
 |
Dolly開源大語言模型
專用API
【更新時間: 2024.08.20】
Dolly模型是由Databricks出品的大規(guī)模語言模型。數(shù)據(jù)集包括頭腦風暴、分類、生成、問答、信息抽取等任務的語料。
|
瀏覽次數(shù)
55
采購人數(shù)
2
試用次數(shù)
0
 SLA: N/A
響應: N/A
適用于個人&企業(yè)
SLA: N/A
響應: N/A
適用于個人&企業(yè)
收藏
×
完成
取消
×
書簽名稱
確定
|



- API詳情
- 定價
- 使用指南
- 常見 FAQ
- 關于我們
- 相關推薦


什么是Dolly開源大語言模型?
Dolly模型是由Databricks出品的大規(guī)模語言模型,它在DashScope上中模型名稱為"dolly-12b-v2"。該模型是在pythia-12b的基礎上,使用databricks-dolly-15k數(shù)據(jù)集微調(diào)得到的。數(shù)據(jù)集包括頭腦風暴、分類、生成、問答、信息抽取等任務的語料。更多信息可以參考Dolly的開源repo。Dolly以用戶文本形式輸入的指令(prompt)作為輸入,返回模型生成的回復作為輸出。在這一過程中,文本將被轉(zhuǎn)換為語言模型可以處理的token序列。由于模型調(diào)用的計算量與token序列長度相關,輸入或輸出token數(shù)量越多,模型的計算時間越長,我們將根據(jù)模型輸入和輸出的token數(shù)量計費。可以從API返回結(jié)果的usage字段中了解到您每次調(diào)用時使用的token數(shù)量。

Dolly開源大語言模型有哪些核心功能?
- 自然語言處理:Dolly能夠處理和理解大量的自然語言文本,包括中文和其他多種語言(取決于其訓練數(shù)據(jù)的范圍)。
- 文本生成:基于輸入的指令或上下文,Dolly能夠生成高質(zhì)量的文本內(nèi)容,如文章、對話、摘要等。
- 指令遵循:Dolly在手動生成的指令數(shù)據(jù)集上進行了微調(diào),能夠遵循用戶的指令完成特定任務,如問答、分類、信息提取等。
- 多場景應用:由于其強大的自然語言處理能力和靈活性,Dolly可以應用于多種場景,如智能客服、文本創(chuàng)作、內(nèi)容推薦等。
Dolly開源大語言模型的核心優(yōu)勢是什么?
- 開源性:Dolly的源代碼、訓練數(shù)據(jù)和模型權(quán)重都是開放的,任何人都可以自由訪問、使用、修改和擴展。這種開源性促進了技術(shù)的共享和創(chuàng)新,降低了使用門檻。
- 可擴展性與靈活性:開發(fā)者可以根據(jù)自己的需求對Dolly進行修改和優(yōu)化,以適應不同的應用場景和任務。這種可擴展性和靈活性使得Dolly能夠更好地滿足企業(yè)和組織的定制化需求。
- 高性能與準確性:Dolly在多個任務上表現(xiàn)出了高性能和準確性,如問答、文本生成、分類等。這得益于其基于大規(guī)模數(shù)據(jù)集的訓練和微調(diào)。
- 多語言支持:Dolly支持多語言輸入,這使得它可以在全球范圍內(nèi)得到廣泛應用,滿足不同語言用戶的需求。
在哪些場景會用到Dolly開源大語言模型?
- 智能客服:在電商、銀行、電信等行業(yè)的客戶服務部門,Dolly可以作為智能客服系統(tǒng)的核心,自動處理用戶咨詢和投訴,提供快速準確的回答。

- 內(nèi)容創(chuàng)作:在廣告、媒體、出版等行業(yè),Dolly可以輔助內(nèi)容創(chuàng)作者生成高質(zhì)量的文案、文章、新聞稿等,提高創(chuàng)作效率和質(zhì)量。
- 數(shù)據(jù)分析與挖掘:在數(shù)據(jù)分析和挖掘領域,Dolly可以處理和分析大量文本數(shù)據(jù),提取有用信息,為決策提供支持。
- 教育與學習輔助:在教育領域,Dolly可以作為學習輔助工具,為學生提供個性化的學習建議和解答疑惑,提高學習效果。


計費單元
|
模型服務 |
計費單元 |
|
Dolly開源大語言模型 |
令 牌 |
Token是模型用來表示自然語言文本的基本單位,可以直觀的理解為“字”或“詞”。對于中文文本來說,1個token通常對應一個漢字;對于英文文本來說,1個token通常對應3至4個字母。
Dolly模型服務根據(jù)模型輸入和輸出的總token數(shù)量進行計量計費,其中多輪對話中的history作為輸入也會進行計量計費。每一次模型調(diào)用產(chǎn)生的實際token數(shù)量可以從 response 中獲取。
計費單價
|
模型服務 |
模型名 |
計費單價 |
|
Dolly開源大語言模型 |
小車-12B-V2 |
限時免費中。 |
免費額度
|
模型服務 |
模型名 |
免費額度 |
|
Dolly開源大語言模型 |
小車-12B-V2 |
申請體驗通過后,提供100,000 tokens免費使用額度。 |
-
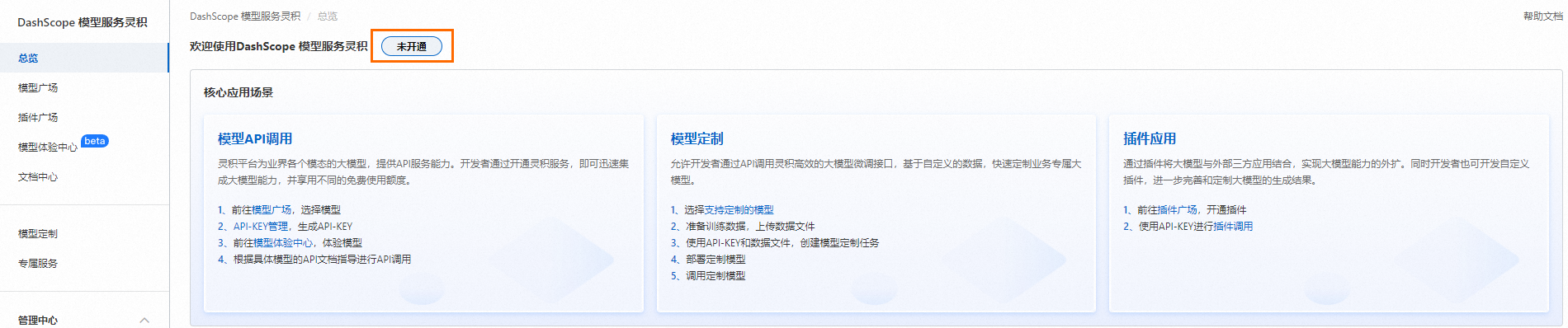
登錄DashScope控制臺。
-
單擊未開通。
-
閱讀服務協(xié)議,然后單擊立即開通。
指南詳情鏈接:https://help.aliyun.com/zh/dashscope/opening-service?spm=a2c4g.11186623.0.0.4e862c9aY1rf1q


計費單元
|
模型服務 |
計費單元 |
|
Dolly開源大語言模型 |
令 牌 |
Token是模型用來表示自然語言文本的基本單位,可以直觀的理解為“字”或“詞”。對于中文文本來說,1個token通常對應一個漢字;對于英文文本來說,1個token通常對應3至4個字母。
Dolly模型服務根據(jù)模型輸入和輸出的總token數(shù)量進行計量計費,其中多輪對話中的history作為輸入也會進行計量計費。每一次模型調(diào)用產(chǎn)生的實際token數(shù)量可以從 response 中獲取。
計費單價
|
模型服務 |
模型名 |
計費單價 |
|
Dolly開源大語言模型 |
小車-12B-V2 |
限時免費中。 |
免費額度
|
模型服務 |
模型名 |
免費額度 |
|
Dolly開源大語言模型 |
小車-12B-V2 |
申請體驗通過后,提供100,000 tokens免費使用額度。 |
-
登錄DashScope控制臺。
-
單擊未開通。
-
閱讀服務協(xié)議,然后單擊立即開通。
指南詳情鏈接:https://help.aliyun.com/zh/dashscope/opening-service?spm=a2c4g.11186623.0.0.4e862c9aY1rf1q

