LangChain的核心模塊
Prompt Templates
Prompt Templates模塊允許用戶定義和管理自定義的提示,這對于不同的應用場景是非常關鍵的。通過使用Prompt Templates,開發者可以輕松調整模型的輸入以滿足特定的需求。例如,在構建一個問答系統時,Prompt Templates可以用于細化問題描述,從而獲得更準確的回答。
LLMs
LangChain的LLMs模塊支持多種大語言模型,包括OpenAI的GPT系列和其他開源模型。這一模塊的核心優勢在于其靈活性,開發者可以根據需求選擇最適合的模型,甚至可以封裝和集成自定義模型。這種靈活性使得LangChain在各類應用場景中都能發揮作用。
Utils
Utils模塊封裝了一些常見的功能和工具,例如搜索引擎、Python編譯器、Bash編譯器等。這些工具的集成使得LangChain能夠更高效地處理各種任務,如數據檢索、代碼執行等,極大地提升了應用的智能化水平。
Chains和Agents
Chains和Agents是LangChain的亮點模塊。Chains用于定義一系列任務的執行邏輯,使得復雜任務的處理更加系統化。而Agents則通過調用不同的工具和邏輯鏈,實現智能化的任務執行。
環境配置與安裝
要使用LangChain,首先需要配置開發環境。確保你的機器上安裝了Python 3.8至3.11的版本,并建議使用Python 3.11以獲得最佳性能。接下來,創建一個虛擬環境以隔離項目的依賴。
python -m venv langchain-env
source langchain-env/bin/activate # Linux/Mac
langchain-envScriptsactivate # Windows
在激活的虛擬環境中,安裝LangChain的依賴項:
pip install langchain
請注意,如果使用的是LangChain Chatchat 0.2.x版本,需要確保LangChain的版本為0.0.x系列。

模型下載與管理
為了在本地或離線環境下運行LangChain應用,需要下載所需的模型。通常可以從HuggingFace等開源平臺獲取模型。例如,默認使用的LLM模型為THUDM/ChatGLM3-6B,Embedding模型為BAAI/bge-large-zh。
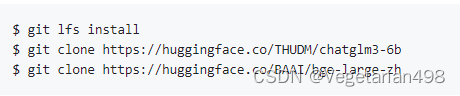
下載模型前,確保安裝了Git LFS:
git lfs install
git clone https://huggingface.co/THUDM/chatglm3-6b
構建本地知識庫
文檔加載與處理
在構建本地知識庫時,首先需要加載文本數據。LangChain提供了靈活的文檔加載器,可以處理多種格式的文件。接著,使用文本分割器將文檔分割為更小的塊,這使得后續的處理更加高效。
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import CharacterTextSplitter
documents = DirectoryLoader('path/to/documents').load()
text_splitter = CharacterTextSplitter(chunk_size=100)
split_docs = text_splitter.split_documents(documents)
生成Embedding
通過LangChain提供的Embedding工具,可以將文本轉換為向量表示,從而在后續的檢索和相似度計算中發揮作用。LangChain支持多種Embedding模型,如OpenAI和HuggingFace的模型。
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
向量數據庫管理
將生成的Embedding存儲在向量數據庫中,以便快速檢索相關文檔。LangChain支持多種向量數據庫,如Chroma和FAISS。
from langchain.vectorstores import Chroma
db = Chroma.from_documents(split_docs, embeddings, persist_directory='./chroma')
db.persist()
構建問答系統
集成ChatGLM
通過LangChain,可以將ChatGLM等大語言模型集成到問答系統中,實現智能化的問答體驗。
from langchain.chains import RetrievalQA
from langchain.llms.chatglm import ChatGLM
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=ChatGLM(), chain_type='stuff', retriever=retriever)

效果測試與優化
通過對問答系統的效果測試,可以發現其在處理本地知識庫中的內容時表現良好。然而,系統的表現與文本分割、Embedding生成、向量庫的選擇等因素密切相關,因此需要不斷調優以獲得最佳效果。
常見問題解答 (FAQ)
什么是LangChain?
LangChain是一個用于構建基于大語言模型應用的開源框架,支持多種模型的集成和定制。
如何配置LangChain的環境?
首先需要在本地安裝Python 3.8至3.11版本,然后通過虛擬環境管理項目的依賴。
使用LangChain需要下載哪些模型?
需要根據具體應用下載對應的LLM和Embedding模型,常用的有ChatGLM和各種HuggingFace模型。
如何構建本地知識庫?
通過文檔加載、文本分割、生成Embedding并存儲到向量數據庫中來構建本地知識庫。
LangChain支持哪些向量數據庫?
LangChain支持Chroma、FAISS等多種向量數據庫,用戶可以根據需求選擇。
通過以上內容,希望能幫助大家更好地理解和使用LangChain構建本地知識庫應用。在開發的過程中,及時更新和優化模型和工具,將幫助您獲得更好的應用效果。
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
3000+提示詞助力AI大模型
和專業工程師共享工作效率翻倍的秘密
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
国产一区二区看久久|
日韩高清一级片|
国产精品三级在线观看|
亚洲国产成人精品视频|
国产成人精品影视|
www.在线欧美|
欧美日韩国产乱码电影|
99精品国产91久久久久久|
九九精品一区二区|
国产一区二区调教|
日韩二区三区在线观看|
国产麻豆精品95视频|
精品日韩欧美一区二区|
中文成人av在线|
亚洲国产裸拍裸体视频在线观看乱了|
精品影视av免费|
日韩电影在线免费|
亚洲精品视频一区|
免费观看在线综合|
成人免费一区二区三区视频|
91麻豆精品国产91久久久久|
激情综合五月婷婷|
国产高清成人在线|
成人av网站免费|
av在线这里只有精品|
丁香天五香天堂综合|
成人黄色大片在线观看|
99riav久久精品riav|
欧美体内she精视频|
色噜噜狠狠色综合欧洲selulu|
中文字幕亚洲区|
99re成人在线|
亚洲精品水蜜桃|
欧美乱妇15p|
国产精品 日产精品 欧美精品|
久久夜色精品国产噜噜av
|
国产精品一区久久久久|
欧美精品一区二区高清在线观看|
91污在线观看|
在线观看精品一区|
国产一区二区三区免费在线观看|
久久毛片高清国产|
欧美一区二区二区|
不卡的av中国片|
亚洲国产精品尤物yw在线观看|
国产精品麻豆视频|
欧美体内she精高潮|
国产一区二区0|
老司机免费视频一区二区三区|
一区二区三区在线看|
国产精品久久久久天堂|
国产成人亚洲综合a∨婷婷图片|
一本在线高清不卡dvd|
99久久精品免费看国产|
色综合亚洲欧洲|
4438x亚洲最大成人网|
精品视频在线免费观看|
91精品国产乱码久久蜜臀|
久久亚洲免费视频|
亚洲午夜在线视频|
国产成人激情av|
欧美日韩视频在线第一区
|
日本韩国一区二区|
成人av在线观|
91福利精品第一导航|
色哟哟一区二区三区|
欧美一级专区免费大片|
欧美国产一区视频在线观看|
国产福利一区二区三区在线视频|
在线看不卡av|
亚洲欧美另类小说|
国产在线麻豆精品观看|
国产欧美日韩视频一区二区|
精品国产精品一区二区夜夜嗨|
蜜桃av一区二区|
亚洲欧美日韩国产手机在线|
久久成人久久爱|
狠狠久久亚洲欧美|
久久精品国产999大香线蕉|
国产成人精品一区二区三区四区|
亚洲精品国产成人久久av盗摄
|
7799精品视频|
亚洲一级二级三级|
成人免费黄色在线|
欧美日韩高清不卡|
精品一区二区三区不卡|
国产欧美一区视频|
亚洲精品v日韩精品|
成人亚洲一区二区一|
丝袜亚洲另类欧美综合|
欧美成人一级视频|
日韩激情视频网站|
伊人夜夜躁av伊人久久|
久久伊99综合婷婷久久伊|
日韩精品国产精品|
中文字幕不卡在线观看|
91在线porny国产在线看|
日韩av电影天堂|
91丨porny丨蝌蚪视频|
欧美一级免费大片|
日韩视频在线你懂得|
欧美精品国产精品|
久久精品99国产精品日本|
午夜不卡在线视频|
国产福利不卡视频|
99热99精品|
日韩精品国产欧美|
日韩电影在线观看一区|
4438x亚洲最大成人网|
日本一区二区三区视频视频|
久久精品这里都是精品|
岛国一区二区三区|
欧美在线视频日韩|
久久久久久免费网|
国产精品热久久久久夜色精品三区|
日韩三级在线观看|
亚洲永久免费av|
精品一二三四区|
亚洲国产精品一区二区www在线
|
成人黄色777网|
欧美日韩一区 二区 三区 久久精品|
一本大道久久a久久综合|
91麻豆精品国产91久久久更新时间|
日韩欧美国产系列|
日本不卡一区二区三区高清视频|
99国产精品久久久久久久久久久
|
国产精品午夜春色av|
日韩欧美精品在线|
亚洲三级视频在线观看|
亚洲激情自拍偷拍|
麻豆一区二区三|
不卡的av在线|
91免费观看视频在线|
色婷婷av一区二区三区gif|
久久综合久久综合亚洲|
日韩午夜电影av|
日韩精品一区二区三区视频在线观看|
欧美探花视频资源|
欧洲视频一区二区|
日韩av中文字幕一区二区|
亚洲国产综合91精品麻豆|
国产一区二区三区在线观看免费视频
|
日韩一区二区精品|
精品视频1区2区3区|
丁香婷婷综合激情五月色|
日本不卡一区二区三区高清视频|
亚洲色图在线播放|
日韩成人一区二区|
久久精品久久99精品久久|
日韩欧美激情在线|
精品少妇一区二区三区在线视频|
一本到不卡精品视频在线观看
|
久久―日本道色综合久久|
亚洲欧洲日韩av|
亚洲午夜久久久久中文字幕久|
美女视频一区二区|
不卡av在线免费观看|
精品成人一区二区三区|
亚洲精品大片www|
免费精品视频在线|
亚洲成人午夜影院|
欧美日韩在线综合|
午夜精品福利一区二区蜜股av
|
一区二区三区在线播放|
中文字幕日韩欧美一区二区三区|
久久先锋影音av鲁色资源网|
精品国产成人系列|
亚洲一区二区四区蜜桃|
国产在线精品一区二区三区不卡|
成人福利在线看|
一本大道久久a久久综合|
亚洲精品在线观看网站|
自拍av一区二区三区|
美女脱光内衣内裤视频久久影院|
www..com久久爱|
久久久久97国产精华液好用吗|
1024亚洲合集|
国产成人精品三级麻豆|
91精品国产一区二区|
久久久一区二区三区捆绑**|
91官网在线观看|
久久综合一区二区|
欧美一级二级在线观看|
欧美日韩高清在线|
欧美系列亚洲系列|
欧美在线观看一区二区|
91影院在线观看|
色呦呦日韩精品|
国产欧美一区二区精品忘忧草|
久久福利资源站|
色综合天天综合网国产成人综合天|
99久久精品国产一区|
成人美女视频在线看|
国产69精品久久777的优势|
欧美激情综合网|
亚洲亚洲精品在线观看|
亚洲在线免费播放|
99精品一区二区三区|
亚洲婷婷国产精品电影人久久|
国产精品美女久久福利网站|