
 |
Crawlbase 網(wǎng)頁內(nèi)容提取
專用API
【更新時(shí)間: 2024.08.01】
Crawlbase 提供了一種強(qiáng)大的爬蟲 API,旨在保護(hù)網(wǎng)絡(luò)爬蟲免受請(qǐng)求阻塞、代理故障和驗(yàn)證碼等問題的影響。該服務(wù)支持無帶寬限制的網(wǎng)頁數(shù)據(jù)抓取,具有99%的成功率,并能夠處理常規(guī)和動(dòng)態(tài)生成的網(wǎng)頁。
免費(fèi)
去服務(wù)商官網(wǎng)采購>
|
瀏覽次數(shù)
130
采購人數(shù)
3
試用次數(shù)
0
 SLA: N/A
響應(yīng): N/A
適用于個(gè)人&企業(yè)
SLA: N/A
響應(yīng): N/A
適用于個(gè)人&企業(yè)
試用
收藏
×
完成
取消
×
書簽名稱
確定
|

- API詳情
- 定價(jià)
- 使用指南
- 常見 FAQ
- 關(guān)于我們
- 相關(guān)推薦


什么是Crawlbase 網(wǎng)頁內(nèi)容提取?
Crawlbase 網(wǎng)頁內(nèi)容提取是一個(gè)功能強(qiáng)大的API服務(wù),它允許用戶通過簡(jiǎn)化的方式獲取網(wǎng)頁的HTML源代碼。這個(gè)API服務(wù)特別注重隱私保護(hù)和數(shù)據(jù)安全,確保用戶的爬取行為不被網(wǎng)站所有者追蹤。Crawlbase 覆蓋了全球范圍內(nèi)的眾多網(wǎng)站,支持各種類型的數(shù)據(jù)提取需求,從簡(jiǎn)單的文本信息到復(fù)雜的網(wǎng)頁結(jié)構(gòu)數(shù)據(jù)均可應(yīng)對(duì)。

什么是Crawlbase 網(wǎng)頁內(nèi)容提取接口?
Crawlbase 網(wǎng)頁內(nèi)容提取有哪些核心功能?
1.高性能網(wǎng)頁爬取:在大規(guī)模的數(shù)據(jù)收集項(xiàng)目中,如價(jià)格監(jiān)控、市場(chǎng)分析或競(jìng)品分析等,Crawlbase能夠高速訪問和下載網(wǎng)頁內(nèi)容,顯著減少數(shù)據(jù)收集所需時(shí)間。
2.API集成:開發(fā)者可以將Crawlbase的API集成到自定義應(yīng)用程序中,實(shí)現(xiàn)自動(dòng)化的數(shù)據(jù)抓取和處理流程。使得外部應(yīng)用能夠直接利用Crawlbase的強(qiáng)大爬取功能,進(jìn)一步擴(kuò)展應(yīng)用的功能和效率。
3.實(shí)時(shí)數(shù)據(jù)抓取:對(duì)于需要實(shí)時(shí)監(jiān)控?cái)?shù)據(jù)變化的場(chǎng)景(如股票價(jià)格監(jiān)控、新聞更新等),Crawlbase能提供實(shí)時(shí)的數(shù)據(jù)抓取服務(wù)。確保用戶能夠獲取最新的信息,做出及時(shí)的決策或調(diào)整策略。
Crawlbase 網(wǎng)頁內(nèi)容提取的核心優(yōu)勢(shì)是什么?
借助我們?yōu)榇蜷_互聯(lián)網(wǎng)數(shù)據(jù)自由之門而創(chuàng)建的工具,您可以在幾分鐘內(nèi)開始抓取和抓取網(wǎng)站。
 |
 |
 |
|
1.節(jié)省 60% 的人力 通過改用我們的無代理抓取解決方案,8 家公 司中有 10 家節(jié)省了超過 60% 的人力。從而 為企業(yè)帶來了更高的運(yùn)營效益和競(jìng)爭(zhēng)力。
|
2.擺脫排隊(duì)系統(tǒng) 將他們的隊(duì)列移動(dòng)到我們的 Crawler 云基礎(chǔ) 設(shè)施的公司,完全擺脫了他們的隊(duì)列系統(tǒng) , 避免了不必要的瓶頸。
|
3.24 / 7客戶支持 開發(fā)人員為開發(fā)人員構(gòu)建的易于使用的爬蟲 API。 繞過塊和驗(yàn)證碼并在不維護(hù)基礎(chǔ)架構(gòu) 的情況下抓取任何網(wǎng)站。
|
 |
 |
 |
|
4.節(jié)省多達(dá) 200 小時(shí) 使用我們的內(nèi)置刮刀,每月可為您的團(tuán)隊(duì)節(jié)省 200 多個(gè)工作小時(shí)。 |
5.節(jié)省高達(dá)$ 8500 平均而言,我們的客戶每月在代理上節(jié)省超過 8500 美元,這是您已經(jīng)在代理上花費(fèi)的資金 的 50%。 |
6.規(guī)避風(fēng)險(xiǎn) 在美國,每年 1 家公司中有 20 家因訪問公 共數(shù)據(jù)而被起訴。 使用我們完全匿名避免風(fēng)險(xiǎn)。 |
在哪些場(chǎng)景會(huì)用到Crawlbase 網(wǎng)頁內(nèi)容提取?
|
1.定期收集 YouTube 數(shù)據(jù) 在數(shù)字營銷和內(nèi)容分析領(lǐng)域,持續(xù)監(jiān)控和分析 YouTube 上的數(shù)據(jù)對(duì) 于業(yè)務(wù)成功至關(guān)重要 。Crawlbase 為 UpscaleMethod 提供了強(qiáng)大 的支持 ,確保其能夠不間斷地滿足對(duì)評(píng)論和分析數(shù)據(jù)的需求,從而優(yōu) 化內(nèi)容策略并提升用戶參與度。 |
 |
 |
2.掃描網(wǎng)站以測(cè)試問題 在網(wǎng)站性能和用戶體驗(yàn)日益重要的今天,能夠及時(shí)發(fā)現(xiàn)并解決網(wǎng)站問 題是提升用戶滿意度的關(guān)鍵 。Crawlbase 幫助 PageWatch 有效地 測(cè)試那些難以抓取的網(wǎng)站,確保了網(wǎng)站的穩(wěn)定性和可靠性,進(jìn)而增強(qiáng) 了用戶對(duì) PageWatch 服務(wù)結(jié)果的信心。 |
|
3.大規(guī)模抓取產(chǎn)品數(shù)據(jù)并快速發(fā)展您的業(yè)務(wù) 在電子商務(wù)和市場(chǎng)分析領(lǐng)域,快速獲取大量的產(chǎn)品數(shù)據(jù)是企業(yè)擴(kuò)大市 場(chǎng)份額和提升運(yùn)營效率的關(guān)鍵 。Crawlbase 極大地簡(jiǎn)化了數(shù)據(jù)收集 過程,使企業(yè)能夠輕松地獲取所需的各種數(shù)據(jù)。 |
 |
4.抓取博客文章以創(chuàng)建摘要
在內(nèi)容聚合和信息提煉方面,能夠快速獲取并處理大量文本數(shù)據(jù)是提供高質(zhì)量服務(wù)的基礎(chǔ)。Crawlbase 為內(nèi)容平臺(tái)提供了一種高效的方式來抓取博客文章并創(chuàng)建準(zhǔn)確的摘要,這對(duì)于為用戶提供相關(guān)且及時(shí)的內(nèi)容至關(guān)重要。


數(shù)分鐘內(nèi)的抓取 API
我們創(chuàng)建了一個(gè) API,它可以讓 Crawlbase 非常容易地集成到您的爬蟲項(xiàng)目中。
#您的第一個(gè) API 調(diào)用
所有 API URL 都以以下基本部分開頭: https://api.crawlbase.com
因此,撥打您的第一個(gè)電話就像在終端中運(yùn)行以下行一樣簡(jiǎn)單。
繼續(xù)嘗試!
curl 'https://api.crawlbase.com/?token=USER_TOKEN&url=https%3A%2F%2Fgithub.com%2Fcrawlbase%3Ftab%3Drepositories'有時(shí)使用普通令牌是不夠的,因?yàn)樵撜军c(diǎn)僅在啟用 JavaScript 瀏覽器時(shí)才能工作,或者因?yàn)槟枰膬?nèi)容是通過客戶端的 JavaScript 呈現(xiàn)的,因此您需要使用 JavaScript 令牌。
來試試 JS 爬取吧!
curl 'https://api.crawlbase.com/?token=USER_TOKEN&url=https%3A%2F%2Fgithub.com%2Fcrawlbase%3Ftab%3Drepositories'#免費(fèi)試用
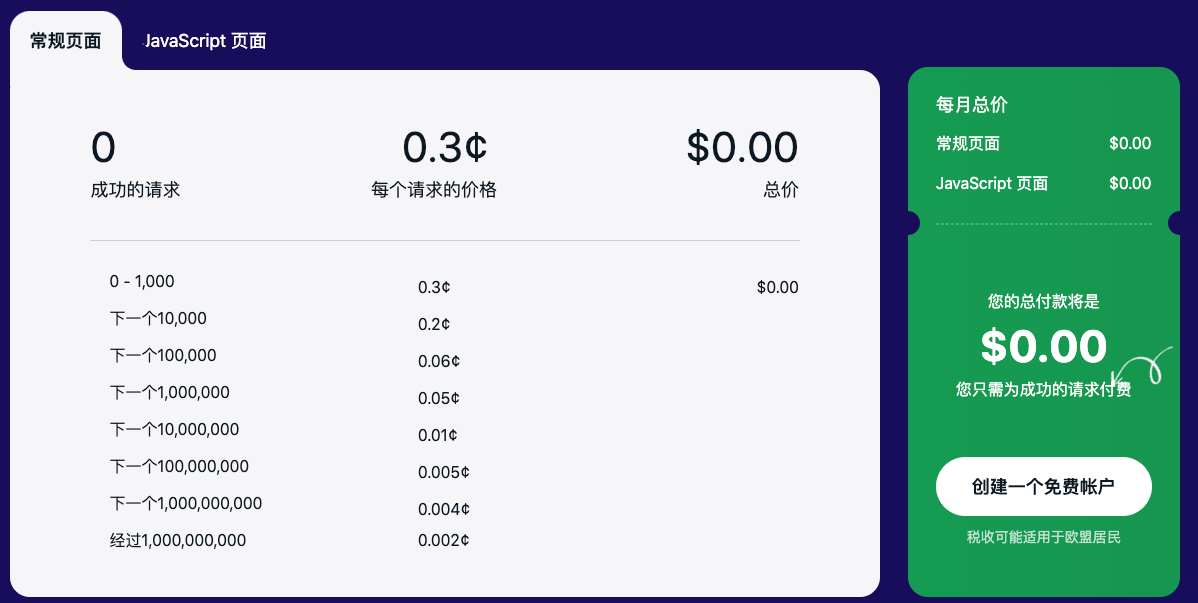
前 1,000 個(gè)請(qǐng)求是免費(fèi)的。
確保充分使用免費(fèi)試用版!
#速率限制
API 的速率限制為最大值 每秒 20 個(gè)請(qǐng)求, 每個(gè)令牌(可根據(jù)要求增加速率限制)。
這意味著您可以發(fā)送 每秒最多 20 個(gè)請(qǐng)求,這意味著每月大約 51 萬個(gè)請(qǐng)求,無論他們使用多少線程。
API 將響應(yīng) 429 超過速率限制時(shí)的狀態(tài)碼。
請(qǐng)注意: 某些特定網(wǎng)站可能有較低的限制。 如果您需要更高的限制,請(qǐng) 聯(lián)系支持 (打開新窗口) (opens new window).
#API 響應(yīng)時(shí)間
API 的平均響應(yīng)時(shí)間在 4 到 10 秒之間,但 我們推薦 為至少 90 秒的調(diào)用設(shè)置超時(shí)。
#成功與失敗
我們只對(duì)成功的請(qǐng)求收費(fèi)(請(qǐng)參閱 原始狀態(tài) 和 電腦狀態(tài) 在下面的響應(yīng)參數(shù)中)。
#其他說明
- 如果您更喜歡使用庫來集成 Crawlbase,您可以查看可用的 API庫在這里 (打開新窗口) (opens new window).
- 建議使用 Accept-Encoding gzip 標(biāo)頭。
- 如果您使用 Scrapy for python,請(qǐng)確保 禁用 DNS 緩存 (打開新窗口) (opens new window).
#
#

數(shù)分鐘內(nèi)的抓取 API
我們創(chuàng)建了一個(gè) API,它可以讓 Crawlbase 非常容易地集成到您的爬蟲項(xiàng)目中。
#您的第一個(gè) API 調(diào)用
所有 API URL 都以以下基本部分開頭: https://api.crawlbase.com
因此,撥打您的第一個(gè)電話就像在終端中運(yùn)行以下行一樣簡(jiǎn)單。
繼續(xù)嘗試!
curl 'https://api.crawlbase.com/?token=USER_TOKEN&url=https%3A%2F%2Fgithub.com%2Fcrawlbase%3Ftab%3Drepositories'有時(shí)使用普通令牌是不夠的,因?yàn)樵撜军c(diǎn)僅在啟用 JavaScript 瀏覽器時(shí)才能工作,或者因?yàn)槟枰膬?nèi)容是通過客戶端的 JavaScript 呈現(xiàn)的,因此您需要使用 JavaScript 令牌。
來試試 JS 爬取吧!
curl 'https://api.crawlbase.com/?token=USER_TOKEN&url=https%3A%2F%2Fgithub.com%2Fcrawlbase%3Ftab%3Drepositories'#免費(fèi)試用
前 1,000 個(gè)請(qǐng)求是免費(fèi)的。
確保充分使用免費(fèi)試用版!
#速率限制
API 的速率限制為最大值 每秒 20 個(gè)請(qǐng)求, 每個(gè)令牌(可根據(jù)要求增加速率限制)。
這意味著您可以發(fā)送 每秒最多 20 個(gè)請(qǐng)求,這意味著每月大約 51 萬個(gè)請(qǐng)求,無論他們使用多少線程。
API 將響應(yīng) 429 超過速率限制時(shí)的狀態(tài)碼。
請(qǐng)注意: 某些特定網(wǎng)站可能有較低的限制。 如果您需要更高的限制,請(qǐng) 聯(lián)系支持 (打開新窗口) (opens new window).
#API 響應(yīng)時(shí)間
API 的平均響應(yīng)時(shí)間在 4 到 10 秒之間,但 我們推薦 為至少 90 秒的調(diào)用設(shè)置超時(shí)。
#成功與失敗
我們只對(duì)成功的請(qǐng)求收費(fèi)(請(qǐng)參閱 原始狀態(tài) 和 電腦狀態(tài) 在下面的響應(yīng)參數(shù)中)。
#其他說明
- 如果您更喜歡使用庫來集成 Crawlbase,您可以查看可用的 API庫在這里 (打開新窗口) (opens new window).
- 建議使用 Accept-Encoding gzip 標(biāo)頭。
- 如果您使用 Scrapy for python,請(qǐng)確保 禁用 DNS 緩存 (打開新窗口) (opens new window).
#
#

