1.3 進入PAI NotebookGallery
登錄PAI控制臺。
在左側導航欄中,選擇快速開始>NotebookGallery。
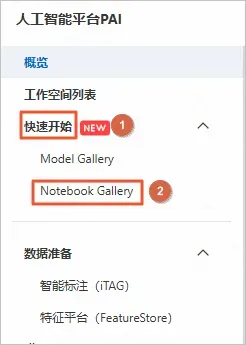
在Notebook Gallery頁面,單擊進入“LLaMA Factory多模態微調實踐:微調Qwen2-VL構建文旅大模型”教程。
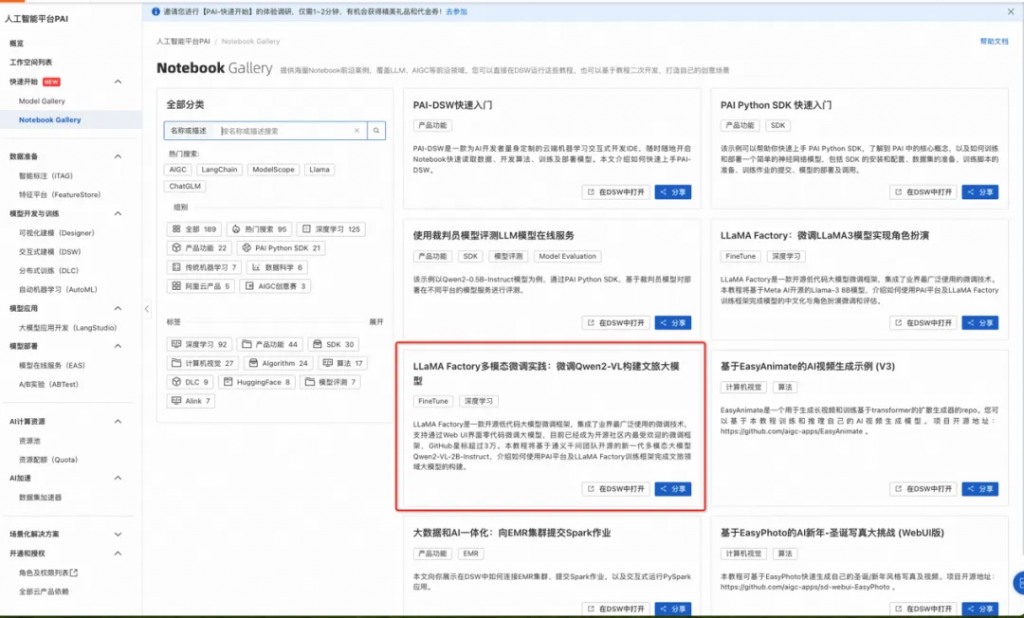
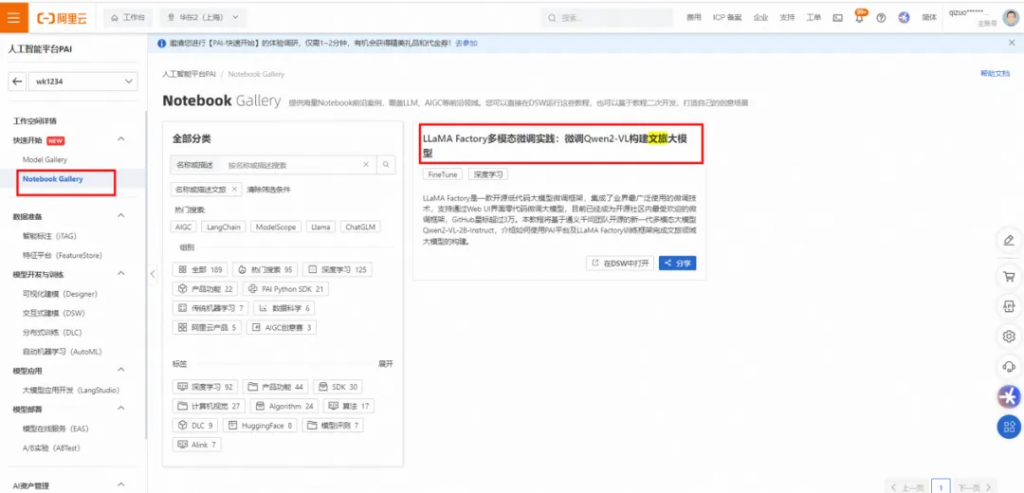
在詳情頁面,您可查看到預置的LLaMA Factory多模態微調實踐:微調Qwen2-VL構建文旅大模型教程,單擊右上角的在DSW中打開。
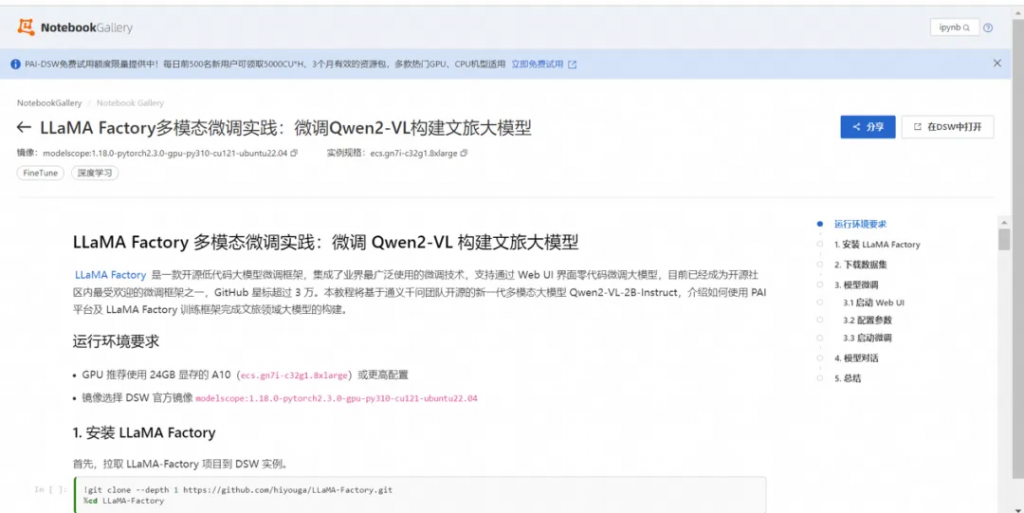
在請選擇對應實例對話框中,單擊新建DSW實例。
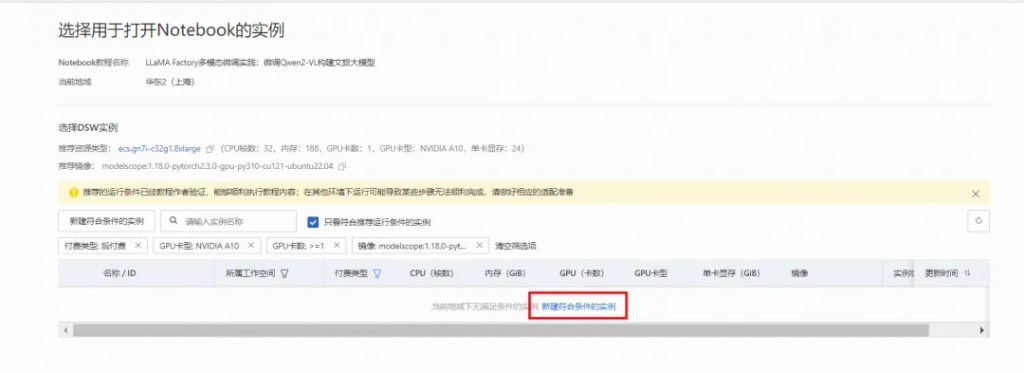
1.4 創建PAI-DSW實例
在配置實例頁面,自定義輸入實例名稱,例如DSW_LlamaFactory。
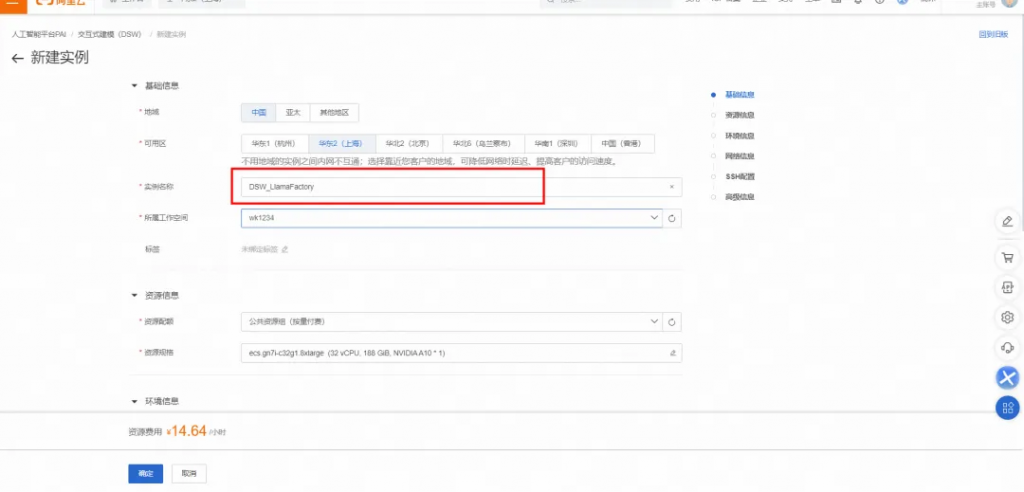
說明:
- 若您是 PAI 產品新用戶,請再次確認是否已領取免費使用權益,點擊領取。若您未領取免費試用權益,或不符合免費試用條件,或歷史已領取且免費試用額度用盡或到期,完成本實驗將產生扣費,大約為6-30元/小時。
- 請在實驗完成后,參考最后一章節清理及后續,停止/刪除實例,以免產生不必要的扣費或資源消耗。
GPU推薦使用 24GB 顯存的 A10(ecs.gn7i-c8g1.2xlarge)或更高配置。※ 支持免費試用的資源:
ecs.gn7i-c8g1.2xlarge、ecs.gn6v-c8g1.2xlarge、ecs.g6.xlarge
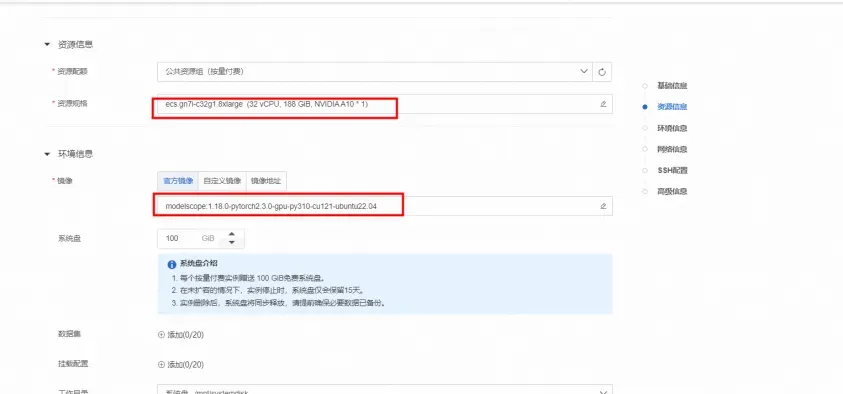
在配置實例頁面的選擇鏡像區域,請確認鏡像是否為官方鏡像的modelscope:1.14.0-pytorch2.1.2-gpu-py310-cu121-ubuntu22.04。
在配置實例頁面,未提及的參數保持默認即可,單擊確認,創建實例。
請您耐心等待大約3分鐘左右,當狀態變為運行中時,表示實例創建成功,點擊打開NoteBook。
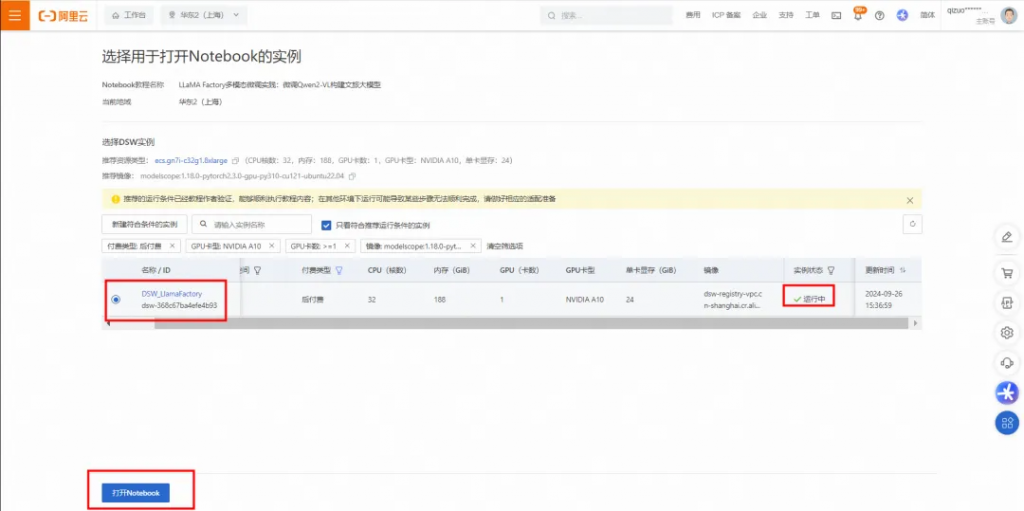
1.5 運行Notebook教程文件
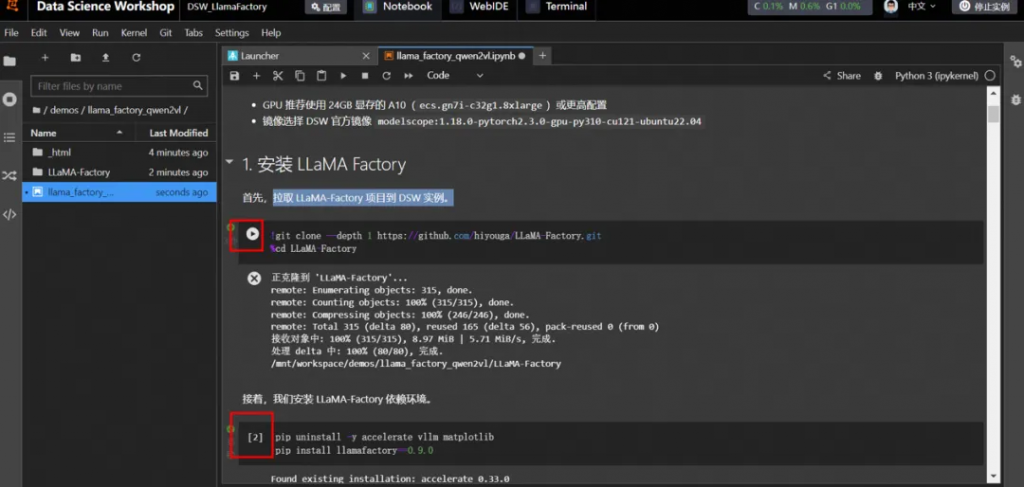
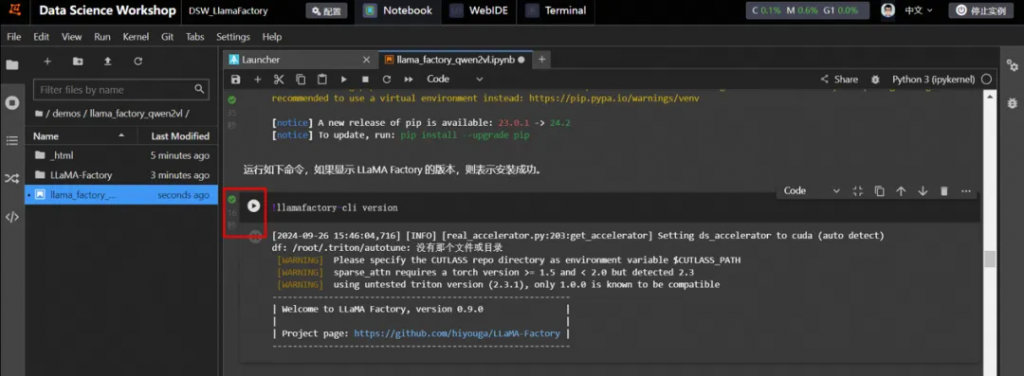
安裝LLaMA Factory
根據教程指引,依次運行命令。
說明:單擊命令左側的運行?按鈕表示開始運行任務,當左側為?號時表明成功運行結束。
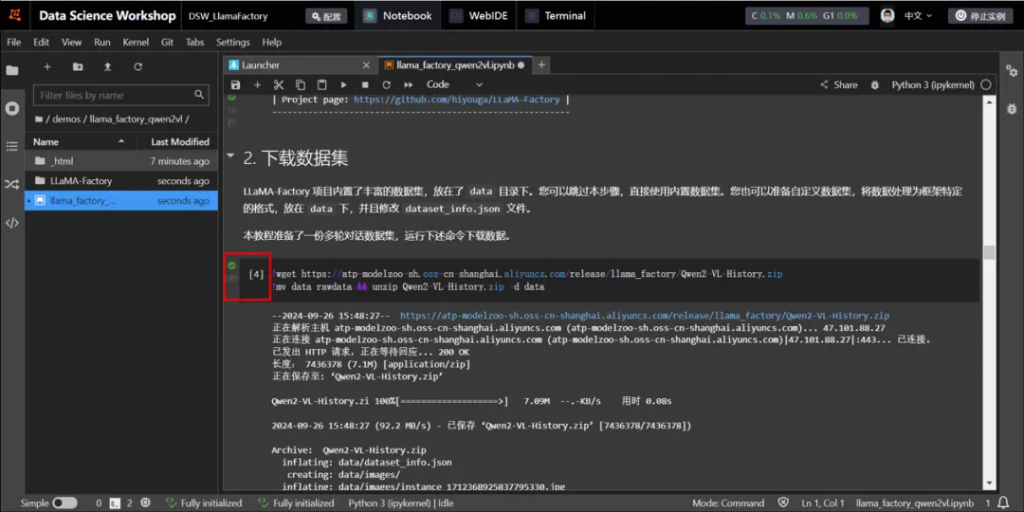
下載數據集
LLaMA-Factory 項目內置了豐富的數據集,放在了 data目錄下。您可以跳過本步驟,直接使用內置數據集。您也可以準備自定義數據集,將數據處理為框架特定的格式,放在 data 下,并且修改 dataset_info.json 文件。
本教程準備了一份多輪對話數據集,運行下述命令下載數據。
說明:單擊命令左側的運行?按鈕表示開始運行任務,當左側為?號時表明成功運行結束。
2. 模型微調
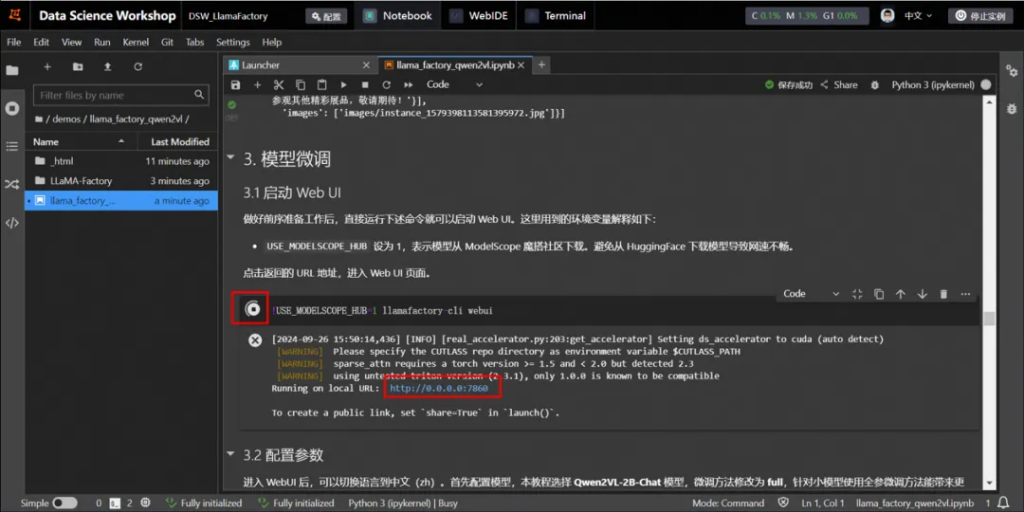
2.1 啟動 Web UI
單擊命令左側的運行?按鈕表示開始運行任務,當左側為?號時表明成功運行結束。
然后單擊返回的URL地址,進入Web UI頁面。
2.2 配置參數
進入 WebUI 后,可以切換語言到中文(zh)。首先配置模型,本教程選擇 Qwen2VL-2B-Chat 模型,微調方法修改為 full,針對小模型使用全參微調方法能帶來更好的效果。

數據集使用上述下載的 train.json。

可以點擊「預覽數據集」。點擊關閉返回訓練界面。
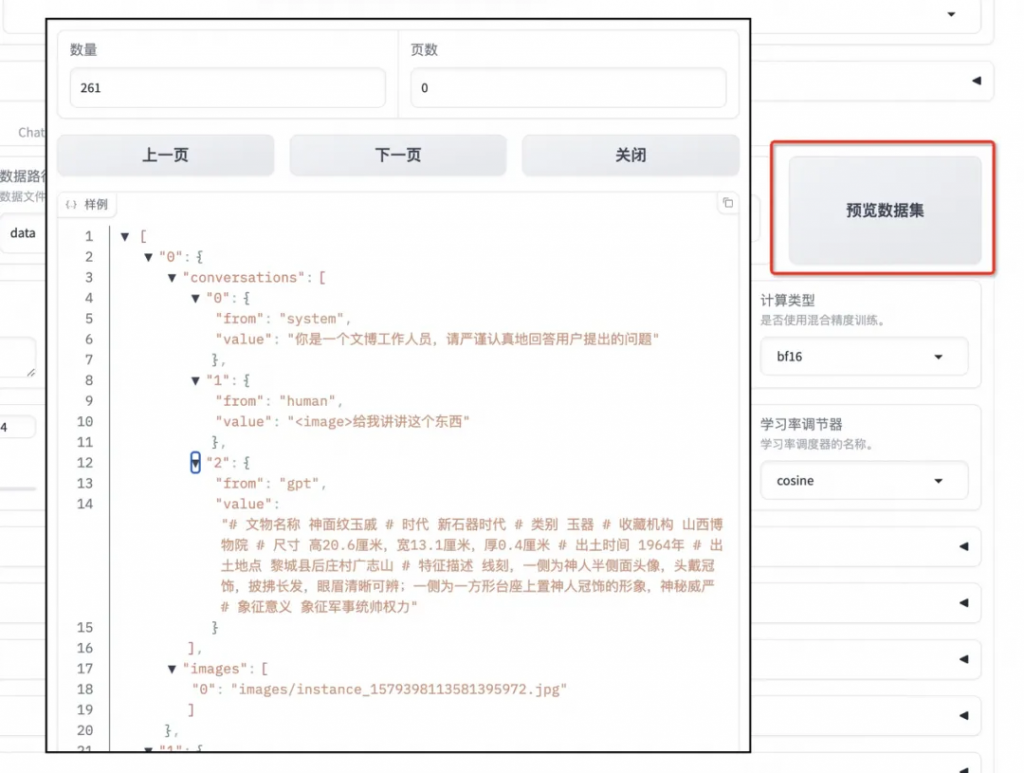
設置學習率為 1e-4,訓練輪數為 10,更改計算類型為 pure_bf16,梯度累積為 2,有利于模型擬合。
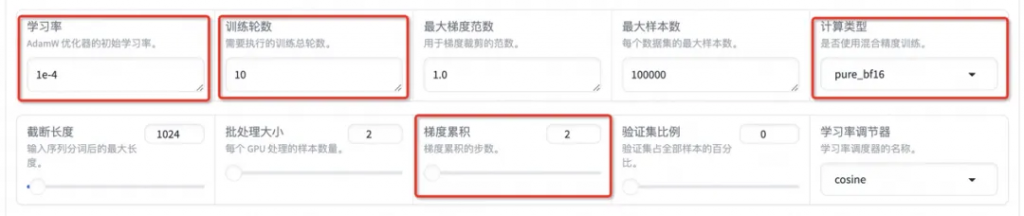
在其他參數設置區域修改保存間隔為 1000,節省硬盤空間。

2.3 啟動微調
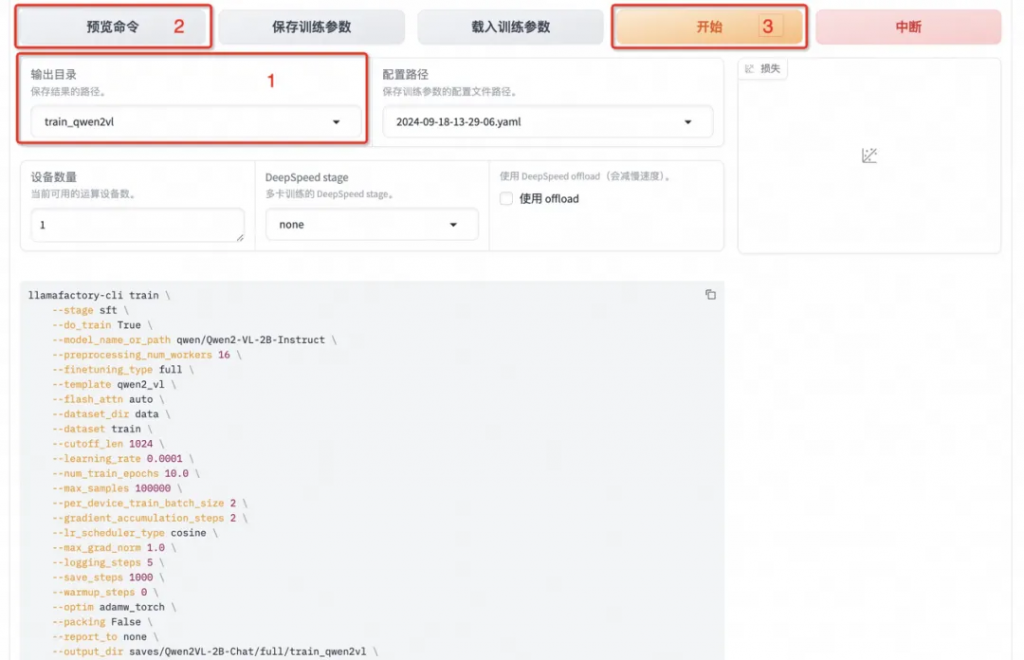
將輸出目錄修改為 train_qwen2vl,訓練后的模型權重將會保存在此目錄中。點擊「預覽命令」可展示所有已配置的參數,您如果想通過代碼運行微調,可以復制這段命令,在命令行運行。
點擊「開始」啟動模型微調。
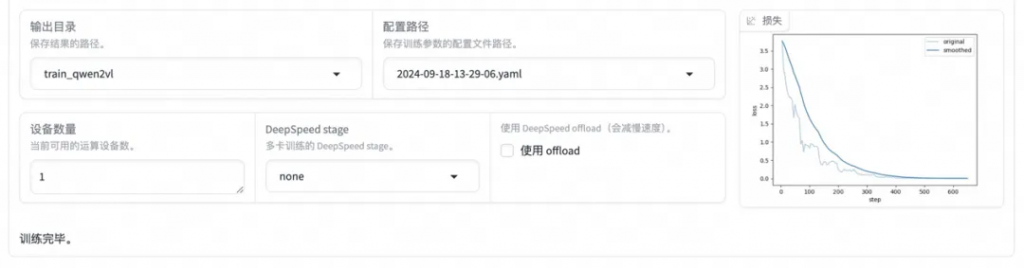
啟動微調后需要等待一段時間,待模型下載完畢后可在界面觀察到訓練進度和損失曲線。模型微調大約需要 14 分鐘,顯示“訓練完畢”代表微調成功。
3. 模型對話
選擇「Chat」欄,將檢查點路徑改為 train_qwen2vl,點擊「加載模型」即可在 Web UI 中和微調后的模型進行對話。
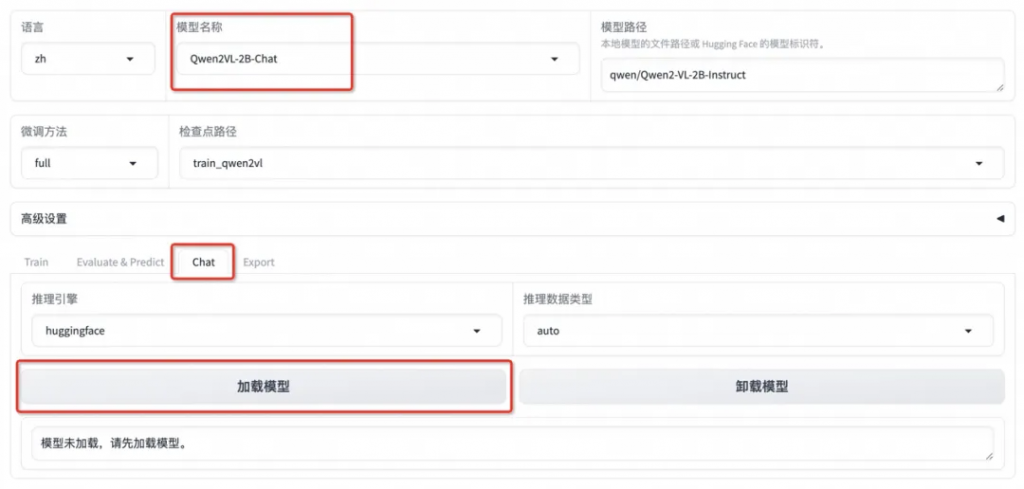
首先點擊下載測試圖片1或測試圖片2,并上傳至對話框的圖像區域,接著在系統提示詞區域填寫“你是一個導游,請生動有趣地回答游客提出的問題”。在頁面底部的對話框輸入想要和模型對話的內容,點擊提交即可發送消息。
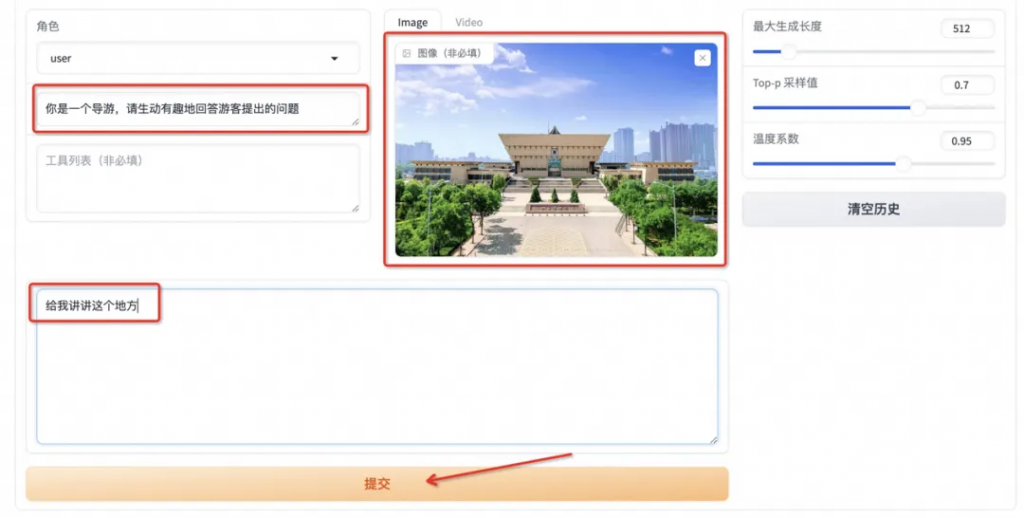
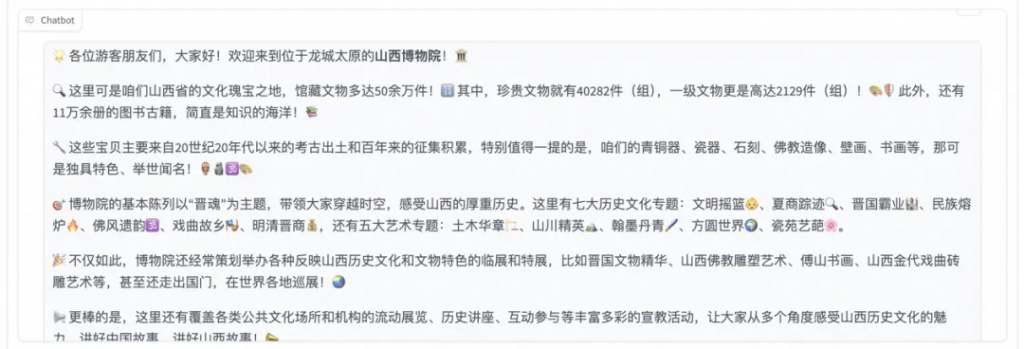
發送后模型會逐字生成回答,從回答中可以發現模型學習到了數據集中的內容,能夠恰當地模仿導游的語氣介紹圖中的山西博物院。
點擊「卸載模型」,點擊檢查點路徑輸入框取消勾選檢查點路徑,再次點擊「加載模型」,即可與微調前的原始模型聊天。

重新向模型發送相同的內容,發現原始模型無法準確識別山西博物院。

三、資源清理和后續操作
- 資源清理
- 在實驗完成后,前往控制臺停止或刪除實例,以避免資源的持續消耗和不必要的費用。
- 后續使用
- 在試用有效期內,可以繼續使用DSW實例進行模型訓練和推理驗證,探索更多AI圖像編輯的可能性。
文章轉自微信公眾號@阿里云開發者
熱門推薦
一個賬號試用1000+ API
助力AI無縫鏈接物理世界 · 無需多次注冊
3000+提示詞助力AI大模型
和專業工程師共享工作效率翻倍的秘密
国内精品久久久久影院日本,日本中文字幕视频,99久久精品99999久久,又粗又大又黄又硬又爽毛片
欧美r级在线观看|
欧美无人高清视频在线观看|
久久99国产精品成人|
欧美剧情电影在线观看完整版免费励志电影
|
欧美区一区二区三区|
日欧美一区二区|
日韩欧美综合一区|
国产精品系列在线播放|
欧美激情一二三区|
在线一区二区三区|
美女免费视频一区二区|
久久精品视频一区二区三区|
成人精品免费网站|
天天操天天干天天综合网|
欧美成人r级一区二区三区|
丰满少妇久久久久久久|
亚洲激情一二三区|
26uuu国产电影一区二区|
caoporm超碰国产精品|
男人操女人的视频在线观看欧美|
国产亚洲欧洲997久久综合|
欧洲av在线精品|
国产经典欧美精品|
日韩综合小视频|
成人欧美一区二区三区小说|
日韩免费在线观看|
欧美亚洲动漫制服丝袜|
国产剧情一区二区三区|
午夜精品久久久久久久久久久|
久久九九全国免费|
日韩免费在线观看|
欧美日韩在线电影|
91美女片黄在线观看91美女|
国产一区二区三区免费看|
亚洲综合网站在线观看|
国产精品理伦片|
久久精品免视看|
欧美成人一区二区三区片免费|
色老头久久综合|
色素色在线综合|
97精品久久久久中文字幕
|
欧美日韩在线播放三区四区|
懂色av一区二区三区免费看|
美女视频网站黄色亚洲|
亚洲成人免费视|
亚洲美女偷拍久久|
亚洲欧洲中文日韩久久av乱码|
国产欧美一区视频|
国产精品乱人伦|
国产亚洲自拍一区|
国产欧美综合在线|
国产精品成人一区二区艾草|
国产欧美日韩激情|
国产日韩精品一区|
国产精品久久久久久久久果冻传媒|
国产亚洲欧美中文|
国产精品久久久久久亚洲伦|
1024精品合集|
亚洲成人免费在线观看|
蜜乳av一区二区三区|
国产精品一区二区在线观看不卡|
国产一区二区三区综合|
波多野结衣一区二区三区|
色综合久久九月婷婷色综合|
欧美日精品一区视频|
欧美一区二区三区视频在线
|
欧美精品1区2区|
欧美一区二区三区四区久久|
久久久久久免费毛片精品|
亚洲国产精品国自产拍av|
亚洲精品成a人|
麻豆成人综合网|
97久久久精品综合88久久|
欧洲视频一区二区|
久久天天做天天爱综合色|
国产精品短视频|
日韩经典一区二区|
国产成人福利片|
欧美久久一二区|
国产精品高潮久久久久无|
日韩成人av影视|
成人福利视频在线看|
欧美蜜桃一区二区三区|
中文字幕精品在线不卡|
天堂av在线一区|
不卡的电影网站|
精品久久国产字幕高潮|
亚洲一区二区精品3399|
av激情综合网|
国产亚洲精久久久久久|
日韩av一区二区三区|
日本高清不卡视频|
国产精品无人区|
精久久久久久久久久久|
欧美三级电影一区|
一区二区在线电影|
av高清不卡在线|
国产欧美精品一区二区色综合|
天天爽夜夜爽夜夜爽精品视频|
91首页免费视频|
国产精品天天摸av网|
国产精品一区二区在线播放|
日韩视频一区二区三区在线播放|
亚洲不卡一区二区三区|
欧美在线免费视屏|
一级特黄大欧美久久久|
在线精品观看国产|
亚洲男人的天堂一区二区|
成人黄动漫网站免费app|
国产香蕉久久精品综合网|
精品一区二区三区在线观看
|
欧美一二三四在线|
日韩精品亚洲专区|
欧美成人女星排行榜|
日本成人在线看|
石原莉奈在线亚洲三区|
欧美三级电影网|
日本免费新一区视频|
日韩欧美国产一区二区三区
|
一区二区三区蜜桃网|
日本精品一区二区三区四区的功能|
一区二区中文字幕在线|
色老头久久综合|
日本不卡的三区四区五区|
欧美精品一区二区三区蜜臀|
国产在线不卡视频|
亚洲欧美中日韩|
欧美日韩一级片在线观看|
美女视频一区二区三区|
欧美激情艳妇裸体舞|
色综合色狠狠综合色|
免费视频最近日韩|
中文欧美字幕免费|
欧美精品在线观看一区二区|
国产一区二区三区免费在线观看|
国产精品久久久久影院色老大|
色综合色狠狠综合色|
美洲天堂一区二卡三卡四卡视频|
国产日韩欧美不卡在线|
欧美日韩精品一区视频|
成人精品电影在线观看|
亚洲电影一区二区三区|
久久婷婷国产综合精品青草|
欧美图片一区二区三区|
国产福利一区二区三区视频|
亚洲综合网站在线观看|
国产欧美日韩不卡|
日韩免费在线观看|
欧美精选在线播放|
一本到一区二区三区|
精品一区二区免费|
亚洲一区二区成人在线观看|
国产色综合一区|
4438x成人网最大色成网站|
www.欧美日韩国产在线|
精一区二区三区|
日韩在线一区二区三区|
亚洲精品国产a|
中文字幕高清不卡|
精品国产一区二区三区忘忧草
|
久久青草欧美一区二区三区|
欧美丰满少妇xxxxx高潮对白|
国产91高潮流白浆在线麻豆
|
91蝌蚪国产九色|
99久久er热在这里只有精品15|
久久精品99国产精品日本|
亚洲成人免费影院|
亚洲与欧洲av电影|
一区二区三区久久久|
一区二区三区四区五区视频在线观看|
国产色综合久久|
国产精品美女久久久久久久网站|
久久午夜羞羞影院免费观看|
欧美sm极限捆绑bd|
欧美精品一区二区久久久|
精品久久久久久久久久久久包黑料|
欧美日韩久久久|
日韩一区二区影院|
日韩精品资源二区在线|
亚洲精品一区二区精华|
国产精品网站在线观看|
亚洲另类色综合网站|
五月天欧美精品|
国产在线视视频有精品|
成人高清伦理免费影院在线观看|
www..com久久爱|
欧美三级蜜桃2在线观看|
欧美一区二区在线免费播放|
337p粉嫩大胆噜噜噜噜噜91av|
国产性做久久久久久|
亚洲欧美日韩成人高清在线一区|
亚洲美女免费在线|
免费一级片91|
99re视频这里只有精品|
欧美高清hd18日本|
久久久国产午夜精品|
亚洲一区二区美女|
国产风韵犹存在线视精品|
欧美亚洲高清一区二区三区不卡|
久久综合久久99|