
ChatGPT生態系統的安全漏洞導致第三方網站賬戶和敏感數據泄露
在實際操作中,智能體工作流的應用模式比我們通常所知的四種模式要豐富得多。例如,Coze平臺不僅提供了多智能體和工作流功能,還擴展到了圖像流領域。
通過插件、大型模型、代碼、知識庫、工作流、圖像流、選擇器、文本處理、消息、變量、數據庫等多種元素構建的工作流,最終會被整合到“技能”模塊中,形成一個智能體(Coze稱之為Bot)。這些智能體能夠執行更多任務,并參與到更復雜的業務流程中。
仔細觀察可以發現,在大型語言模型(LLM)應用日益普及的背景下,許多工作流都是將傳統業務流程與智能體工作流相結合的。這些工作流不僅包括了“四種模式”,還包括了將傳統應用與生成式AI(GenAI)結合的工作流,以及直接應用大型語言模型的簡單工作流。
一個典型的例子是,目前通過AI代理構建平臺構建的智能體工作流還無法處理操作企業管理軟件等復雜業務流程(受到API和連接能力的限制),而通過RPA等超自動化工具連接更多的簡單智能體工作流是一種有效的解決方案。
同時,RPA等超自動化工具現在已經發展成為RPA Agent,使用RPA本身也是智能體工作流應用的一種形式。這種應用方式正在越來越多地被用于企業級業務場景。
在王吉偉頻道的觀點中,Agentic Workflow不僅僅是智能體工作流,它是一個包含傳統軟件(工具、解決方案)、大型語言模型、AI代理等在內的新型業務流程的集合。當傳統業務流程包含了LLM工作流或Agent工作流時,都可以被視為Agentic Workflow。
特別是在大型語言模型代理化以及智能助手(如Copilot,具備反思、規劃、工具使用能力,并能調用代理)代理化的趨勢下,它們更符合Agentic Workflow的定義。
因此,研究Agentic Workflow不僅要關注AI代理和Agentic Workflow本身,還要關注大型語言模型及RPA等傳統業務流程在LLM和Workflow方面的進展。
為了幫助大家更好地學習和理解Agentic Workflow,本文精選了25篇與智能體工作流相關的論文,并將其分為技術框架、系統(套件與工具)、評估測試基準、編程語言、模型與工作流及方法論六大類別,希望對讀者有所啟發。
Sibyl: Simple yet Effective Agent Framework for Complex Real-world Reasoning
論文地址:https://arxiv.org/abs/2407.10718
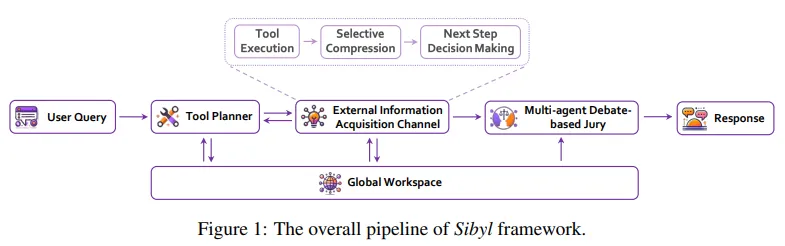
大型語言模型(LLM)集成了固有知識、上下文學習和零樣本能力,展現出強大的問題解決能力。然而,現有智能體在長期推理和工具潛力利用方面存在不足,導致現實世界推理任務中的缺陷。為克服這些限制,Sibyl作為一個新型的LLM智能體框架,通過最少工具有效處理復雜推理任務。
Sibyl從全球工作空間理論中獲取靈感,整合了全球工作空間,加強了系統知識和對話歷史的管理與共享。在心智理論的指導下,Sibyl通過多主體辯論的陪審團機制自我完善答案,確保全面性和平衡性。這一設計旨在簡化系統復雜性,拓寬問題解決范圍,促進從系統1到系統2的思維轉變。
Sibyl注重可擴展性和易調試性,采用函數式編程中的重入概念,以無縫集成到其他LLM應用中。在GAIA基準測試集中,Sibyl實現了34.55%的平均得分,展現了其先進性能。論文作者期望Sibyl能推動開發更可靠和可重用的LLM智能體,以應對復雜的現實世界推理挑戰。
PEER: Expertizing Domain-Specific Tasks with a Multi-Agent Framework and Tuning Methods
論文地址:https://arxiv.org/abs/2407.06985
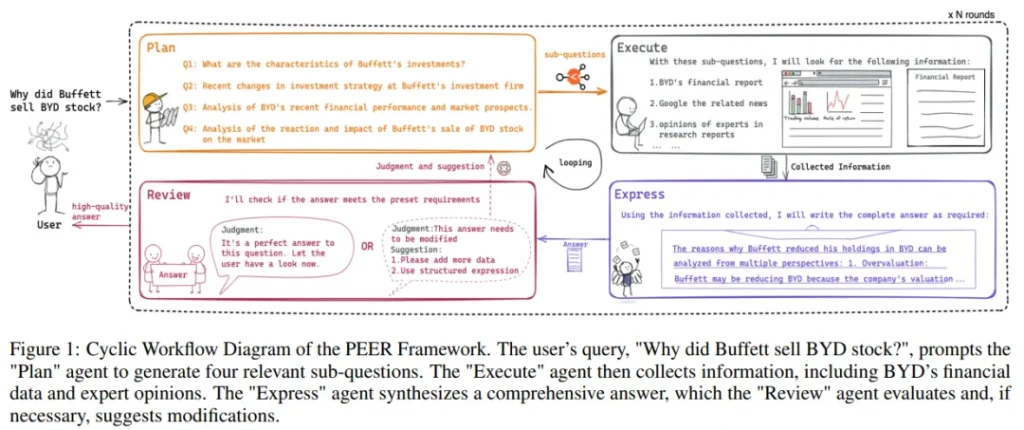
在專業領域應用中,GPT-4 通過精確的提示和檢索增強生成(RAG)技術展現出巨大潛力,但同時也面臨性能、成本和數據隱私的三重困境。高性能需求往往需要復雜的技術處理,而要管理多個智能體在復雜工作流程中的表現,不僅成本高,難度也大。
為應對這些挑戰,論文提出了 PEER(規劃、執行、表達、審查)多智能體框架。該框架通過整合精細的問題拆解、高效的信息檢索、綜合的總結能力以及嚴格的自我評估,系統化地處理專業領域任務。
考慮到成本和數據隱私的顧慮,許多企業正從 GPT-4 等專有模型轉向定制模型,以期在成本、安全性與性能之間找到平衡點。團隊利用在線數據和用戶反饋,開發了一套行業實踐,旨在實現模型的高效調整。
本研究提供了一套最佳實踐指南,用于在特定領域問題解決中應用多智能體系統,并實施有效的智能體調優策略。特別是在金融問答領域的實證研究表明,該方法達到了 GPT-4 性能的 95.0%,同時在成本控制和數據隱私保護方面表現出色。
BMW Agents — A Framework For Task Automation Through Multi-Agent Collaboration
論文地址:https://arxiv.org/abs/2406.20041
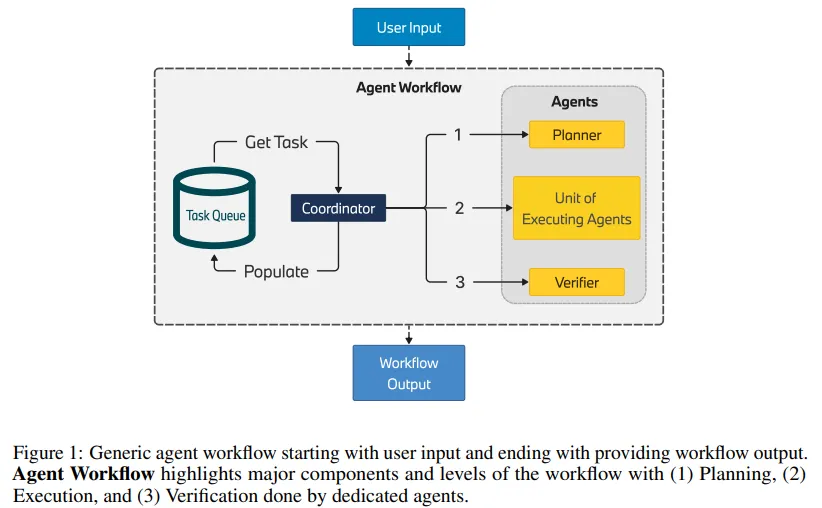
由大型語言模型(LLM)驅動的自主智能體展現了自動化的巨大潛力。技術的初步成效已在多個演示中顯現,其中包括智能體解決復雜任務、與外部系統交互以擴展知識,以及觸發必要操作。
特別是,多個智能體以協作方式共同解決復雜任務的場景,彰顯了它們在非嚴格和非明確環境下的運作能力。因此,多智能體方法在許多工業應用中具有極大的應用潛力,無論是構建復雜的知識檢索系統還是開發下一代機器人流程自動化。
考慮到當前LLM一代的推理能力,處理復雜流程需要采取多步驟策略,這包括制定明確定義的模塊化任務計劃。這些任務可以由單一智能體或一組智能體根據其復雜性執行。在本項研究中,團隊專注于構建一個靈活的智能體工程框架,特別關注規劃和執行階段,以應對跨不同領域的復雜應用案例。
該框架能夠為工業應用提供了所需的可靠性,并且為確保多個自主智能體能夠協同工作、共同解決問題提供了一套可擴展、靈活且協作的技術流程。
Trace is the New AutoDiff — Unlocking Efficient Optimization of Computational Workflows
論文地址:https://arxiv.org/abs/2406.16218
項目地址:https://microsoft.github.io/Trace
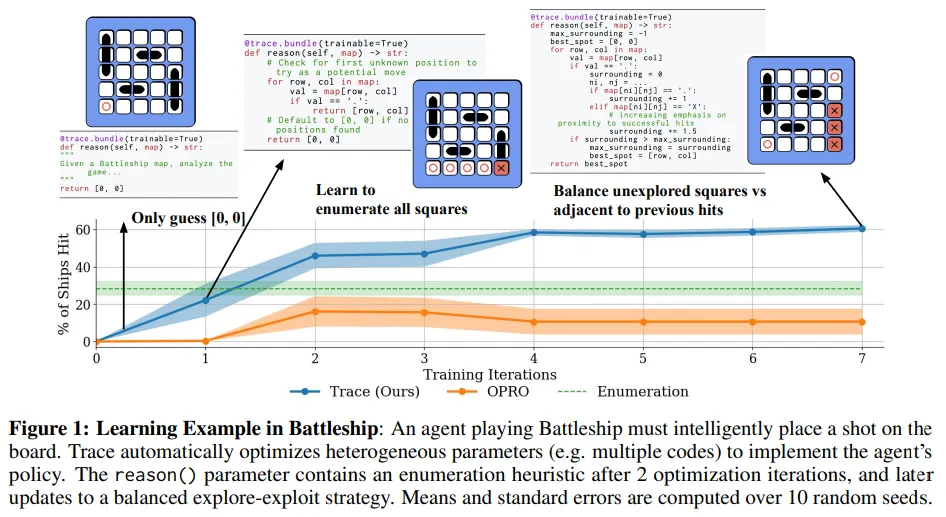
論文探索了一種針對自動化編碼助手、機器人和副駕駛等人工智能系統的優化問題,研究團隊開發了一個名為Trace的端到端優化框架,它將AI系統的計算流程視為神經網絡圖,并基于反向傳播的泛化進行優化。這種優化處理了包括豐富反饋、異構參數和復雜目標在內的多種因素,并能適應動態變化的計算圖。
Trace框架通過一種新的迭代優化數學設置——使用跟蹤預言機優化(OPTO)——來捕獲和抽象AI系統的特性,以設計跨領域的優化器。在OPTO中,優化器通過接收執行跟蹤和輸出反饋來迭代更新參數。Trace提供了一個Python接口,利用類似PyTorch的接口高效地將計算流程轉換為OPTO實例。
利用Trace,團隊開發了一個名為OptoPrime的通用優化器,它基于LLM,能夠解決多種OPTO問題,包括數值優化、提示優化、超參數調優、機器人控制器設計和代碼調試等,且性能可與領域內專業優化器相媲美。論文認為,Trace、OptoPrime和OPTO框架將推動下一代交互式智能體的發展,使其能夠利用各種反饋實現自動適應。
RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models
https://arxiv.org/abs/2310.16340
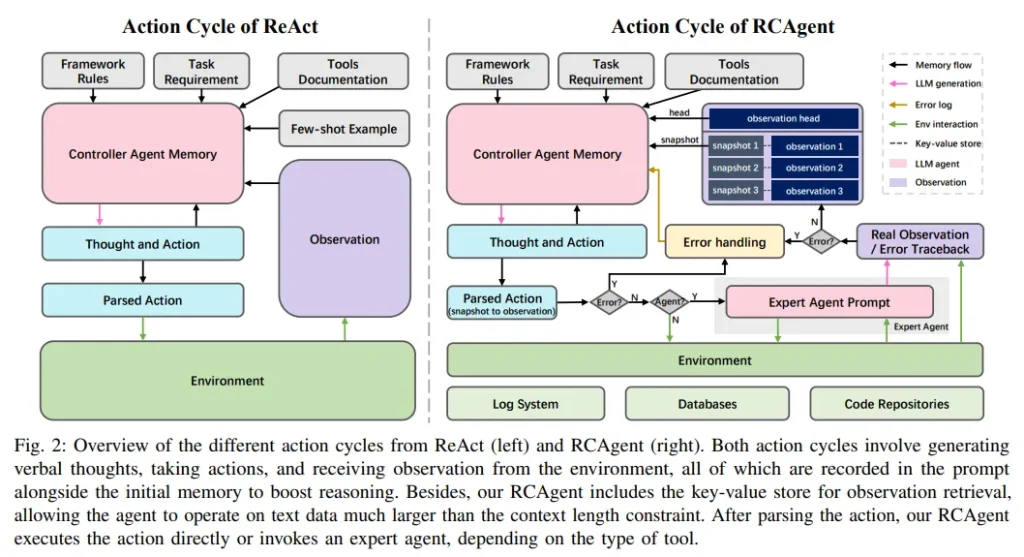
近期,云根本原因分析(RCA)領域對大型語言模型(LLM)的應用進行了積極探索。但現有方法仍依賴手動設置工作流,未能充分發揮LLM在決策和環境交互方面的能力。為此,研究團隊推出了RCAgent,這是一個工具增強的LLM自治智能體框架,專為實用且注重隱私的工業RCA設計。
RCAgent不依賴外部模型如GPT系列,而是在內部部署的模型上運行,能夠自主進行自由格式的數據收集和綜合分析。該框架融合了多項增強功能,包括行動軌跡的自洽性,以及一系列用于上下文管理、穩定性提升和領域知識導入的方法。
實驗結果表明,RCAgent在RCA的多個方面(如預測根本原因、解決方案、證據和責任)以及規則內外任務上均顯示出顯著且一致的優勢,這些優勢已通過自動化指標和人工評估得到驗證。此外,RCAgent已成功集成至阿里云Apache Flink實時計算平臺的診斷和問題發現工作流程中,進一步提升了工業RCA的效率和準確性。
AgileCoder: Dynamic Collaborative Agents for Software Development based on Agile Methodology
論文地址:https://arxiv.org/abs/2406.11912
軟件智能體正成為解決復雜軟件工程任務的有前景的工具。然而,現有研究常常過于簡化軟件開發流程,而現實世界中的這些流程往往更為復雜。
為了應對這一挑戰,研究團隊設計了AgileCoder,這是一個將敏捷方法論(AM)整合進框架的多智能體系統。該系統將特定的AM角色,如產品經理、開發人員和測試人員,分配給不同的智能體,它們根據用戶輸入協作開發軟件。
AgileCoder通過組織工作為一系列沖刺(sprint),提高開發效率,并專注于逐步完成軟件的開發。此外,還引入了一個動態代碼圖生成器,該模塊能夠在代碼庫更新時動態創建代碼依賴圖。這使得智能體能夠更深入地理解代碼庫,從而在軟件開發過程中實現更精確的代碼生成和修改。
AgileCoder在性能上超越了現有的基準,如ChatDev和MetaGPT,樹立了新的標準,并展現了多智能體系統在高級軟件工程環境中的強大能力。這標志著軟件開發向更自動化、智能化方向邁出了重要一步。
Parrot: Efficient Serving of LLM-based Applications with Semantic Variable
論文地址:https://arxiv.org/abs/2405.19888
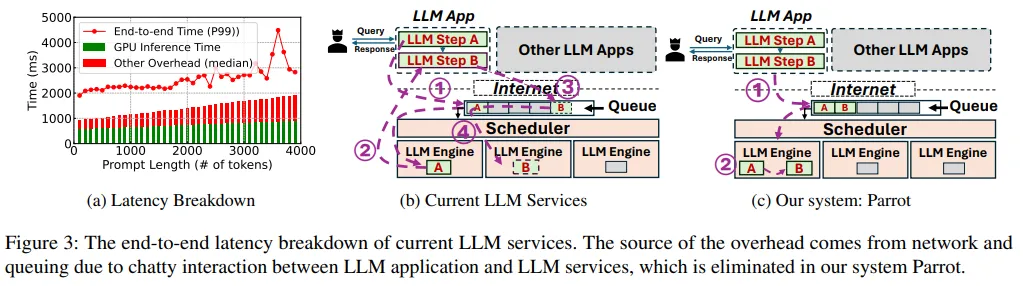
LLM的興起催生了基于LLM與傳統軟件優勢的新型應用程序——AI智能體(也叫副駕駛),這是一種軟件新范式。
不同租戶的LLM應用程序通過多個LLM請求設計復雜工作流以完成任務,但受限于當前公共LLM服務提供的簡化請求級API,丟失了關鍵的應用程序級信息。這些服務只能盲目優化單個LLM請求,導致應用程序的整體性能不佳。
該論文介紹了Parrot,這是一個專注于LLM應用程序端到端體驗的服務系統。Parrot引入了語義變量的概念,這是一種統一的抽象,將應用程序級知識暴露給公共LLM服務。語義變量在請求提示中標注輸入/輸出變量,并在連接多個LLM請求時形成數據管道,提供了一種自然的LLM應用程序編程方式。
公開語義變量給公共LLM服務,使其能夠執行數據流分析,揭示多個LLM請求間的相關性,為LLM應用程序的整體性能優化開辟了新空間。廣泛的評估顯示,Parrot針對流行和實際的LLM應用程序用例實現了顯著的性能提升。
Automating the Enterprise with Foundation Models
論文地址:https://arxiv.org/abs/2405.03710
項目地址:https://github.com/HazyResearch/eclair-agents
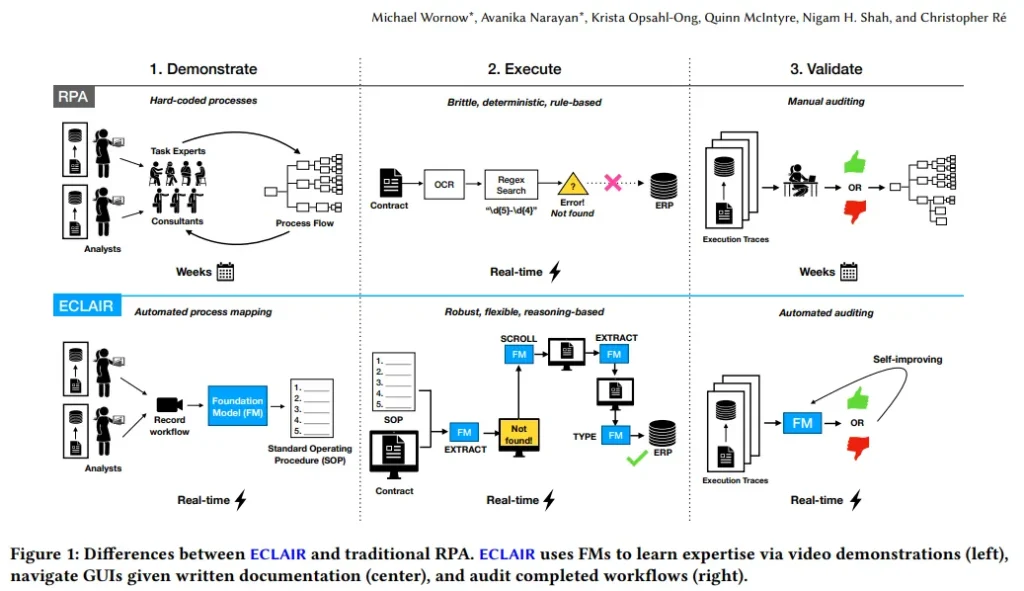
企業工作流程自動化每年可帶來 4 萬億美元的生產力提升。盡管這一領域已受到數據管理社區數十年的關注,但實現端到端工作流自動化的終極目標仍然具有挑戰性。現有解決方案主要依賴流程挖掘和機器人流程自動化(RPA),這些機器人通常被硬編碼以遵循預設規則。
通過對醫院和大型B2B企業的案例研究,研究團隊發現RPA的普及受到諸如高設置成本(12-18個月)、執行不可靠(初始準確率60%)和維護繁重等問題的制約。新一代多模態基礎模型(FM),如GPT-4,以其卓越的推理和規劃能力,為工作流自動化提供了新的可能性。
為此,論文提出了ECLAIR系統,它在最少人工監督下實現企業工作流程自動化。初步實驗顯示,ECLAIR通過多模態FM實現了接近人類水平的工作流理解(準確率93%),并基于工作流的自然語言描述即可快速設置,實現了40%的端到端完成率。論文認為,人與AI的協作、驗證和自我改進是未來研究的開放性挑戰,并提出利用數據管理技術來解決這些問題。
S-Agents: Self-organizing Agents in Open-ended Environments
https://arxiv.org/abs/2402.04578
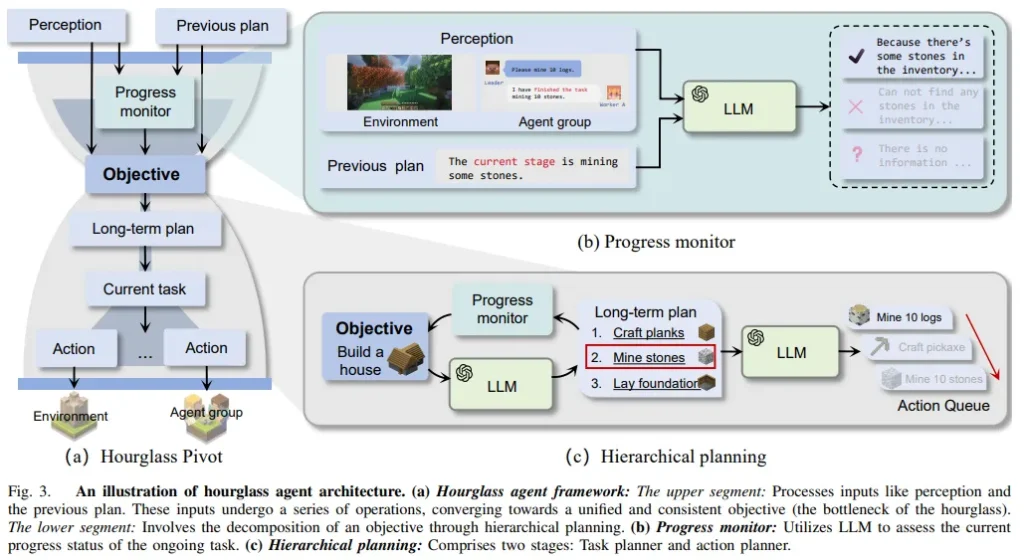
利用LLM,自主智能體在處理各類任務上取得了顯著進步。在開放環境中,為了提升協作的效率和有效性,需要靈活調整策略。然而,現有研究多聚焦于固定且任務導向的工作流程,而忽視了以智能體為中心的組織結構。
受人類組織行為的啟發,該團隊提出了一種自組織智能體系統(S-Agents),它包括動態工作流的“智能體樹”結構、用于平衡信息優先級的“沙漏智能體架構”,以及支持智能體間異步任務執行的“非阻礙協作”方法。這一結構使得一組智能體能在無人為干預下,有效應對開放和動態環境的挑戰。
團隊的實驗在Minecraft環境中進行,S-Agent系統在執行協作建造和資源收集任務時表現出了熟練和高效,從而驗證了其組織結構和協作方法的有效性。這一研究成果為智能體在復雜環境中的自組織協作提供了新的視角和解決方案。
A Human-Computer Collaborative Tool for Training a Single Large Language Model Agent into a Network through Few Examples
論文地址:https://arxiv.org/abs/2404.15974
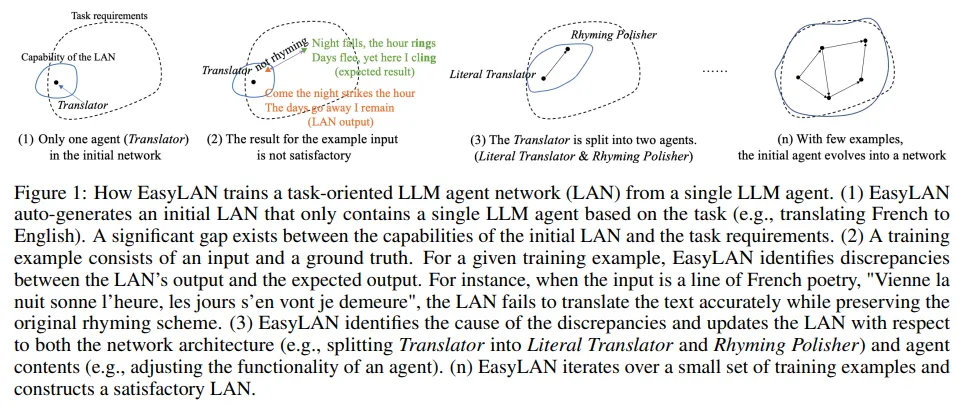
單個大型語言模型(LLM)智能體在解決復雜任務時能力有限。通過將多個LLM智能體連接成網絡,可以顯著提升整體性能。然而,構建這樣的LLM智能體網絡(LAN)是一項耗時且復雜的過程。
在本研究中,團隊推出了EasyLAN,這是一個旨在幫助開發者構建智能體網絡的人機協作工具。EasyLAN首先根據任務描述生成一個只包含單個智能體的網絡。然后,它利用訓練樣本來逐步優化網絡。EasyLAN會分析輸出與實際值之間的差異,診斷錯誤原因,并采取策略進行修正。用戶可以參與EasyLAN的工作流程,或直接對網絡進行調整。
最終,網絡從單一智能體發展成為一個成熟的LLM智能體網絡。實驗結果表明,使用EasyLAN,開發者能夠迅速構建出性能優異的智能體網絡。這一工具極大地簡化了智能體網絡的構建過程,提高了開發效率。
PromptRPA: Generating Robotic Process Automation on Smartphones from Textual Prompts
論文地址:https://arxiv.org/abs/2404.02475
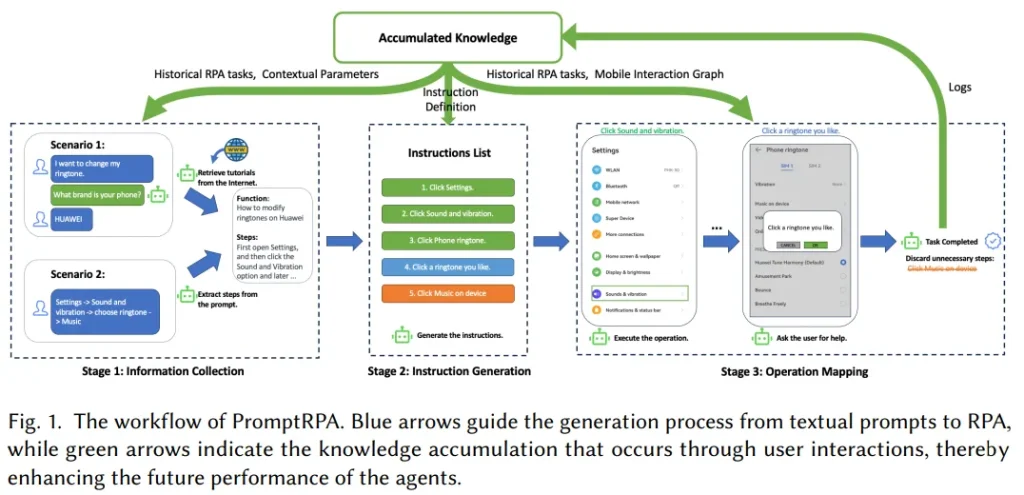
機器人流程自動化(RPA)通過模擬人機交互,在不修改現有代碼的基礎上,為自動化圖形用戶界面(GUI)上的任務提供了有效的解決方案。但RPA的廣泛應用受限于對腳本語言和工作流設計專業知識的需求。
為解決這一問題,研究團隊提出了PromptRPA,這是一個能夠理解與任務相關的各種文本提示(如目標、程序)并生成及執行相應RPA任務的系統。
PromptRPA由一系列智能體組成,它們模仿人類的認知功能,專門用于解讀用戶意圖、管理由RPA生成的外部信息,并在智能手機上執行操作。這些智能體能夠從用戶反饋中學習,并根據積累的知識不斷提升性能。
實驗結果顯示,使用PromptRPA后,性能從基線的22.28%顯著提升至95.21%,且每個新任務平均僅需1.66次用戶干預。
PromptRPA在創建教程、智能輔助以及客戶服務等領域展現出廣闊的應用前景,為RPA技術的進一步普及和應用提供了新的可能性。
ProAgent: From Robotic Process Automation to Agentic Process Automation
論文地址:https://arxiv.org/abs/2311.10751
項目地址:https://github.com/OpenBMB/ProAgent
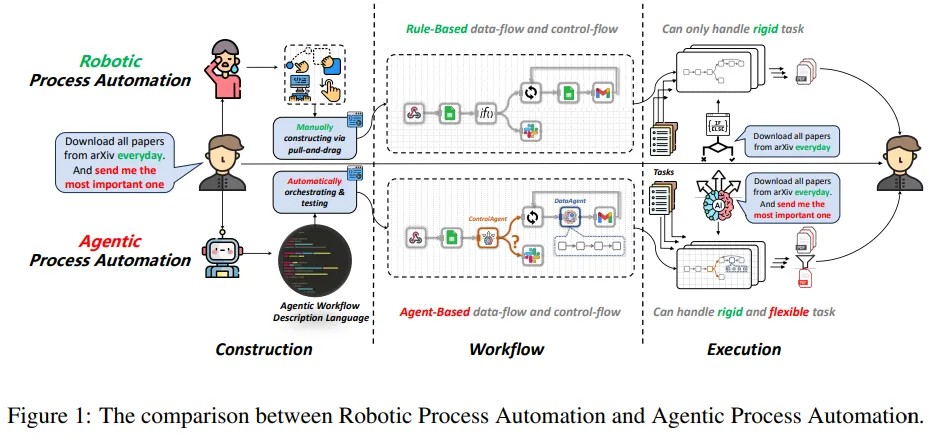
自動化技術從古代的水車發展到今天的RPA,一直在解放人類從事繁重任務。但RPA在處理需要人類智能的任務時面臨挑戰,尤其是在精心設計工作流和執行中的動態決策方面。
隨著大型語言模型(LLM)的出現,研究團隊提出了智能體流程自動化(APA),這是一種革命性的自動化新范式,利用基于LLM的智能體實現高級自動化,通過將任務分配給負責構建和執行的智能體來減輕人力負擔。
論文具體實現了ProAgent,這是一個基于LLM的智能體,它可以根據人工指令創建工作流程,并通過協調專業的智能體做出復雜決策。
通過實證實驗,論文詳細展示了APA在工作流構建和執行方面的過程,證明了APA的可行性,并展現了由智能體驅動的自動化新范式的巨大潛力。這不僅為自動化領域帶來了新的視角,也為未來智能自動化的發展提供了新的方向。
A Survey on LLM-Based Agents: Common Workflows and Reusable LLM-Profiled Components
論文地址:https://arxiv.org/abs/2406.05804
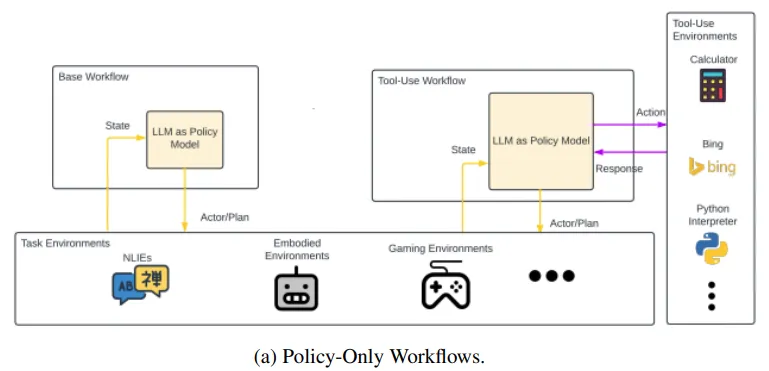
大型語言模型(LLM)的最新進展推動了基于LLM的復雜智能體框架的開發。然而,這些框架的復雜性在一定程度上阻礙了細粒度差異化的實現,這對于在不同框架間高效實現功能和推動未來研究至關重要。因此,該調查的主要目標是通過識別通用工作流程和可重用的LLM分析組件(LMPC),來促進對近期提出的多種框架的統一理解。
這項工作旨在簡化不同智能體框架之間的差異,通過提取共通的工作流程和分析組件,為研究者和開發者提供一個更加清晰和一致的視角。通過這種方式,論文希望能夠降低開發和維護智能體框架的難度,同時為未來的研究和創新打下堅實的基礎。
WorkArena++: Towards Compositional Planning and Reasoning-based Common Knowledge Work Tasks
論文地址:https://arxiv.org/abs/2407.05291
基準測試項目:https://github.com/ServiceNow/WorkArena/tree/workarena-plus-plus

大型語言模型(LLM)因其模仿人類智能的能力而備受關注,這促使基于LLM的自主智能體數量激增。盡管最新的LLM展現出根據用戶指令進行規劃和推理的潛力,但它們在自主任務解決方面的實際應用效果尚待深入研究。特別是在企業環境中,自動化智能體的應用被寄予厚望,期望能夠帶來顯著的影響。
為了解決這一研究空白,論文提出了WorkArena++,這是一個創新的基準測試套件,包含682個任務,覆蓋知識工作者日常執行的實際工作流程。WorkArena++的目標是全面評估網絡智能體在規劃、問題解決、邏輯/算術推理、信息檢索以及上下文理解等方面的能力。
通過對最先進的LLM、視覺語言模型(VLM)以及人類工作者的實證研究,論文揭示了這些模型在職場中作為有效助手所面臨的若干挑戰。
除了基準測試,論文還提供了一種機制,能夠輕松生成數千條基于真實情境的觀察/動作軌跡,這些軌跡可以用于微調現有的智能體模型,并期望這項工作能夠成為推動社區向有能力的自主智能體發展的重要資源。
FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agent
論文地址:https://arxiv.org/abs/2406.14884
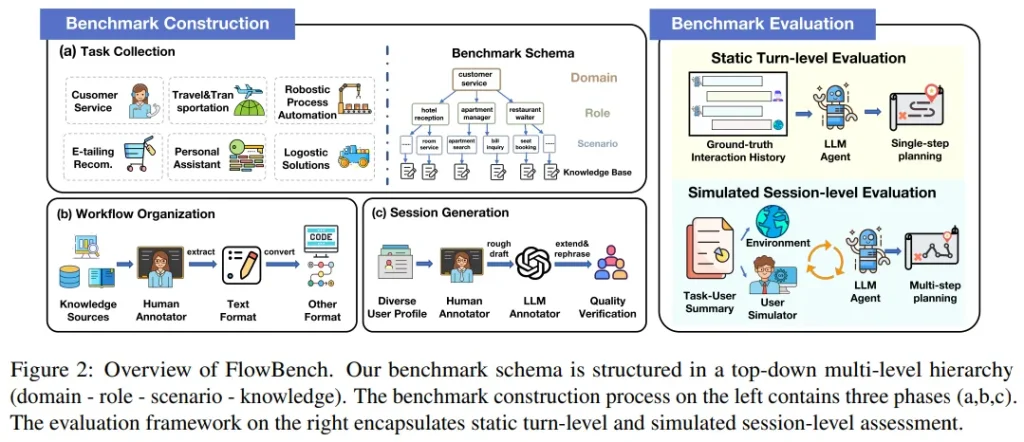
大型語言模型(LLM)驅動的智能體已成為執行復雜任務的有前途工具,它們通過迭代規劃和行動來完成任務。但當缺乏對專業知識密集型任務的深入理解時,這些智能體可能會產生不切實際的規劃幻想。為提高規劃的可靠性,該團隊嘗試整合與工作流相關的外部知識。
盡管這一方法有潛力,但整合的知識往往雜亂無章、形式多樣,缺乏嚴格的形式化和全面評估。因此,該團隊對不同格式的工作流知識進行形式化處理,并推出了FlowBench——首個工作流引導規劃的基準測試。FlowBench覆蓋6個領域的51個不同場景,以多種形式展現知識。
為了在FlowBench上評估不同的LLM,團隊設計了一個多層評估框架,評估了工作流知識在多種格式下的有效性。結果表明,現有的LLM智能體在規劃方面還有很大的提升空間。論文期望FlowBench這一具有挑戰性的基準測試能夠為未來智能體規劃研究提供參考,推動相關技術的進步。
Do Multimodal Foundation Models Understand Enterprise Workflows? A Benchmark for Business Process Management Tasks
論文地址:https://arxiv.org/abs/2406.13264
數據集和實驗項目地址:https://github.com/HazyResearch/wonderbread
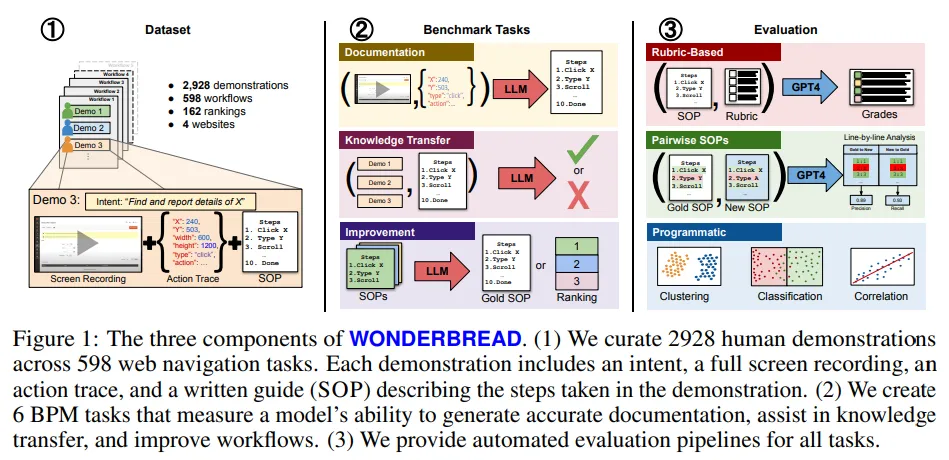
現有的機器學習(ML)基準測試在評估業務流程管理(BPM)任務時,缺乏足夠的深度和多樣性的注釋。BPM 是一種旨在記錄、衡量、改進和自動化企業工作流的實踐。
目前的研究幾乎完全集中在單一任務上,即利用多模態基礎模型(FM)如 GPT-4 實現端到端的自動化。這種對自動化的專注忽視了大多數BPM工具的實際應用情況——在典型的流程優化項目中,僅僅記錄相關工作流就占據了60%的時間。
為了填補這一空白,研究團隊推出了WONDERBREAD,這是首個用于評估BPM任務的多模態FM基準測試,它超越了自動化的范疇。該論文的貢獻包括:
團隊期望WONDERBREAD能夠激勵開發更多以人為中心的AI工具,用于企業應用程序,并進一步探索多模態FM在更廣泛的BPM任務中的應用。
APPL: A Prompt Programming Language for Harmonious Integration of Programs and Large Language Model Prompts
論文地址:https://arxiv.org/abs/2406.13161
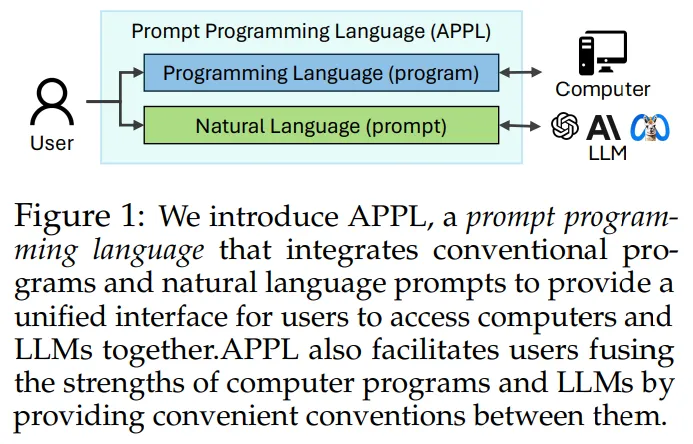
大型語言模型(LLM)通過精心設計的提示和外部工具的集成,日益展現出處理各類任務的能力。然而,隨著任務復雜性的提升,涉及LLM的工作流程可能變得復雜,難以實現和維護。為解決這一難題,研究團隊提出了APPL,一種新穎的提示編程語言,它作為計算機程序與LLM之間的橋梁,支持將提示無縫嵌入Python函數,反之亦然。
APPL具備直觀的Python原生語法,擁有異步語義的高效并行化運行時環境,并且配備了無需額外成本的跟蹤模塊,以支持有效的故障診斷和重放。論文通過三個典型場景——自一致性的思維鏈(CoT-SC)、ReAct工具使用的智能體,以及多智能體聊天——證明了APPL程序的直觀性、簡潔性和高效性。
此外,對三個可并行化工作流的實驗進一步證實了APPL在并行化獨立LLM調用方面的有效性,并實現了與預期估算相匹配的顯著加速比。這表明APPL是一個強大的工具,能夠提升LLM在復雜任務中的性能和可用性。
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
論文地址:https://arxiv.org/abs/2405.04324
項目地址:https://github.com/ibm-granite/granite-code-models
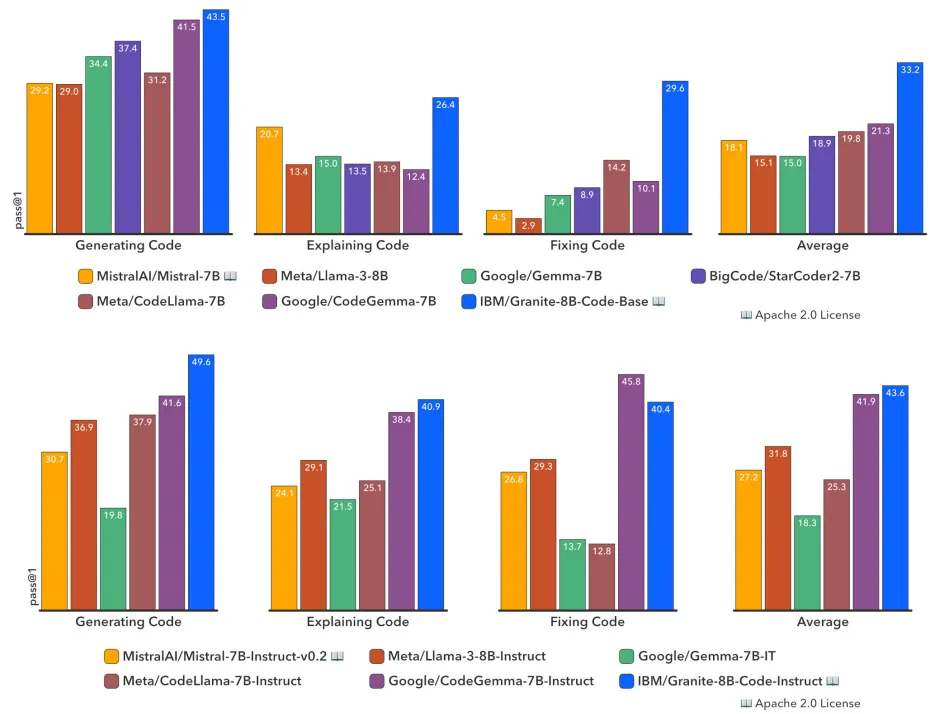
LLM在代碼訓練方面取得了突破性進展,正深刻改變著軟件開發的生態。越來越多的代碼LLM被融入到軟件開發工具中,以提升程序員的工作效率。同時,基于LLM的智能體也開始展現出獨立處理復雜編碼任務的能力。
要充分發揮代碼LLM的潛力,需要它們具備廣泛的能力,如代碼生成、錯誤修復、代碼解釋、文檔編寫和代碼庫維護等。在本項研究中,團隊推出了Granite系列僅解碼器代碼模型,專門用于代碼生成任務。這些模型經過了116種編程語言的代碼訓練,覆蓋了從30億到340億參數大小不等的多種模型,能夠滿足從復雜的應用現代化到設備內存受限的各種場景。
通過一系列綜合任務的評估,團隊發現Granite Code模型在所有可用的開源代碼LLM中始終保持最先進的性能。
該模型系列針對企業級軟件開發流程進行了特別優化,在代碼生成、修復和解釋等多項編碼任務中均有出色表現,成為一個多功能的全能型代碼模型。所有Granite Code模型均在Apache 2.0許可下發布,既適用于研究也適用于商業用途,為軟件開發領域帶來了前所未有的靈活性和創新潛力。
Towards Hierarchical Multi-Agent Workflows for Zero-Shot Prompt Optimization
論文地址:https://arxiv.org/abs/2405.20252
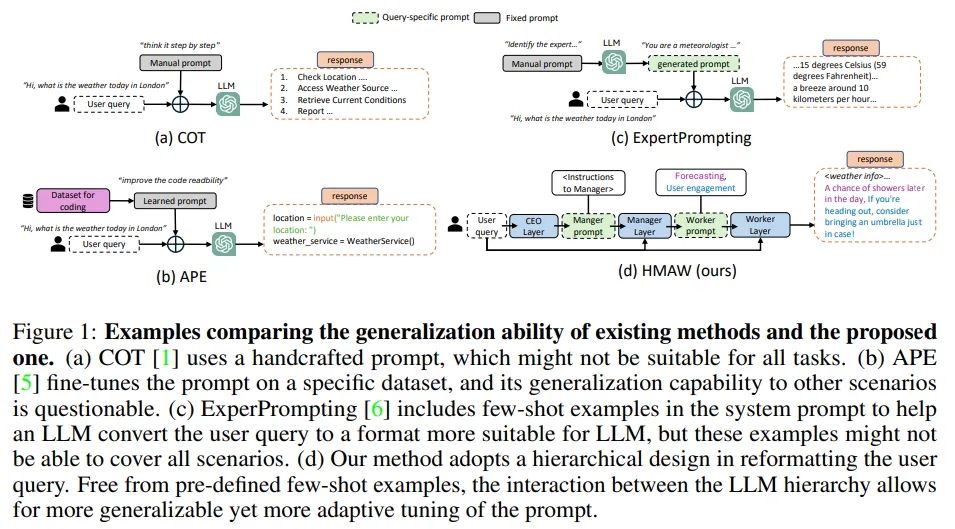
大型語言模型(LLM)在解答用戶問題上取得了顯著進步,支撐了多樣化的應用場景。但LLM的回答質量極大程度上依賴于提示的質量,一個精心設計的提示能夠引導LLM準確回答極具挑戰性的問題。
盡管已有研究開發了多種策略來優化提示,包括手工制作和領域內優化,它們在開放場景下的有效性仍受限,因為前者依賴于人類對問題的理解,而后者對未見過場景的泛化能力不足。
為克服這些限制,研究團隊提出了一種讓LLM自主設計最佳提示的方法。具體來說,團隊構建了一個分層的提示生成框架,首先創建包含精確指令和準確措辭的提示,再基于此生成最終答案。這一流程稱為分層多智能體工作流(HMAW)。
與現有方法相比,HMAW不受任何人類預設限制,無需訓練,完全任務獨立,同時能夠適應任務的細微差別。通過跨多個基準的實驗,證實了HMAW雖然簡單,卻能創建出詳盡且合適的提示,進一步提升了LLM的性能。
Autonomous Workflow for Multimodal Fine-Grained Training Assistants Towards Mixed Reality
論文地址:https://arxiv.org/abs/2405.13034
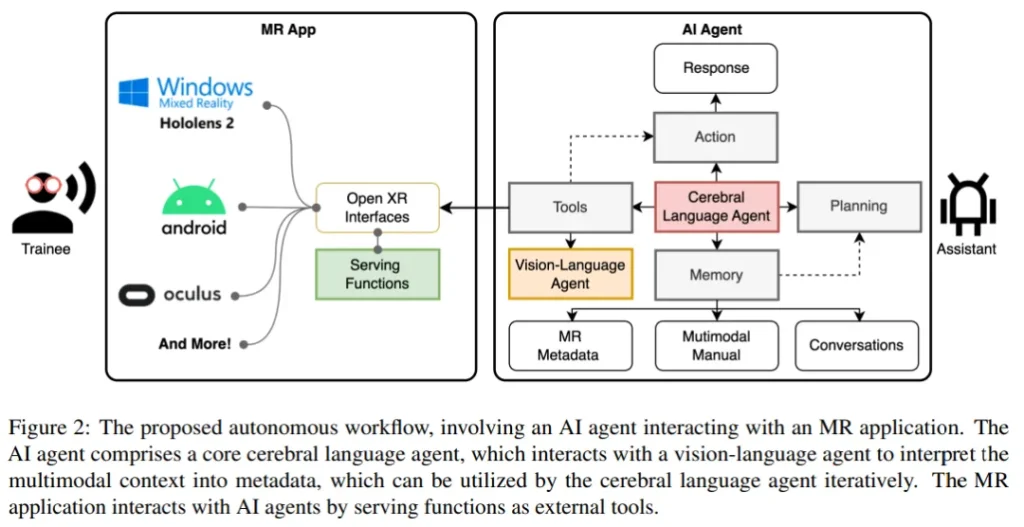
自主人工智能智能體(Autonomous Agent)在自動理解基于語言的環境中展現出巨大潛力,尤其是在大型語言模型(LLM)迅猛發展的背景下。然而,對多模態環境的深入理解尚待進一步探索。本研究設計了一個自主工作流程,旨在將AI智能體無障礙地集成到擴展現實(XR)應用中,實現細粒度訓練。
論文展示了一個在XR環境中用于樂高積木組裝的多模態細粒度培訓助手的案例。該智能體結合了LLM、記憶、規劃功能以及與XR工具的交互能力,能夠根據歷史經驗做出決策。此外,論文介紹了LEGO-MRTA,這是一個多模態細粒度裝配對話數據集,它能夠在商業LLM服務的工作流程中自動合成,包含多模態說明、對話、XR響應和視覺問答。
研究團隊選取了幾個流行的開放資源LLM作為基準,評估它們在微調和未微調狀態下對團隊提出的數據集的性能。論文期望這一工作流程能夠推動更智能助手的開發,實現XR環境中的無縫用戶交互,并促進AI和人機交互(HCI)社區的研究。
Leveraging Multi-AI Agents for Cross-Domain Knowledge Discovery
論文地址:https://arxiv.org/abs/2404.08511
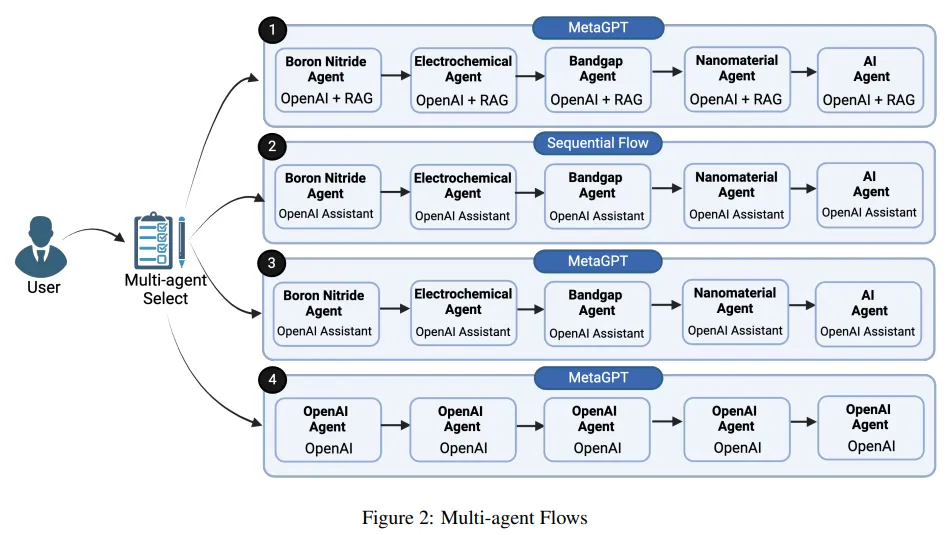
在迅速發展的人工智能領域,跨領域知識的整合與應用是一項關鍵的挑戰與機遇。本研究提出了一種新方法,通過部署專注于不同知識領域的多人工智能智能體,實現跨學科的知識發現。每個智能體都像特定領域的專家,在統一框架下協同工作,提供綜合的、超越單一領域限制的深入見解。
研究團隊的平臺通過促進智能體間的無縫互動,利用每個智能體的獨特優勢,增強了知識發現和決策過程。通過對比分析不同的多智能體工作流場景,評估了它們在效率、準確性和知識整合廣度上的表現。實驗結果表明,這些特定領域的多智能體系統在識別和填補知識空白方面表現出色。
這項研究不僅凸顯了協作智能在促進創新中的關鍵作用,也為人工智能推動的跨學科研究和應用的發展奠定了基礎。團隊在小規模試點數據上評估了其方法,結果顯示出預期趨勢,隨著自定義訓練智能體的數據量增加,這些趨勢預計將變得更加明顯。
The Case for Developing a Foundation Model for Planning-like Tasks from Scratch
論文地址:https://arxiv.org/abs/2404.04540
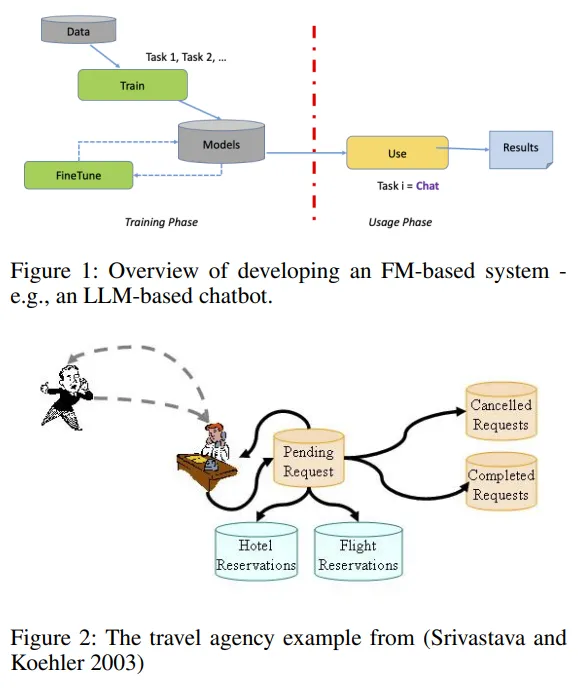
基礎模型 (FM) 徹底改變了許多計算領域,包括自動規劃和調度 (APS)。例如,最近的一項研究發現它們對規劃問題很有用:計劃生成、語言翻譯、模型構建、多智能體規劃、交互式規劃、啟發式優化、工具集成和大腦啟發規劃。
除了APS,還有許多任務涉及生成一系列行動,這些行動對于達成目標的可執行性有不同的保障,團隊統稱這些為類似計劃(PL)任務,例如業務流程、程序編寫、工作流管理和指南制定。研究人員正考慮將FM應用于這些領域。
然而,以往的研究多集中在使用現成的預訓練FM,并可能對它們進行微調。該論文討論了為PL任務從頭開始設計全面的FM的必要性,并探討了設計時需考慮的因素。論文認為,這樣的FM將為PL問題提供新的有效解決方案,正如大型語言模型(LLM)為APS領域所做的那樣。
Transformations in the Time of The Transformer
論文地址:https://arxiv.org/abs/2401.10897
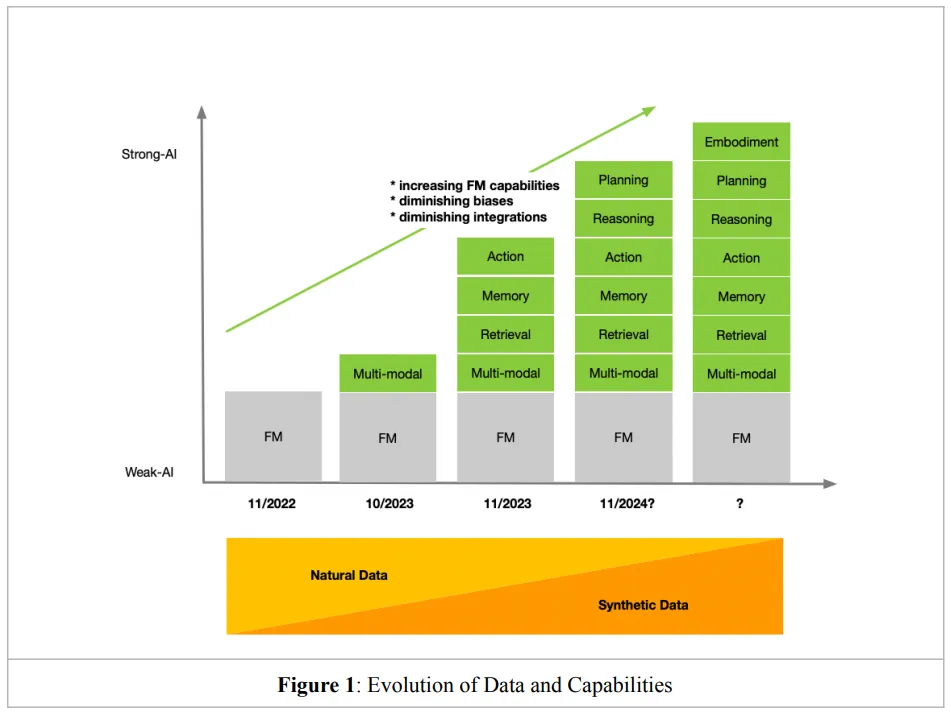
基礎模型為以人工智能為主導的視角重新設計現有系統和工作流程提供了新的機遇。然而,實現這一轉型面臨著挑戰和需要權衡的問題。本文旨在提供一個結構化的框架,幫助企業在向以AI為優先的組織轉型過程中做出明智的決策。所提供的建議旨在幫助企業全面、有意識地做出知情的選擇,同時避免受到不必要的干擾。
盡管這個領域看似發展迅猛,但其中一些核心的基礎要素發展步伐相對較慢。團隊專注于這些穩定不變的因素,以此構建論證的邏輯基礎。通過深入理解這些不變的基本面,企業可以更穩健地把握AI轉型的方向和步驟。
Synergizing Human-AI Agency: A Guide of 23 Heuristics for Service Co-Creation with LLM-Based Agents
論文地址:https://arxiv.org/abs/2310.15065
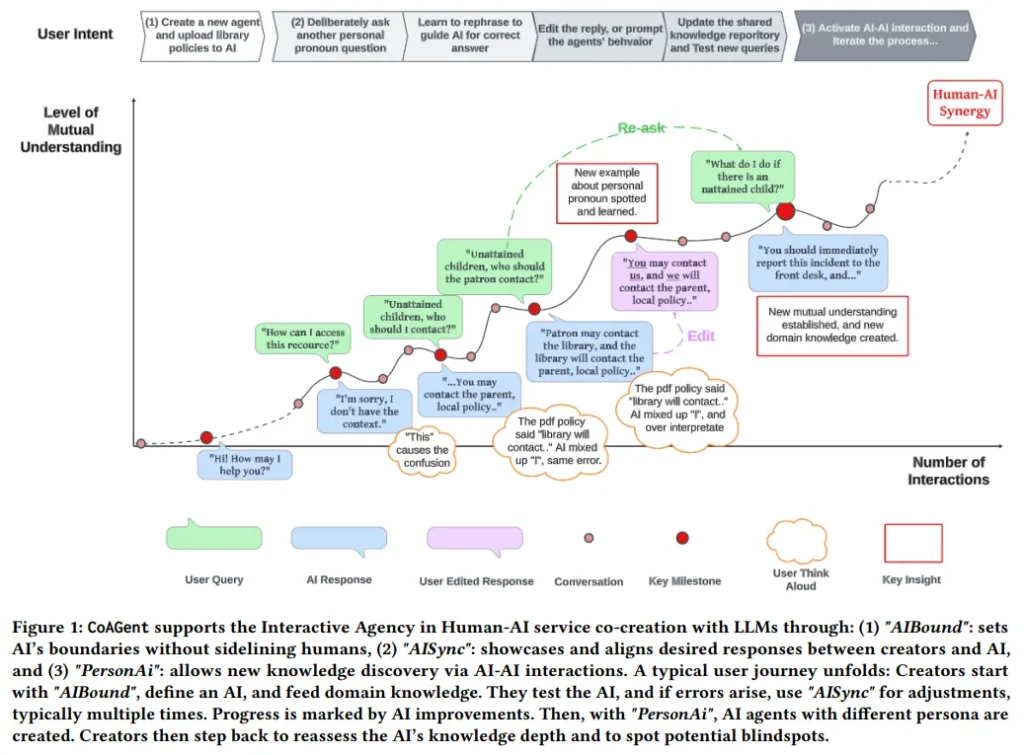
本項實證研究為服務供應商提供了入門知識,幫助他們確定是否以及如何將大型語言模型(LLM)技術集成到其從業者和更廣泛社區的工作之中。通過CoAGent——一種與基于LLM的智能體共同創造服務的工具,研究團隊探索了非AI專家與AI相互學習的過程。
這項研究通過與23位來自美國公共圖書館的領域專家合作,經歷了一個三階段的參與式設計流程,揭示了將AI集成到人類工作流程中所面臨的根本性挑戰。
研究結果提供了23種可操作的“與AI共同創造服務的啟發式方法”,這些方法突出了人類與AI之間微妙的共同責任。并進一步提出了人工智能的9個基本智能體方面,強調了所有權、公平待遇和言論自由等基本要素。這種創新方法通過將AI視為關鍵利益相關者,并利用AI與AI的交互來識別盲點,從而豐富了參與式設計模型。
這些見解為服務環境中協同和道德的人類與AI共創鋪平了道路,為人工智能共存的勞動力生態系統做好了準備。這不僅為服務供應商提供了實用的指導,也為構建人機協作的未來提供了寶貴的洞見。
The Foundations of Computational Management: A Systematic Approach to Task Automation for the Integration of Artificial Intelligence into Existing Workflows
論文地址:https://arxiv.org/abs/2402.05142
在AI迅猛發展的今天,組織面臨一個核心問題:如何將AI技術有效融入現有運營?為解答這一問題、調控期望并減少挑戰,該論文引入了計算管理——一種系統化的任務自動化方法,旨在增強組織利用AI的潛力。計算管理融合了管理科學的戰略洞察與計算思維的分析精確性,架設了二者之間的橋梁。
論文提供三個分步流程,以助于在工作流中啟動AI的集成。
首先是任務(重新)制定,它將工作活動拆解為基本單元,每個單元由智能體執行,包括明確行動并產生多樣結果。
第二,評估任務自動化潛力,通過任務自動化指數對任務進行評估,依據其標準化輸入、規則明確性、重復性、數據依賴性和客觀輸出進行排序。
第三,任務規范模板詳述了16個關鍵組件,作為選擇或調整AI解決方案以適應現有工作流程的清單。
這些流程結合了手動和自動方法,并為現有的大型語言模型(LLM)提供了使用提示,以輔助完成這些步驟。計算管理為人與AI的協同提供了路線圖和工具,提升了組織效率和創新力,為人機共榮的未來鋪平了道路。
注:本文論文敘述部分配圖,皆來自論文截圖,具體內容請參考論文詳情。
本文轉自 微信公眾號@王吉偉







