
 |
AssemblyAI 流媒體語音到文本
專用API
【更新時間: 2024.07.12】
將實(shí)時音頻流同步轉(zhuǎn)換為文本,準(zhǔn)確率接近90%,延遲600毫秒。同步轉(zhuǎn)錄對話、會議和現(xiàn)場活動,即時提升現(xiàn)場互動。
|
瀏覽次數(shù)
22
采購人數(shù)
2
試用次數(shù)
0
 SLA: N/A
響應(yīng): N/A
適用于個人&企業(yè)
SLA: N/A
響應(yīng): N/A
適用于個人&企業(yè)
試用
收藏
×
完成
取消
×
書簽名稱
確定
|


- API詳情
- 定價
- 使用指南
- 常見 FAQ
- 關(guān)于我們
- 相關(guān)推薦


什么是AssemblyAI 流媒體語音到文本?
將實(shí)時音頻流同步轉(zhuǎn)換為文本,準(zhǔn)確率接近 90%,延遲小于 600 毫秒。
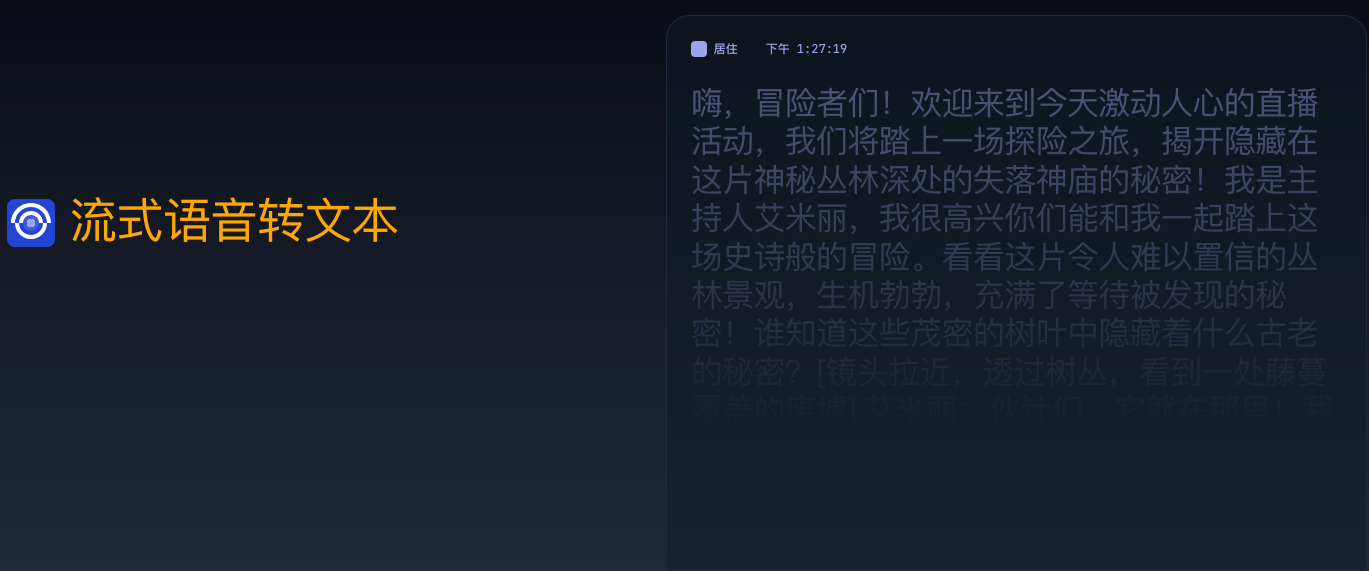
AssemblyAI 流媒體語音到文本有哪些核心功能?
1. 自動將現(xiàn)場音頻轉(zhuǎn)換為文本:同步轉(zhuǎn)錄對話、會議和現(xiàn)場活動,并立即提升現(xiàn)場互動。
2. 流式轉(zhuǎn)錄:以高精度、低延遲轉(zhuǎn)錄現(xiàn)場音頻。
3. 自動標(biāo)點(diǎn)和大小寫:自動為轉(zhuǎn)錄文本添加專有名詞的大小寫和標(biāo)點(diǎn)符號。
4. 自定義詞匯:提高針對您的特定用例或產(chǎn)品所特有或定制的詞匯的準(zhǔn)確性。
5. ITN/格式化:自動將口頭形式的文本轉(zhuǎn)換為正確的書面格式,以提高文字記錄的可讀性。
6. 話語結(jié)束檢測:自定義話語結(jié)束檢測,以便更準(zhǔn)確地檢測一個說話者在流式語音轉(zhuǎn)文本中何時結(jié)束話語。
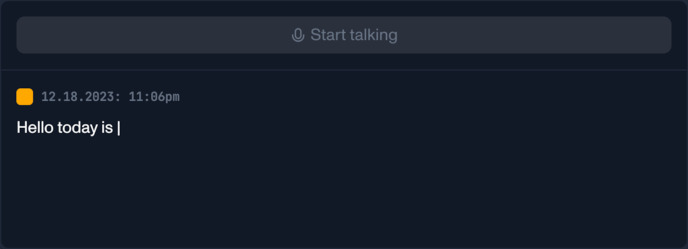
AssemblyAI 流媒體語音到文本的核心優(yōu)勢是什么?
 |
 |
 |
低延遲自動轉(zhuǎn)錄現(xiàn)場音頻,幾乎瞬間,與定制的端點(diǎn)控制。
|
行業(yè)領(lǐng)先的品質(zhì)獲得高度準(zhǔn)確的結(jié)果。
|
高并發(fā)輕松處理大容量音頻文件。
|
 |
 |
 |
|
自動添加大小寫和標(biāo)點(diǎn)符號的專有名詞的轉(zhuǎn)錄文本。
|
每月更新和改進(jìn)在我們的更新日志中查看每周的產(chǎn)品和準(zhǔn)確性改進(jìn)。 |
企業(yè)級安全性AssemblyAI致力于最高標(biāo)準(zhǔn)的安全實(shí)踐,以確保您和您客戶的數(shù)據(jù)安全。 |
在哪些場景會用到AssemblyAI 流媒體語音到文本?
1. 語音轉(zhuǎn)文本
在市場上最準(zhǔn)確的語音轉(zhuǎn)文本模型的基礎(chǔ)上構(gòu)建,準(zhǔn)確率達(dá) 92.5% 以上。

2. 語音理解
利用音頻智能從語音數(shù)據(jù)中提取最大價值,并利用 LeMUR 發(fā)揮大型語言模型的作用。

步驟1:安裝SDK?
通過pip安裝軟件包:
步驟2:配置SDK?
在這一步中,您將創(chuàng)建一個SDK客戶端,并將其配置為使用您的API密鑰。
-
瀏覽到“您的API密鑰”下的文本,然后單擊該文本以復(fù)制它。
-
使用您的API密鑰創(chuàng)建新客戶端。將
YOUR_API_KEY替換為復(fù)制的API密鑰。
步驟3:提交音頻進(jìn)行轉(zhuǎn)錄?
在此步驟中,您將提交音頻文件進(jìn)行轉(zhuǎn)錄,并等待轉(zhuǎn)錄完成。處理音頻文件所需的時間取決于其持續(xù)時間和啟用的模型。大多數(shù)的傳輸在45秒內(nèi)完成。
-
指定要轉(zhuǎn)錄的音頻的URL。URL需要可以從AssemblyAI的服務(wù)器訪問。有關(guān)支持的格式列表,請參閱常見問題解答。不支持YouTube URL。如果你想轉(zhuǎn)錄YouTube視頻,你需要先下載音頻。
-
要生成轉(zhuǎn)錄本,請將音頻URL傳遞到
transcribe()。這可能需要一分鐘,而我們正在處理音頻。
選擇語音模型您可以選擇要使用的模型類別,以實(shí)現(xiàn)最適合您的應(yīng)用程序的成本-性能權(quán)衡。請參見選擇語音模型。
-
如果轉(zhuǎn)錄失敗,轉(zhuǎn)錄的
status將被設(shè)置為error。要查看失敗的原因,您可以打印error的值。 -
打印完整的成績單。
-
運(yùn)行應(yīng)用程序并等待它完成。
您已成功轉(zhuǎn)錄第一個音頻文件。中可以查看所有已提交的轉(zhuǎn)錄作業(yè)。
步驟4:啟用其他AI模型?
通過使用轉(zhuǎn)錄選項(xiàng)啟用我們的任何AI模型,您可以從音頻中提取更多見解。在這一步中,您將啟用Speaker diarization模型來檢測誰說了什么。
-
創(chuàng)建一個
TranscriptionConfig,將speaker_labels設(shè)置為True,然后將其作為第二個參數(shù)傳遞給transcribe()。 -
除了完整的文字記錄外,您現(xiàn)在還可以訪問每個發(fā)言者的發(fā)言。
轉(zhuǎn)錄對象中的許多屬性只有在啟用相應(yīng)的模型后才可用。有關(guān)詳細(xì)信息,請參閱語音轉(zhuǎn)文本和音頻智能下的模型。
合作客戶
步驟1:安裝SDK?
通過pip安裝軟件包:
步驟2:配置SDK?
在這一步中,您將創(chuàng)建一個SDK客戶端,并將其配置為使用您的API密鑰。
-
瀏覽到“您的API密鑰”下的文本,然后單擊該文本以復(fù)制它。
-
使用您的API密鑰創(chuàng)建新客戶端。將
YOUR_API_KEY替換為復(fù)制的API密鑰。
步驟3:提交音頻進(jìn)行轉(zhuǎn)錄?
在此步驟中,您將提交音頻文件進(jìn)行轉(zhuǎn)錄,并等待轉(zhuǎn)錄完成。處理音頻文件所需的時間取決于其持續(xù)時間和啟用的模型。大多數(shù)的傳輸在45秒內(nèi)完成。
-
指定要轉(zhuǎn)錄的音頻的URL。URL需要可以從AssemblyAI的服務(wù)器訪問。有關(guān)支持的格式列表,請參閱常見問題解答。不支持YouTube URL。如果你想轉(zhuǎn)錄YouTube視頻,你需要先下載音頻。
-
要生成轉(zhuǎn)錄本,請將音頻URL傳遞到
transcribe()。這可能需要一分鐘,而我們正在處理音頻。
選擇語音模型您可以選擇要使用的模型類別,以實(shí)現(xiàn)最適合您的應(yīng)用程序的成本-性能權(quán)衡。請參見選擇語音模型。
-
如果轉(zhuǎn)錄失敗,轉(zhuǎn)錄的
status將被設(shè)置為error。要查看失敗的原因,您可以打印error的值。 -
打印完整的成績單。
-
運(yùn)行應(yīng)用程序并等待它完成。
您已成功轉(zhuǎn)錄第一個音頻文件。中可以查看所有已提交的轉(zhuǎn)錄作業(yè)。
步驟4:啟用其他AI模型?
通過使用轉(zhuǎn)錄選項(xiàng)啟用我們的任何AI模型,您可以從音頻中提取更多見解。在這一步中,您將啟用Speaker diarization模型來檢測誰說了什么。
-
創(chuàng)建一個
TranscriptionConfig,將speaker_labels設(shè)置為True,然后將其作為第二個參數(shù)傳遞給transcribe()。 -
除了完整的文字記錄外,您現(xiàn)在還可以訪問每個發(fā)言者的發(fā)言。
轉(zhuǎn)錄對象中的許多屬性只有在啟用相應(yīng)的模型后才可用。有關(guān)詳細(xì)信息,請參閱語音轉(zhuǎn)文本和音頻智能下的模型。
合作客戶

