數據:包含回答問題的相關信息的數據集合(如文件、網頁)。
檢索: 能從數據中檢索相關源知識的檢索策略。
生成: 利用相關源知識,在 LLM 的幫助下生成回復。
RAG 管道流量
在與模型直接交互時,LLM (大語言模型)會收到一個問題,并根據其參數知識生成一個響應。 RAG 在此過程中增加了一個額外步驟,利用檢索功能查找相關數據,為 LLM (大語言模型)建立額外的上下文。
在下面的例子中,我們使用密集向量檢索策略從數據中檢索相關的源知識。 然后將這些源知識作為上下文傳遞給 LLM(大語言模型),以生成響應。
RAG 不一定要使用密集矢量檢索,它可以使用任何能從數據中檢索出相關源知識的檢索策略。 它可以是簡單的關鍵詞搜索,甚至是谷歌網頁搜索。
我們將在今后的文章中介紹其他檢索策略。
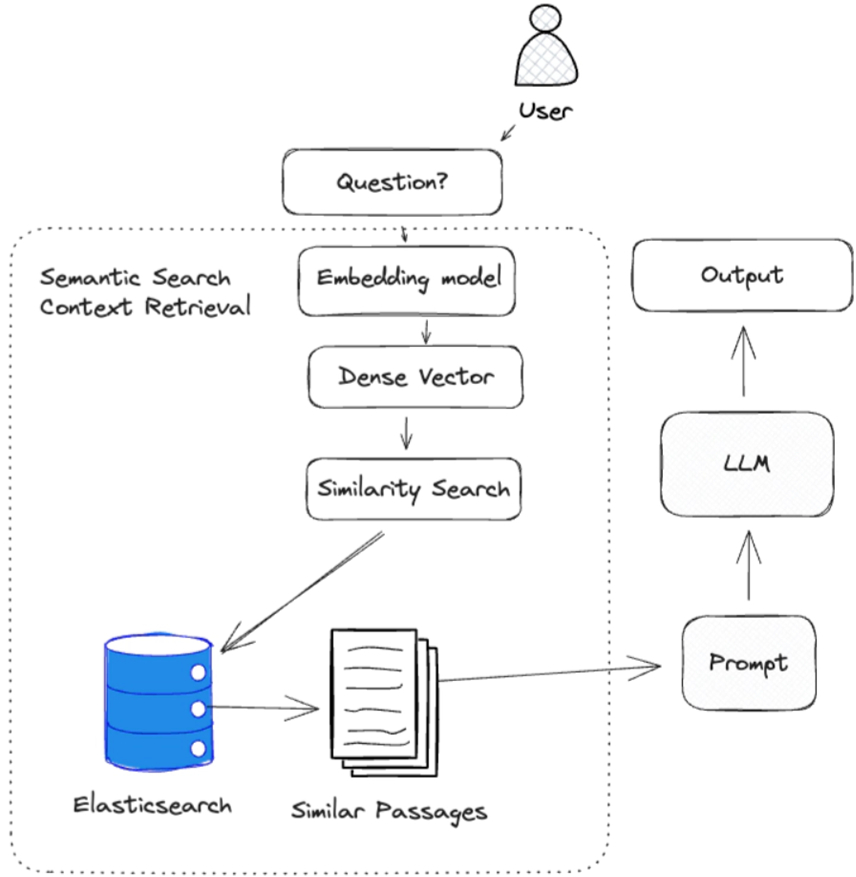
檢索源知識
檢索相關源知識是有效回答問題的關鍵。
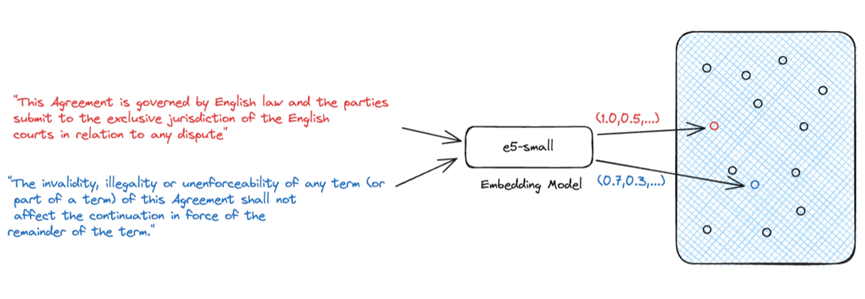
生成式人工智能最常用的檢索方法是使用密集向量進行語義搜索。 語義搜索是一種需要嵌入模型將自然語言輸入轉化為表示源知識的密集向量的技術。 我們依靠這些密集向量來表示源知識,因為它們能夠捕捉文本的語義。 這一點非常重要,因為它允許我們將源知識的語義與問題進行比較,以確定源知識是否與問題相關。
給定一個問題及其嵌入,我們就能找到最相關的源知識。
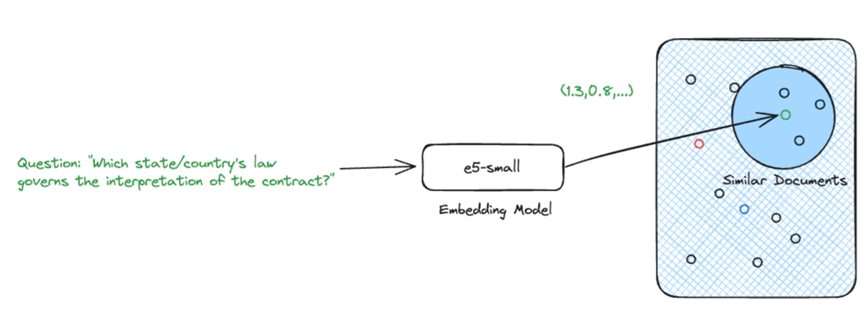
使用密集向量進行語義搜索并不是唯一的檢索選擇,但卻是當今最流行的方法之一。 我們將在今后的文章中介紹其他方法。
RAG 的優勢
訓練后,LLM (大語言模型)被凍結。 模型的參數知識是固定的,無法更新。 但是,當我們在 RAG 管道中添加數據和檢索時,我們可以根據底層數據源的變化更新源知識,而無需重新訓練模型。
以源知識為基礎
模型的響應也可以受限于只使用上下文中提供的源知識,這有助于限制幻覺。 這種方法還允許使用較小的、針對特定任務的 LLM(大語言模型),而不是大型的、通用的模型。 這樣就能優先使用源知識來回答問題,而不是在訓練過程中獲得的一般知識。
在答復中引用資料來源
此外,RAG 還能提供用于回答問題的源知識的清晰可追溯性。 這對于合規性和監管原因非常重要,也有助于發現 LLM(大語言模型) 的幻覺。 這就是所謂的源跟蹤。
行動中的 RAG
檢索到相關源知識后,我們就可以利用它來生成對問題的回答。 為此,我們需要
建立背景:包含回答問題相關信息的源知識集合(如文檔、網頁)。 這為模型生成回復提供了背景。
提示模板:針對特定任務(回答問題、總結文本)用自然語言編寫的模板。 用作 LLM (大語言模型)的輸入。
問題:與任務相關的問題。 一旦有了這三個組件,我們就可以使用 LLM(大語言模型)生成對問題的回復。
RAG 面臨的挑戰
有效檢索是有效回答問題的關鍵。 良好的檢索可為上下文提供一系列不同的相關源知識。 然而,這與其說是一門科學,不如說是一門藝術,需要大量的實驗才能獲得成功,而且在很大程度上取決于使用情況。
精確的密集矢量
由于大型文檔包含多種語義,因此難以用單個密集向量來表示。 為了實現有效的檢索,我們需要將文檔分解成較小的文本塊,這些文本塊可以準確地表示為單個密集向量。
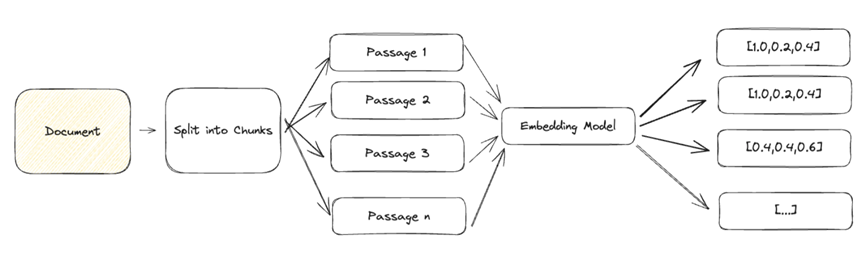
一般文本的常見方法是按段落分塊,并將每個段落表示為一個密集的向量。 根據您的使用情況,您可能希望使用標題、小標題甚至句子將文檔細分為若干小塊。
大背景
在使用 LLM(大語言模型) 時,我們需要注意傳遞給模型的上下文的大小。
LLM (大語言模型)一次可處理的令牌數量有限制。 例如,GPT-3.5-turbo 有 4096個令牌的限制。
其次,隨著情境的增加,產生的反應質量可能會下降,從而增加產生幻覺的風險。
較大的背景也需要更多的時間來處理,更重要的是,它們會增加 LLM 的成本。
這又回到了檢索的藝術上。 我們需要在分塊大小和嵌入準確性之間找到恰當的平衡點。
結論:
Retrieval Augmented Generation(檢索增強生成)是一種強大的技術,可以通過提供相關的源知識作為上下文,幫助提高 LLM (大語言模型)生成的回復質量。 但 RAG 并不是靈丹妙藥。它需要大量的實驗和調整才能達到最佳效果,而且在很大程度上取決于您的使用情況。
本文翻譯源自:https://www.elastic.co/search-labs/blog/retrieval-augmented-generation-rag
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
3000+提示詞助力AI大模型
和專業工程師共享工作效率翻倍的秘密
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
av不卡免费在线观看|
国产亚洲欧洲997久久综合|
91免费视频网|
亚洲日本电影在线|
91视频在线看|
亚洲成人综合网站|
欧美成人一区二区三区|
成人av在线资源|
亚洲自拍偷拍欧美|
精品久久一二三区|
jizz一区二区|
久久精品国产亚洲一区二区三区|
久久久精品影视|
91亚洲精品一区二区乱码|
曰韩精品一区二区|
久久久一区二区|
欧美色网一区二区|
经典三级视频一区|
亚洲黄色性网站|
久久亚洲欧美国产精品乐播
|
亚洲一级在线观看|
国产三区在线成人av|
欧美疯狂做受xxxx富婆|
成人深夜在线观看|
全国精品久久少妇|
中文字幕视频一区|
久久影视一区二区|
欧美亚洲一区二区在线|
国产成人在线视频网址|
国产精品成人网|
91麻豆精品国产自产在线观看一区|
精品中文字幕一区二区|
亚洲18影院在线观看|
亚洲精品中文在线影院|
中文字幕精品在线不卡|
久久综合久久综合亚洲|
精品久久久久99|
7777精品伊人久久久大香线蕉的|
99久久国产综合色|国产精品|
国产伦精一区二区三区|
久久99国产精品免费|
欧美aaaaaa午夜精品|
日韩专区中文字幕一区二区|
亚洲二区在线视频|
亚洲丰满少妇videoshd|
午夜激情一区二区|
偷拍日韩校园综合在线|
亚洲va欧美va人人爽午夜|
亚洲综合自拍偷拍|
亚洲愉拍自拍另类高清精品|
一区二区三区在线看|
亚洲曰韩产成在线|
午夜av一区二区|
日本亚洲一区二区|
国产在线播放一区二区三区|
成人免费毛片片v|
日本韩国欧美三级|
欧美肥大bbwbbw高潮|
欧美不卡视频一区|
国产精品久久久久一区二区三区|
国产精品三级久久久久三级|
国产精品久久久久久久久免费桃花
|
午夜在线电影亚洲一区|
亚洲mv在线观看|
裸体一区二区三区|
国产白丝精品91爽爽久久|
一本色道久久综合亚洲91|
欧美剧情片在线观看|
精品国产一区二区三区不卡|
久久久久国产成人精品亚洲午夜|
国产精品久久免费看|
亚洲尤物视频在线|
国产风韵犹存在线视精品|
日本黄色一区二区|
欧美一级搡bbbb搡bbbb|
国产精品麻豆一区二区|
亚洲h在线观看|
成人app在线观看|
欧美日本乱大交xxxxx|
国产喷白浆一区二区三区|
亚洲va欧美va天堂v国产综合|
国产精品一区二区黑丝|
欧美精品乱码久久久久久按摩
|
欧美精品在线一区二区|
国产精品伦一区二区三级视频|
天堂一区二区在线免费观看|
暴力调教一区二区三区|
久久婷婷一区二区三区|
性做久久久久久免费观看欧美|
成人性视频免费网站|
日韩一区二区三区免费观看|
亚洲精品国产a久久久久久|
成人国产精品免费观看动漫
|
精品国产免费一区二区三区四区|
一区二区三区免费观看|
波波电影院一区二区三区|
久久女同精品一区二区|
免费成人美女在线观看|
欧美日韩免费观看一区三区|
亚洲视频电影在线|
91美女片黄在线|
中文字幕日韩精品一区|
成人小视频在线|
国产精品色呦呦|
av电影在线观看不卡|
国产精品高潮呻吟久久|
懂色av中文一区二区三区|
26uuu色噜噜精品一区|
精品一区二区三区的国产在线播放|
5858s免费视频成人|
日韩精品乱码免费|
日韩网站在线看片你懂的|
久久精品99国产精品|
久久女同精品一区二区|
成人午夜视频福利|
樱花草国产18久久久久|
欧美视频在线观看一区二区|
午夜电影网亚洲视频|
日韩精品一区二区在线|
国产一区视频在线看|
国产精品女同一区二区三区|
色天天综合久久久久综合片|
亚洲第一会所有码转帖|
欧美videos大乳护士334|
国产激情精品久久久第一区二区|
国产精品嫩草影院com|
在线观看网站黄不卡|
麻豆国产一区二区|
一色屋精品亚洲香蕉网站|
欧美日韩日日夜夜|
国产成人鲁色资源国产91色综|
中文字幕制服丝袜成人av|
欧美乱妇一区二区三区不卡视频
|
国产夫妻精品视频|
亚洲chinese男男1069|
国产女主播视频一区二区|
色欧美乱欧美15图片|
老司机精品视频线观看86|
一区精品在线播放|
欧美一区二区在线视频|
av成人老司机|
国产在线精品不卡|
日本欧美加勒比视频|
亚洲精品成人天堂一二三|
久久嫩草精品久久久精品一|
欧美日韩成人在线一区|
国产一区二区三区av电影|
日韩激情一二三区|
亚洲一区二区在线播放相泽|
中文字幕在线观看不卡|
国产视频一区二区三区在线观看
|
91丨porny丨户外露出|
国产麻豆成人精品|
六月丁香婷婷色狠狠久久|
午夜不卡av免费|
亚洲国产精品视频|
亚洲特级片在线|
日本一区二区高清|
国产亚洲精久久久久久|
精品久久久久久久人人人人传媒|
欧美视频你懂的|
欧美午夜精品久久久久久超碰
|
国产在线不卡视频|
麻豆精品国产传媒mv男同|
麻豆91精品91久久久的内涵|
免费观看一级欧美片|
日本视频一区二区三区|
日韩国产欧美在线观看|
亚洲r级在线视频|
三级久久三级久久|
久久99热狠狠色一区二区|
国产在线精品一区二区不卡了|
日韩精品一区第一页|
久久精品国产亚洲a|
国产成人自拍网|
色av综合在线|
欧美一区二区视频观看视频|
精品99一区二区三区|
国产精品乱码妇女bbbb|
一级特黄大欧美久久久|
日韩高清欧美激情|
国产成人精品一区二|
欧洲一区在线电影|
日韩一区二区三区电影在线观看|
日韩一区二区视频|
国产精品视频yy9299一区|
亚洲综合网站在线观看|
久久99精品一区二区三区三区|
极品少妇xxxx精品少妇偷拍|
成人免费视频一区|
欧美乱熟臀69xxxxxx|
久久久99精品久久|
亚洲一区视频在线观看视频|
免费观看成人鲁鲁鲁鲁鲁视频|
国产一区二区视频在线播放|
91国在线观看|
日本一区二区不卡视频|
日本人妖一区二区|
色综合天天狠狠|
久久久国产精品麻豆|