Kafka
通用API
【更新時間: 2024.03.29】
Apache Kafka是一種高吞吐量、分布式的消息發布訂閱系統,以其強大的實時數據處理和流處理能力而廣受業界認可。
|
瀏覽次數
126
采購人數
0
試用次數
0
 適用于個人&企業
適用于個人&企業
收藏
×
完成
取消
×
書簽名稱
確定
|



- 詳情介紹
- 常見 FAQ
- 相關推薦


什么是Kafka?
"Kafka" 是一個開源的分布式流處理平臺,由Apache軟件基金會開發。它最初被設計為一個高吞吐量的分布式發布-訂閱消息系統,但隨著時間的推移,Kafka已經成為處理大規模數據流和構建實時數據管道的關鍵組件。Kafka能夠處理大量的數據,支持每秒數百萬條消息的發布和訂閱,同時保持極低的延遲。
Kafka的架構包括生產者(Producer)、消費者(Consumer)和Broker(服務器)等組件。生產者負責將消息發布到Kafka集群中的特定主題(Topic),而消費者則從主題中訂閱并消費消息。Broker則負責存儲和轉發消息,確保消息的高可用性和持久性。

Kafka有哪些核心功能?
完全兼容生態100%兼容 Apache Kafka:Kafka確保了與開源Apache Kafka的完全兼容性,這意味著任何基于Apache Kafka構建的應用程序或工具都可以無縫遷移到Kafka平臺上,無需進行代碼修改或額外適配,從而實現了零成本的遷移策略。 性能優異:除了兼容性外,Kafka還通過內部業務的不斷歷練和優化,實現了卓越的性能表現。它能夠處理高吞吐量的數據流,同時保持低延遲和高可靠性,滿足各種實時數據處理場景的需求。 |
資源池管理規格變更靈活性:Kafka支持資源池的規格變更功能,允許用戶根據業務體量的變化隨時選擇合適的資源池進行統一管理。這種靈活性確保了資源的有效利用,避免了資源的浪費或不足。 資源使用監控大屏:平臺管理員可以通過資源使用監控大屏實時查看資源池的使用情況,包括CPU、內存、磁盤I/O等關鍵指標的實時監控。這種可視化的管理方式使得管理員能夠一目了然地掌握資源池的運行狀態。 |
Topic生命周期管理Web UI化管理:Kafka提供了Topic生命周期的Web UI化管理界面,使得用戶可以通過瀏覽器輕松進行Topic的創建、刪除、修改等操作。這種管理方式不僅提高了操作的便捷性,還降低了人為錯誤的風險。 分區配置與擴容:Kafka支持對Topic的分區進行精細化的配置和擴容操作。用戶可以根據實際需求調整分區數量,以平衡數據的存儲和訪問壓力。同時,Kafka還提供了分區數據預覽功能,方便用戶了解分區內的數據分布情況。 |
消費者組管理消費狀態與Lag狀態監控:Kafka用戶實時查看消費組的消費狀態和Lag狀態。消費狀態反映了消費者組當前處理消息的情況,而Lag狀態則反映了消費者組落后于生產者的消息數量。 多維度重置消費位點:Kafka支持對消費者組進行多維度的重置消費位點操作。用戶可以根據需要選擇重置到最早的偏移量、最新的偏移量或指定的偏移量。這種靈活性使得用戶能夠根據需要靈活地調整消費者組的消費進度。 |



Kafka的技術原理是什么?
- 分布式架構:
- Kafka將數據分散到多個節點上進行存儲和處理,以實現高可用、高吞吐量和負載均衡等目標。
- Kafka中的每個Topic被分成多個Partition,每個Partition可以在多個節點上進行副本備份,這樣可以保證數據的可靠性和高可用性。
- 消息存儲:
- Kafka將消息存儲在硬盤上,而不是內存中,這種方式可以在消息量較大時降低內存的使用量,并且可以在節點崩潰后恢復數據。
- 消息在Partition中以有序的方式排列,每個消息都有一個唯一的偏移量(Offset)。
- 發布/訂閱模式:
- Kafka采用發布/訂閱模型,消息發布者(Producer)將消息發送到Kafka的消息中心(Broker)中,然后由訂閱者(Consumer)從中心中讀取消息。
- 一個消息可以被多個訂閱者同時讀取,Kafka支持多個消費者組,每個消費者組內的消費者共享一個Topic的消息,但不會重復消費消息。
- 高性能設計:
- Kafka通過批量發送、零拷貝、壓縮和消息緩存等技術顯著提高性能。
- Kafka的預讀取(Pread)技術可以提高消息的讀寫效率,從而提升Kafka的吞吐量。
- 消息可靠性:
- Kafka通過多副本備份和ISR(In-Sync Replicas)機制保證消息的可靠性。每個Partition可以有多個副本,ISR是指所有副本中與Leader副本保持同步的副本。當Leader副本出現故障時,ISR中的某個副本會成為新的Leader,繼續處理消息。
- 擴展性和靈活性:
- Kafka的設計具有良好的擴展性和靈活性,可以根據實際需求靈活地擴展集群規模和增加節點。
- Kafka提供了多種API接口和客戶端工具,以便開發人員更方便地使用Kafka進行消息處理。
Kafka的核心優勢是什么?
 |
 |
 |
|
標準API接口 |
服務商賬號統一管理 |
零代碼集成服務商 |
 |
 |
 |
|
智能路由
|
服務擴展 服務擴展不僅提供特性配置和歸屬地查詢等增值服務,還能根據用戶需求靈活定制解決方案,滿足多樣化的業務場景,進一步提升用戶體驗和滿意度。
|
可視化監控 |
在哪些場景會用到Kafka?
1. 實時ETL(Extract, Transform, Load)
- 在實時數據處理和分析領域,Kafka與流式計算引擎(如火山引擎流式計算Flink版)相結合,可以實現業務數據的實時ETL過程。ETL是數據倉庫和數據湖建設中不可或缺的一環,用于從各種數據源中提取數據,經過轉換和清洗后加載到目標存儲系統中。Kafka作為數據源和數據處理中間件的橋梁,能夠接收來自各種業務系統的實時數據流。通過Kafka的API接口,這些數據流被高效地傳遞給Flink等流式計算引擎。Flink利用其強大的并行處理能力和狀態管理能力,對數據流進行實時轉換和聚合,生成有價值的信息和洞察。最終,處理后的數據可以被存儲在數據倉庫、數據湖或實時分析系統中,供業務團隊進行進一步的查詢和分析。

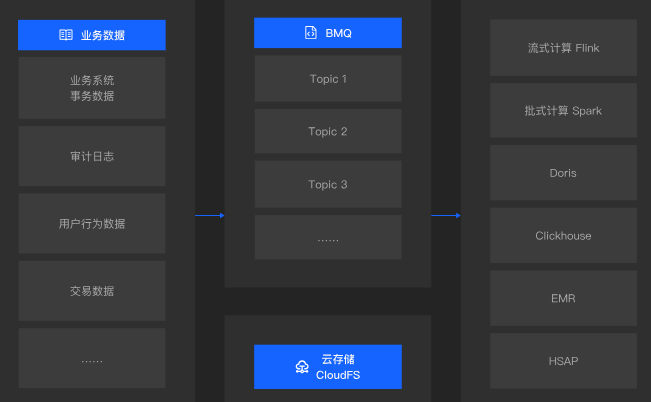
2. 數據中轉
- 在復雜的數據處理架構中,Kafka常被用作數據中轉樞紐,實現不同系統之間的數據流轉和協作。通過使用云原生消息引擎BMQ(假設它完全兼容Kafka API),企業可以輕松地將同一份數據從源系統轉存到不同的專用存儲系統中。例如,一個電商平臺可能會將訂單數據實時發送到Kafka中,然后通過Kafka的API接口將數據轉發到關系型數據庫(用于事務處理)、NoSQL數據庫(用于快速查詢)以及數據倉庫(用于長期存儲和分析)。這種數據中轉的方式不僅提高了數據處理的靈活性,還確保了數據的一致性和可靠性。
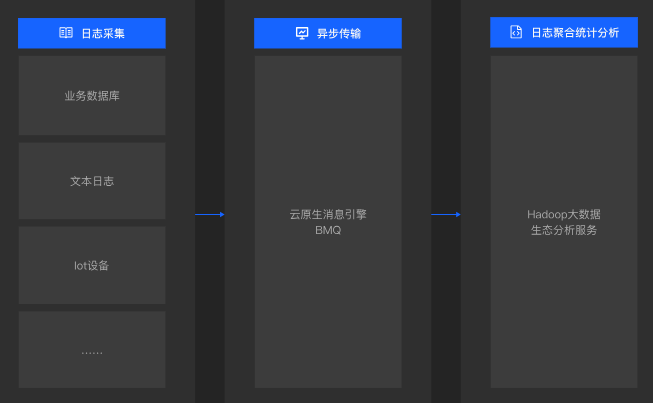
3. 日志分析
- Kafka在日志收集和分析領域也扮演著重要角色。它可以作為日志聚合的解決方案,將各種日志數據集中聚合到一個地方,便于后續的分析和處理。企業通常會在其分布式系統中部署大量的應用程序和服務,這些應用程序和服務會產生大量的日志數據。通過Kafka的API接口,這些日志數據可以被實時地收集到Kafka集群中。然后,企業可以利用ELK(Elasticsearch、Logstash、Kibana)等日志分析工具對Kafka中的日志數據進行索引、搜索、可視化和告警。這樣,開發人員和運維人員就可以快速地定位問題、監控系統性能和優化應用程序。
4. 實時事件驅動架構(EDA)
- 在構建現代微服務架構時,實時事件驅動架構(EDA)成為了一個關鍵設計模式。Kafka通過其API接口在此場景中發揮了核心作用。在EDA中,Kafka作為事件總線,連接了系統中各個微服務。微服務之間不直接通信,而是通過發布到Kafka主題中的事件進行間接通信。這種松耦合的設計提高了系統的可擴展性、可靠性和可維護性。例如,一個在線購物系統中,當用戶下單時,訂單服務會發布一個訂單創建事件到Kafka中。庫存服務、支付服務等多個微服務訂閱了該主題,并基于接收到的事件進行相應的業務處理。通過這種方式,Kafka API接口促進了微服務間的實時數據交換和協同工作。
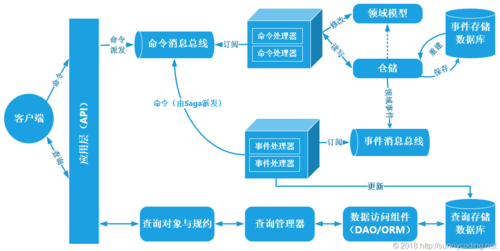
-
高吞吐量數據處理:Kafka設計之初就是為了處理高吞吐量的數據流。它能夠以極高的速度接收和發送數據,支持每秒處理數百萬條消息,這使得它非常適合用于處理大規模實時數據流。
-
低延遲消息傳遞:Kafka提供了低延遲的消息傳遞機制,使得數據能夠幾乎實時地在生產者和消費者之間流動。這對于需要快速響應的應用場景至關重要,如實時分析、實時推薦系統等。
-
高可擴展性:Kafka的分布式架構使得它能夠輕松地進行水平擴展,以應對不斷增長的數據量和處理需求。通過增加更多的Kafka服務器(broker),可以線性地提升系統的吞吐量和處理能力。
-
高容錯性:Kafka通過數據復制和分區機制提供了高容錯性。每個分區的數據都會被復制到多個broker上,以確保數據的可靠性和可用性。即使某個broker發生故障,系統也能自動切換到其他副本繼續工作,而不會丟失數據或中斷服務。
-
解耦生產者和消費者:Kafka作為一個消息隊列,實現了生產者和消費者之間的解耦。生產者只需將消息發送到Kafka集群,而無需關心消費者何時消費這些消息。同樣,消費者也可以按照自己的節奏從Kafka中拉取數據,而無需與生產者保持同步。這種解耦機制提高了系統的靈活性和可擴展性。
-
支持多種數據消費模式:Kafka支持多種數據消費模式,包括實時處理、離線處理和批處理。這使得Kafka能夠適用于多種不同的應用場景,如實時分析、日志收集、數據備份等。
