
如何調用 Minimax 的 API
VideoLDM 的應用不僅限于娛樂和創意領域,還包括自主駕駛和監控等需要高分辨率視頻數據處理的行業。其生成高分辨率視頻的能力,使其在模擬真實世界場景中尤為出色。
VideoLDM 是在圖像生成領域的基礎上發展而來的,其架構設計包括幾個關鍵步驟。首先,通過預訓練的潛在空間擴散模型(LDM)生成圖像,然后通過引入時間層將其擴展為視頻生成模型。第二步是將圖像生成器轉換為視頻生成器,這需要在潛在空間中進行時間對齊,并通過微調實現長時間視頻的生成。
視頻生成的過程分為如下幾個步驟:
在 LDM 中,時間層的引入是實現圖像生成器向視頻生成器轉變的關鍵。這一過程涉及在原有的空間層中加入時間層,以 3D 卷積和時間注意力層的形式實現。在此過程中,空間層的參數保持不變,而時間層的參數則通過視頻數據進行微調。
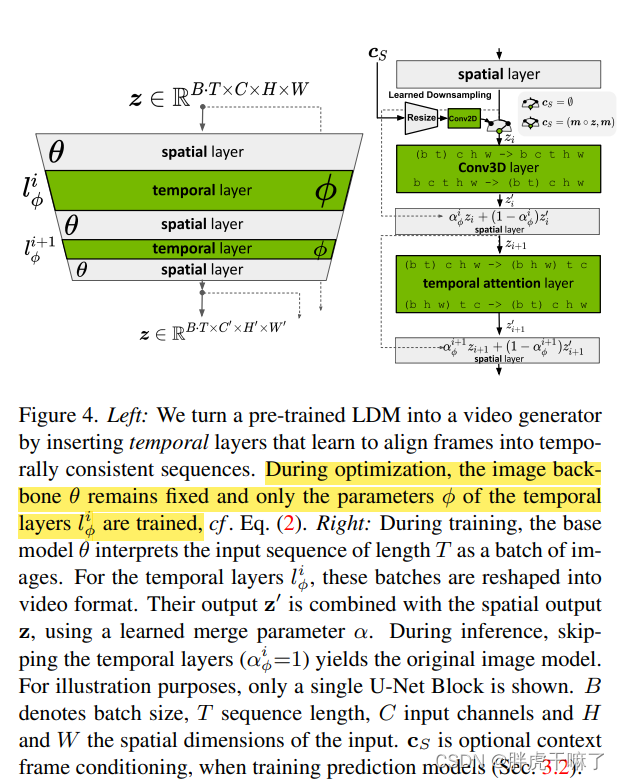
時間層的設計是為了對齊獨立的圖像幀,使得它們能夠形成連續的視頻序列。通過這種設計,VideoLDM 可以生成更多具有時間連貫性的幀序列,從而提高視頻生成的質量。
直接將圖像自編碼器應用于視頻生成會引發圖像閃爍等問題。為了克服這一難題,VideoLDM 對自編碼器進行了時序微調。通過對解碼器進行微調,而保持編碼器不變,模型能夠更好地適應視頻數據的時序特性。
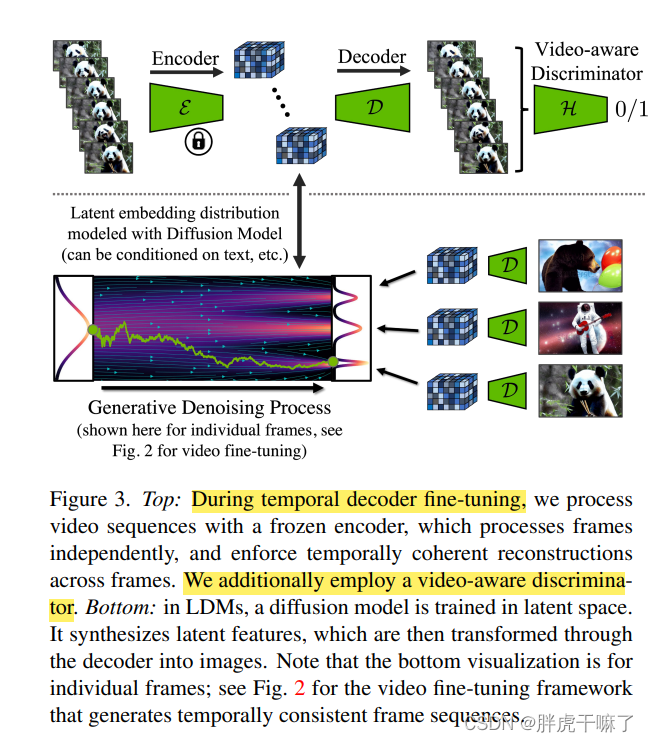
這種微調利用了 3D 卷積構建的時序判別器來確保幀與幀之間的連續性。微調通過調整解碼器的參數,使其能夠處理時序一致的潛向量,從而生成視覺上連貫的視頻內容。
雖然 b 章節的方法適用于短視頻生成,但對于長視頻,VideoLDM 采用預測模型來擴展其生成長度。通過輸入多個上下文幀進行訓練,VideoLDM 能夠預測未來的幀序列。此過程通過二進制掩碼實現,掩蓋住需要預測的幀,保留上下文幀。
推理階段,利用生成的關鍵幀作為上下文幀,迭代地生成長視頻。通過無分類器擴散引導,采樣過程更加穩定。
為了增強視頻的幀率和流暢性,VideoLDM 在關鍵幀之間采用時序插值策略。利用條件掩碼機制,在關鍵幀之間生成插值幀。實驗表明,單次插值可使視頻長度增加數倍,經過多次迭代,可顯著提升視頻的幀率。
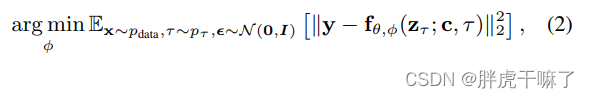
這種插值方法使得生成的視頻在視覺上更加連貫,從而提升用戶的觀看體驗。
為進一步提升視頻清晰度,VideoLDM 在視頻上采樣過程中對超分辨率模型進行時序微調。通過將時間層拓展至上采樣器,模型能夠在提升分辨率的同時保持幀間一致性。
這種時序微調策略有效地結合了空間和時間信息,使得每一幀都能在高分辨率下保持一致的視覺效果。
通過本文的探討,VideoLDM 顯示了其在高分辨率視頻生成中的強大能力。未來,隨著技術的發展,VideoLDM 將在更多領域內展現其應用潛力,為視頻生成帶來更多創新。





