RNN是一種處理序列數據的神經網絡,具有內在的反饋回路,能夠記住每個時間步的信息狀態。RNN在對文本等序列數據建模方面顯示出潛力。
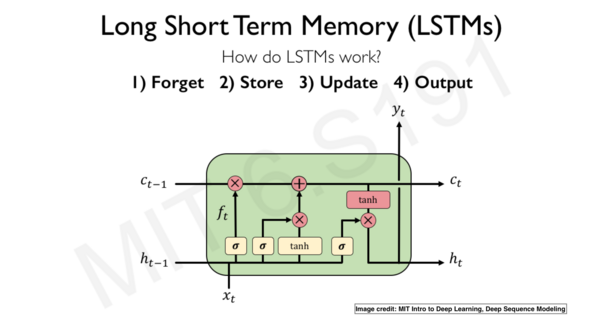
LSTM是一種可以處理長序列數據的RNN變體,通過門機制控制信息流的方式來解決梯度不穩定的問題。LSTM在文本分類、情感分析和語音識別等任務中表現優異。
盡管LSTM功能強大,但其計算成本較高。GRU(門控循環單元)通過減少參數的方式,提供了一個計算更高效的選擇。
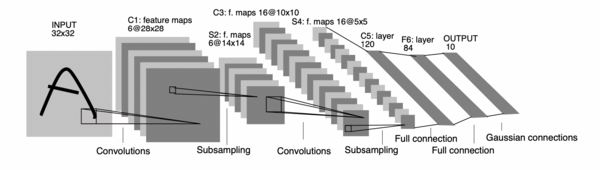
LeNet-5是1998年由Yann LeCun提出的卷積神經網絡架構,首創用于文檔識別,包含卷積層、池化層和全連接層。
隨著AlexNet在2012年ImageNet挑戰賽中取得的成功,卷積神經網絡開始在計算機視覺領域被廣泛應用,推動了圖像分類的發展。
現代卷積網絡,如VGG、GoogLeNet和ResNet,通過增加網絡深度和復雜性,顯著提高了視覺識別任務的準確性。
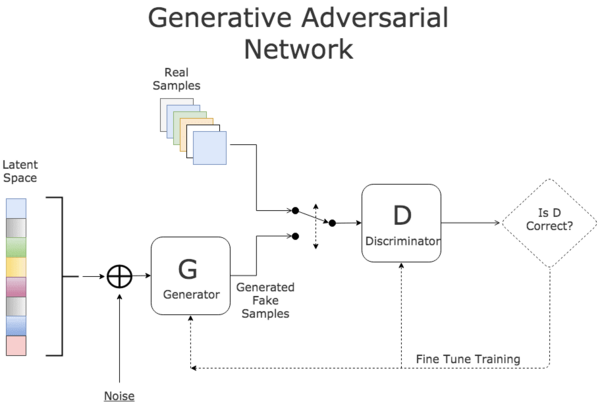
GAN由Ian Goodfellow在2014年引入,由生成器和判別器組成,用于生成逼真樣本。GAN在圖像生成和Deepfake等領域有著顯著貢獻。
除了GAN,生成模型還包括變分自編碼器(VAE)和自編碼器等,它們在圖像合成和數據生成方面展現了強大的能力。
GAN被廣泛應用于生成圖像、音樂等多種數據類型,其生成的高質量樣本在藝術創作和數據增強中極具價值。
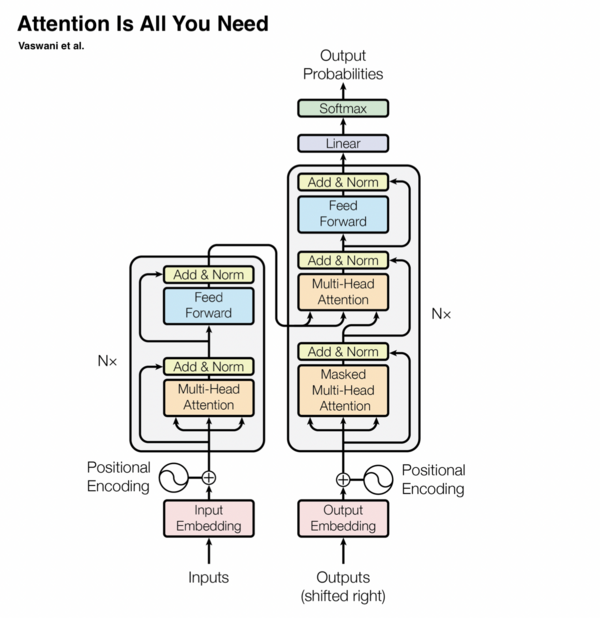
Transformer是一種基于注意力機制的深度學習模型,不依賴于循環網絡或卷積。它主要由多頭注意力、殘差連接和層歸一化等組件構成。
注意力機制允許模型在不依賴序列順序的情況下處理數據,極大提升了計算效率,并在NLP領域引入了革命性的變化。
Transformer在機器翻譯、文本摘要和語音識別等任務中表現出色,成為NLP領域的核心技術。
GPT(Generative Pre-trained Transformer)系列是大規模語言模型的典范,展現了在自然語言生成和理解中的強大能力。
基于Transformer的代碼生成模型如OpenAI的Codex,可以生成和編輯程序代碼,極大提升了軟件開發的效率。
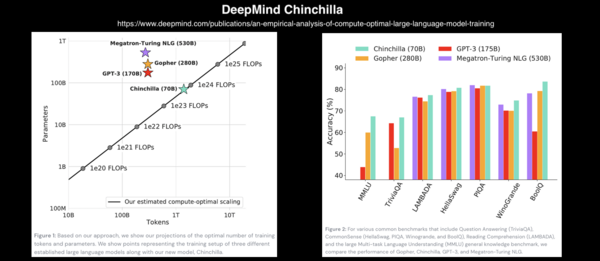
隨著模型參數的不斷增長,如GPT-3的1750億參數,對計算資源的需求也在不斷增加,推動了硬件和軟件的共同發展。
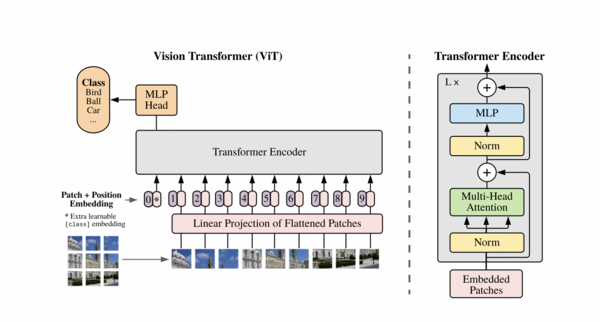
Vision Transformer(ViT)將Transformer架構應用于計算機視覺,通過圖像塊的處理實現了優異的圖像分類性能。
多模態模型結合視覺和語言的能力,例如DALL·E 2,在文本到圖像生成和圖像字幕等任務中展現出色。
Swin Transformer通過使用移位窗口機制,增強了Transformer在目標檢測和圖像分割等下游任務中的表現。