Elasticsearch
通用API
【更新時間: 2024.03.29】
Elasticsearch 是一個開源、分布式、實時搜索與數(shù)據(jù)分析引擎,以其高可擴展性和近實時搜索能力著稱。
|
瀏覽次數(shù)
90
采購人數(shù)
0
試用次數(shù)
0
 適用于個人&企業(yè)
適用于個人&企業(yè)
收藏
×
完成
取消
×
書簽名稱
確定
|
 最佳渠道
最佳渠道


- 詳情介紹
- 常見 FAQ
- 相關(guān)推薦


什么是Elasticsearch?
Elasticsearch 是一個功能強大的開源搜索引擎,它不僅限于簡單的搜索功能,更是一個全方位的分布式搜索和分析引擎。它基于Apache Lucene這一成熟的、高性能的、可擴展的信息檢索(IR)庫構(gòu)建而成,但Elasticsearch通過其獨特的分布式架構(gòu)和高級抽象,極大地簡化了Lucene的復(fù)雜性,使得開發(fā)者能夠更容易地實現(xiàn)高效、實時的全文搜索、日志分析以及復(fù)雜的數(shù)據(jù)分析需求。Elasticsearch 的核心優(yōu)勢在于其近實時(NRT)的搜索能力,這意味著一旦數(shù)據(jù)被索引,它幾乎可以立即被搜索到,極大地提升了用戶體驗和數(shù)據(jù)處理效率。此外,Elasticsearch 支持高度可伸縮的架構(gòu)設(shè)計,能夠隨著數(shù)據(jù)量的增長自動進行水平擴展,保持服務(wù)的高可用性和性能穩(wěn)定性。這種能力使得Elasticsearch能夠輕松應(yīng)對從TB級到PB級數(shù)據(jù)的存儲、檢索和分析需求。在數(shù)據(jù)交互方面,Elasticsearch 采用了廣泛支持的JSON格式,這不僅簡化了數(shù)據(jù)的序列化和反序列化過程,也使得Elasticsearch能夠輕松地與各種現(xiàn)代應(yīng)用程序和框架集成。同時,Elasticsearch 支持復(fù)雜的查詢語句,包括但不限于全文搜索、范圍查詢、地理空間查詢等,為開發(fā)者提供了豐富的數(shù)據(jù)檢索和分析手段。

Elasticsearch有哪些核心功能?
限流插件QoS限流插件是Elasticsearch中一個非常重要的功能擴展,它允許管理員在集群級別或索引級別上精細控制讀寫操作的速率。這一功能對于維護集群的穩(wěn)定性至關(guān)重要,特別是在高并發(fā)訪問或資源受限的環(huán)境下。通過配置合理的讀寫限流策略,可以防止因過度請求而導(dǎo)致的資源耗盡,從而保護集群免受雪崩效應(yīng)的影響。此外,限流插件還能幫助優(yōu)化資源分配,確保關(guān)鍵業(yè)務(wù)的高可用性。 |
多元檢索多元檢索是Elasticsearch的一大亮點,它支持多種檢索方式的靈活組合,以滿足不同場景下的復(fù)雜需求。通過內(nèi)置的KNN(K-Nearest Neighbors)算法,Elasticsearch提供了強大的向量搜索和向量數(shù)據(jù)庫能力,這使得它不僅能夠處理傳統(tǒng)的全文搜索任務(wù),還能輕松應(yīng)對如LLM(大型語言模型)問答、以圖搜圖、以文搜圖等基于向量相似度的檢索場景。 |
索引壓縮索引壓縮是Elasticsearch優(yōu)化存儲效率的關(guān)鍵技術(shù)之一。通過采用高效的壓縮算法(如ZSTD),Elasticsearch能夠在不影響寫入性能的前提下,顯著減少索引數(shù)據(jù)的存儲空間占用。這一功能對于降低成本、提高存儲效率具有重要意義。特別是對于那些需要處理海量數(shù)據(jù)的場景,索引壓縮能夠幫助用戶在不增加硬件投入的情況下,實現(xiàn)數(shù)據(jù)的更長時間保存和更快速的查詢響應(yīng)。 |
數(shù)據(jù)導(dǎo)入數(shù)據(jù)導(dǎo)入是Elasticsearch處理大規(guī)模數(shù)據(jù)集時不可或缺的一環(huán)。為了應(yīng)對千萬級、億級甚至更高量級的數(shù)據(jù)導(dǎo)入需求,Elasticsearch提供了多種高效的數(shù)據(jù)導(dǎo)入方案,其中混合云Hyperloader是一個典型的例子。該方案利用Hadoop HDFS等分布式存儲系統(tǒng)作為數(shù)據(jù)中轉(zhuǎn)站,首先將數(shù)據(jù)在Hadoop集群中生成索引并存儲于HDFS中,然后再將索引數(shù)據(jù)批量導(dǎo)入到Elasticsearch集群中。 |




Elasticsearch的技術(shù)原理是什么?
- 分布式存儲和架構(gòu):
- Elasticsearch采用了分布式存儲模式,能夠?qū)?shù)據(jù)分散存儲在多個節(jié)點上,每個節(jié)點可以保存多個分片。這種分布式架構(gòu)不僅提高了系統(tǒng)的擴展性,還增強了系統(tǒng)的容錯性。
- 節(jié)點通過集群名稱來識別并加入特定的集群,默認情況下,每個節(jié)點都會被安排加入名為“elasticsearch”的集群。
- 倒排索引:
- Elasticsearch使用倒排索引的數(shù)據(jù)結(jié)構(gòu)來加快搜索速度。倒排索引是一個將文檔中每個單詞與包含該單詞的文檔進行關(guān)聯(lián)的索引結(jié)構(gòu),使得搜索特定單詞時能夠快速找到相關(guān)文檔。
- 分詞和詞匯處理:
- 在建立索引之前,Elasticsearch會對文本進行分詞處理,將文本拆分成有意義的詞項,并進行詞干化和標(biāo)準(zhǔn)化等處理,以提高搜索的準(zhǔn)確性和效率。
- 分布式搜索和查詢:
- 當(dāng)用戶執(zhí)行搜索請求時,Elasticsearch會將查詢分發(fā)到所有的節(jié)點上進行并行處理。每個節(jié)點都會返回自己的搜索結(jié)果,并根據(jù)相關(guān)性進行排名。然后,集群會將各個節(jié)點的結(jié)果合并,并按照相關(guān)性進行最終排名,返回給用戶最終的搜索結(jié)果。
- 實時性:
- Elasticsearch支持實時索引和查詢,當(dāng)文檔被索引后,它可以立即被搜索到,這使得Elasticsearch適用于需要實時更新和搜索的應(yīng)用場景,如日志分析、實時監(jiān)控等。
- 水平擴展和高可用性:
- 由于Elasticsearch的分布式存儲和架構(gòu),可以輕松地進行水平擴展,通過增加節(jié)點和分片來提高系統(tǒng)的處理能力和存儲容量。同時,Elasticsearch還具有自動分片和故障轉(zhuǎn)移功能,保證了系統(tǒng)的高可用性。
Elasticsearch的核心優(yōu)勢是什么?
 |
 |
 |
|
標(biāo)準(zhǔn)API接口 |
服務(wù)商賬號統(tǒng)一管理 |
零代碼集成服務(wù)商 |
 |
 |
 |
|
智能路由
|
服務(wù)擴展 服務(wù)擴展不僅提供特性配置和歸屬地查詢等增值服務(wù),還能根據(jù)用戶需求靈活定制解決方案,滿足多樣化的業(yè)務(wù)場景,進一步提升用戶體驗和滿意度。
|
可視化監(jiān)控 |
在哪些場景會用到Elasticsearch?
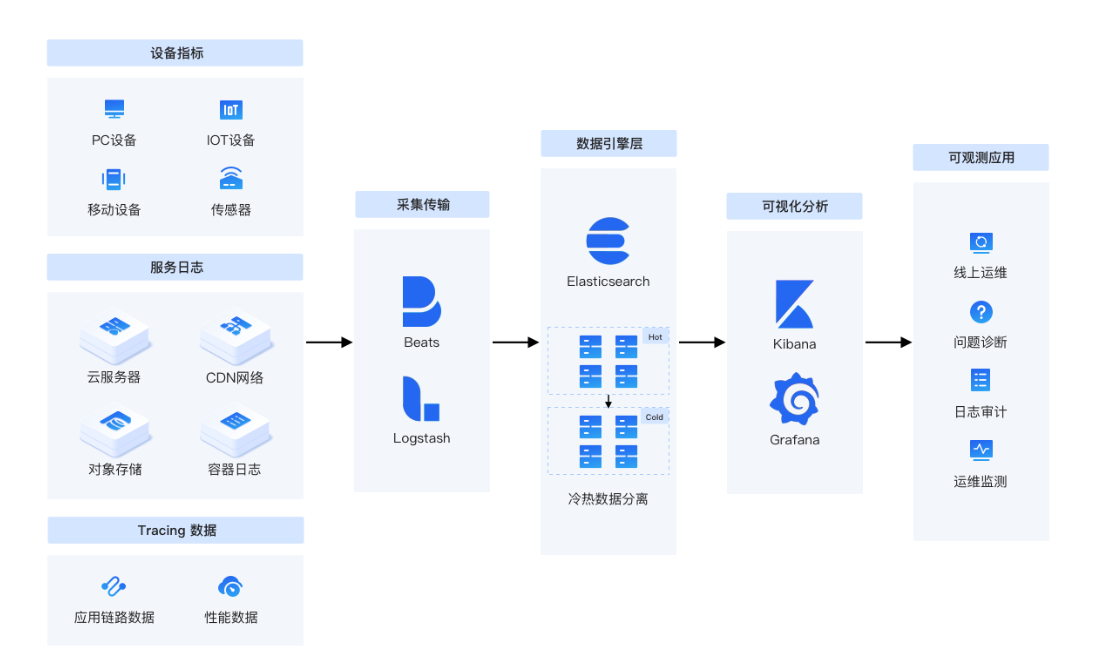
1. 觀測分析
在現(xiàn)代企業(yè)環(huán)境中,隨著微服務(wù)架構(gòu)、容器化、云原生等技術(shù)的廣泛應(yīng)用,業(yè)務(wù)系統(tǒng)的復(fù)雜性和數(shù)據(jù)量急劇增加。這些系統(tǒng)運行中產(chǎn)生的海量日志和監(jiān)控數(shù)據(jù)成為了企業(yè)運維和經(jīng)營的寶貴資源。為了高效管理和利用這些數(shù)據(jù),Elasticsearch API接口在多個關(guān)鍵場景中發(fā)揮著不可替代的作用:
-
日志收集與分析:在企業(yè)基礎(chǔ)設(shè)施運維中,Elasticsearch API接口被用于收集來自不同系統(tǒng)、應(yīng)用和服務(wù)的日志數(shù)據(jù),并進行統(tǒng)一存儲和實時分析。通過API接口,可以輕松地將日志數(shù)據(jù)導(dǎo)入Elasticsearch,并利用其強大的查詢和聚合功能進行快速搜索、分析和問題診斷。
-
系統(tǒng)監(jiān)控與告警:在系統(tǒng)監(jiān)控場景下,Elasticsearch API接口支持實時監(jiān)控指標(biāo)數(shù)據(jù)的收集和分析,幫助運維團隊及時發(fā)現(xiàn)系統(tǒng)異常和潛在問題。結(jié)合Kibana的可視化能力,可以直觀地展示監(jiān)控數(shù)據(jù),并通過設(shè)置報警策略實現(xiàn)自動化告警,提高運維效率和響應(yīng)速度。
-
數(shù)據(jù)歸檔與審計:對于需要長期保存的數(shù)據(jù),如日志、交易記錄等,Elasticsearch API接口提供了基于BOS的冷熱分離存儲方案,有效降低了存儲成本。同時,通過API接口可以輕松實現(xiàn)數(shù)據(jù)的歸檔和審計,滿足合規(guī)性和安全性要求。
-
業(yè)務(wù)洞察與決策支持:在運營監(jiān)測、業(yè)務(wù)洞察等場景下,Elasticsearch API接口支持對業(yè)務(wù)數(shù)據(jù)進行深度分析和挖掘,幫助企業(yè)管理層做出更加明智的決策。通過API接口可以獲取到實時、準(zhǔn)確的數(shù)據(jù)報表和趨勢分析,為業(yè)務(wù)決策提供有力支持。
2. 大模型知識庫
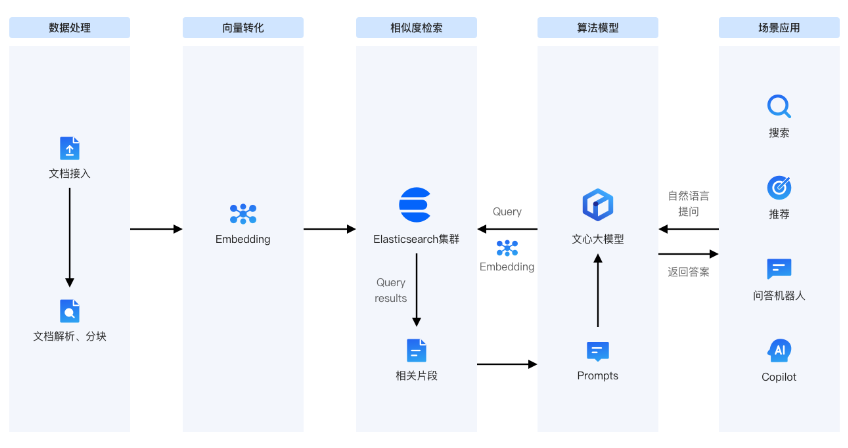
在大模型應(yīng)用落地過程中,Elasticsearch API接口同樣發(fā)揮著重要作用。通過向量檢索技術(shù),Elasticsearch能夠高效存儲和檢索大量知識數(shù)據(jù),為模型提供實時、準(zhǔn)確的知識補充:
-
知識庫構(gòu)建:利用Elasticsearch API接口,可以輕松地構(gòu)建和維護一個包含豐富知識數(shù)據(jù)的知識庫。這些數(shù)據(jù)可以是文檔、文章、問答對等,通過向量化處理后存儲在Elasticsearch中。
-
知識檢索與推薦:在智能問答、企業(yè)知識庫等場景中,Elasticsearch API接口支持高效的向量檢索和相似度計算。通過輸入查詢向量或文本,可以快速找到與之最相似的知識條目,并推薦給用戶或模型進行進一步處理。
-
模型優(yōu)化:通過不斷將新知識數(shù)據(jù)寫入Elasticsearch并進行檢索訓(xùn)練,可以不斷優(yōu)化模型的推理和回答結(jié)果。這種方式可以降低模型更新訓(xùn)練的成本和時間,提高模型的準(zhǔn)確性和效率。
3. 檢索推薦
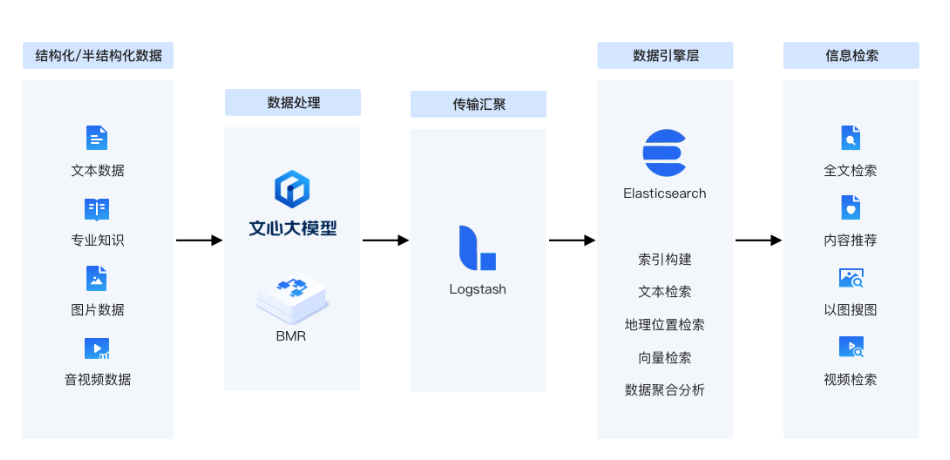
在信息檢索和推薦系統(tǒng)中,Elasticsearch API接口以其高性能、高并發(fā)和靈活性而受到廣泛應(yīng)用:
-
快速響應(yīng):通過Elasticsearch API接口,可以實現(xiàn)從PB級數(shù)據(jù)中毫秒級返回搜索結(jié)果的能力。這對于提高用戶體驗和滿足高并發(fā)訪問需求至關(guān)重要。
-
復(fù)雜查詢:Elasticsearch API接口支持靈活的查詢語法和組合條件,可以輕松實現(xiàn)模糊匹配、多字段搜索、范圍查詢等復(fù)雜查詢需求。這對于提升搜索結(jié)果的準(zhǔn)確性和相關(guān)性具有重要意義。
-
向量標(biāo)量混合檢索:在視頻推薦、以圖搜圖等非結(jié)構(gòu)化數(shù)據(jù)檢索場景中,Elasticsearch API接口支持向量標(biāo)量混合檢索技術(shù)。通過將非結(jié)構(gòu)化數(shù)據(jù)轉(zhuǎn)化為向量形式進行存儲和檢索,可以大大提高檢索效率和準(zhǔn)確性。
4. 數(shù)據(jù)分析
在數(shù)據(jù)分析領(lǐng)域,Elasticsearch API接口作為ELK方案(Logstash+Elasticsearch+Kibana)的核心組件之一,為數(shù)據(jù)統(tǒng)一管理、實時分析和結(jié)果呈現(xiàn)提供了有力支持:
-
聚合分析:通過Elasticsearch API接口,可以輕松實現(xiàn)數(shù)據(jù)的聚合分析功能。這包括但不限于統(tǒng)計、分組、排序等操作,有助于深入挖掘數(shù)據(jù)背后的規(guī)律和趨勢。
-
可視化分析:結(jié)合Kibana的可視化能力,Elasticsearch API接口支持將分析結(jié)果以圖表、儀表盤等形式直觀展示給用戶。這有助于用戶更好地理解數(shù)據(jù)、發(fā)現(xiàn)問題并做出決策。
-
商業(yè)智能:通過Elasticsearch API接口與其他BI工具(如Sugar BI、Prometheus等)的集成,可以進一步擴展數(shù)據(jù)分析的廣度和深度。這有助于企業(yè)構(gòu)建更加完善的商業(yè)智能體系,提高經(jīng)營效率和競爭力。
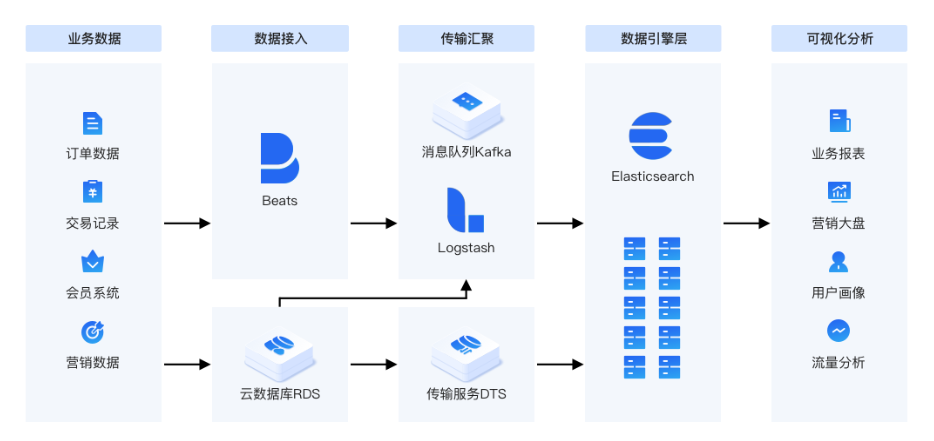
1. 高效搜索問題
- 海量數(shù)據(jù)搜索:Elasticsearch為處理大規(guī)模數(shù)據(jù)集提供了高效的搜索能力。無論是結(jié)構(gòu)化還是非結(jié)構(gòu)化數(shù)據(jù),Elasticsearch都能通過其分布式索引和查詢機制實現(xiàn)快速檢索。
- 實時搜索:與傳統(tǒng)數(shù)據(jù)庫相比,Elasticsearch的實時查詢處理能力更強,能夠應(yīng)對大規(guī)模并發(fā)搜索請求,提供近乎實時的搜索體驗。
2. 數(shù)據(jù)索引與存儲
- 全文索引:Elasticsearch基于Lucene構(gòu)建,支持全文索引,能夠?qū)?shù)據(jù)中的文本內(nèi)容轉(zhuǎn)化為索引,從而實現(xiàn)快速的全文搜索。
- 多類型數(shù)據(jù)支持:Elasticsearch支持豐富的數(shù)據(jù)類型,包括text、keyword、integer、long、float、double、boolean、date等,能夠靈活地處理各種類型的數(shù)據(jù)。
3. 數(shù)據(jù)分析與探索
- 復(fù)雜查詢:Elasticsearch支持多種復(fù)雜的查詢類型,如布爾查詢、短語查詢、過濾器、排序、分頁等,滿足多樣化的數(shù)據(jù)分析需求。
- 趨勢與模式發(fā)現(xiàn):除了簡單的數(shù)據(jù)檢索和聚合外,Elasticsearch還能幫助用戶發(fā)現(xiàn)數(shù)據(jù)中的趨勢和模式,為決策提供支持。
4. 分布式與可擴展性
- 分布式特性:Elasticsearch的分布式特性使其能夠輕松應(yīng)對數(shù)據(jù)量的增長,通過增加節(jié)點來擴展集群的容量和性能。
- 靈活的伸縮性:Elasticsearch提供了靈活的伸縮性配置,可以根據(jù)實際需求調(diào)整索引的分片數(shù)量、副本數(shù)量等參數(shù),以優(yōu)化系統(tǒng)的性能和穩(wěn)定性。
5. 集成與生態(tài)
- 生態(tài)支持:Elasticsearch是Elastic Stack(之前稱為ELK Stack)的核心組件之一,與Logstash、Kibana等產(chǎn)品緊密集成,形成了一套完整的日志收集、處理和可視化解決方案。
- 廣泛的集成:Elasticsearch還支持與其他多種技術(shù)和工具集成,如Hadoop、Spark、Kafka等,為用戶提供更多的選擇和靈活性。
