在全連接層中,輸入數據通過權重矩陣進行線性變換,然后通過激活函數進行非線性變換,從而實現對輸入數據的復雜映射。這使得全連接層能夠對輸入數據進行特征提取和模式識別。
全連接層的數學描述
權重矩陣與線性變換
全連接層的核心在于其權重矩陣。假設輸入為一個向量 ( x ),權重矩陣為 ( W ),則輸出 ( y ) 可以表示為:
import numpy as np
def fully_connected_layer(x, W, b):
return np.dot(W, x) + b
其中,( b ) 為偏置向量。這個線性變換過程可以幫助模型捕捉輸入數據的線性關系。
激活函數的作用
在全連接層中,激活函數可以提供非線性能力,使得網絡能夠擬合復雜的函數關系。常見的激活函數包括 ReLU、sigmoid 和 tanh。
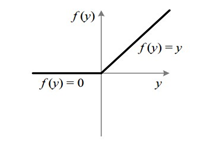
激活函數的選擇對模型的性能有很大影響,需根據具體任務進行選擇。
全連接層在不同網絡中的應用
在VGG網絡中的應用
VGG網絡是一種經典的深度卷積神經網絡,它在最后幾層使用了多個全連接層來進行分類任務。例如,在 VGG-16 中,最后一層卷積的輸出為7x7x512,而全連接層的輸出則是一個4096維的向量。

這種設計使得 VGG 網絡能夠很好地提取圖像的高層語義特征,并進行有效的分類。
在ResNet中的改進
ResNet引入了殘差連接(Residual Connection),并在某些版本中用全局平均池化(GAP)替代了全連接層,從而減少參數量并提升模型性能。
這種設計不僅提高了模型的訓練速度,而且在某些任務上也提高了準確性。
全連接層的優缺點
優點
- 強大的表達能力:由于每個神經元都與前一層的所有神經元相連,全連接層具有很強的表達能力,可以捕捉到數據的全局特征。
- 靈活性:全連接層可以與不同的激活函數結合使用,從而適應不同的任務需求。
缺點
- 參數量大:全連接層通常需要大量的參數,這會導致計算復雜度和內存占用的增加。
- 容易過擬合:由于參數量大,模型容易在訓練數據上過擬合,導致對新數據的泛化能力不足。
如何優化全連接層
減少參數量
一種有效的減少全連接層參數量的方法是使用全局平均池化(Global Average Pooling,GAP)替代全連接層。這種方法不僅減少了參數量,還能提高特征的全局性。
使用正則化技術
正則化技術(如L2正則化、Dropout等)是防止過擬合的有效手段。通過在訓練過程中引入懲罰項,可以限制模型的復雜度,從而提高模型的泛化能力。
調整網絡結構
通過調整全連接層的層數和每層的神經元數量,可以在模型復雜度和計算效率之間取得平衡。通常情況下,較少的神經元和層數可以減少參數量,但可能會降低模型的表達能力。
全連接層在圖像分類中的應用
在圖像分類任務中,全連接層通常位于網絡的末端,負責將卷積層提取的特征進行分類。以貓的分類任務為例,全連接層可以通過對輸入圖像的特征進行加權求和,最終輸出一個概率值,表示圖像中包含某個類別的可能性。
在這個過程中,全連接層的作用就如同一個“決策者”,負責將前一層提取的復雜特征進行整合,從而做出最終的判斷。
全連接層在自然語言處理中的應用
在自然語言處理(NLP)任務中,全連接層同樣發揮著重要作用。例如,在文本分類任務中,全連接層可以將前一層提取的文本特征進行整合,并輸出分類結果。
在這種任務中,全連接層的設置(如層數、神經元數量、激活函數等)需要根據具體任務需求進行調整,以達到最佳效果。
FAQ
什么是全連接層?
全連接層是神經網絡中一種基本的層結構,特點是層中的每一個神經元都與前一層的所有神經元相連接。它常用于特征整合和分類任務。
全連接層與卷積層有什么區別?
卷積層主要用于局部特征提取,而全連接層用于全局特征整合。因此,卷積層通常放在網絡的前部,而全連接層通常放在后部,用于最終的分類或回歸任務。
如何減少全連接層的過擬合?
可以通過使用正則化技術(如L2正則化、Dropout等)來減少過擬合。此外,適當減少層數和神經元數量,以及使用數據增廣等方法也有助于提高模型的泛化能力。
全連接層的參數量如何影響模型性能?
全連接層的參數量直接影響模型的復雜度和計算效率。過多的參數可能導致過擬合,而過少的參數可能導致模型表達能力不足。因此,需在參數量和模型性能之間取得平衡。
為什么有些網絡用全局平均池化替代全連接層?
全局平均池化(GAP)可以減少模型的參數量,從而減少過擬合的風險。此外,GAP能夠提高特征的全局性,有助于提升模型在某些任務上的表現。
本文通過詳盡的例子和分析,幫助您理解全連接層在深度學習中的角色及其重要性。無論是在圖像處理還是自然語言處理任務中,全連接層都扮演著不可或缺的角色。
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
3000+提示詞助力AI大模型
和專業工程師共享工作效率翻倍的秘密
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
成人免费黄色大片|
久久久噜噜噜久久人人看
|
国产毛片精品视频|
91精品视频网|
激情成人综合网|
国产亚洲欧美在线|
成人一区二区在线观看|
综合欧美亚洲日本|
在线综合+亚洲+欧美中文字幕|
男女男精品视频|
久久久三级国产网站|
99精品在线免费|
午夜成人免费电影|
国产精品色婷婷久久58|
成人精品鲁一区一区二区|
亚洲综合色成人|
国产日韩成人精品|
欧美巨大另类极品videosbest
|
国产自产v一区二区三区c|
欧美国产国产综合|
欧美日韩精品一区二区三区|
日韩有码一区二区三区|
国产精品毛片大码女人|
日韩精品一区二区三区中文不卡|
99久久久久久|
成人精品免费看|
国产美女精品人人做人人爽|
日韩成人dvd|
日韩精品一二三四|
亚洲一区二区三区四区五区中文|
亚洲国产成人在线|
国产亚洲午夜高清国产拍精品|
欧美丰满美乳xxx高潮www|
欧美日韩一区视频|
播五月开心婷婷综合|
成人免费电影视频|
国产99一区视频免费|
国产成人在线免费|
成人黄色a**站在线观看|
av在线一区二区|
一本大道久久a久久精二百|
91香蕉国产在线观看软件|
欧美视频在线不卡|
欧美一区二区黄|
国产亚洲欧美日韩日本|
国产精品视频你懂的|
亚洲国产一区二区三区|
日韩不卡手机在线v区|
国产一区二区三区美女|
91偷拍与自偷拍精品|
欧美日韩国产乱码电影|
精品国产人成亚洲区|
自拍偷在线精品自拍偷无码专区|
亚洲第一av色|
国产美女av一区二区三区|
一本色道综合亚洲|
日韩写真欧美这视频|
国产精品免费视频网站|
香蕉av福利精品导航|
丁香婷婷综合激情五月色|
在线中文字幕一区二区|
久久综合九色综合欧美就去吻|
国产精品午夜免费|
美日韩黄色大片|
欧美曰成人黄网|
国产精品久99|
国内成人自拍视频|
欧美一区二视频|
亚洲大片一区二区三区|
不卡一区在线观看|
日本一区二区视频在线|
国产一区视频导航|
日韩欧美一区二区久久婷婷|
亚洲高清一区二区三区|
色琪琪一区二区三区亚洲区|
亚洲国产精品成人综合色在线婷婷
|
欧美大度的电影原声|
欧美变态tickling挠脚心|
日韩精品一卡二卡三卡四卡无卡|
在线免费精品视频|
亚洲自拍欧美精品|
在线免费一区三区|
婷婷亚洲久悠悠色悠在线播放|
欧美精品色综合|
日本成人中文字幕|
久久综合九色综合97婷婷女人|
国产一区二区三区在线观看免费
|
91久久免费观看|
亚洲国产日韩a在线播放|
欧美日韩一卡二卡|
国模无码大尺度一区二区三区|
精品99999|
欧美中文字幕一二三区视频|
秋霞午夜鲁丝一区二区老狼|
久久精子c满五个校花|
色婷婷久久久亚洲一区二区三区
|
91免费版在线|
久久av资源站|
一区二区三区四区在线|
欧美日韩激情在线|
另类欧美日韩国产在线|
亚洲精品国产精品乱码不99|
91精品国产美女浴室洗澡无遮挡|
a4yy欧美一区二区三区|
男女激情视频一区|
一区二区三区av电影|
亚洲国产精品成人综合色在线婷婷|
欧美日韩成人综合在线一区二区|
国产suv精品一区二区三区|
亚洲成人激情自拍|
亚洲精品亚洲人成人网在线播放|
国产视频一区二区在线观看|
日韩小视频在线观看专区|
男女视频一区二区|
久国产精品韩国三级视频|
亚洲va韩国va欧美va|
亚洲www啪成人一区二区麻豆|
一区二区高清视频在线观看|
亚洲欧洲综合另类在线|
亚洲免费视频成人|
亚洲午夜免费视频|
日韩中文字幕一区二区三区|
日本sm残虐另类|
国产一区二区美女诱惑|
韩国三级中文字幕hd久久精品|
激情五月播播久久久精品|
国产激情精品久久久第一区二区|
91麻豆精品一区二区三区|
久久精品在这里|
中文在线一区二区|
日韩理论片网站|
亚洲成av人片一区二区三区|
午夜久久久影院|
国产美女一区二区三区|
av一二三不卡影片|
色婷婷av一区二区三区大白胸|
91精品国产乱码|
成人欧美一区二区三区视频网页
|
日本欧美肥老太交大片|
精品一区二区三区香蕉蜜桃|
av一区二区三区黑人|
日韩午夜激情av|
一区二区三区中文字幕电影|
精品一二线国产|
欧美日韩高清不卡|
亚洲欧洲日韩一区二区三区|
国产一区美女在线|
欧美日韩第一区日日骚|
亚洲免费观看高清在线观看|
成人少妇影院yyyy|
国产日韩影视精品|
国产福利精品导航|
国产色综合一区|
成人永久免费视频|
国产精品美女久久久久久久久久久
|
国产91在线观看|
久久精品人人做人人爽人人|
紧缚捆绑精品一区二区|
日韩欧美你懂的|
麻豆免费精品视频|
ww久久中文字幕|
国产成人av影院|
国产精品麻豆一区二区|
99久久精品国产导航|
最好看的中文字幕久久|
欧美一a一片一级一片|
秋霞午夜av一区二区三区|
欧美成人女星排行榜|
成人亚洲精品久久久久软件|
一本到不卡精品视频在线观看|
亚洲最新在线观看|
精品电影一区二区三区
|
理论电影国产精品|
中文字幕不卡的av|
欧美电影在哪看比较好|
高清免费成人av|
亚洲成av人在线观看|
国产喷白浆一区二区三区|
欧美视频中文字幕|
国产成人综合在线观看|
日韩毛片在线免费观看|
制服丝袜亚洲色图|
色噜噜狠狠色综合欧洲selulu|
国内久久精品视频|
婷婷综合另类小说色区|
亚洲裸体在线观看|
成人欧美一区二区三区白人|
久久久久高清精品|
久久久噜噜噜久噜久久综合|
日韩一区二区三区在线观看|
欧美日韩视频在线观看一区二区三区
|
www.久久精品|
成人做爰69片免费看网站|
国产乱一区二区|
国产麻豆精品视频|
国产激情一区二区三区四区
|
99国产精品一区|
在线观看亚洲精品视频|
欧美私人免费视频|
日韩美女视频在线|