜索,形成多路搜索召回。
倒數排序融合:應用倒數排名融合算法,根據文檔在多個查詢中的相關性重新排列文檔。
重排: 使用一些重排算法對結果進行重排。
輸出生成:然后可以參考重新排列后的topK搜索結果,生成最終輸出。
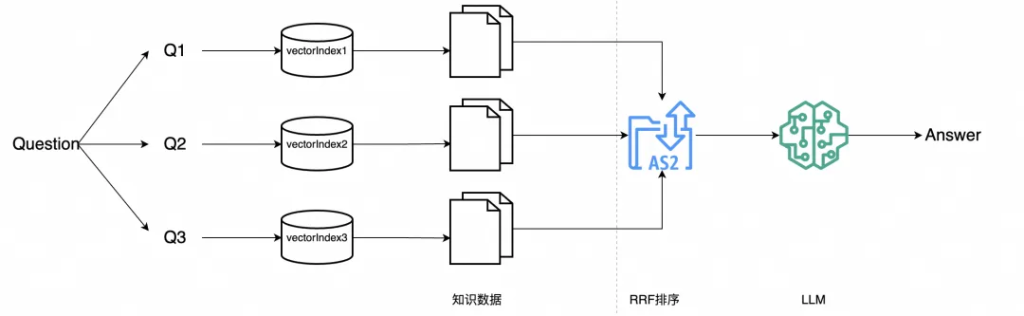
排序包含兩個動作,一是獨立對每個question檢索返回的內容根據相似度排序,確定每個返回chunk在各自候選集中的位置,相似度越高排名越靠前。二是對所有question返回的內容利用RRF(Reciprocal Rank Fusion)綜合排序。
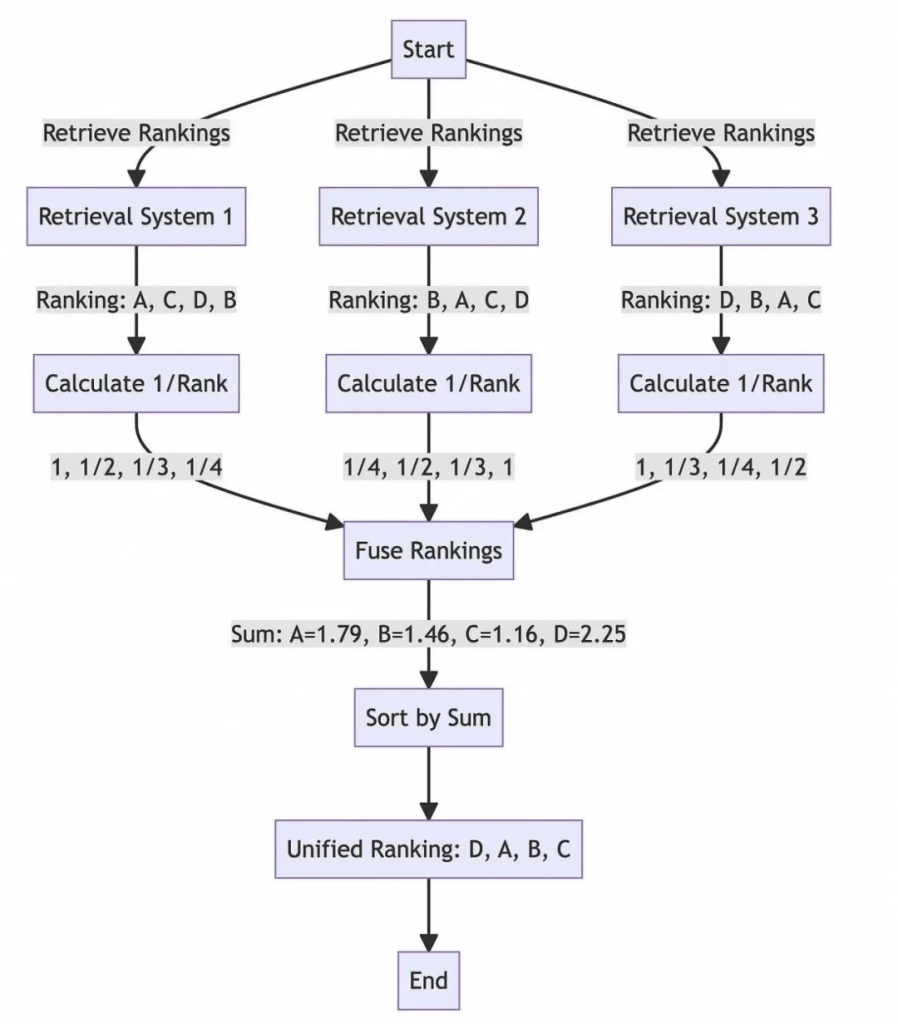
通過引入一個后退一步的問題,這個問題通常更容易回答,并且圍繞一個更廣泛的概念或原則,大型語言模型可以更有效地構建它們的推理。
Step-Back Prompting 過程典型的Step-Back Prompting過程主要包括兩個步驟:
1)抽象:這是指大型語言模型(LLM)不會立即嘗試回答原始問題。相反,它會提出一個關于更大的概念或規則的更一般性問題。這有助于它思考和查找事實。
2)推理:在得到一般問題的答案后,大型語言模型(LLM)使用這些信息來思考并回答原始問題。這被稱為“抽象基礎推理”。它利用來自更大觀點的信息來對原始的、更難的問題給出一個好的答案。
示例
比如問:如果一輛汽車以100公里/小時的速度行駛,行駛200公里,需要多長時間?
此時大模型對數學計算可能會比較迷茫。
后退提示:給定速度和距離,計算時間的基本公式是什么?
輸入:為了計算時間,我們使用以下公式:時間=距離/速度
使用公式,時間=200公里/100公里/小時=2小時。
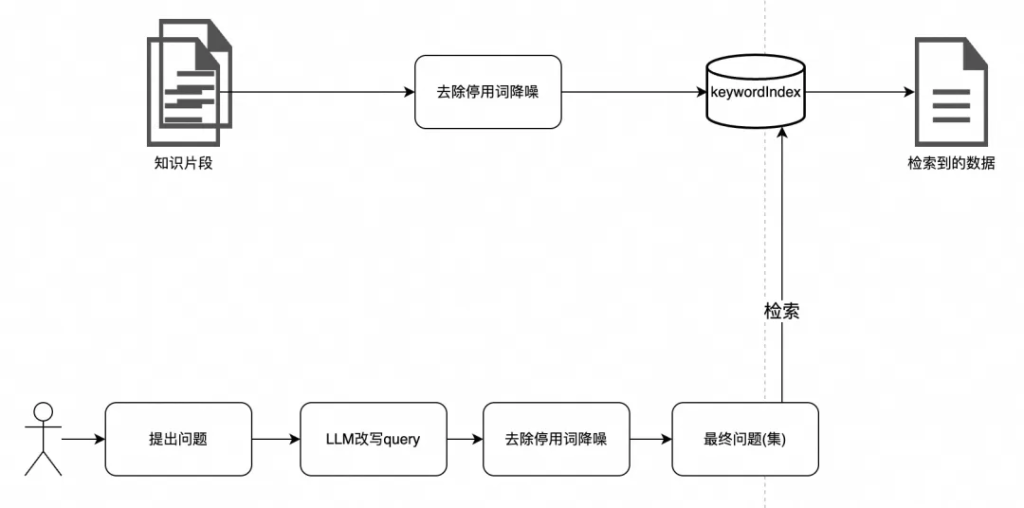
當用戶問一個問題時,有些停用詞是不起作用的,比如:How to register an account on Alibaba.com,在這個語境中,核心訴求是 register an account,至于How to在表達核心訴求時,意義沒那么大,其次,當下沉Alibaba的外貿業務時,on Alibaba.com也變得沒那么重要,因為Alibaba的外貿業務系統就是運行在Alibaba.com上,知識庫中的知識自然也是Alibaba.com相關的。
可以針對用戶問題,去除停用詞,比如ES中維護了一份停用詞庫,可直接使用。如果解決方案中沒有ES,也可自己維護停用詞庫,在nltk、stopwords-iso、Rank NL、Common Stop Words in Various Languages等開源庫中維護了大量的停用詞庫,可根據需要取用。
在NLP領域,向量召回一直處于無可替代的地位,把自然語言轉換成低緯度向量,基于向量的相似度來評判語義的相似程度,這也是業界比較流行的做法。再結合上面提到的向量索引的降噪、假設性性問題以及對用戶query的優化,一般都能取得比較不錯的成績。
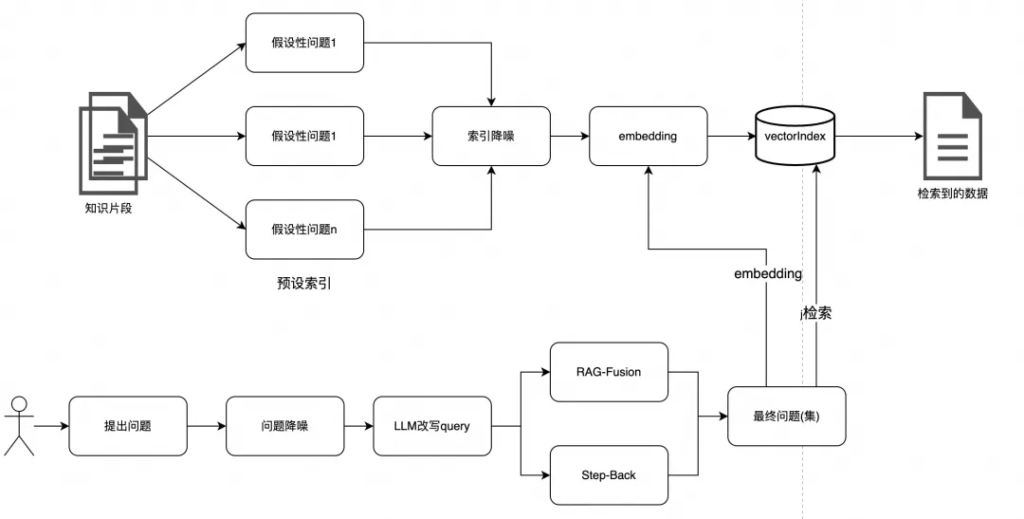
但單純的語義向量召回時,當文本向量化模型訓練不夠優時,向量召回的準確率會比較低,此時需要利用其他召回方式作為補充。
除了向量召回,常見的召回方式還有分詞召回以及圖譜召回。
傳統的倒排索引檢索,基于BM25打分排序機制,從而找到從分詞上比較相似的知識數據。結合上面提到的去除停用詞策略,以達到比較精準的程度。
知識圖譜在知識生產和關系提取上有著獨特的優勢,他能基于現有的數據,根據其關系的抽象,產生新的知識。
比如現在有兩條知識:1)阿里巴巴在國內采用A公司的物流服務。
2)阿里巴巴與物流公司B達成合作,為客戶提供更加優質、便捷的物流服務。
上面兩條知識經過 NL2Cypher抽取:alibaba-logisticsServices-A
alibaba-logisticsServices-B
基于這兩條知識,可產生一條新知識:alibaba-logisticsServices-A & B
當用戶問阿里巴巴平臺支持哪些物流服務時,可直接找到 A & B。
在NLP領域,單純的語義向量召回時,當文本向量化模型訓練不夠優時,向量召回的準確率會比較低,此時需要利用其他召回作為補充。一般業務會采用多路召回的方式,來達到比較好的召回效果,多路召回的結果經過模型精排,最終篩選出優質結果。至于使用幾種召回策略,根據業務而定。
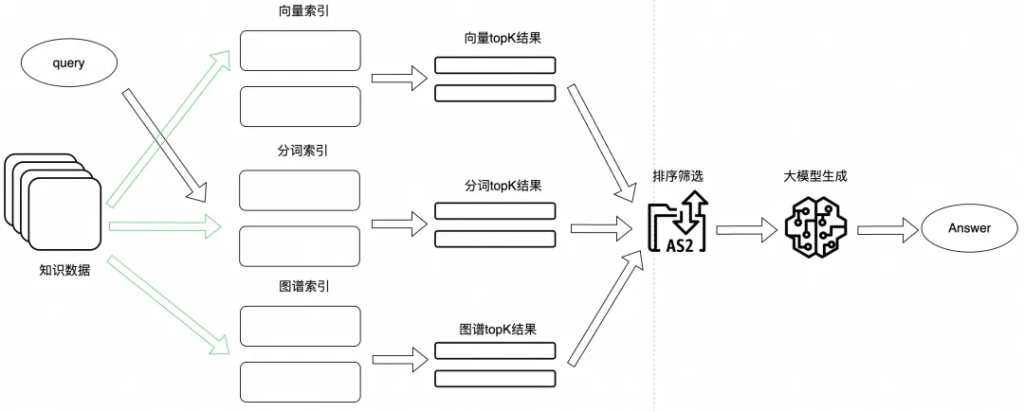
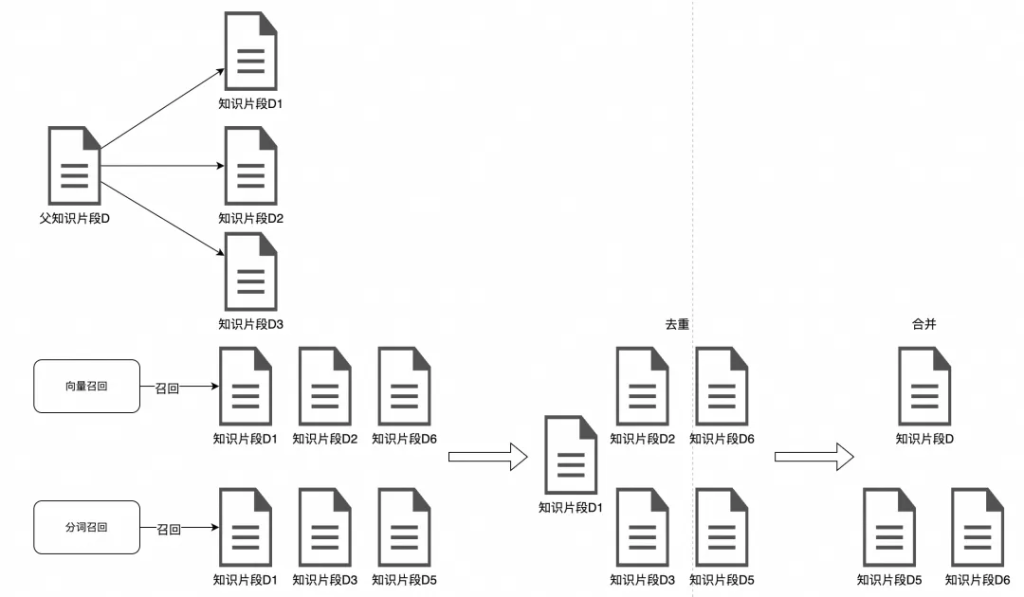
首先多路召回可能都會召回同一個結果,針對這部分數據要去重,否則對大模型輸入的token數是一種浪費。
其次,去重后的文檔可以根據數據切分的血緣關系,做文檔的合并。
比如檢索到的D1、D2、D3都來自同一個父知識片段D,則使用D替換D1、D2、D3,以保證有比較好的知識語義完整性。
每種召回策略的排序打分模型有差異,在最終統一的數據篩選層面,要有統一的評判標準。
目前,可用的重新排序模型并不多。一種選擇是Cohere提供的在線模型,可以通過API訪問。此外,還有一些開源模型,如bge-reranker-base和bge-reranker-large等,根據業務需要擇優選擇。
RAG想做出來比較容易,但想做好還是比較難的,每個步驟都有可能對最終效果產生影響。
我們在RAG中也做了大量的探索,比如:知識切分方面,做了固定字符切分的效果驗證,分析索引噪音點,利用大模型做了大量的降噪處理;在query改寫方面,利用大模型做了更加明確的意圖抽取,并對用戶的query進行降噪的探索;在數據召回方面,embedding模型基于bge、voyage和cohere做了大量的測評,探索向量+分詞的召回策略;
在后置處理優化上,做了知識的去重以及rerank的探索等。
RAG的發展會越來越迅速,只要知識依賴和知識更新的問題沒有得到解決,RAG就有其存在的價值和一席之地。
文章轉自微信公眾號@阿里云開發者







