文件存儲HDFS
通用API
【更新時間: 2024.03.29】
HDFS(Hadoop Distributed File System)是一種分布式文件系統,專為大規模數據存儲與處理而設計。
|
瀏覽次數
48
采購人數
0
試用次數
0
 適用于個人&企業
適用于個人&企業
收藏
×
完成
取消
×
書簽名稱
確定
|


- 詳情介紹
- 常見 FAQ
- 相關推薦


什么是文件存儲HDFS?
"文件存儲HDFS",即Hadoop分布式文件系統,是專為應對大數據挑戰而設計的存儲解決方案。它構成了Hadoop生態系統的核心,通過分布式架構和一系列優化技術,實現了對海量數據的高效、可靠、低成本存儲。HDFS不僅能夠支持PB級的數據量,還通過數據冗余機制確保了數據的高可用性和容錯性,即使在硬件故障的情況下也能保證數據的完整性和可訪問性。
該文件系統特別適合于處理大規模數據集上的批量操作,如MapReduce作業,它通過減少磁盤尋道時間、優化數據本地化等技術手段,提供了極高的數據吞吐率。這種特性使得HDFS成為大數據處理、數據湖分析以及機器學習等應用場景中不可或缺的一部分。
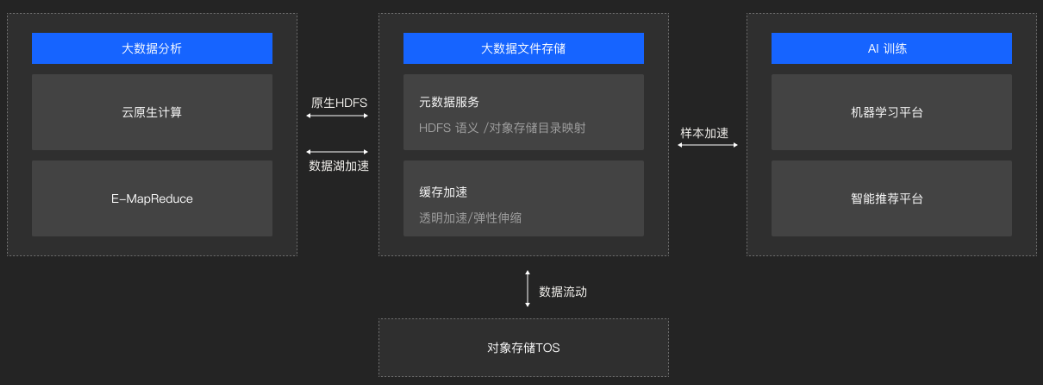
在大數據處理方面,HDFS作為底層存儲系統,支持MapReduce、Spark等大數據處理框架對海量數據進行分布式處理,加速了數據處理的速度和效率。對于數據湖分析,HDFS提供了靈活的存儲解決方案,允許企業以低成本存儲各種類型的數據,并通過高級分析工具進行深入的洞察和決策支持。而在機器學習領域,HDFS則成為存儲訓練數據集、模型參數等關鍵數據的理想選擇,支持分布式機器學習框架進行高效的模型訓練和推理。

什么是文件存儲HDFS接口?
文件存儲HDFS有哪些核心功能?
|
數據加速 |
多場景支持 |
|
數據管理 |
私有化部署 |




文件存儲HDFS的技術原理是什么?
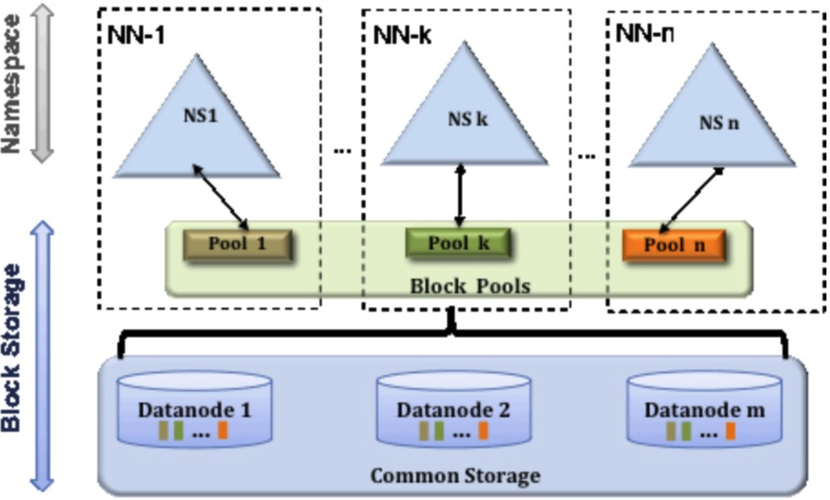
- 分布式存儲:
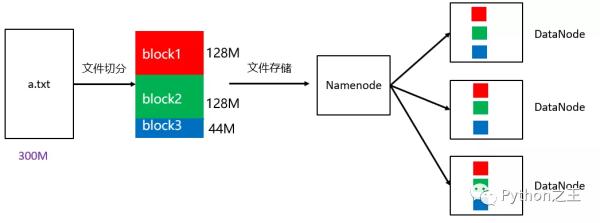
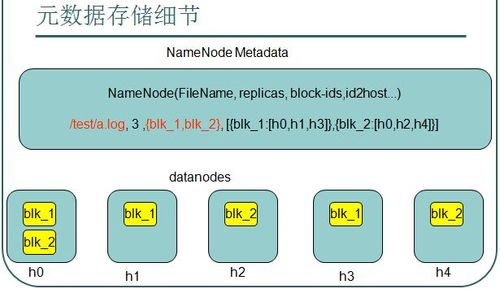
- HDFS將大文件分割成多個固定大小的塊(通常為64MB或128MB),這些塊是HDFS文件系統中的最小存儲單元。
- 每個塊都有多個副本(通常是3個),它們被存儲在不同的數據節點上,以防止單點故障和數據丟失。
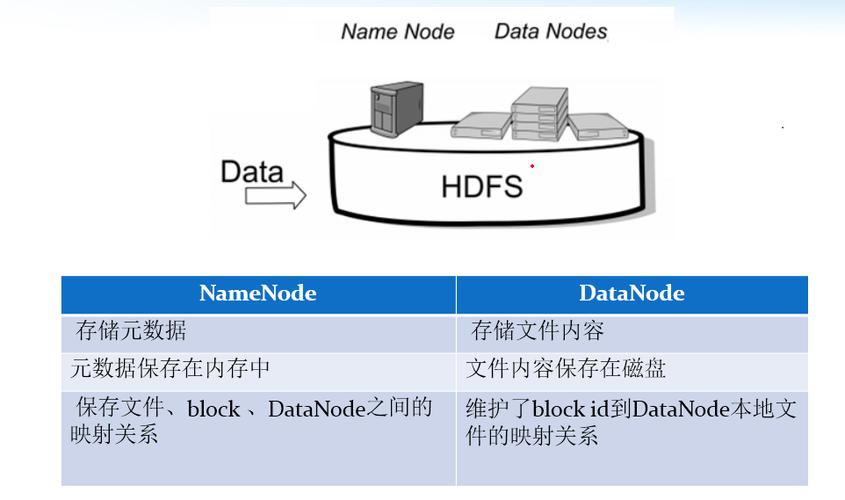
- 文件的元數據(包括文件名、文件大小、塊列表等信息)存儲在名稱節點(NameNode)上,它維護了文件系統的目錄樹和文件到數據塊的映射關系。
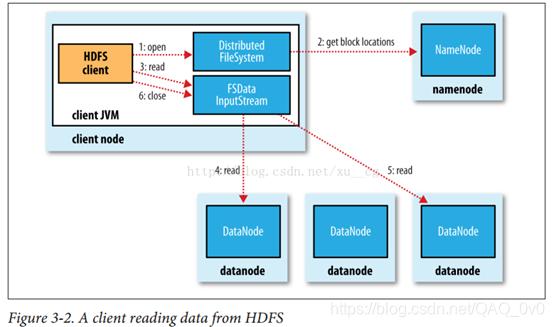
- 數據訪問與處理:
- 當客戶端需要讀取或寫入文件時,它會向NameNode發送請求,NameNode會返回包含文件塊位置信息的列表。
- 客戶端根據返回的位置信息,直接從相應的DataNode中讀取或寫入數據塊。
- HDFS支持高吞吐量的數據訪問,通過優化數據本地性和減少磁盤尋道時間來提高性能。
- 容錯與可靠性:
- HDFS通過數據冗余和容錯機制來保證數據的安全性和可靠性。當某個DataNode失效時,系統會自動將該DataNode上的塊副本復制到其他DataNode上,以實現數據的自動故障恢復。
- HDFS還提供了數據校驗和等機制來檢測數據損壞,并在必要時進行修復。
文件存儲HDFS的核心優勢是什么?
 |
 |
 |
|
標準API接口 |
服務商賬號統一管理 |
零代碼集成服務商 |
 |
 |
 |
|
智能路由
|
服務擴展 服務擴展不僅提供特性配置和歸屬地查詢等增值服務,還能根據用戶需求靈活定制解決方案,滿足多樣化的業務場景,進一步提升用戶體驗和滿意度。
|
可視化監控 |
在哪些場景會用到文件存儲HDFS?
1. 大數據存儲
HDFS作為Hadoop生態系統的核心組件之一,主要用于存儲大規模數據集。它能夠支持PB級別的數據存儲需求,滿足大型企業和互聯網公司對于海量數據存儲的迫切需求。在這些場景中,HDFS的API接口被用于數據的上傳、下載、查詢和管理等操作,確保數據的安全性和可靠性。
2. 數據分析與挖掘
HDFS提供高可靠性和高性能的數據存儲解決方案,非常適合用于數據分析、數據挖掘等大數據處理任務。許多企業通過HDFS存儲數據,并使用Hadoop等框架進行數據分析。在這些場景中,HDFS的API接口被用于讀取存儲在HDFS上的數據,并將其提供給數據分析工具或算法進行處理。通過API接口,用戶可以輕松地訪問和管理存儲在HDFS上的數據,從而支持復雜的數據分析任務。
3. 日志處理
許多應用程序會生成大量的日志數據,這些日志數據對于系統的監控、故障排查和性能優化至關重要。HDFS可以作為日志存儲的解決方案,支持大規模、高并發的日志處理需求。通過HDFS的API接口,用戶可以實時地將日志數據上傳到HDFS中,并利用Hadoop等框架對日志數據進行分析和處理。這種方式不僅提高了日志處理的效率,還降低了存儲成本。
4. 數據備份與恢復
HDFS提供數據冗余和容錯機制,能夠保證數據的安全性和可靠性。因此,許多企業會選擇使用HDFS作為數據備份和恢復的解決方案。在這些場景中,HDFS的API接口被用于數據的備份和恢復操作。通過API接口,用戶可以輕松地將數據從本地或遠程存儲系統備份到HDFS中,并在需要時從HDFS中恢復數據。這種方式不僅簡化了數據備份和恢復的流程,還提高了數據的可靠性和可用性
5. 圖像處理與視頻分析
HDFS可以存儲大量的圖像和視頻數據,適合用于圖像處理、圖像識別和視頻分析等任務。在這些場景中,HDFS的API接口被用于讀取存儲在HDFS上的圖像和視頻數據,并將其提供給圖像處理或視頻分析算法進行處理。通過API接口,用戶可以高效地訪問和管理存儲在HDFS上的圖像和視頻數據,從而支持復雜的圖像處理和視頻分析任務。
6. 實時數據處理
HDFS可以與其他組件(如Apache Kafka、Apache Storm等)結合使用,支持實時數據處理需求。在這些場景中,HDFS的API接口被用于實時數據的存儲和查詢。通過API接口,用戶可以將實時數據流式傳輸到HDFS中,并利用Hadoop等框架對實時數據進行處理和分析。這種方式不僅提高了實時數據處理的效率,還降低了處理成本。
7. 機器學習與深度學習
在機器學習和深度學習領域,HDFS同樣發揮著重要作用。許多機器學習和深度學習算法需要使用大量的訓練數據來訓練模型。通過HDFS的API接口,用戶可以輕松地將訓練數據上傳到HDFS中,并利用分布式計算框架(如TensorFlow、PyTorch等)進行模型訓練。這種方式不僅提高了模型訓練的效率,還降低了訓練成本。
一、硬件層面
- 使用高效穩定的硬件:
- 確保集群中的服務器、存儲設備、網絡設備等硬件組件具備高可靠性和穩定性。
- 考慮使用SSD(固態硬盤)替代傳統的HDD(機械硬盤),以提高讀寫速度和降低延遲,從而提升整體性能。
- 冗余硬件配置:
- 部署冗余的電源、風扇、網絡交換機等關鍵硬件組件,以防止單點故障導致整個系統不可用。
二、軟件與配置層面
- 優化HDFS配置:
- 根據實際負載和數據特性調整HDFS的配置參數,如塊大小、副本數量、心跳間隔等。
- 適當增加數據塊的副本數量可以提高數據的可靠性和容錯能力,但也要考慮存儲成本和性能影響。
- 使用數據壓縮:
- 在存儲和傳輸數據時采用壓縮算法(如LZO、Snappy等),以減少數據大小,提高存儲效率和傳輸速度。
- 啟用數據校驗:
- HDFS支持CRC32等校驗和機制,用于驗證數據塊的完整性。確保在文件創建時生成校驗和,并在讀取時驗證校驗和,以發現潛在的數據損壞。
三、數據備份與恢復
- 數據備份策略:
- 制定合理的數據備份策略,確保關鍵數據有多個副本存儲在不同的節點或位置。
- 利用HDFS的冗余副本機制,確保數據在節點故障時能夠自動恢復。
- 數據恢復能力:
- 引入糾刪碼(Erasure Coding)技術,如Reed-Solomon和Cauchy等算法,以在數據塊丟失時從其他數據塊中恢復數據。
- 定期驗證數據備份的完整性和可用性,確保在需要時能夠迅速恢復數據。
四、系統監控與管理
- 實時監控與告警:
- 部署監控系統,實時監控HDFS集群的狀態、性能、負載等指標。
- 設置告警閾值,當集群狀態異常或性能指標超出閾值時及時發出告警通知。
- 定期維護與升級:
- 定期對HDFS集群進行維護,包括清理垃圾數據、優化存儲布局、更新軟件版本等。
- 關注Hadoop社區和官方發布的更新和補丁,及時將集群升級到最新版本以修復已知的安全漏洞和性能問題。
五、高可用性與容錯性
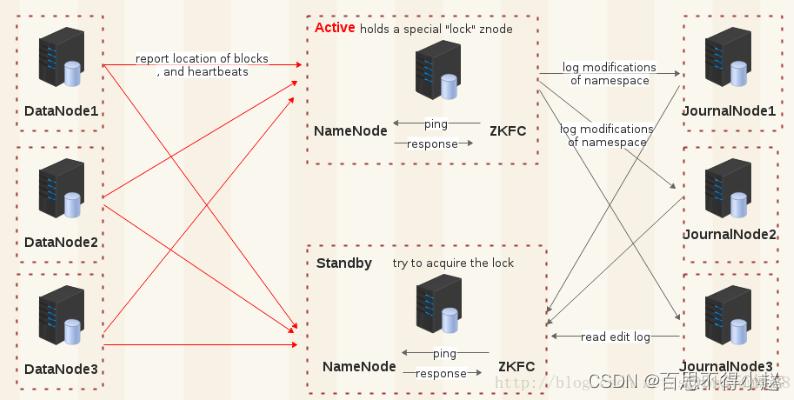
- NameNode高可用:
- 部署NameNode高可用(HA)架構,使用兩個或多個NameNode實例,一主一備或多主多備模式,確保在主NameNode故障時能夠迅速切換到備用NameNode。
- 機架感知與數據布局:
- 利用HDFS的機架感知能力,優化數據塊的存儲布局,以提高數據訪問的帶寬利用率和容錯能力。
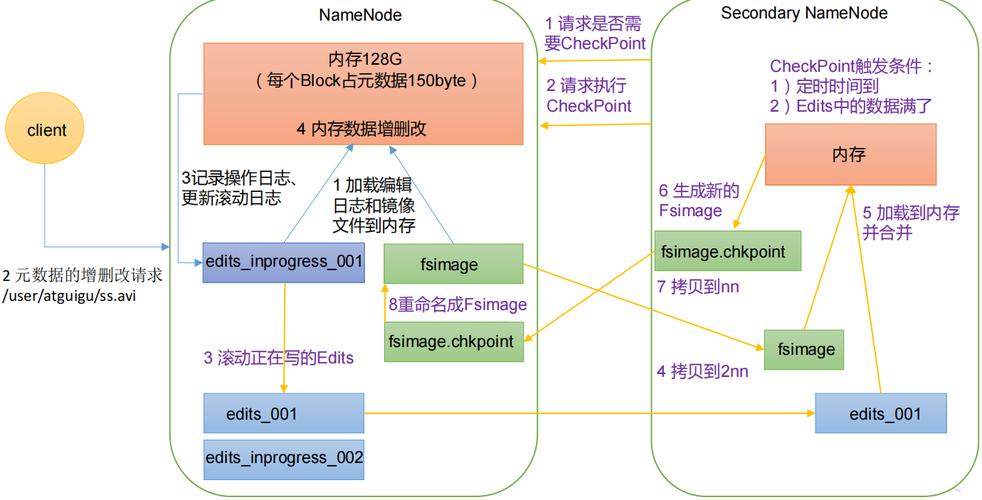
- 快照與回收站:
- 使用HDFS的快照功能,定期為重要數據創建快照,以便在需要時恢復數據到特定時間點的狀態。
- 啟用回收站功能,為刪除的文件提供臨時存儲空間,以便在誤刪除時能夠迅速恢復數據。
