
 |
網(wǎng)站在線爬蟲服務-grabz
專用API
【更新時間: 2024.08.08】
GrabzIt提供的在線爬蟲服務簡化了網(wǎng)頁數(shù)據(jù)抓取。用戶可自定義目標網(wǎng)站和數(shù)據(jù)類型,設(shè)置存儲與傳輸方式,實現(xiàn)數(shù)據(jù)的自動化提取與分析。
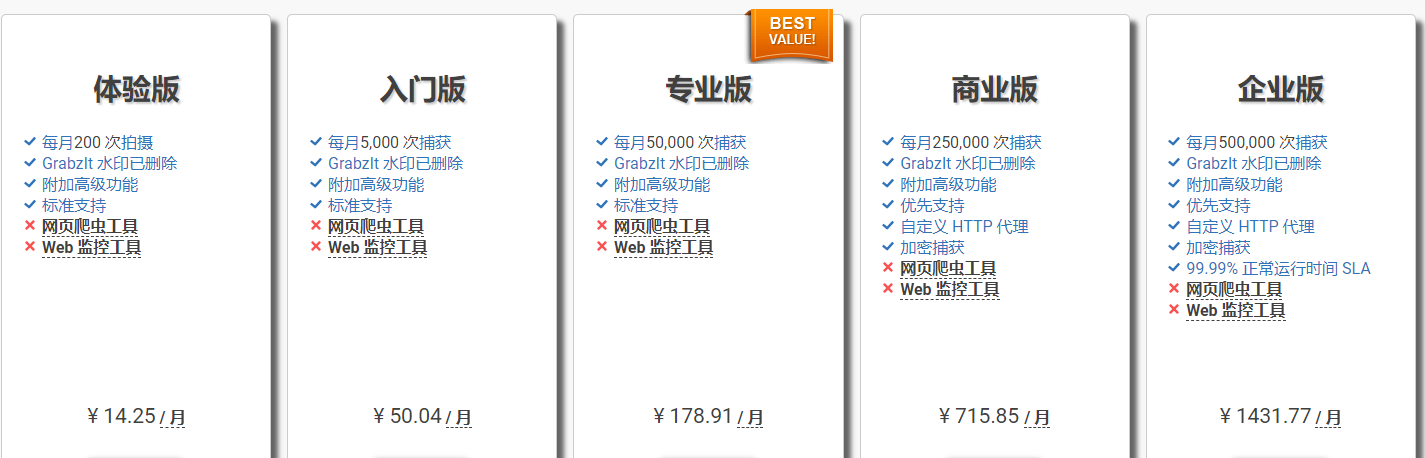
¥ 14.25 / 月
去服務商官網(wǎng)采購>
|
瀏覽次數(shù)
54
采購人數(shù)
3
試用次數(shù)
0
 SLA: N/A
響應: N/A
適用于個人&企業(yè)
SLA: N/A
響應: N/A
適用于個人&企業(yè)
收藏
×
完成
取消
×
書簽名稱
確定
|


- API詳情
- 定價
- 使用指南
- 常見 FAQ
- 關(guān)于我們
- 相關(guān)推薦


什么是grabz的網(wǎng)站在線爬蟲服務?
grabz網(wǎng)站在線爬蟲服務指的是GrabzIt提供的在線網(wǎng)頁抓取服務,它簡化了從互聯(lián)網(wǎng)上任何網(wǎng)站抓取數(shù)據(jù)的過程。通過該服務,用戶可以定義目標網(wǎng)站、指定要抓取的數(shù)據(jù)類型以及數(shù)據(jù)的存儲和傳輸方式,從而實現(xiàn)自動化的數(shù)據(jù)提取和分析。
grabz的網(wǎng)站在線爬蟲服務有哪些核心功能?
-
網(wǎng)頁轉(zhuǎn)圖像:使用我們的API將網(wǎng)頁轉(zhuǎn)換為圖像。
-
HTML轉(zhuǎn)DOCX: 利用我們的API實現(xiàn)HTML和網(wǎng)頁到DOCX格式的轉(zhuǎn)換。
-
TML表格轉(zhuǎn)CSV: 我們的API支持將HTML表格轉(zhuǎn)換成CSV、JSON或Excel格式。
-
URL轉(zhuǎn)呈現(xiàn)HTML:獲取執(zhí)行所有資源后網(wǎng)頁的實際HTML。
-
URL轉(zhuǎn)PDF或HTML轉(zhuǎn)PDF: 使用我們的API將網(wǎng)頁或HTML轉(zhuǎn)換成PDF格式,便于離線瀏覽。
-
視頻轉(zhuǎn)GIF:利用我們的API將YouTube、Vimeo等在線視頻轉(zhuǎn)換為GIF動畫。
-
網(wǎng)頁轉(zhuǎn)圖標: 通過我們的API,根據(jù)網(wǎng)頁元數(shù)據(jù)為任何URL生成圖像圖標。
-
HTML轉(zhuǎn)視頻:使用我們的API將HTML或URL轉(zhuǎn)換為加載完成的網(wǎng)頁視頻。
grabz的網(wǎng)站在線爬蟲服務的核心優(yōu)勢是什么?
- 易用性:設(shè)計簡單,用戶無需編程技能即可使用,大大降低了使用門檻。
- 高效性:支持多瀏覽器實例和代理服務器,加快抓取速度,避免被目標網(wǎng)站阻塞。
- 靈活性:提供豐富的選項和配置,滿足不同用戶的個性化需求。
- 準確性:能夠處理復雜的網(wǎng)頁結(jié)構(gòu)和動態(tài)內(nèi)容,確保抓取數(shù)據(jù)的準確性和完整性。
- 可擴展性:支持大規(guī)模數(shù)據(jù)抓取,滿足企業(yè)級應用的需求。
在哪些場景會用到grabz的網(wǎng)站在線爬蟲服務?
1. 數(shù)據(jù)收集與分析
- 市場調(diào)研:企業(yè)可以利用GrabzIt API接口從多個網(wǎng)站收集競爭對手的產(chǎn)品信息、價格策略、市場活動等數(shù)據(jù),用于市場趨勢分析、競爭對手分析以及市場策略制定。
- 行業(yè)報告:分析師和顧問公司可以使用該API接口從多個來源抓取數(shù)據(jù),整合成行業(yè)報告,為客戶提供深入的市場洞察。

2. 內(nèi)容聚合與展示
- 內(nèi)容聚合平臺:如新聞聚合網(wǎng)站、電商平臺的價格比較工具等,可以使用GrabzIt API接口從多個網(wǎng)站抓取內(nèi)容,并在自己的平臺上進行展示,為用戶提供更全面的信息和服務。
- 垂直領(lǐng)域應用:在特定行業(yè)或垂直領(lǐng)域,如房地產(chǎn)、汽車等,應用可以抓取相關(guān)網(wǎng)站的數(shù)據(jù),為用戶提供更精準的信息檢索和比較功能。

3. SEO與網(wǎng)站監(jiān)控
- SEO優(yōu)化:SEO從業(yè)者可以利用GrabzIt API接口監(jiān)控網(wǎng)站在搜索引擎中的排名和表現(xiàn),評估SEO策略的效果,并根據(jù)數(shù)據(jù)反饋調(diào)整優(yōu)化策略。
- 網(wǎng)站健康檢查:網(wǎng)站管理員可以使用該API接口定期檢查網(wǎng)站的關(guān)鍵頁面和內(nèi)容是否正常運行,及時發(fā)現(xiàn)并處理潛在的問題。

4. 自動化測試與監(jiān)控
- 軟件測試:在軟件開發(fā)和測試階段,開發(fā)團隊可以使用GrabzIt API接口自動化地抓取網(wǎng)頁,以測試網(wǎng)站的功能和性能是否符合預期。
- 網(wǎng)站監(jiān)控:運維團隊可以使用該API接口對網(wǎng)站進行實時監(jiān)控,確保網(wǎng)站在高并發(fā)、高負載等情況下仍能穩(wěn)定運行。

1. 確定目標網(wǎng)站
定義要從哪些網(wǎng)站、文件或網(wǎng)站部分抓取數(shù)據(jù)。然后安排執(zhí)行此操作的時間。
2. 指定數(shù)據(jù)指定要抓取的數(shù)據(jù)
定義要抓取網(wǎng)頁或文件的哪些部分。接下來,定義如何存儲這些數(shù)據(jù)。
3. 封裝數(shù)據(jù)打包抓取的數(shù)據(jù)
指定存儲數(shù)據(jù)的文件格式。最后指定您希望如何將抓取數(shù)據(jù)傳輸給您。
指南詳情鏈接:https://grabz.it/scraper/
創(chuàng)始人
我們的創(chuàng)始人Dominic Skinner(理學學士、理學碩士)是一位經(jīng)驗豐富的網(wǎng)絡(luò)開發(fā)人員,他創(chuàng)辦 GrabzIt 的目的是讓網(wǎng)絡(luò)完全機器可讀。我們?nèi)栽谂崿F(xiàn)這一目標。他利用自己多年的軟件工程經(jīng)驗,努力讓 GrabzIt 的所有服務盡可能地對其他網(wǎng)絡(luò)開發(fā)人員和非網(wǎng)絡(luò)開發(fā)人員有用。
基礎(chǔ)設(shè)施
GrabzIt 網(wǎng)絡(luò)
左側(cè)是我們的 Web 服務架構(gòu)的簡化圖。雖然實際上涉及的服務器更多,但在適用時,這些服務器會為對我們的 Web 服務發(fā)出的請求提供緩存響應。所有這些都是為了使我們的系統(tǒng)具有大規(guī)模可擴展性,并允許我們在需要時輕松擴展我們的能力。
由于我們的系統(tǒng)滿足全球眾多客戶的需求,因此它在設(shè)計上盡可能可靠,并在系統(tǒng)架構(gòu)的所有層中內(nèi)置了多個冗余系統(tǒng)。
結(jié)合所有這些因素,您應該可以自信地選擇 GrabzIt 來解決您的數(shù)據(jù)捕獲需求。
1. 確定目標網(wǎng)站
定義要從哪些網(wǎng)站、文件或網(wǎng)站部分抓取數(shù)據(jù)。然后安排執(zhí)行此操作的時間。
2. 指定數(shù)據(jù)指定要抓取的數(shù)據(jù)
定義要抓取網(wǎng)頁或文件的哪些部分。接下來,定義如何存儲這些數(shù)據(jù)。
3. 封裝數(shù)據(jù)打包抓取的數(shù)據(jù)
指定存儲數(shù)據(jù)的文件格式。最后指定您希望如何將抓取數(shù)據(jù)傳輸給您。
指南詳情鏈接:https://grabz.it/scraper/
創(chuàng)始人
我們的創(chuàng)始人Dominic Skinner(理學學士、理學碩士)是一位經(jīng)驗豐富的網(wǎng)絡(luò)開發(fā)人員,他創(chuàng)辦 GrabzIt 的目的是讓網(wǎng)絡(luò)完全機器可讀。我們?nèi)栽谂崿F(xiàn)這一目標。他利用自己多年的軟件工程經(jīng)驗,努力讓 GrabzIt 的所有服務盡可能地對其他網(wǎng)絡(luò)開發(fā)人員和非網(wǎng)絡(luò)開發(fā)人員有用。
基礎(chǔ)設(shè)施
GrabzIt 網(wǎng)絡(luò)
左側(cè)是我們的 Web 服務架構(gòu)的簡化圖。雖然實際上涉及的服務器更多,但在適用時,這些服務器會為對我們的 Web 服務發(fā)出的請求提供緩存響應。所有這些都是為了使我們的系統(tǒng)具有大規(guī)模可擴展性,并允許我們在需要時輕松擴展我們的能力。
由于我們的系統(tǒng)滿足全球眾多客戶的需求,因此它在設(shè)計上盡可能可靠,并在系統(tǒng)架構(gòu)的所有層中內(nèi)置了多個冗余系統(tǒng)。
結(jié)合所有這些因素,您應該可以自信地選擇 GrabzIt 來解決您的數(shù)據(jù)捕獲需求。

