
2024年您產品必備的10大AI API推薦
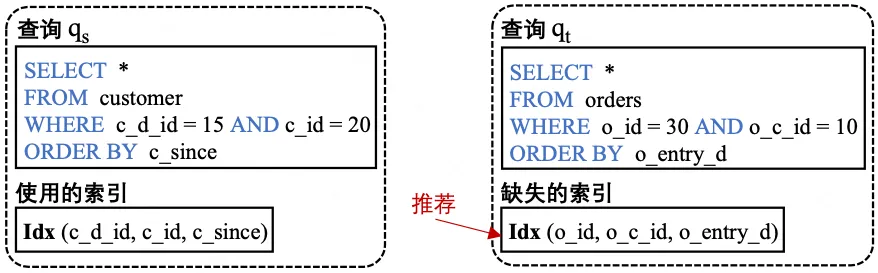
基于AI+數據驅動的索引推薦聚焦于Query級別的索引推薦,出發點是在某個數據庫中因為缺失索引導致的慢查詢,在其它數據庫中可能有相似的索引創建案例:這些查詢語句相似,因此在相似位置上的列創建索引也可能帶來類似的收益。例如下圖中,查詢和在語句結構和列類型上非常相似。因此,我們可以通過學習查詢的索引創建模式來為查詢 推薦缺失的索引。
對于不同列數的索引推薦,我們會分別訓練基于XGBoost的二分類模型。例如,我們目前最高支持三列的索引推薦,因此會分別訓練一個單列索引推薦模型、一個兩列索引推薦模型和一個三列索引推薦模型。對于給定的一個單列候選索引和它對應的慢查詢,我們使用單列索引推薦模型來判斷該單列候選索引是否能夠改善該慢查詢的性能。同樣的,對于給定的一個兩列(三列)候選索引和它對應的慢查詢,我們使用兩列(三列)索引推薦模型來判斷這個兩列(三列)候選索引是否能夠改善該慢查詢的性能。如果一條慢查詢中包含的候選索引個數為,那么則需要次模型預測來完成對這條慢查詢的索引推薦。
基于AI+數據驅動的索引推薦的整體架構如下圖所示,主要分為兩個部分:模型訓練和模型部署。
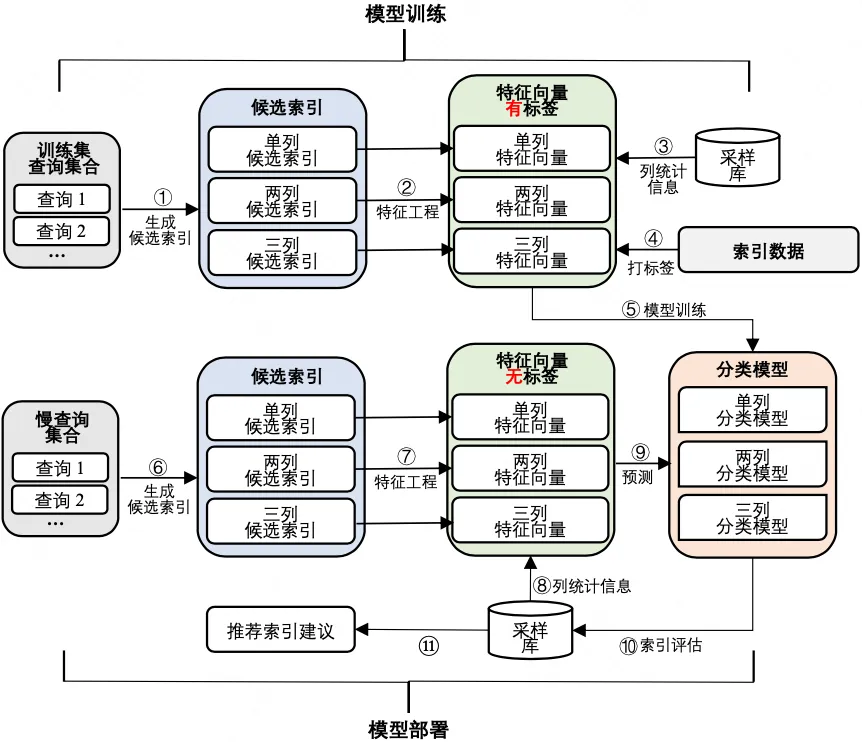
如上文所述,我們收集DAS平臺基于代價的慢查詢優化建議每天的索引推薦數據(包括慢查詢和被驗證有效的推薦索引)作為訓練數據。我們生成每條查詢的單列、兩列和三列候選索引,并通過特征工程來為每個候選索引構建特征向量,使用索引數據來為特征向量打標簽。之后,單列、兩列和三列特征向量將分別用于訓練單列、兩列和三列索引推薦模型。
針對需要推薦索引的慢查詢,我們同樣生成候選索引并構建特征向量。接下來,我們使用分類模型來預測特征向量的標簽,即預測出候選索引中的有效索引。隨后,我們在采樣庫上創建模型預測出的有效索引,并通過實際執行查詢來觀察建立索引前后查詢性能是否得到改善。只有當查詢性能真正得到改善時,我們才會將索引推薦給用戶。
我們提取查詢中出現在聚合函數、WHERE、JOIN、ORDER BY、GROUP BY這些關鍵詞中的列作為單列候選索引,并對這些單列候選索引進行排列組合來生成兩列和三列候選索引。同時,我們會獲取查詢所涉及的表中已經存在的索引,并將其從候選索引集合中刪除。這一步驟遵循索引的最左前綴原則:如果存在索引,那么候選索引 和 都將從候選索引集合中刪除。
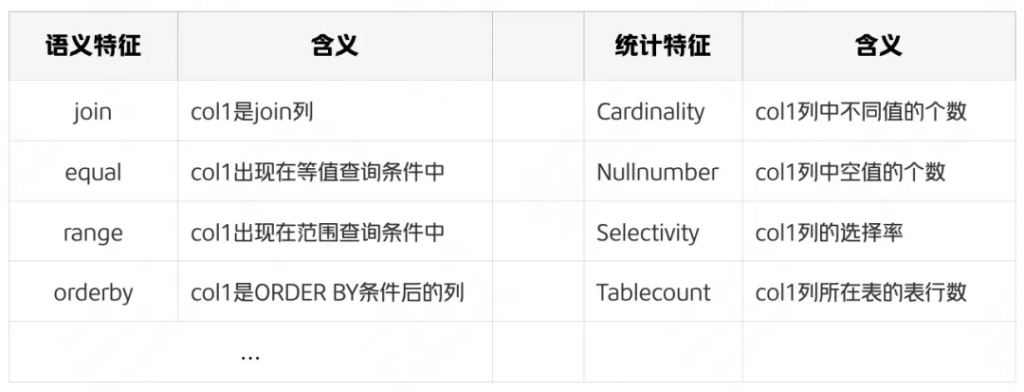
一個候選索引的特征向量包括語句特征和統計特征兩部分。語句特征描述了候選索引列在查詢中的出現位置(采用one-hot的編碼方式),統計特征描述了候選索引列的統計信息,如所在表的表行數、Cardinality值、選擇率等,這些是判斷是否需要在候選索引列上建立索引的重要指標。下表以單列候選索引 為例,展示了它的部分重要特征及其含義:
兩列候選索引 的特征是通過對單列候選索引 和 的特征進行拼接而成的,此外,我們還會計算 和 共同的Cardinality值作為兩列候選索引 的額外統計特征,以更加全面地描述其統計信息。同樣地,我們也會采用使用這種方式來構建三列候選索引 的特征。在生成完一條查詢的特征向量之后,我們使用這條查詢使用到的索引來為生成的特征向量打標簽。
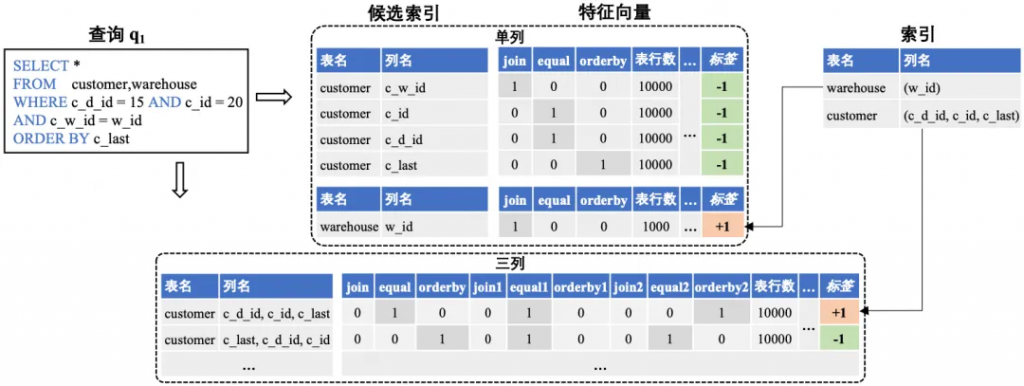
下圖以查詢 為例,展示我們為訓練集中的一條查詢生成特征向量并打標簽的過程。查詢 涉及兩張表customer表和warehouse表,其中customer表的c_w_id、c_id、c_d_id、c_last四列參與到查詢中,因此對應生成四條單列特征向量;warehouse表的w_id列參與到查詢中,因此只生成了一條單列特征向量。查詢 使用的單列索引為Idx(w_id),所以單列候選索引 (w_id) 對應的特征向量被標記為正樣本,其余特征向量則被標記為負樣本。接下來,我們對單列候選索引進行排列組合來生成多列候選索引及其特征向量。由于查詢 使用到的多列索引只有一個三列索引Idx(c_d_id, c_id, c_last),因此我們跳過生成兩列候選索引,只生成三列候選索引。這是因為我們是基于查詢使用到的索引來為特征向量打標簽的,如果查詢沒有使用到兩列索引,那么生成的所有兩列特征向量均為負樣本,這可能會導致訓練集正負樣本不均衡的問題。最后,基于查詢使用到的三列索引,我們將三列候選索引 (c_d_id, c_id, c_last) 對應的特征向量標記為正樣本。以上就是我們為查詢 生成特征向量并打標簽的整個過程,查詢 為單列索引推薦模型的訓練集貢獻了五條樣本(一條正樣本,四條負樣本),為三列索引推薦模型的訓練集貢獻了六條樣本(一條正樣本,五條負樣本)。
在為一條慢查詢推薦索引時,我們依次生成慢查詢中所有的單列、雙列和三列候選索引,并通過上述的特征工程來構造特征向量。然后,我們將特征向量輸入給對應的分類模型進行預測,并從三個分類模型的預測結果中分別挑選出一個預測概率最高的候選索引(即一個單列索引、一個兩列索引和一個三列索引)作為模型推薦的索引。
雖然推薦的索引越多,慢查詢的性能就越有可能得到改善,但是模型推薦的部分索引可能是無效的,這些無效索引帶來的存儲空間開銷和更新索引的開銷是不可忽視的。因此,直接將模型推薦的索引全部推薦給用戶是不合理的。為此,在將索引推薦給用戶之前,我們會首先將三個分類模型推薦的索引建立在采樣庫上進行驗證,采樣庫是線上數據庫的一個mini版本,它抽取了線上數據庫的部分數據。在采樣庫上,我們會觀察在建立推薦的索引之后,查詢的執行時間是否得到改善。如果得到改善,我們就把查詢使用到的一個或多個模型推薦的索引作為索引建議推薦給用戶。
正如前文所述,美團DAS平臺目前采用代價方法和AI模型并行為慢查詢推薦索引。具體來說,AI模型可以在某些場景下,彌補代價方法漏選或錯選推薦索引的問題。就在剛過去的3月份,在代價方法推薦索引的基礎上,AI模型有額外12.16%的推薦索引被用戶所采納。
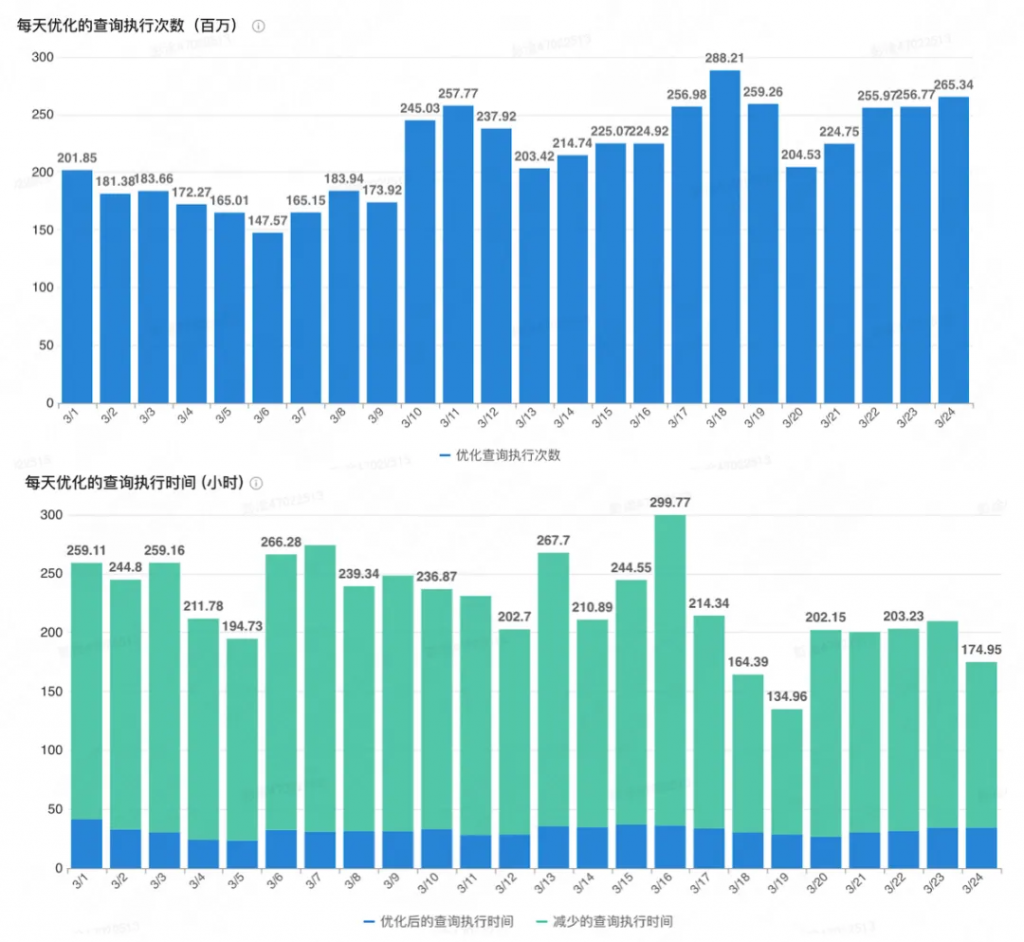
這些額外補充的索引對于查詢的改善情況如上圖所示:上半部分展示了優化的查詢執行次數,下半部分展示了查詢在使用推薦的索引之后的執行時間以及減少的執行時間,這些索引總計約優化了52億次的查詢執行,減少了4632小時的執行時間。
目前,大模型技術(如GPT-4)已經得到了越來越多的認可,幾乎可以勝任各種領域的任務。我們計劃嘗試通過Fine-Tune開源的大型語言模型(如Google開源的T5模型)來解決索引推薦的問題:輸入一條慢查詢,讓模型來生成針對慢查詢的索引建議。在推薦索引無法改善慢查詢的情況下,后續我們可以提供一些文本建議來幫助用戶優化SQL,比如減少返回不必要的列,使用JOIN代替子查詢等。
彭淦,美團基礎研發平臺工程師,主要負責美團數據庫自治服務DAS的SQL優化建議工作。
在這里特別感謝華東師范大學數據科學與工程學院的蔡鵬教授,教授在VLDB、ICDE、SIGIR、ACL等領域重要國際會議上發表多篇論文。目前的研究方向為內存事務處理,以及基于機器學習技術的自適應數據管理系統。本文也是美團數據庫研發中心跟蔡鵬教授展開科研合作后的具體實踐。美團科研合作致力于搭建美團技術團隊與高校、科研機構、智庫的合作橋梁和平臺,依托美團豐富的業務場景、數據資源和真實的產業問題,開放創新,匯聚向上的力量,圍繞機器人、人工智能、大數據、物聯網、無人駕駛、運籌優化等領域,共同探索前沿科技和產業焦點宏觀問題,促進產學研合作交流和成果轉化,推動優秀人才培養。面向未來,我們期待能與更多高校和科研院所的老師和同學們進行合作。歡迎老師和同學們發送郵件至:meituan.oi@meituan.com。
文章轉自微信公眾號@美團技術團隊







