GraphRAG:基于PolarDB+通義千問api+LangChain的知識圖譜定制實踐
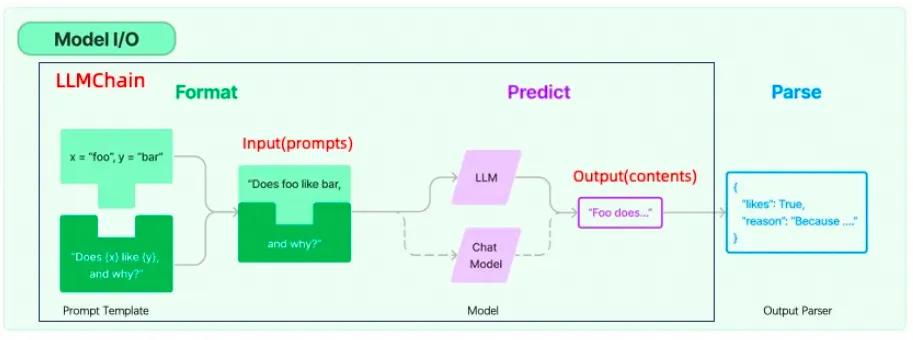
Models(模型)
這些模型是LangChain積木盒中的基礎積木。如同用樂高搭建房屋的地基,LLMs為構建復雜的語言理解和生成任務提供了堅實的基礎。
這些模型就像是為你的樂高小人制作對話能力。它們能夠讓應用程序進行流暢的對話,好比是給你的樂高積木人注入了會說話的靈魂。
如果說其他模型讓積木能夠理解和生成文本,文本嵌入模型則提供了理解文本深度含義的能力。它們就像是一種特殊的積木塊,可以幫助其他積木更好地理解每個塊應該放在哪里。
Prompts(提示)
想象一下,你正在給樂高小人編寫劇本,告訴他們在不同場景下應該說什么。Prompt Templates就是這些劇本,它們指導模型如何回答問題或者生成文本。
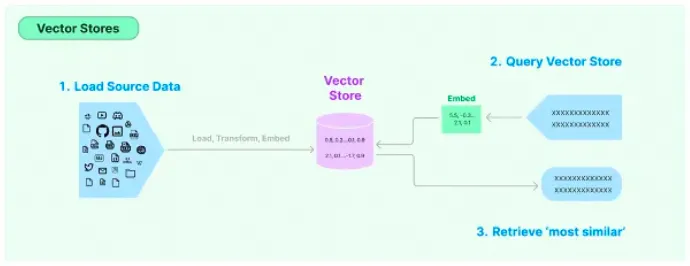
Indexes(索引)
LangChain通過Indexs索引允許文檔結構化,讓LLM更直接、更有效地與文檔互動。
這些就像是一個個小倉庫,幫助你的樂高世界中的智能模型存儲和訪問信息。Document Loaders能夠將文檔加載到系統中,方便模型快速查找。
有時候你需要將一大塊樂高板分成幾個小塊來構建更復雜的結構。Text Splitters可以將長篇文本拆分成易于處理的小塊。
這些是一種特殊的存儲設施,幫助你的樂高模型記住文本的數學表示(向量)。這就像是讓積木塊記住它們在整個結構中的位置。
想象一下你需要從一堆積木中找到一個特定的小部件。Retrievers能夠快速在向量存儲中檢索和提取信息,就像是樂高世界里的搜索引擎。??
Memory(記憶):對話的連貫性
LangChain通過Memory工具類為Agent和Chain提供了記憶功能,讓智能應用能夠記住前一次的交互,比如在聊天環境中這一點尤為重要。
最常見的一種對話內容中的Memory類,這就好比是在你的樂高角色之間建立了一個記憶網絡,使它們能夠記住過去的對話,這樣每次交流都能在之前的基礎上繼續,使得智能積木人能夠在每次對話中保持連貫性。
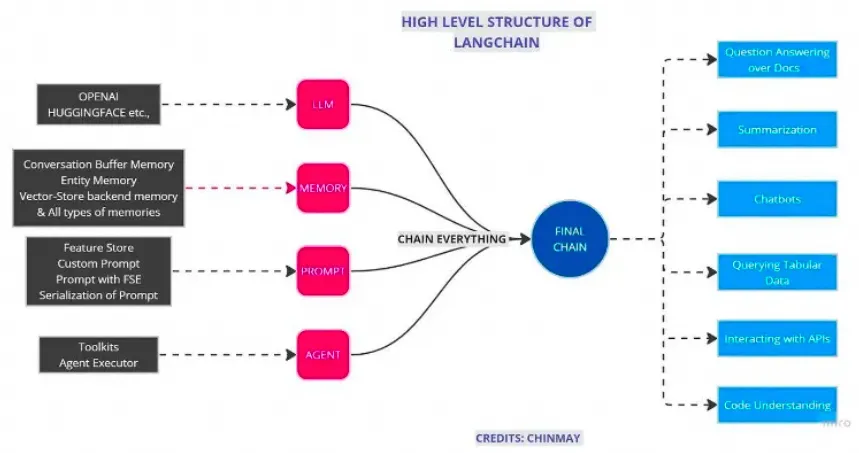
Chains(鏈)
CHAIN模塊整合了大型語言模型、向量數據庫、記憶系統及提示,通過Agents的能力拓展至各種工具,形成一個能夠互相合作的獨立模塊網絡。它不僅比大模型API更加高效,還增強了模型的各種應用,諸如問答、摘要編寫、表格分析和代碼理解等。
??
Chain是連接不同智能積木塊的基本方式,而LLM Chain是最簡單的LLM+Prompts的一種chain,專門用于鏈接語言模型。Index-related Chains則將索引功能集成進來,確保信息的高效流動。
Agents(代理)
在LangChain的世界里,Agent是一個智能代理,它的任務是聽取你的需求(用戶輸入)和分析當前的情境(應用場景),然后從它的工具箱(一系列可用工具)中選擇最合適的工具來執行操作。這些工具箱里裝的是LangChain提供的各種積木,比如Models、Prompts、Indexes等。
如下圖所示,Agent接受一個任務,使用LLM(大型語言模型)作為它的“大腦”或“思考工具”,通過這個大腦來決定為了達成目標需要執行什么操作。它就像是一個有戰略眼光的指揮官,不僅知道戰場上的每個小隊能做什么,還能指揮它們完成更復雜的任務。
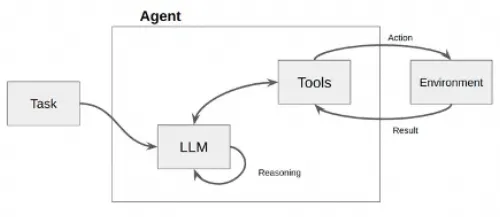
LangChain中Agent組件的架構圖如下,本質上也是基于Chain實現,但是它是一種特殊的Chain,這個Chain是對Action循環調用的過程,它使用的PromptTemplate主要是符合Agent Type要求的各種思考決策模版。Agent的核心思想在于使用LLM進行決策,選擇一系列要執行的動作,并以此驅動應用程序的核心邏輯。通過Toolkits中的一組特定工具,用戶可以設計特定用例的應用。
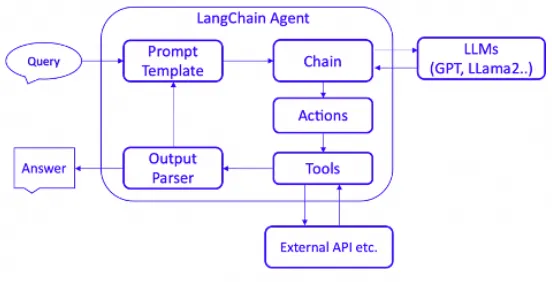
AgentExecuter負責迭代運行代理,直至滿足設定的停止條件,這使得Agent能夠像生物一樣循環處理信息和任務。
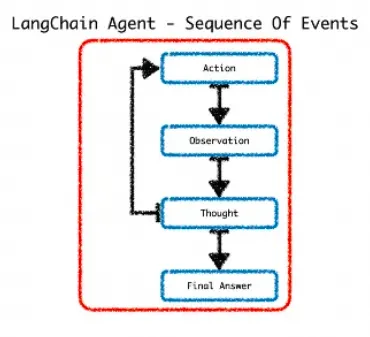
觀察(Observation)
在這個階段,代理通過其輸入接口接收外部的觸發,比如用戶的提問或系統發出的請求。代理對這些輸入進行解析,提取關鍵信息作為處理的基礎。觀察結果通常包括用戶的原始輸入或預處理后的數據。
在思考階段,代理使用預先設定的規則、知識庫或者利用機器學習模型來分析觀察到的信息。這個階段的目的是確定如何響應觀察到的情況。代理可能會評估不同的行動方案,預測它們的結果,并選擇最合適的答案或行為。
在LangChain中,這個過程可能涉及以下幾個子步驟:
1.理解用戶意圖:使用NLP(自然語言處理)技術來理解用戶的問題是什么。
2.推斷所需工具:確定哪個工具(或工具組合)能解決用戶的問題。
3.提取參數:提取所需工具運行的必要參數。這可能涉及文本解析、關鍵信息提取和驗證等過程。
根據思考階段的結果,代理將執行特定的行動。行動可能是提供答案、執行任務、調用工具或者與用戶進行進一步的交云。
在LangChain代理中,這通常涉及以下幾個子步驟:1.參數填充:將思考階段提取的參數填入對應的工具函數中。2.工具執行:運行工具,并獲取執行結果。這可能是查詢數據庫、運行算法、調用API等。3.響應生成:根據工具的執行結果構建代理的響應。響應可以是純文本消息、數據、圖像或其他格式。
4.輸出:將生成的響應輸出給用戶或系統。
代理類型決定了代理如何使用工具、處理輸入以及與用戶進行交互,就像給機器人挑選不同的大腦一樣,我們有很多種”智能代理”可以根據需要來選擇。有的代理是為聊天模型(接收消息,輸出消息)設計的,可以支持聊天歷史;有的代理更適合單一任務,是為大語言模型(接收字符串,輸出字符串)而設計的。而且,這些代理的能力也不盡相同:有的能記住你之前的對話(支持聊天歷史),有的能同時處理多個問題(支持并行函數調用),也有的只能專心做一件事(適用于單一任務)。此外,有些代理需要我們提供一些額外信息才能更好地工作(所需模型參數),而有些則可以直接上手,不需要額外的東西。所以,根據你的需求和你所使用的模型,你可以選擇最合適的代理來幫你完成任務,常見的代理類型如下:
| 智能代理類型 | 預期模型類型 | 支持聊天歷史 | 支持多輸入工具 | 支持并行函數調用 | 需要的模型參數 | 何時使用 | API參考 |
| OpenAI Tools | 聊天型 | ? | ? | ? | tools | 如果你使用的是較新的OpenAI模型(1106及以后) | ?Ref?[18] |
| OpenAI Functions | 聊天型 | ? | ? | functions | 如果你使用的是OpenAI模型,或者是經過微調以支持函數調用的開源模型,并且暴露與OpenAI相同的函數參數 | ?Ref?[19] | |
| XML | 大型語言模型 | ? | 如果你使用的是Anthropic模型,或者其他擅長XML的模型 | ?Ref?[20] | |||
| Structured Chat | 聊天型 | ? | ? | 如果你需要支持具有多個輸入的工具 | ?Ref?[21] | ||
| JSON Chat | 聊天型 | ? | 如果你使用的是擅長JSON的模型 | ?Ref?[22] | |||
| ReAct | 大型語言模型 | ? | 如果你使用的是簡單模型,推理觀察再行動 | ?Ref?[23] | |||
| Self Ask With Search | 大型語言模型 | 如果你使用的是簡單模型,并且只有一個搜索工具,追問+中間答案的技巧,who/when/how | ?Ref??[24] |
如果說Chain是LangChain中的基礎連接方式,那么Agent就是更高階的版本,它不僅可以綁定模板和LLM,還能夠根據具體情況添加或調整使用的工具。簡單來說,如果Chain是一條直線,那么Agent就是能夠在多個路口根據交通情況靈活選擇路線的專業司機。
使用LangChain處理人臉識別問題的排查
隨著人臉識別服務的線上線下日調用量和應用場景快速發展,人臉識別團隊正在面臨一個巨大的挑戰,每天反饋到團隊的各種識別問題的case過多,排查起來費時費力,為了快速診斷問題,團隊決定使用LangChain來構建一個智能排查助手。這個助手可以分析用戶問題,錯誤日志,與人臉識別的APIs進行交互,甚至生成修復建議。
在LangChain框架中,工具(Tools)是用于解決特定問題的可調用的功能模塊。它們可以是簡單的函數,也可以是更復雜的對象,能夠實現一項或多項特定任務。下面將詳細介紹幾種不同的工具定義及其在人臉識別問題排查過程中的應用。
首先,我們需要導入依賴的函數,主要來自各個現有日志系統的接口,能夠提取比對分,黑名單,讀取人臉庫大小等信息:
from face_functions import (
extract_compare_scores,
extract_local_group_size,
extract_actual_group_size,
perform_logic_judgement,
search_by_exact_query,
search_by_fuzzy_query,
blacklist
)當用戶遇到人臉比對失敗的情況時,人臉的日志系統都在zmng平臺上,我們現在通過zmng_query工具提取UID,根據UID查詢相關的用戶信息,包括他們是否在黑名單上,提取比對分數,并獲取機具端及實際的人臉庫大小信息,判斷是什么原因識別不通過。
# 定義 zmng_query 工具的具體實現函數
def zmng_query(uid):
# 實現查詢 zmng 平臺以獲取與 uid 相關的錯誤詳情
# 查詢可能包括黑名單狀態、比對分數和 groupSize
# 返回查詢結果
return "需要調用compare_scores_tool extract_local_group_size extract_actual_group_size blacklist_query perform_logic_judgement 這五個tool,用于問題的排查輸入"
# 創建 zmng_query 工具實例
zmng_query_tool = Tool(
name="zmng_query",
func=zmng_query,
description=(
"當用戶刷臉比對不通過,需要確認是否為黑名單或其他原因時使用此工具。"
"此工具能查詢黑名單狀態,提取比對分數,并獲取機具端及實際的groupSize信息,"
"以便于準確診斷比對失敗的原因。需要通過uid或zid進行查詢,"
"這是一個9位數編碼,能唯一識別一個人。使用此工具時,至少提供一個參數['uid']或['zid']。"
)
)這個工具用于從日志文件中提取比對分數,這對于診斷是人臉比對技術問題還是用戶本身的問題非常關鍵。
compare_scores_tool = Tool(
name="extract_compare_scores",
func=extract_compare_scores,
description=(
"當用戶刷臉比對不通過時,用于提取日志中的比對分數。"
)
)這兩個工具分別用于提取機具端和實際的人臉庫大小(groupSize)。這項信息有助于判斷是否所有必要的人臉數據都已經下發到機具端。
local_group_size_tool = Tool(
name="extract_local_group_size",
func=extract_local_group_size,
description=(
"當用戶刷臉比對不通過時,用于提取日志中機具端的人臉庫大小groupSize。"
)
)
actual_group_size_tool = Tool(
name="extract_actual_group_size",
func=extract_actual_group_size,
description=(
"當用戶刷臉比對不通過時,用于提取實際的人臉庫大小groupSize。"
)
)此工具用于查詢指定用戶是否在黑名單中,這是人臉識別系統中的一項常見檢查。
blacklist_query_tool = Tool(
name="blacklist_query",
func=blacklist,
description="查詢指定UID是否在黑名單中。"
)根據比對分數和本地庫與實際庫的大小,此工具能夠給出比對不通過的分析結論。
logic_judgement_tool = Tool(
name="perform_logic_judgement",
func=perform_logic_judgement,
description="根據比對分數和本地與實際庫的大小,給出比對不通過的分析結論。"
)在LangChain框架中,tools是一系列用于執行特定任務的函數或類的實例,它們可以被智能代理(Agent)調用以完成用戶請求。在提供的上下文中,需要用到的tool已經定義好了。
tools = [
compare_scores_tool, #"當用戶刷臉比對不通過時,用于提取日志中的比對分數。"
local_group_size_tool, #"當用戶刷臉比對不通過時,用于提取日志中機具端的人臉庫大小groupSize。"
actual_group_size_tool, #"當用戶刷臉比對不通過時,用于提取實際的人臉庫大小groupSize。"
blacklist_query_tool, #"查詢指定UID是否在黑名單中。"
zmng_query_tool
]將所有這些工具組裝到一個列表中,然后可以使用這個列表來初始化一個智能代理(Agent),該代理能夠運行工具并與用戶進行互動。在LangChain中,智能代理負責管理用戶的輸入,并決定調用哪個工具來處理特定的請求或問題。通過這種方式,我們可以構建一個強大的、能夠解決人臉識別相關問題的智能系統。
LangChain使用大型語言模型(LLM)如GPT-4來處理自然語言的理解和生成。在這里,我們創建一個聊天模型實例,這將允許我們的代理與用戶進行自然語言交互:
tools = [
compare_scores_tool, #"當用戶刷臉比對不通過時,用于提取日志中的比對分數。"
local_group_size_tool, #"當用戶刷臉比對不通過時,用于提取日志中機具端的人臉庫大小groupSize。"
actual_group_size_tool, #"當用戶刷臉比對不通過時,用于提取實際的人臉庫大小groupSize。"
blacklist_query_tool, #"查詢指定UID是否在黑名單中。"
zmng_query_tool
]temperature參數控制生成文本的創造性;較低的temperature值(例如0)將導致更確定性和一致性的響應。
一旦工具和聊天模型都被實例化,我們就可以初始化智能代理。在LangChain中,代理(Agent)是與用戶進行交云的主體,它使用上面定義好的tools和LLM來處理用戶的輸入并提供響應。
# 代理初始化,結合工具和聊天模型
agent = initialize_agent(tools, chat_model, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)現在,我們可以開始與用戶的交互:
print("您好,有什么能幫助您? (輸入 'exit' 結束對話)")
while True:
user_input = input("You: ")
if user_input.lower() in "exit", "goodbye", "quit":
print("再見!")
break
# 運行代理并獲取當前用戶輸入的響應
response = agent.run(user_input)
# 打印出代理的響應
print("Agent:", response)在這個交互式循環中,智能代理會根據用戶的輸入運行相應的工具,并使用聊天模型生成自然語言響應。這使得用戶可以以對話方式提出問題,并得到解答。
在LangChain框架中,智能代理(Agent)通常按照觀察(Observation)- 思考(Thought)- 行動(Action)的模式來處理任務。這個模型相當于一個決策循環,代理首先觀察外部輸入,然后進行內部思考以產生相應的行動方案。下面詳細解釋這個技術鏈路和邏輯:
#AgentExecutor的核心邏輯,偽代碼:
next_action = agent.get_action(...)
while next_action != AgentFinish:
observation = run(next_action)
next_action = agent.get_action(...,next_action, observation)
return next_action#實際AgentExecutor中的部分相關代碼:
for agent_action in actions:
if run_manager:
run_manager.on_agent_action(agent_action, color="green")
# Otherwise we lookup the tool
if agent_action.tool in name_to_tool_map:
tool = name_to_tool_map[agent_action.tool]
return_direct = tool.return_direct
color = color_mapping[agent_action.tool]
tool_run_kwargs = self.agent.tool_run_logging_kwargs()
if return_direct:
tool_run_kwargs["llm_prefix"] = ""
# We then call the tool on the tool input to get an observation
observation = tool.run(
agent_action.tool_input,
verbose=self.verbose,
color=color,
callbacks=run_manager.get_child() if run_manager else None,
**tool_run_kwargs,
)我們構建了一個關于人臉識別的問答智能代理,用戶詢問:“為什么我的臉無法被系統識別?”以下是這個代理按照Observation-Thought-Action模式處理此請求的過程:
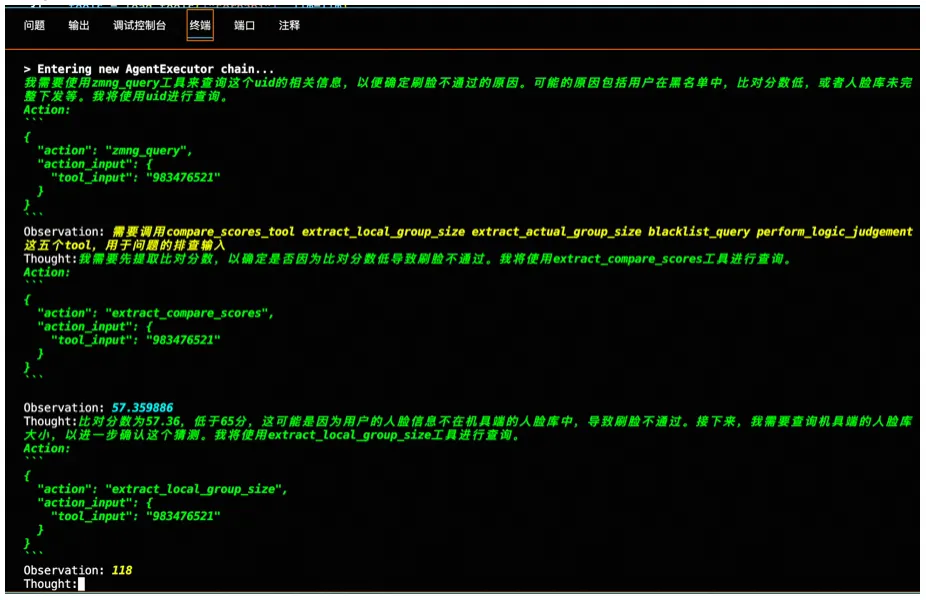
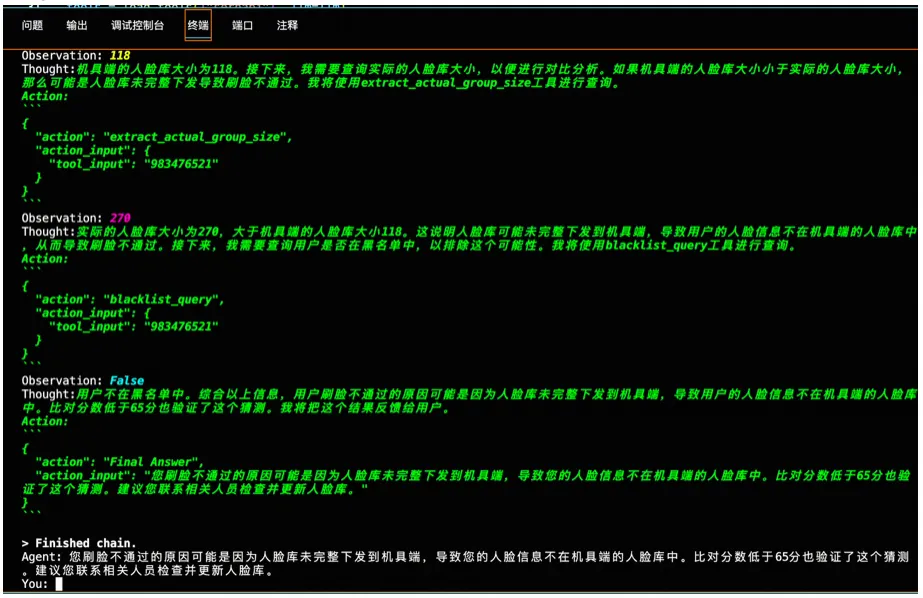
利用LangChain與人臉問答知識庫進行交互下面這些技術模塊共同構成了一個基于LangChain與人臉知識庫進行交互的系統。
下面這些技術模塊共同構成了一個基于LangChain與人臉知識庫進行交互的系統。
這個模塊負責讀取問題和答案對,并將它們存儲在一個字典結構中,以便后續檢索。
def load_qa_data(filepath):
qa_data = {}
with open(filepath, 'r', encoding='utf-8') as file:
lines = file.readlines()
current_question = None
answer_lines = [] # 用于累積多行答案的列表
for line in lines:
if line.startswith('問題: '):
if current_question:
# 將之前問題的答案存儲到字典中
qa_data[current_question] = ' '.join(answer_lines).strip()
# 去除"問題: "部分,并去除兩端空白字符
current_question = line[len('問題: '):].strip()
answer_lines = [] # 為新的問題重置答案行列表
elif current_question:
# 這是一個答案的一部分,可能不是第一行
answer_lines.append(line.strip())
# 不要忘記處理文件中的最后一個問題
if current_question and answer_lines:
qa_data[current_question] = ' '.join(answer_lines).strip()
return qa_dataFaiss 是 Facebook AI Research (FAIR) 精心打造的一款強大向量數據庫,專為高效執行相似性搜索和稠密向量聚類而設計。在處理大型數據集時表現尤為出色,能迅速在海量向量中鎖定與查詢向量最為匹配的項,極大地加速了搜索流程。無論是機器學習還是數據挖掘,Faiss 都是一個不可或缺的工具,常見的應用場景包括但不限于推薦系統、圖像搜索和自然語言處理。除了 Faiss,LangChain 支持的向量數據庫范圍廣泛,覆蓋了多種語言和平臺。這些數據庫包括阿里云的 OpenSearch、AnalyticDB、Annoy、Atlas、AwaDB,以及 Azure Cognitive Search、BagelDB、Cassandra、Chroma、Clarifai 等。此外,還有 ClickHouse Vector Search、Activeloop’s Deep Lake、Dingo,以及各種DocArray搜索能力,如DocArrayHnswSearch和DocArrayInMemorySearch。ElasticSearch、Hologres、LanceDB、Marqo、MatchingEngine、Meilisearch、Milvus、MongoDB Atlas 和 MyScale 也在支持之列。OpenSearch 和 pg_embedding 也提供了優質的搜索服務。這些多樣化的數據庫選擇使得LangChain能夠在不同的環境和需求下提供靈活、高效的搜索能力。
embeddings_model = OpenAIEmbeddings()這一行創建了一個OpenAIEmbeddings實例,它是用來生成文本embedding的。這些embedding是高維向量,可以捕捉文本內容的語義信息,用于文本之間的相似性比較。
#創建FAISS索引
def create_faiss_index(embedding_matrix):
dimension = embedding_matrix.shape[1] # 獲取向量的維度
index = faiss.IndexFlatL2(dimension) # 創建基于L2距離的FAISS索引
index.add(embedding_matrix.astype(np.float32)) # 向索引中添加向量
return indexcreate_faiss_index函數接受一個embedding矩陣(通常是二維數組,其中每行是一個向量),初始化一個FAISS索引,并將這些向量添加到索引中。這個索引后續將用于相似性搜索。
def search_faiss_index(query_embedding, index):
query_embedding = np.array(query_embedding).astype(np.float32) # 確保查詢向量為float32類型
_, indices = index.search(np.array([query_embedding]), 1) # 在索引中搜索最相似的向量
return indices[0][0] # 返回最相似向量的索引與查詢向量最相似的存儲向量。函數返回最相似項的索引,這通常用來在一個數據庫或列表中檢索具體項。
當用戶提出一個特定的問題時,這個功能會根據用戶的輸入在知識庫中查找精確匹配的問題。
def search_by_exact_query(user_query):
# 從文件加載問題和答案
qa_data = load_qa_data(filepath)
# 獲取答案并打印
return(get_answer(qa_data, user_query))這個模塊使用嵌入向量和Faiss索引來找到與用戶查詢最相似的問題,并返回相應的答案。1.初始化文本嵌入模型。2.使用文本嵌入模型將文本轉換為向量。3.使用這些嵌入向量創建FAISS索引。4.當用戶提出查詢時,將查詢文本也轉換為嵌入向量。5.使用FAISS索引找到最相似的嵌入向量。
def search_by_fuzzy_query(user_query):
# 從文件加載問題和答案
qa_data = load_qa_data(filepath)
# Get embedding vectors for all questions and convert to numpy array
questions = list(qa_data.keys())
question_embeddings_list = embeddings_model.embed_documents(questions)
question_embeddings = np.array(question_embeddings_list)
# Create the faiss index
faiss_index = create_faiss_index(question_embeddings)
# # Prompt user for a query and process
user_query_embedding_list = embeddings_model.embed_documents([user_query])
user_query_embedding = np.array(user_query_embedding_list[0])
# Search the faiss index for the most similar question
closest_question_index = search_faiss_index(user_query_embedding, faiss_index)
closest_question = questions[closest_question_index]
# Print the closest question's answer
return(qa_data[closest_question])在tools列表中,增加search_by_exact 和 search_by_fuzzy 兩個工具能力,其他邏輯不變。
tools = [
Tool(
name="search_by_exact",
func=search_by_exact_query,
description="當需要準確回答用戶問題時使用此工具。使用時需提供參數['query']。如果查詢為錯誤代碼,直接查詢并返回對應的錯誤原因和解決方法;如果觀察結果顯示有必要或可選發送郵件,請調用send_email工具。"
),
Tool(
name="search_by_fuzzy",
func=search_by_fuzzy_query,
description="當需要回答用戶問題時使用此工具。使用時需提供參數['query']。如果查詢為錯誤代碼,直接查詢并返回對應的錯誤原因和解決方法;如果查詢非錯誤代碼,可咨詢此工具相關解決方案;如果觀察結果顯示有必要或可選發送郵件,請調用send_email工具。"
),
send_email_tool, # Assuming definition is provided elsewhere
compare_scores_tool,
local_group_size_tool,
actual_group_size_tool,
blacklist_query_tool,
zmng_query_tool
]通過LangChain的靈活性和模塊化,這個能夠自動化處理人臉識別問題的智能排查助手,大大提高了問題診斷的效率并減輕了人工負擔。注意觀察下面agent的Observation Thought Action三個階段,agent會自動提取出tool需要的參數,形成action:
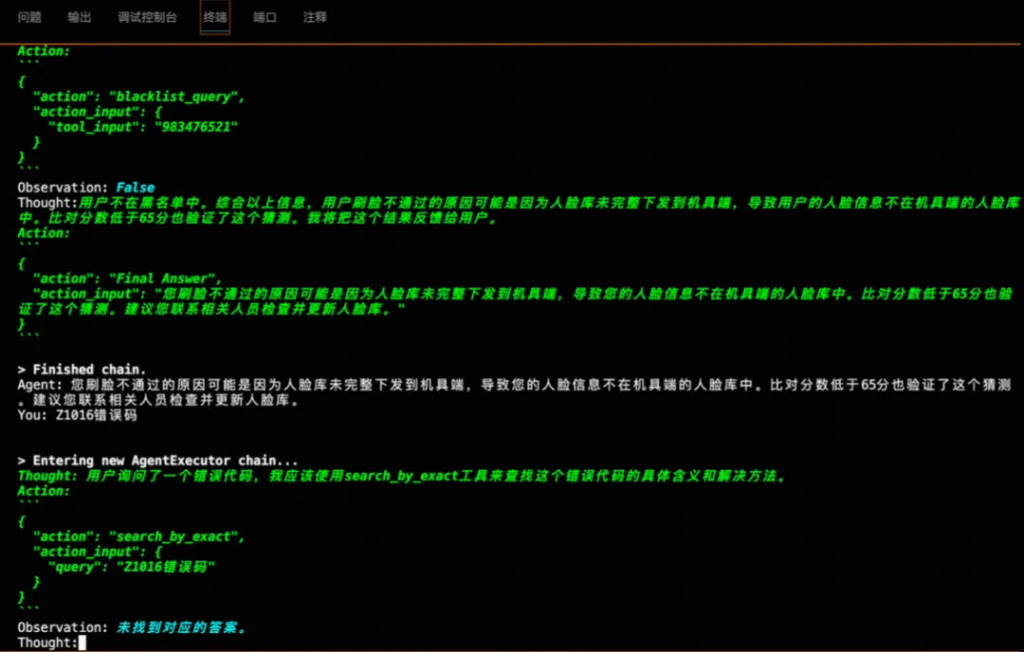

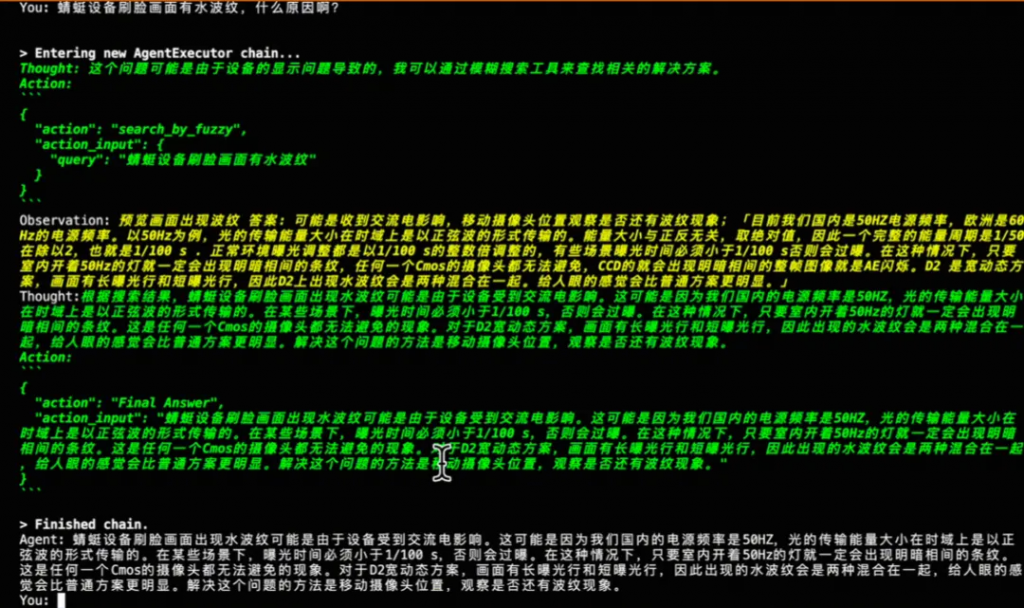
一句話總結,Langchain這個開發框架,是為了讓我們更容易更低成本的構建大語言模型的智能應用,其中有自主行動能力,能夠思考跟外部環境/工具交互的叫Agent,智能體。
AI Agent業界定義是具有環境感知、決策制定和行動執行能力的智能實體,并且能夠通過獨立思考和工具調用來逐步實現既定目標。隨著大型語言模型(LLM)的出現,AI Agent又被定義為基于LLM驅動的Agent實現對通用問題的自動化處理。當AI Agent被賦予一個目標時,它能獨立地進行思考和行動,詳細規劃出完成任務所需的每一個步驟,并通過外部反饋與自我思考來創建解決問題的prompt。例如,當要求ChatGPT購買咖啡時,它可能會回應“無法購買咖啡,因為它僅是一個文字型AI助手”。AI Agent的關鍵特征包括自治性、知覺、反應能力、推理與決策能力、學習能力、通信能力以及目標導向性,這些特性使得智能體能成為真正釋放LLM潛能的關鍵,它能為LLM核心提供強大的行動能力。
智能體(AI Agent)的發展可謂是人工智能領域的一個重要里程碑。大語言模型不再局限于處理文本信息,它們的能力正在擴展到與世界各種軟件工具的直接交互中。通過調用APIs,這些模型現在可以獲取信息、執行分析、生成報告、發送通知,甚至訪問網絡,訪問數據庫,使其功能變得無比強大。這種變化,讓這些模型從單純的文本處理者轉變為真正的數字助理,能夠理解用戶的需求,并使用正確的工具為用戶提供服務。
隨著技術的發展,大語言模型使用工具能力與日俱增。早期的模型可能需要明確的、結構化的指令才能正確調用幾十個工具,而現在,部分模型可以根據目標自由的調用上萬個工具,并采取相應的行動。想象一下,僅通過簡單的對話,你的智能代理就能為你預訂餐廳、安排行程、購物,甚至編程。這種靈活性和智能度的提升,極大地增強了用戶的體驗。
另一個領域的進步是智能體正在從單一的智能代理到多代理系統的轉變。初期,一個代理只能單一地執行任務,而現在,多個代理能夠同時工作,協同完成更加復雜的任務。例如,一個代理可以負責數據收集,而另一個代理同時進行數據分析,第三個代理則負責與用戶溝通結果。這些代理之間的協同工作像是一個高效的團隊,每個成員都在其擅長的領域發揮作用。
同時,智能代理與人類用戶之間交互也在往更自然化的方向發展,多代理系統工作過程中,可以引入人類的決策。這種人機交互的深度,使得智能代理不僅是工具的操作者,更是人類的合作者。
正是這些技術進步,塑造了我們今天所見證的智能體技術景觀,大語言模型在工具使用能力上的顯著提升以及智能代理的發展,為未來的可能性打下了堅實的基礎。全球范圍內,新興的智能體技術如OpenAI的WebGPT為模型賦予了利用網頁信息的能力,Adept培養的ACT-1能獨立于網站操作并使用Excel、Salesforce等軟件,谷歌的PaLM項目旗下的SayCan和PaLM-E嘗試將LLM與機器人相結合,Meta的Toolformer探索使LLM能夠自主調用API,而普林斯頓的Shunyu Yao所做的ReAct工作則結合了思維鏈prompting技術和“手臂”概念,使LLM能夠搜索并利用維基百科信息。隨著這些技術的不斷完善和創新,我們有望完成更多曾經難以想象的任務,開啟智能體技術的嶄新篇章。
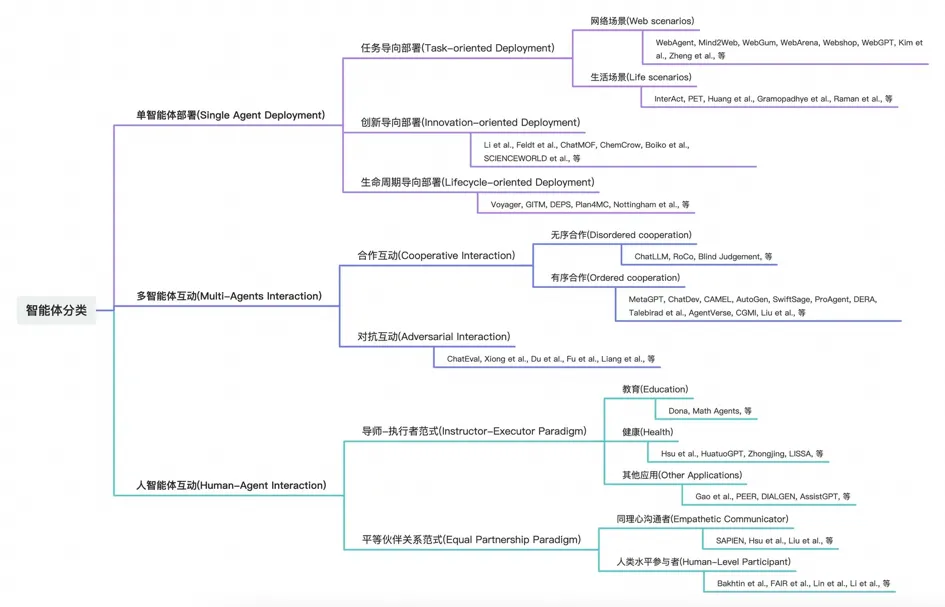
增強智能體的工具使用能力
智能代理和工具之間的關系可以類比為人類使用工具來完成任務的方式。就像人類使用錘子敲打釘子一樣,代理可以調用一個API來獲取數據、使用翻譯服務來翻譯文本或者執行其他功能以協助或完成它們的任務。通過增強代理的工具使用能力,它們能夠執行更復雜、更精細的任務,并在更廣泛的場景中提供幫助。
最近一些開源的大語言模型能夠自由地與各種外部工具交互,比如Toolformer、Gorilla、ToolLLama等模型,它們是一類設計為優化和改進代理工具使用能力的模型,使代理更有效地與工具集成,完成任務,從而擴展LLMs的能力范圍。
Gorilla是一個基于檢索感知的LLaMA-7B大型語言模型,也是一種基礎的智能體,它能夠使用各種API工具。這個模型通過分析自然語言查詢,精準地找出并調用合適、語義語法均正確的API,從而提升了大型語言模型執行任務的能力和準確性。
Gorilla的一個主要特點是它能夠準確地調用超過1600個API,并且這個數量還在增長。這一成就展示了如何利用語言模型的理解和生成能力,來擴展其在自動化工具使用上的潛力。為了進一步提高Gorilla的性能,開發團隊通過模擬聊天式對話,對LLaMA-7B模型進行了微調,讓其能夠更自然地與用戶進行交流,并生成相應的API調用。
此外,Gorilla也能夠處理帶有約束條件的API調用,這要求模型除了理解API的基本功能外,還必須能夠識別和考慮各種參數約束。這一能力讓Gorilla在處理特定要求的任務時顯得更加智能和可靠。
在訓練過程中,Gorilla不僅在無檢索器的情況下學習,還在有檢索器的環境中進行訓練,以提升其適應和理解不斷更新的API文檔的能力。這種訓練方式使得Gorilla不僅能響應用戶的直接指令,還能夠針對檢索到的相關API文檔生成精確的調用指令,減少了錯誤幻覺的發生。
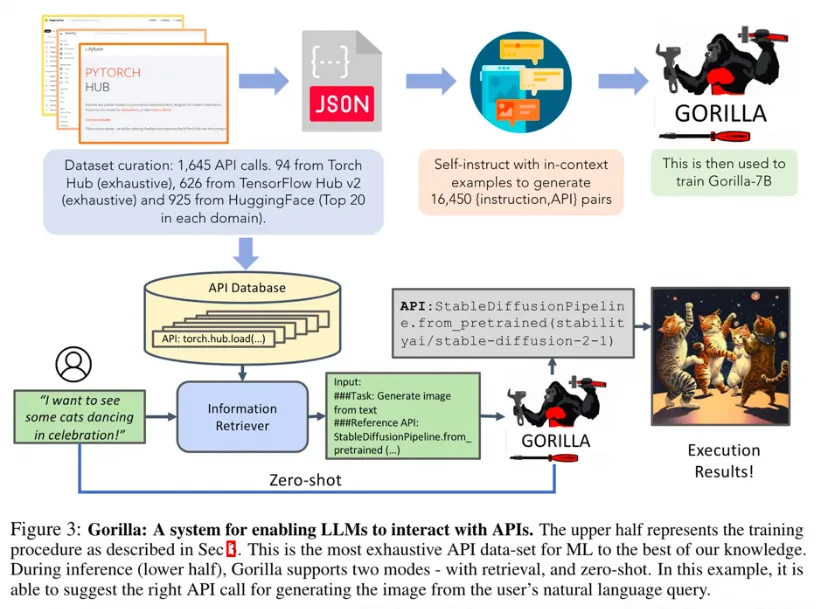
總的來說,Gorilla不僅增強了語言模型在API調用和工具使用上的能力,還提高了處理帶約束任務的復雜性,展現了智能體在自動化和人機交互方面的巨大潛力。
Gorilla-CLI是一個由加州大學伯克利分校開發,基于Gorilla模型的提升命令行交互體驗的工具,它通過智能化的命令預測和補全,使得命令行操作更加直觀和高效。當開發者在終端中輸入命令時,Gorilla-CLI能夠根據上下文提示可能的命令補全,甚至可以根據過去的操作模式預測下一步可能的命令,從而加速開發流程。https://github.com/gorilla-llm/gorilla-cli?
安裝步驟:
#通過pip安裝Gorilla CLI
pip install gorilla-cli
# Gorilla命令生成示例
$ gorilla 從當前目錄下找到qa.txt文件
# 命令建議:
find . -name "qa.txt"
# Gorilla命令生成示例
$ gorilla 統計qa.txt文件中有多少個問題?
# Gorilla命令生成示例
$ gorilla 把qa.txt中的問題單獨寫到一個新的文件中
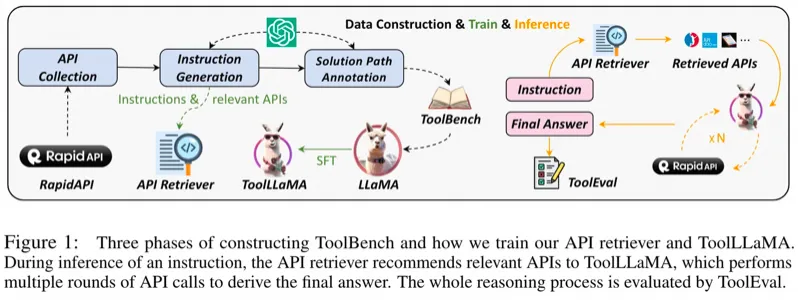
ToolLLaMA也是一個基于開源LLaMA-7B語言模型的框架,旨在增強模型執行復雜任務的能力,特別是遵循指令使用外部工具API。通過擴展傳統LLMs的功能,ToolLLaMA可以處理真實世界的應用場景,這些場景需要結合多個API工具來完成任務。(gorilla5月份剛發布, ToolLLaMa 8月份就緊跟著發布了)
ToolLLaMA的關鍵特點在于支持大量的真實世界API,共16464個,覆蓋49個類別。這種豐富的API支持為用戶提供了更多的工具選項,以滿足各種應用需求。ToolLLaMA使用ChatGPT生成的指令調整數據集ToolBench,這些數據集包含單工具和多工具使用場景的指令,使得模型能夠學習如何解析和執行包含多個API調用的指令。
為了提高在這些復雜任務中的效率,ToolLLaMA采用了DFSDT算法,它是一種基于深度優先搜索的決策樹,能夠幫助模型在多個潛在解決方案中做出更好的選擇。此算法增強了模型規劃任務路徑和推理的能力。
ToolLLaMA訓練了一個API檢索器,能夠為給定的用戶指令推薦合適的API,從而省去了手動篩選API的步驟,使得整個使用流程更加高效。
在性能評估方面,ToolEval結果表明,ToolLLaMA在執行復雜指令及泛化到未見APIs方面的效果與封閉源碼的高級模型ChatGPT相似。這一發現表明,通過適當的訓練方法和數據集,開源LLMs能夠實現類似于封閉源碼LLMs的工具使用能力。ToolLLaMA項目的代碼、訓練模型和演示都已在GitHub公開,以促進社區的進一步發展和應用。
總體而言,ToolLLaMA不僅在API支持數量上超越了類似Gorilla的模型,更在任務規劃、API檢索和泛化能力上提供了新的優勢,這些都是推動開源LLMs在復雜應用場景中應用的重要因素。https://github.com/OpenBMB/ToolBench?
安裝步驟:
#克隆這個倉庫并導航到ToolBench文件夾。
git clone git@github.com:OpenBMB/ToolBench.git
cd ToolBench
#安裝包(python>=3.9)
pip install -r requirements.txt
#或者只為ToolEval安裝
pip install -r toolbench/tooleval/requirements.txt
#使用我們的RapidAPI服務器進行推理
#請首先填寫表單,審核后我們會發送給您toolbench密鑰。然后準備您的toolbench密鑰:
export TOOLBENCH_KEY="your_toolbench_key"
#對于ToolLLaMA,要使用ToolLLaMA進行推理,請運行以下命令:
export PYTHONPATH=./
python toolbench/inference/qa_pipeline.py \
--tool_root_dir data/toolenv/tools/ \
--backbone_model toolllama \
--model_path ToolBench/ToolLLaMA-7b \
--max_observation_length 1024 \
--observ_compress_method truncate \
--method DFS_woFilter_w2 \
--input_query_file data/test_instruction/G1_instruction.json \
--output_answer_file toolllama_dfs_inference_result \
--toolbench_key $TOOLBENCH_KEY
#如果想要嘗試自己訓練,參考下面的流程
#準備數據和工具環境:
wget --no-check-certificate 'https://drive.google.com/uc?export=download&id=1XFjDxVZdUY7TXYF2yvzx3pJlS2fy78jk&confirm=yes' -O data.zip
unzip data.zip 數據預處理,以G1_answer為例:
export PYTHONPATH=./
python preprocess/preprocess_toolllama_data.py \
--tool_data_dir data/answer/G1_answer \
--method DFS_woFilter_w2 \
--output_file data/answer/toolllama_G1_dfs.json
#訓練代碼基于FastChat。您可以使用以下命令使用我們的預處理數據data/toolllama_G123_dfs_train.json來訓練2 x A100(80GB)的ToolLLaMA-7b的lora版本。對于預處理的細節,我們分別將G1、G2和G3數據分割成訓練、評估和測試部分,并在我們的主要實驗中合并訓練數據進行訓練:
export PYTHONPATH=./
deepspeed --master_port=20001 toolbench/train/train_lora.py \
--model_name_or_path huggyllama/llama-7b \
--data_path data/toolllama_G123_dfs_train.json \
--eval_data_path data/toolllama_G123_dfs_eval.json \
--conv_template tool-llama-single-round \
--bf16 True \
--output_dir toolllama_lora \
--num_train_epochs 5 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 2 \
--evaluation_strategy "epoch" \
--prediction_loss_only \
--save_strategy "epoch" \
--save_total_limit 8 \
--learning_rate 5e-5 \
--weight_decay 0. \
--warmup_ratio 0.04 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--source_model_max_length 2048 \
--model_max_length 8192 \
--gradient_checkpointing True \
--lazy_preprocess True \
--deepspeed ds_configs/stage2.json \
--report_to none如果你正在計劃一個給最好朋友的驚喜派對,并希望為每位參加聚會的人提供一些鼓舞人心的話語,那么可以使用toolLLama這樣的語言模型,它能夠讓你輕松地調用一個工具來生成或查找各種名人的勵志名言,特別是關于愛情、夢想和成功的話語。例如,其中一個例子返回了:“成功不是終點,失敗也不是致命的:真正重要的是繼續前進的勇氣。”–丘吉爾
智能體的發展:從單任務到多代理協同與人代理交互
隨著人工智能技術的不斷進化,我們見證了智能體(AI Agent)的發展:從只能執行單一任務的簡單代理,到如今能夠進行多代理協同與人類代理交互的復雜系統。這種進步不僅拓寬了智能應用的邊界,使其能夠在更加復雜的環境中同時處理多種任務,還提升了與用戶合作的能力,共同做出更加精細化的決策。
我們正步入一個新紀元,其中最新的開源大型語言模型(LLMs)能夠自由地與多樣化的外部工具交互,完成更加豐富和復雜的任務。這不僅推動了AI技術的民主化,還為社區驅動的創新和發展打開了新的大門。
盡管LLMs的智能和精準的提示輸入提供了巨大優勢,但有效利用這些模型仍然需要用戶掌握相應的技巧,這已導致培訓市場的出現。然而,prompt工程的復雜性也對普通用戶的體驗造成了挑戰。AI智能體,作為能夠感知環境、做出決策和執行動作的獨立實體,可能是解決這一挑戰的關鍵。AI智能體不僅能夠自主完成任務,也能夠主動與環境交互。隨著LLMs的發展,AI智能體為這些模型提供了實際行動力,不僅僅是作為工具,而是作為能夠自動化處理通用問題的智能實體。通過釋放LLMs的潛能,AI智能體將成為未來技術的關鍵驅動力。例如,AutoGPT將復雜任務分解為更易管理的子任務,并生成相應的提示(prompts)。MetaGPT將高級人類流程管理經驗編碼到智能體的提示中,促進了多智能體之間的結構化合作。ChatDev受到軟件開發的經典瀑布模型的啟發,通過模擬一個虛擬軟件公司的環境,展示了智能體在專業功能研討會中的合作潛力。在這個環境中,多個智能體扮演不同的角色,遵循開發流程,通過聊天進行協作。
MetaGPT是由Deep Wisdom聯合幾個大學發布的一個基于大型語言模型(LLMs)專門為高效整合人類工作流程而設計的多智能體合作框架。通過將標準化操作程序(SOPs)編碼到智能體的提示序列中,MetaGPT簡化了工作流程,使智能體能夠以類似于人類專家的方式來校驗中間成果,這有助于減少錯誤的發生。
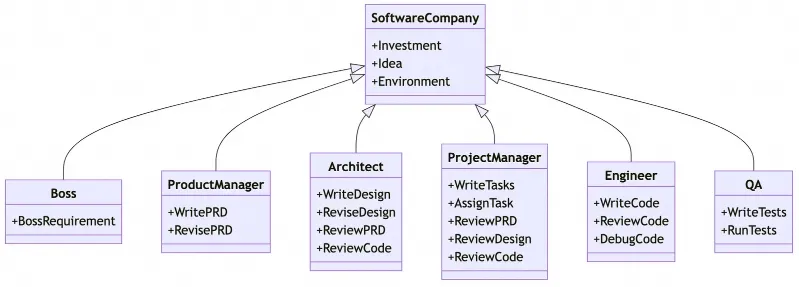
在MetaGPT系統中,智能體根據裝配線原則被分配不同的角色,以協同完成復雜任務。任務被分解為多個子任務,每個子任務由相應的智能體負責。這種方法不僅提高了任務執行的一致性,還提升了解決方案的質量。例如,在軟件工程的協作任務中,MetaGPT展現出了相較于傳統基于聊天的多智能體系統更一致的解決方案生成能力。
廣泛接受的SOPs在任務分解和有效協調中扮演了關鍵角色,尤其是在確定團隊成員職責和中間產物標準方面。在軟件開發領域,產品經理通常依據SOP來創建產品需求文檔(PRD),這有助于指導整個開發過程。
MetaGPT框架吸取了SOPs的重要經驗,并允許智能體生成結構化且高質量的需求文檔、設計文檔、流程圖和界面規格。這種結構化的中間輸出能夠顯著提升目標代碼生成的成功率。MetaGPT模擬了一個高度規范化的公司流程環境,在這個環境中,所有智能體必須嚴格遵守已確立的標準和工作流程。在角色扮演構架中,智能體被分配了各種各樣的角色,以高效協同工作、分解復雜任務。這種角色扮演的設計有助于減少無效交流,并降低大模型幻覺風險。
MetaGPT通過”編程促進編程”(programming to program)的方法,提供了一個有前景的元編程框架。智能體不僅是代碼的執行者,還主動參與到需求分析、系統設計、代碼生成-修改-執行、以及運行時調試的全過程。每個智能體都擁有特定的角色和專業知識,并遵循既定的標準。如此一來,MetaGPT成為了一種獨特的解決方案,在自動化編程任務中展現出巨大的潛力,并推動了元編程的高效實現。??
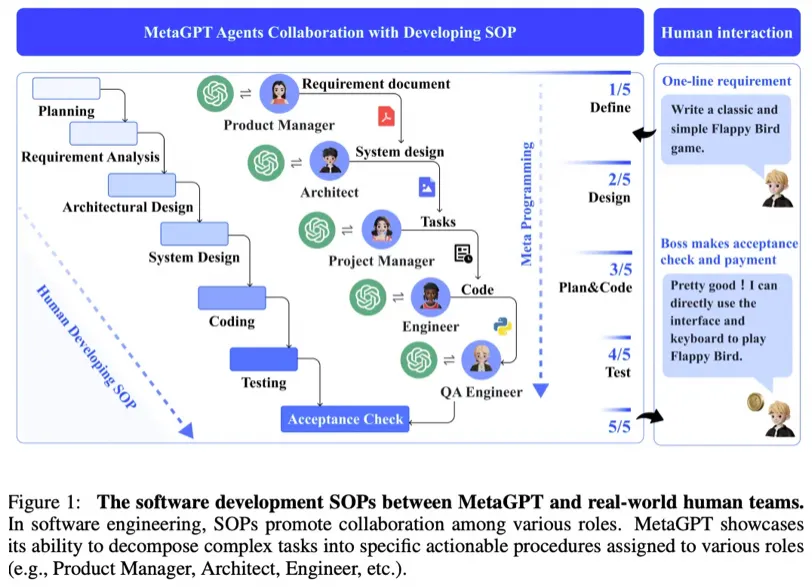
MetaGPT接受單行需求作為輸入,并輸出用戶故事、競爭分析、需求、數據結構、API、文檔等。在內部,MetaGPT包括產品經理、架構師、項目經理和工程師。它提供了一個軟件公司的整個流程,以及精心編排的標準操作程序(SOP)。代碼 = SOP(團隊) 是其核心理念。我們將SOP具體化,并將其應用到由大型語言模型(LLMs)組成的團隊中。
在通信協議中,智能體通過共享消息池發布和訂閱結構化消息,以此來協調工作和交換信息。這允許智能體根據自己的角色和任務需求,獲取相關信息并執行任務。
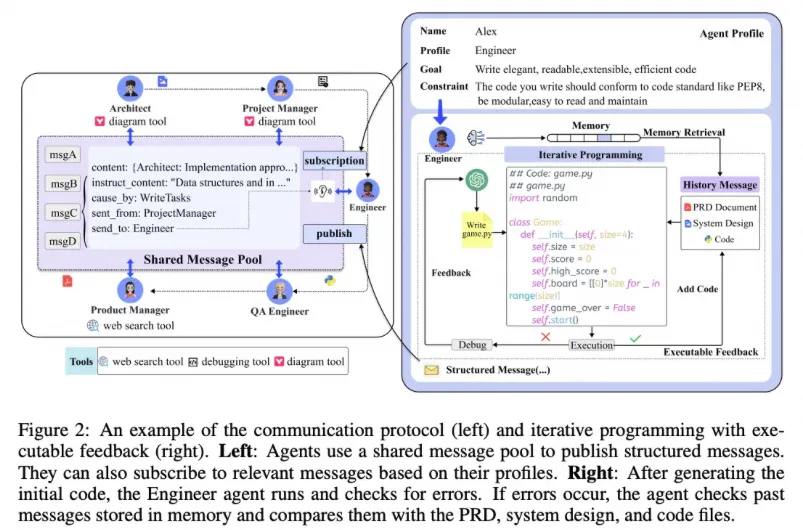
MetaGPT中的工程師智能體可以生成代碼,運行代碼檢查錯誤。如果遇到錯誤,智能體會查閱存儲在記憶中的消息,并將它們與產品需求文檔、系統設計和代碼文件進行對比,以識別問題并進行修正。這一過程涉及迭代編程和可執行反饋,使得智能體可以不斷優化其解決方案。
整個軟件開發過程圖強調了MetaGPT對SOPs的依賴性。這些SOPs規定了從項目開始到完成的每一步,確保智能體可以高效、系統地完成任務。
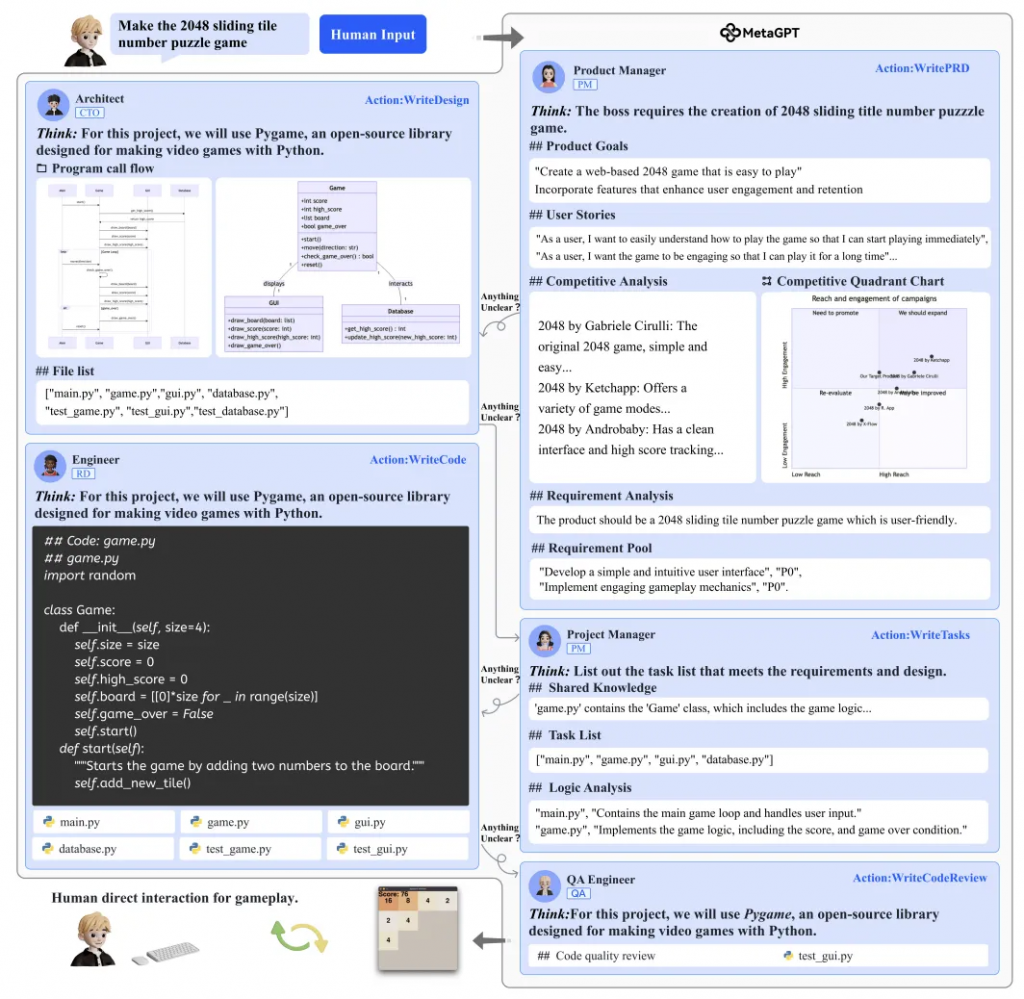
MetaGPT實驗流程
#步驟1:確保您的系統上安裝了Python 3.9或更高版本。您可以使用以下命令來檢查:
#您可以使用conda來初始化一個新的python環境
conda create -n metagpt python=3.9
conda activate metagpt
python3 --version
#步驟2:克隆倉庫到您的本地機器以獲取最新版本,并進行安裝。
git clone https://github.com/geekan/MetaGPT.git
cd MetaGPT
pip3 install -e . # 或者 pip3 install metagpt # 用于穩定版本
#步驟3:設置您的OPENAI_API_KEY,或確保它已經存在于環境變量中
mkdir ~/.metagpt
cp config/config.yaml ~/.metagpt/config.yaml
vim ~/.metagpt/config.yaml
#步驟4:運行metagpt命令行工具
metagpt "Create a 2048 game in python"
#步驟5 [可選]:如果您想要保存工作區中的產物,如象限圖、系統設計、序列流程圖等,可以在執行步驟3之前執行此步驟。默認情況下,框架是兼容的,整個過程可以完全不執行此步驟而運行。
如果執行,請確保您的系統上安裝了NPM。然后安裝mermaid-js。(如果您的計算機中沒有npm,請前往Node.js官方網站安裝Node.js https://nodejs.org/,然后您的計算機中將有npm工具。)
npm --version
sudo npm install -g @mermaid-js/mermaid-cli運行過程:

ChatDev是OpenBMB聯合清華大學NLP實驗室共同開發的大模型全流程自動化軟件開發框架,它模擬了一家虛擬軟件公司,由擔任不同職能的多個智能代理運作,包括首席執行官(CEO)、首席產品官(CPO)、首席技術官(CTO)、程序員、審查員、測試員和設計師。這些智能代理構成了一個多代理組織架構,并共同致力于一個使命:”通過編程革新數字世界。” 在ChatDev中,代理們通過聊天參與研討會協作,涵蓋設計、編碼、測試以及文檔撰寫等多種專業任務。
ChatDev的主要目標是提供一個易于使用、高度可定制和可擴展的框架,該框架基于大型語言模型(LLMs),旨在成為研究集體智能的理想場景。https://github.com/OpenBMB/ChatDev?
ChatDev通過模擬軟件開發的瀑布模型,實現了智能的分階段、分聊天的協作。每個階段包含多個原子聊天,而在每個聊天中,兩個扮演不同角色的智能體通過任務導向的對話來協同完成子任務。這個流程不僅包括了智能體之間基于指令的互動,還包括了角色專業化、記憶流、自省等機制,以確保智能體能夠高效、準確地執行任務,并持續優化決策過程。
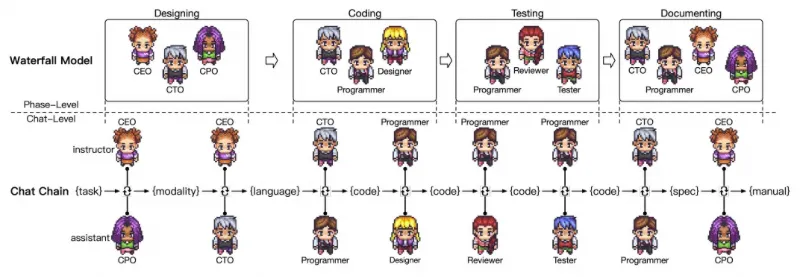
角色專業化使每個智能體都能在對話中有效地扮演其指定的角色,比如程序員、審查員等。記憶流記錄了聊天中的對話歷史,使智能體在做決策時有足夠的上下文信息。自省機制則是在達成共識的情況下,讓智能體反思并驗證決策,確保沒有違反終止條件。

在編碼和測試階段,為了減少代碼幻覺——即智能體生成與現有代碼庫不一致的代碼——ChatDev引入了思維指令機制。智能體通過角色交換,明確詢問或解釋代碼中的具體問題,這樣可以更精確地定位問題所在,并通過更具體的指令指導程序員修復問題。這種機制加強了智能體對代碼的理解,提高了編程和測試的準確性。
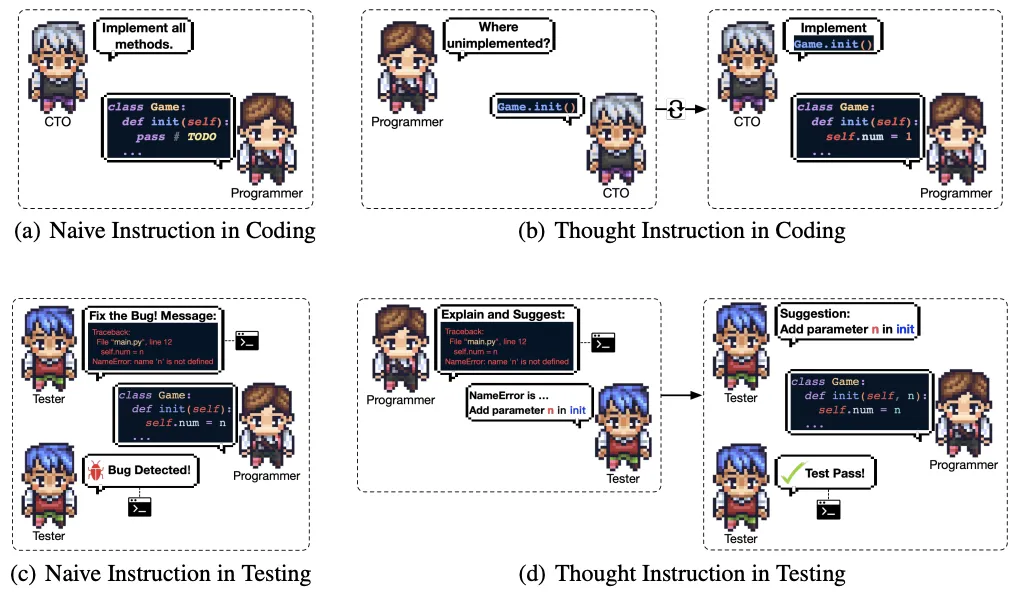
克隆GitHub倉庫:使用以下命令開始克隆倉庫:
git clone https://github.com/OpenBMB/ChatDev.git
設置Python環境:確保你有一個3.9或更高版本的Python環境。你可以使用以下命令創建并激活這個環境,將ChatDev_conda_env替換為你喜歡的環境名稱:
conda create -n ChatDev_conda_env python=3.9 -y
conda activate ChatDev_conda_env
安裝依賴項:移動到ChatDev目錄,并通過運行以下命令安裝必需的依賴項:
cd ChatDev
pip3 install -r requirements.txt
設置OpenAI API密鑰:將你的OpenAI API密鑰作為環境變量導出。將"your_OpenAI_API_key"替換為你實際的API密鑰。記住,這個環境變量是會話特定的,所以如果你打開一個新的終端會話,你需要再次設置它。在Unix/Linux系統上:
export OPENAI_API_KEY="your_OpenAI_API_key"
構建你的軟件:使用以下命令開始構建你的軟件,將[description_of_your_idea]替換為你的想法描述,將[project_name]替換為你想要的項目名稱:在Unix/Linux系統上:
python3 run.py --task "[description_of_your_idea]" --name "[project_name]"
運行你的軟件:一旦生成,你可以在WareHouse目錄下的特定項目文件夾中找到你的軟件,例如project_name_DefaultOrganization_timestamp。在該目錄下使用以下命令運行你的軟件:在Unix/Linux系統上:
cd WareHouse/project_name_DefaultOrganization_timestamp
python3 main.py# 安裝完成后,我們創建了一個字謎游戲:
python3 run.py --task "創建一個猜英文字謎的游戲" --name 'puzzle'
# 可視化智能代理對游戲的生成過程:
python3 visualizer/app.pyMetaGPT和ChatDev都支持自動化軟件開發,但在架構設計、技術實現、支持功能等方面存在一些差異。
| 功能特點 | MetaGPT | ChatDev |
| 流程標準化 | 標準化操作程序 | 聊天鏈 |
| 任務解決模式 | 按指令操作 | 智能體間通信 |
| 架構設計 | 系統接口 | —① |
| 緩解代碼幻覺 | — | 思維指令 |
| 藝術設計 | — | 文字到圖片設計師 |
| 記憶 | 上下文檢索 | 短時記憶共享 |
| 消息共享 | 智能體層面廣播 | 階段層面傳遞 |
| 版本管理 | — | Git |
| 自動化測試 | —② | 解釋器反饋 |
| 自然語言文檔 | 產品需求文檔 | 用戶手冊 |
①MetaGPT通過序列流程顯式設計架構;而ChatDev的架構設計是通過生成性基礎模型隱式實現的。②截至2023年9月19日,MetaGPT的官方代碼庫目前不支持軟件開發的自動化測試。
全球范圍內,多個AI智能體產品如AiAgent.app和GPT Researcher已被推出,并在媒體報道、行業分析、研究助理等領域獲得成功應用。這些智能體設計得足夠靈活,能夠調用軟件應用和硬件設備,大大提升了工作效率和便利性。盡管AI智能體的發展時間短暫,它們迅速在各行業中得到認可。隨著大型語言模型(LLMs)的多模態能力和計算力的增強,早年提出的智能體理念得以迅速實現,并廣泛應用于多個領域。各種開源AI智能體的出現,加速了技術供應商和創業團隊引入智能體的步伐,并幫助更多組織認識到并接受了AI智能體的概念,這可能成為LLMs落地的主要模式,并助力多個行業更好地利用LLMs。
LangChain為大型語言模型提供了一種全新的搭建和集成方式,正如樂高積木提供了無盡的創造可能。通過這個強大的框架,我們可以將復雜的技術任務簡化,讓創意和創新更加易于實現。在第一篇的內容中,我們穿越了LangChain的世界,體驗了如同搭建樂高積木般構建語言模型應用的樂趣。從LangChain的核心概念到其在現實世界中人臉問題的智能排查應用,我們見證了這一框架如何助力智能體的創新與成長。
在第二篇的內容中,我們討論了智能體的發展,目前主要呈現兩大方向。首先,我們看到了諸如Gorilla和ToolLLaMa這樣的進步,它們通過增強大型語言模型(LLMs)本身的工具使用能力,為我們帶來直觀、高效的互動體驗。這些工具的發展將大語言模型的潛力發揮到極致,為智能體提供了更為強大的支持功能。
另一方向是多代理協同,像MetaGPT和ChatDev這樣的系統展示了通過多智能體的合作可以如何高效解決問題。這種多代理模式模擬了人類團隊工作的方式,每個智能體扮演特定的角色,共同完成任務。這不僅提高了任務執行的效率,也開啟了智能代理未來無限的可能性。
隨著技術的不斷進化,智能代理正在從單一任務執行者轉變為能夠協同工作的團隊成員。這一轉變不僅擴大了智能體在各行各業中的應用范圍,也為未來出現的人與智能體之間的互動提供了基礎。讓我們攜手前進,共同迎接智能體技術帶來的充滿驚喜的新時代。
引用:
1.https://api.python.langchain.com/en/latest/langchain_api_reference.html
2.https://python.langchain.com/docs/modules/agents/concepts#agentexecutor
3.https://arxiv.org/pdf/2305.15334.pdf Gorilla: Large Language Model Connected with Massive APIs
4.https://arxiv.org/abs/2312.17025 ChatDev: Communicative Agents for Software Development
5.https://arxiv.org/abs/2307.16789 ToolLLM: Facilitating Large Language Models to Master
6.https://arxiv.org/abs/2308.00352 MetaGPT: Meta Programming for A Multi-Agent
7.https://github.com/gorilla-llm/gorilla-cli
8.https://github.com/OpenBMB/ToolBench
9.https://github.com/geekan/MetaGPT
10.https://github.com/OpenBMB/ChatDev
11.https://cobusgreyling.medium.com/agents-f444d165024
12.https://developers.lseg.com/en/article-catalog/article/bond-copilot–unleashing-rd-lib-search-api-with-ai-llm-langchain
13.https://huggingface.co/moka-ai/m3e-base
14.https://blog.csdn.net/lrb0677/article/details/132198025
15.https://zhuanlan.zhihu.com/p/645655496
16.https://www.sohu.com/a/723783296_116132,全球AI Agent大盤點,大語言模型創業一定要參考的60個AI智能體
17.https://36kr.com/p/2203231346847113, LangChain:Model as a Service粘合劑,被ChatGPT插件干掉了嗎?18.https://api.python.langchain.com/en/latest/agents/langchain.agents.openai_tools.base.create_openai_tools_agent.html19.https://api.python.langchain.com/en/latest/agents/langchain.agents.openai_functions_agent.base.create_openai_functions_agent.html20.https://api.python.langchain.com/en/latest/agents/langchain.agents.xml.base.create_xml_agent.html21.https://api.python.langchain.com/en/latest/agents/langchain.agents.structured_chat.base.create_structured_chat_agent.html22.https://api.python.langchain.com/en/latest/agents/langchain.agents.json_chat.base.create_json_chat_agent.html23.https://api.python.langchain.com/en/latest/agents/langchain.agents.react.agent.create_react_agent.html
24.https://api.python.langchain.com/en/latest/agents/langchain.agents.self_ask_with_search.base.create_self_ask_with_search_agent.html
文章轉自微信公眾號@阿里云開發者